
Abstract
Background
Accessible tools to efficiently detect and segment diffusion abnormalities in acute strokes are highly anticipated by the clinical and research communities.
Methods
We developed a tool with deep learning networks trained and tested on a large dataset of 2,348 clinical diffusion weighted MRIs of patients with acute and sub-acute ischemic strokes, and further tested for generalization on 280 MRIs of an external dataset (STIR).
Results
Our proposed model outperforms generic networks and DeepMedic, particularly in small lesions, with lower false positive rate, balanced precision and sensitivity, and robustness to data perturbs (e.g., artefacts, low resolution, technical heterogeneity). The agreement with human delineation rivals the inter-evaluator agreement; the automated lesion quantification of volume and contrast has virtually total agreement with human quantification.
Conclusion
Our tool is fast, public, accessible to non-experts, with minimal computational requirements, to detect and segment lesions via a single command line. Therefore, it fulfills the conditions to perform large scale, reliable and reproducible clinical and translational research.
Plain language summary
Determining the volume and location of lesions caused by acute ischemic strokes - in which blood flow is restricted to part of the brain - is crucial to guide treatment and patient prognosis. However, this process is time-consuming and labor-intensive for clinicians. Here, using brain imaging datasets from patients with ischemic strokes, we create an artificial intelligence-based tool to quickly and accurately determine the volume and location of stroke lesions. Our tool outperforms some similar existing approaches, it is fast, publicly available, accessible to non-experts, and it runs on normal computers with minimal computational requirements. As such, it may be useful both for clinicians treating patients and researchers studying ischemic stroke.
Similar content being viewed by others
Introduction
Stroke is a major cause of death and long-term disability in US, with increasing mortality rates among middle-aged adults1. Defining the stroke core in diffusion-weighted images (DWIs), a magnetic resonance imaging (MRI) sequence highly sensitive to the acute lesion, is a major benchmark for acute treatment. The importance of fast locating and objectively quantifying the acute damage has been reinforced by many stroke trials2,3,4,5. Clinical research also relays on objective quantification of lesions to access brain function (as lesion-symptoms studies6), to stratify populations in clinically relevant groups, and to model prognosis7,8,9,10. Due to the great variability of stroke population and lesions in both biological and technical aspects, stroke research depends on large datasets and, consequently, on automated tools to process them with accuracy and high levels of reproducibility. Therefore, accessible tools that can fast and efficiently detect and segment diffusion abnormalities in acute strokes are well anticipated by the clinical and research communities.
Traditional machine learning algorithms use texture features11, asymmetric features12, abnormal voxel intensity on histogram13 or probabilistic maps of populations14,15, or advanced statistical models such as support vector machine16 and random forest17, to detect and segment diffusion abnormalities in acute strokes. Although these methods represent resourceful statistical approaches and can work reasonably in high-resolution images and homogeneous protocols, the low-level features these methods utilize such as intensity, spatial, and edge information reduce their capability to capture the large variation in lesion pattern, especially in typical clinical, low-resolution, and noisy data.
As the prosperous progress in deep learning (DL) in the past two decades, several DL neural network models18,19,20, such as the convolutional neural networks (CNNs), performed better brain lesion detection and segmentation than traditional methods. A landmark was the introduction of UNet21, to re-utilize coarse semantical features via skip connections from encoders to decoders in order to predict better segmentation. Further developments of UNet variants, such as Mnet, DenseUnet, Unet++, and Unet3+22,23,24 optimized the features utilization. The emergence of attention-gate techniques25,26,27 conditioned networks to focus on local semantical features. Recent studies applied “attention UNets”, for example, to predict final ischemic lesions from baseline MRIs28,29. Nevertheless, segmenting medical images with 3D networks still remains a challenge.
The 3D networks suffer from issues like gradient vanishing and lack of generalization, due to their complex architectures. Training a large number of parameters requires a large number of training samples, which is not typically available when utilizing real clinical images. As a result, most prior DL methods20,30,31 were developed in 2D architectures, ignoring the 3D contextual information. In addition, they were mostly trained and/or tested on 2D lesioned brain slices; therefore, they are not generalizable in clinical applications where there is no prior information about the lesion location. More recently, “2.5D” networks32, 3D dual-path local patch-wise CNNs, DeepMedic31, and other CNNs proposed in the Ischemic Stroke Lesion Segmentation (ISLES) challenge18, aimed to improve local segmentation. However, they still do not fully utilize the whole-brain 3D contextual information which might lead to more false positives, especially in “lesion-like” artifacts commonly seen in clinical DWIs. Furthermore, previous networks were mostly evaluated on segmenting late subacute and chronic ischemic abnormalities in high-resolution MRIs, with research-suited homogenous protocols32,33,34 which do not reflect the challenges of real clinical data. To our best knowledge, Zhang et al.35 were the first to reveal the potential of the 3D whole-brain dense networks on low-resolution clinical acute lesion segmentation. However, the relatively modest sample size utilized (242 clinical low-resolution images for training, validating and testing the models, plus 36 downsampled high-resolution images to test for generalization), compared to the large amounts of trainable parameters and high variations of stroke biological features, raises questions about the generalization and robustness of the derived models.
The requirement of large amounts of data for training and testing DL models is a common challenge for achieving good generalization and efficiency in practical applications. Artificial data augmentation does not necessarily mirror the biological heterogeneity of strokes, and imperfectly reflects the noise, low resolution, and technical variability of clinical data. Models developed in modest and homogeneous samples, or in artificial augmented data, might be less efficient in heterogeneous and noisy clinical samples36. Lastly, the lack of accessibility reduces the potential generalization and translation of previous methods: currently, there is no platform that allows regular users (not imaging experts) to readily and rapidly detect and segment diffusion abnormalities in acute stroke clinical images.
In this study, we developed DL network ensembles for the detection and segmentation of lesions from acute and early subacute ischemic strokes in brain MRIs. Our network ensembles were trained and validated in 1390 clinical 3D images (DWIs) and tested in 459 images. The lesion core was manually delineated in all the images, serving as “ground truth”. Furthermore, we evaluated false positives on extra 499 DWIs of brains with “not visible” lesions. To our best knowledge, this is the largest clinical set ever used. We also tested our trained models on an external population of 140 individuals scanned at the hyperacute stroke phase and 24 h later (STIR dataset37). Our results show that our model ensembles are in general comparable to 3D pathwise CNNs (as “DeepMedic”) for lesion segmentation, performing superiorly for detection and segmentation of small lesions, with much lower false-positive rate. Our model is generalizable and robust on the external dataset, over the acute phases. Finally, our model is readily and publicly available as a tool with minimal implementation requirements, enabling non-expert users to detect and segment lesions in about one minute in their local computers, with a single command line.
Methods
Cohort
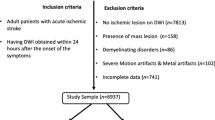
This study included MRIs of patients admitted to the Comprehensive Stroke Center at Johns Hopkins Hospital with the clinical diagnosis of ischemic stroke, between 2009 and 2019 (flowchart for data inclusion in Fig. 1). It utilizes data from an anonymized dataset (IRB00228775), created under the waiver of informed consent because the image is anonymized. We have complied with all relevant ethical regulations and the guidelines of the Johns Hopkins Institutional Review Board, that approved this study (IRB00290649).

The traced box shows the independent testing samples.
From the 2348 DWIs quality-controlled for clinical analysis, 499 images did not show visible lesion. These mostly include transitory ischemic strokes (TIA) or strokes with volume under the image resolution. They are called images with “not visible” lesions and were used to calculate false positives in this study. The other 1849 DWIs showed lesions classified by a neuroradiologist as a result of acute or early subacute ischemic stroke, with no evidence of hemorrhage. The lesion core was defined in DWI, in combination with the apparent diffusion coefficient maps (ADC) by two experienced evaluators and was revised by a neuroradiologist until reaching a final decision by consensus. This manual definition was saved as a binary mask (stroke = 1, brain and background = 0) in the original image space of each subject.
The DWIs with ischemic lesions were randomly split into a training dataset (n = 1390), which was used to train and validate all subsequent models, and testing dataset (n = 459), which was used exclusively for testing models. A second external dataset, STIR, was used to test the generalization of our models in a completely unrelated population (flowchart in Fig. 1). We have complied with all relevant STIR regulations for data usage. From the STIR dataset, we included 140 subjects scanned twice: at the hyperacute stroke event (here called “STIR 1”) and up to 24 h later (“STIR 2”). The longitudinal aspect of STIR enables to evaluate the performance of our models according to the stroke’s onset.
The demographic, lesion, and scanner profiles for all the datasets are summarized in Table 1. The distribution according to arterial territories (MCA > PCA > VEB > ACA) and the demographic characteristics reflect the general population of stroke patients. MRIs were obtained on seven scanners from four different manufacturers, in different magnetic fields (1.5T (60%) and 3T), with more than a hundred different protocols. The DWIs had high in-plane (axial) resolution (1 × 1 mm, or less), and typical clinical high slice thickness (ranging from 3 to 7 mm). Although a challenge for imaging processing, the technical heterogeneity promotes the potential generalization of the resulting developed tools. The demographics (age, sex, race, time from symptoms onset, and NIHSS) and lesion characteristics (e.g., volume, intensity, location) were balanced between training and testing ischemic sets (Supplementary Table 1).
Lesion delineation
The lesion delineations were performed using ROIEditor. The evaluators looked for hyperintensities in DWI and/or hypo intensities (<30% average brain intensity) in ADC. Additional contrasts were used to rule out chronic lesions or microvascular white matter disease. A “seed growing” tool in ROIEditor was often used to achieve a broad segmentation, followed by manual adjustments. The segmentation was performed by two individuals highly experienced in lesion tracing (more than 10 years of experience). In addition, they were trained by detailed instructions and illustrative files, in a subset of 130 cases (randomly selected 10% of the dataset). These cases were then revised by a neuroradiologist, discussed with the evaluators, and (blinded) retraced, revised, and re-analyzed after 2 weeks. The interevaluator index of agreement, Dice score, in this set was 0.76 ± 0.14; the intra-evaluator Dice was 0.79 ± 0.12. Although this is a satisfactory level of agreement, it demonstrates that human segmentation is not totally reproducible, even when performed by experienced, trained evaluators. After consistent consensus agreement was achieved in the initial set, the evaluators started working on the whole dataset. The neuroradiologist revised all the segmentation and identified the sub-optimum cases that were subsequently retraced. The segmentations were revised as many times as necessary until reaching a final decision by consensus among all evaluators.
Image preprocessing
To convert the images to a common space, where the next preprocessing steps will take place, we: (1) resampled DWI, B0 (the image in the absence of diffusion gradients), and ADC into 1 × 1 × 1 mm3, (2) skull-stripped with an in-house “UNet BrainMask Network”, (3) used “in-plane” (IP) linear transformations to map the images to the standard MNI (Montreal Neurological Institute) template, (4) normalized the DWI intensity to reduce the variability and increase the comparability among subjects, (5) “down-sampled” (DS) images to reduce the memory resource requirement in the next steps (e.g., DL networks). Details of these procedures follow.
Automated skull stripping—BrainMask network
To decrease computational complexity and time required for skull stripping, we built an “UNet BrainMask Network” using DWI, B0 images, and gold-standard brain masks. The gold standards brain masks were generated as follows: first, all DWI and B0 images were resampled into 1 × 1 × 1 mm3 and skull striped by a level-set algorithm (available under ROIStudio, in MRIStudio38), with W5 = 1.2 and 4, respectively (see explanation about the choice of parameters in MRIstudio website38). The brain masks were the union of masking on DWI and B0. Then, these brain masks were further manually corrected by our annotators, serving as ground true for the “UNet BrainMask Network”.
To train our “UNet BrainMask Network”, all images are mapped to MNI and downsampled to 4 × 4 × 4 mm3. The final brain mask inferenced by the network was then post-processed by the closing and the “binary_fill_holes” function from Python scipy module, upsampled to 1 × 1 × 1 mm3, and dilated by one voxel with image smoothing. The Dice agreement between the “gold-standard” brain masks and those obtained with our network was above 99.9%, in an independent test dataset of 713 brains. The average processing time was about 19 s (against 4.3 min taken by the level-set algorithm38), making it suitable for large-scale, fast processing.
IP-MNI and IP-MNI DS space
We used sequential linear transformations (3D rigid translation followed by scaling/rotation along x and y axis) to map B0, less affected by the acute stroke, into JHU_MNI_B038, a template in MNI space. No rotation was performed along the interslice coordinate (z axis), aiming to preserve the image contrast and the continuity of manual annotations, and to ameliorate issues related to the low resolution and voxel anisotropy. We called this standardized space “in-plane MNI"(IP-MNI). The IP-MNI images were then padded into 192 × 224 × 192 voxels, to facilitates the next step of “down-sampling” (DS) by (2, 2, 4) in (x, y, z) axes and max-pooling operations, which reduces the memory resource requirement in DL networks. The voxel dimension of the downsampled images are 96 × 112 × 48 voxels, which is called IP-MNI DS space.
DWI intensity normalization
Intensity normalization increases the comparability between subjects and, as normalizing images to a standardized space, is crucial for diverse image analytical processes. Although the lesion might affect intensity distribution, we assume that the majority of brain voxels are from healthy tissue and can be a good reference for intra- and interindividual comparison. We used bimodal Gaussian function in Eq. (1) to fit the intensity histogram of DWI and cluster two groups of voxels: the “brain tissue” (the highest peak) and “non-brain tissue” (the lowest peak at lowest intensities, composed mostly by cerebrospinal fluid).
where ai, bi, ci are the coefficients of the scale, mean, and standard deviation of Gaussian distribution. ai, bi, ci are calculated by least-square fitting the bimodal Gaussian function to the intensity histogram of individual DWI. DWI intensities are normalized to make the “brain tissue” intensity with zero mean and one standard deviation. Supplementary Fig. 1A shows that the DWI intensity distribution of voxels in a brain with ischemic lesions (blue) and in a brain with “not visible” lesion (orange) prior to (left column), and post-to (right column) intensity normalization. We note that the preservation of the minor peak at high intensities in the brain with ischemic lesion indicates the preservation of the lesion contrast after normalization. Supplementary Fig. 1B–D shows the distribution of DWI intensities in groups of images, prior to and post-to intensity normalization. We note that the distributions are much more homogeneous, and the individual variations are smaller after intensity normalization. More importantly, intensity differences between different magnetic fields and scan manufacturers are ameliorated after intensity normalization. Our choice for this intensity normalization approach is, therefore, based on its success to capture the contrast between lesioned voxels and normal tissue voxels, while minimizing variations in intensity range across subjects. The influence of other intensity normalization approaches, from simple z score normalization up to different self-supervised methods39,40, is subject to further evaluation.
Lesion segmentation with unsupervised (“classical”) methods
We tried two “classical” methods for lesion segmentation: (1) “t-scores” maps of DWI and ADC for individual brains14, via comparing them to the set of brains with “not visible” lesions, and (2) ischemic probabilistic maps of abnormal voxels, here called “IS”, via the modified c-fuzzy algorithms15.
T-score method14
After mapping all the images to a common template (JHU-EVE MNI38), we computed the t-score maps of DWI and ADC, tdwi, tadc, for each individual s compared to all controls, as in Nazari-Farsani et al.14. The images were smoothed by a Gaussian filter with different full width at half-maximum (FWHM), Wfwhm. The lesion voxels were detected by thresholding the t-scores maps (i.e., tdwi > σdwi, tadc > σadc) and thresholding DWI intensities individually (i.e., tid > σid). These three thresholds and FWHM were optimized by cross-validation in the training dataset. We searched all parameters’ configurations as follows: Wfwhm ∈ {2, 3, 4, 5}, σdwi ∈ {1, 1.5, 2, 2.5, 3, 3.5}, σadc ∈ {1, 1.5, 2, 2.5, 3, 3.5}, σid ∈ {1.5, 2, 2.5, 3, 3.5}. σdwi, σadc, and σid are in z score scale, rather than percentage. Wfwhm is in the unit of the pixel. The best model was Wfwhm = 4, σdwi = 2, σadc = 1, σid = 3.5. The Dice and Net Overlap (defined as14) of the top four configurations are summarized in Supplementary Table 2.
Modified c-fuzzy method15
We first created intensity mean and standard deviation “templates” in IP-MNI space, Is,μ(x, y, z) and Is,σ(x, y, z) for s = dwi and s = adc, separately, using the normalized DWI and ADC of cases with “not visible” lesions. We then modified and computed the dissimilarity equation for individual DWI and ADC, Is(x, y, z) for s = dwi and s = adc, compared to Is,μ(x, y, z) and Is,σ(x, y, z) similar as in Guo et al.15.
where αs is the parameter used for controlling sensitivity. The probability map of abnormal low-intensity (H1) and high-intensity (H2) voxels were computed as:
To generate the probabilistic maps of ischemic voxels, PIS, we looked for these voxels to have abnormal high intensity (H2) in DWI and abnormal low intensity (H1) in ADC compared to the templates, and also relatively high intensity in its own individual DWI, is defined as follows:
where Q(⋅) is the standard normal distribution Q function, and tid(x, y, z) is the t-score of DWI voxel intensity, compared to the mean and standard deviation of the whole-brain voxels, μid and σid, in each individual DWI. Like what was described for the t-score method, the DWI and ADC images were smoothed by a Gaussian filter with different FWHM. The six following parameters’ combinations were optimized by cross-validation in training dataset: Wfwhm ∈ {2, 3, 4, 5}, αdwi ∈ {0.5, 1, 1.5, 2, 2.5}, λdwi ∈ {2, 3, 4}, αadc ∈ {0.5, 1, 1.5, 2, 2.5}, λadc ∈ {2, 3, 4}, σid ∈ {2, 2.5, 3, 3.5}. σid is in z score scale, rather than percentage. Wfwhm is in the unit of the pixel. The best parameters’ configuration was Wfwhm = 2, αdwi = 1.5, λdwi = 4, αadc = 0.5, λadc = 2, σid = 2. The performance in all datasets is summarized in Supplementary Table 3.
As shown in Supplementary Fig. 2, the modified c-fuzzy method performed better than the t-score method for lesion segmentation. In addition, the t-score method performed worse on our testing dataset (Dice about 0.37) than what is described by the developers14 (Dice about 0.5) Therefore, the classical t-score method was considered insufficiently efficient to segment lesions in our large and heterogeneous clinical dataset.
Lesion segmentation with Deep Learning: DAGMNet implementation details
3D DAGMNet architecture
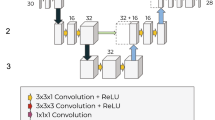
The architecture of our proposed 3D DAGMNet, depicted in Fig. 2, is equipped with intraskip connections as UNet3+24, fused multiscale contextual information block, deep supervision, L1 regularization on final predicts, dual attention gate (DAG)25,26,27, self-normalized activation (SeLU)41, and batch normalization. The details of the important components and training techniques/parameters are outlined in the following subsections.

a The architecture of the DAGMNet. In DAG, sAG stands for spatial attention gate and cAG stands for channel attention gate. “Nf" denotes the number features (Nf = 32 for our final deployed DAGMNet). b Flowchart of the input image’s dimension for training networks and flowchart of the lesion predict’s dimension for inferencing networks in IP-MNI (high-resolution) space.
DAGMNet was intuitively designed to capture semantical features directly from input images at different receptive scale levels, as MNet, and to segment lesions of various volumes with consistent efficiency, via deep supervision at each level. This aims to conquer the drawback that although big lesions can be easily detected at different receptive scale levels in the original generic UNet, small lesions features could be dropped after downsampling pathway/max-pooling layer. Furthermore, The introduction of the interskip connections between layers in UNet structure and intraskip connections as UNet3+ help model share and re-utilize features between different receptive scale levels with lower computational complexity than DenseUNet and UNet++. The final fuse block combines all-scale semantic features (from small lesion volume to large ones) to generate the final predict output. At the end of the fusion block, L1-regularization on predicts prevents the networks from false-positive claiming.
To overcome the high variability in lesion volume, shape, and location, DAG was utilized to condition the networks to emphasize the most informative components (both spatial and channel-wise) from encoders’ semantic features at each level prior to decoders, increasing the sensitivity to small lesions or lesions with subtle contrast. In DAG, spatial attention gate (sAG) was used to spatially excite the receptive for the most abnormal voxels, like the hyperintensity in DWI or predicts from the third channel ("IS"). On the other hand, the channel attention gate (cAG) was included to excite the most semantical/morphological features associated to ischemic lesions from artifacts.
The inclusion of information from classical methods (“IS”) as the third channel aimed to help the networks to focus on abnormal voxels, even if in small clusters (small lesions). In addition, the batch-normalization technique and SeLU activation function aim to self-normalize the networks, avoiding the gradient vanish problem usually faced in complex 3D networks.
Encoder and decoder
As shown in Fig. 2, each encoder or decoder convolution block is composed with two consecutive convolution layers with batch normalization and SeLU activation. The number of features at the first level is denoted as “Nf”. For our proposed model, Nf was 32.
At the encoder part, input images were downsampled by (2, 2, 2) to each receptive scale level and encoded by an encoder convolution block with Nf = 32 for each level. At the second, third, and fourth levels, the encoded features from the previous level were concatenated with the features at the present level and furthered encoded by an encoder block with feature number 2 × Nf, 4 × Nf, and 8 × Nf, respectively.
At the decoder part, each level has an decoder convolution block with deep supervision. The feature numbers of decoders at the first, second, third, and fourth levels are Nf, 2 × Nf, 4 × Nf, and 8 × Nf. The input for decoders at the first, second, and third-level are features from dual attention gate concatenated with the upsampled decoded features from the second, third, and fourth level, respectively. The decoder at the fourth level only takes the features from dual attention gate as input at the same level.
The final predict is fused by a fuse convolution block at the end. The fuse convolution block takes concatenated features decoded from decoders at each level as inputs. The intraskip connection at each level to fuse convolution block was implemented by transposing up-sampling layers.
Dual attention gate (DAG)
DAG has two parts: channel attention gate (cAG) and spatial attention gate (sAG). Both have two parts, squeezing and exciting parts as depicted in Fig. 2a.
-
cAG block could be considered as a self-attention function intrinsically exciting the most important feature channels. cAG squeeze all spatial features into a channel-wise descriptor by a global average pooling layer and a global max-pooling layer. The most activated local spatial receptive fields would lead to the highest global average/max for its corresponding channel. Then the channel-wise dependencies are calibrated by a fully connected dense layer with sigmoid activation to generate a set of weights of the aggregated spatial information. Each channel will be excited by its corresponding weight post-to the cAG block.
-
sAG block could be considered as a self-attention function intrinsically exciting the most important receptive fields. sAG squeezes channel-wise features into spatial statistics with Global Maximum Pooling (GM pooling), Global Average Pooling (GA pooling), and 1 × 1 × 1 convolution layer. Any local spatial semantical features will be excited by a 5 × 5 × 5 convolution layer with SeLU activation to condition network’s attention locally. The sum of both excited spatial local features from both inputs is further calibrated by a 1 × 1 × 1 convolution layer with sigmoid activation.
sAG and cAG both take two inputs: “input 1” from low-level encoded features directly from images at the same receptive scale, “input 2” is all accumulated encoded features from all previous levels, including the current scale level.
SeLU: self-normalization activation function
Compared to rectified linear unit (ReLU), SeLU activation function was reported to have more power to reduce gradient vanish problem among more complicated network structures. Besides, its self-normalization makes the network learn more from morphological features and be less dependent on image contrast. Hence, we used SeLU activation function in our proposed networks.
Deep supervision
Deep supervision is adopted in our model to learn hierarchical representations at each level. Each decoder and the fuse block are fed into a 3-by-3-by-3 convolution layer with sigmoid activation to generate side output, which is supervised by our ground true lesion annotation at its corresponding level.
Loss function
To ameliorate the imbalanced voxel classes issue (between the number of lesion and non-lesion voxels) and regularize the false-positive rate predicted by networks, a hybrid loss function described in Eq. (6) was utilized to train our proposed models.
where Lfuse is the loss function supervised at the final output of the fusion block Xfuse and Li,side is the loss function supervised at the side output of the decoders at each level Xde,i as follows:
where wgds = 1, wbbc = 1, wr = 1e − 5 due to hyperparameter tuning, Lgds is the generalized dice loss function defined as42, Lbbc is the balanced binary cross-entropy defined as21, and L1(p) is the L1 regularization on all predicted voxels defined as
where p(x, y, z) is the predicts from networks at (x, y, z) coordinates. The loss function is optimized during training step by ADAM optimizer with learning rate = 3E − 4. Learning rate will be factor by 0.5 when loss function is on a plateau over 5 epochs with minimum learning rate = 1E − 5.
The dimension of the inputs and predicts during training and inferencing
The networks were trained and inferenced in IP-MNI DS space, which is 96 × 112 × 48 voxels. All images (DWI, ADC, IS) in IP-MNI space were downsampled (DS) along x, y, and z axis with stride of (2, 2, 4) into 16 smaller volumes in 96 × 112 × 48 × 3 voxels for 3-channel models, as shown in Fig. 2b. The input shape of networks with 3 channels is 96 × 112 × 48 × 3.
During training step, as shown in Fig. 2b, one of these 16 downsampled volumes are randomly selected to be the inputs of 3-channel networks for each subject in a selected batch (batch size = 4). This re-sampling strategy aims to increase the robustness of our networks to the image’s spatial shifting and inhomogeneity. To make efficient backpropagation for training networks, the downsampled volumes were standard normalized to zero mean and unit-variant within the brain mask region for both DWI and ADC channels.
During inferencing step, the 16 lesion predicts from networks in IP-MNI DS space were stacked according to the way their inputs volumes were downsampled in the original coordinates, to construct the final predict in IP-MNI space (Fig. 2c). Then, the lesion mask was “closed” with connectivity 1 voxel. The predicted lesion binary mask (predicted value > 0.5) in IP-MNI space was then mapped back to individual original space. We refined the final prediction by removing clusters with <5 pixels in each slice, which is the smallest size of lesions defined by human evaluators.
Hyperparameter
For searching hyperparameters, such as weights for loss functions and networks structures, 20% of subjects from the training dataset were randomly selected as validation dataset, with the same random states for all experiment models. In each experiment, once the loss functions converged in validation dataset along the training epochs (200 epochs at top, early stops at 100 epochs if training and validation loss function converged early), we selected the best model from the snapshot models at every 10 epochs in the validation dataset. We chose maximum training epoch as 200 because most experiments of benchmark models converged after 80 to 120 epochs. For each experiment, we trained the same-type networks independently, with different training set and different resampled validation set, at least twice to check if similar performance would be achieved and avoid overfitting. Once the networks parameters (including weights for loss or regularization, different network layers, depth...etc.) were finalized according to their best dice performance in the validation sets, we used the whole training dataset, including the validation dataset, to train the final deployed models and to make the loss function and dice scores converge to the similar level as the previous experiment. This allowed us to fully use all training dataset and capture the population variation. All Testing datasets and the STIR datasets were totally unexploited till this step was done.
System implementation
All the evaluated methods and models were built with TensorFlow43 (tensorflow-gpu version is 2.0.0) and Keras44 (2.3.1) framework on Python 3.6. Imaging processing and analysis were built with Nibabel45, Scipy46, Dipy47, and Scikit-image48,49. The experiments run on a machine with an Intel Core (Intel(R) Xeon(R) CPU E5-2620 v4 @ 2.10GHz) with 2 NVIDIA TITAN XP GPUs (with CUDA 10.1). The average inference time over all testing dataset and memory requirements are listed in Table 2.
Evaluation of efficiency and comparison among methods
The performances metrics, Dice score, precision, sensitivity, and subject detection rate (SDR), are defined as follows.
TP, FP, and FN, respectively, denote the number of true positives, false positives, and false negatives in the unit of the voxel. The SDR represents the percentage of the subjects whose lesions are detected. Therefore, high SDR indicates good performance in the datasets of subjects with visible lesions (our testing dataset and STIR) but indicates low performance in the dataset of subjects with “not visible” lesions, because the predicted lesion voxels would be false positives. Hence, in the dataset of subjects with “not visible” lesions, it is false-positive SDR.
All models were compared to the manual delineation of the stroke (used here as “gold-standard”) on original raw space. All models were trained, validated, and optimized in the same training dataset, and tested in the independent testing dataset and in the external dataset, STIR. For fair comparison, all models were designed to utilize similar number of trainable parameters, except for DeepMedic, whose default network uses more trainable parameters than all other networks (Table 2).
Besides comparing global performance in the whole brain, we compared models’ performance according to lesion volume and location (by vascular territories) and analyzed the Spearman correlation coefficient of performance with the lesion volume and contrast in DWI and ADC. The “scipy.stats” module is used to calculate the Spearman correlation coefficient. The 95%CI for SDR is calculated with z score = 1.96 and the 95% CI for the Spearman correlation coefficient is calculated by Fishers’ transformation with z score = 1.96.
The lesion contrast in DWI, κDWI, and in ADC, κADC, are defined as the ratio between the average intensity of the lesion voxels and the average intensity of the “normal brain tissue” voxels in DWI and ADC, respectively. High κDWI and low κADC are expected in acute and subacute lesions which tend to be “bright” in DWI and “dark” in ADC. Furthermore, false-positive analysis was conducted on voxel- and subject-basis among the 499 images with “not visible” lesions.
Statistical significance testing
The statistical significance testing was performed by ANOVA test in module “bioinfokit” for continuous data, and by Chi-square test in “scipy.stats.chi2_contingency” module for categorical data. The statistical significance on the demographic, lesion, and image profiles distribution between training and testing datasets is shown in Supplementary Table 1. For race/ethnicity and MRI manufacturer, we compared the major groups. For symptoms onset to MRI time, we compared groups with onset time < 6 and ≥6 h. The statistical comparison among models’ performance in the Testing and STIR dataset is shown in Supplementary Fig. 3. The statistical comparison of models’ performance regarding to demographic, lesion, and image profiles is illustrated in Supplementary Fig. 4.
Reporting summary
Further information on research design is available in the Nature Research Reporting Summary linked to this article.
Results
Lesion segmentation with unsupervised (“classical”) methods
An important question is how the lesion segmentation generated by unsupervised classic methods for abnormal voxel detection compares with DL; and whether the combination of supervised and nonsupervised methods improves the performance. To investigate these questions, we generated ischemic probabilistic maps of abnormal voxels, here called “IS”, via the modified c-fuzzy algorithms15 as detailed in Methods. The best model (Supplementary Table 2) showed modest efficiency on the Testing dataset (Dice: 0.45 ± 0.26) and in STIR 2 (Dice: 0.48 ± 0.28) and was even less efficient in STIR 1 (Dice: 0.23 ± 0.22).
General comparison of DL models’ performance
Our proposed 3D network, called “DAGMNet” (Fig. 2), was compared with other generic benchmark networks, including FCN, UNet, and DeepMedic. All models were compared to the manual lesion delineation.
In general, “CH3” models that utilize three channel inputs (DWI+ADC+IS, the probabilistic ischemic maps obtained by the modified c-fuzzy method) performed slightly better than “CH2” models (that have only DWI and ADC as inputs). This is particularly noticeable in STIR 1, in a trade-off a slight increase in false positives. It is likely that the extra “IS” channel conditions the network attention to regions of abnormal voxel intensity. This improves the model performance in most of the cases, as the identified abnormal voxels truly correspond to lesions. On the other hand, it might increase the false positives in a minority of cases, in which the abnormal voxels correspond to DWI artifacts.
As depicted in Fig. 3 and Table 2, our proposed model, DAGMNet_CH3, outperforms generic UNet and FCN in all the testing datasets, with higher Dice scores and higher Precision. This is particularly significant by comparing the performances of DAGMNet and FCN in the Testing dataset and STIR 2 (Supplementary Fig. 3). This suggests the robustness and generalization of our proposed model to external data. Compared to DeepMedic, our proposed model shows higher Dice in the testing dataset, comparable Dice in STIR 2, and lower Dice in STIR 1, although all differences are not statistically significant. DAGMNet_CH3 also shows significantly higher precision than DeepMedic in the Testing dataset and STIR 2, but lower sensitivity, with a higher number of false negatives in the Testing set. On the other hand, DeepMedic detected significantly more false positives than all other models, both subject-wise and voxel-wise. For instance, DeepMedic claims false-alarm lesions in more than 55% (twice as our model) of the “not visible” lesion cases.

The performance is shown according to testing dataset (a), vascular territory (b), and lesion volume (c), S: small, M: medium, L: large. In each Whisker’s boxplot, the white square indicates the average; the black trace indicates the median. The whisker is a representation of a multiple (1.5) of the interquartile range (IQR). False-positive and false-negative are in units of voxels, in the original image space. All the sub-figures share the same legend as in sub-figure (c).
Performance according to lesion volume and location
Taking advantage of our large dataset, we stratified the testing dataset into three comparable sized groups, according to the lesion volumes. These groups contain subjects with lesion volumes here called small, “S” (<1.7 ml, n = 152), medium, “M” (≥1.7 ml and <14 ml, n = 144), and large, “L” (≥14 ml, n = 163). All the models, except for FCN, perform comparably well in subjects with large lesions, as shown in Figs. 3, 4, and Table 2. Our proposed model and UNet have remarkably higher Dice in subjects with small lesions. Specifically, our proposed model has significantly higher Dice compared to DeepMedic (by average Dice: +0.05, P value: =0.02), UNet_CH2 (by average Dice: +0.06, P value = 0.03), FCN_CH3 (by average Dice: +0.14, P value = 3.9E − 8), and FCN_CH2 (by average Dice: +0.17, P value = 3.0E − 11).

The probability density (y axis) of the Dice score of different models in the Testing dataset; (a) is for all subjects; (b), (c), and (d) are stratified by the lesion volume. All the sub-figures share the same legends as the sub-figure (d).
By grouping lesions according to their location in the major vascular territories (anterior, posterior, middle cerebral arteries—ACA, PCA, MCA—and the vertebro-basilar—VB—territory), we observed that all models had their worse performance in ACA and their best performance in MCA (Fig. 3). As shown in Table 1, the MCA lesions are, in average, larger than lesions in other territories, while the ACA territory contains smaller lesions with lower DWI contrast and is more prone to DWI artfacts. Our models outperformed DeepMedic and generic UNet in ACA and VB territories. Last, the trade-off between precision and sensitivity was clear, for all the models, in MCA lesions.
Performance according to affected hemisphere, population demographics, and scanner profile
In general, all the models performed consistently, regardless the affected hemisphere, patients’ sex and race, symptoms onset to MRI time, scanner manufacturers, and magnetic strengths, as indicated in Fig. 5 and Supplementary Fig. 4. The only exceptions were DeepMedic and FCN_CH2, that had significantly lower Dices in Manufacturer 3 (GE), compared to Manufacturer 1 (Siemens) with P values 0.0223 and 0.0413, respectively. However, this is interpreted with caution given the small sample of Manufacturer 3 (GE) in the Testing dataset.

The performance is shown according to (a) lesion hemisphere, (b) scanner manufacturer, (c) MRI magnetic field, (d) patient’s race, (e) patient’s sex, and (f) symptom onset to MRI time. In each Whisker’s boxplot, the white square indicates the average; the black trace indicates the median. The whisker is a representation of a multiple (1.5) of the interquartile range (IQR). All the sub-figures share the same legends as sub-figure (c).
Relationship of the models’ performance with lesion volume and contrast
The models performance, represented by the Dice agreement between the “human-defined” and the “network-defined” (predicted) lesion positively correlated with the lesion volume and lesion contrast in DWI, and negatively correlated with the lesion contrast in ADC (Fig. 6). This means that, as expected, large and high-contrast lesions are easy to define, both by human and by artificial intelligence. Our proposed model has the lowest correlation between the Dice and lesion volume. Because the Dice score is sensitive to false positives, large lesions tend to have higher Dice than small lesions even for methods with uniform performance across lesion volumes. The decrease of the correlation between Dice and volumes found for our proposed method might result from its superior performance in small lesions. The correlation between the human-defined lesion volume versus the predicted lesion volume is high for all the models (Table 2 and Fig. 6). Our proposed model showed the highest correlation coefficient between the human-defined lesion contrast versus the predicted lesion contrast, implying the highest agreement with human annotation.

The first three columns are scatter plots of lesion features (volume, DWI, and ADC contrast) versus Dice score of the different models (rows) in the Testing dataset (n = 459). They show how the models perform in lesions of diverse volume and contrast. The last three columns are the metrics of volume, DWI, and ADC of the lesions as traced by human evaluators (“true”) vs. as predicted by the different models (rows). Volumes are in ml. ADC values are in 1e − 4 mm2/s. Spearman’s correlation coefficient and 95% CI are in Table 2. The DWI contrast metrics are defined in “Methods”.
Discussion
Although several multicenter and clinical trials2,3,4,5 as well as lesion-symptom mapping studies6 reinforced the need for the quantification of the acute stroke core, there is a gap to be filled by free and accessible technologies that provide fast, accurate, and regional-specific quantification. Commercial platforms50 are restrictive and do not provide the 3D lesion segmentation required for lesion-based studies or for objective clinical application. Refining methods and disseminating technologies to improve the current lesion estimation will enable better tuning parameters of clinical importance, improving individual classification, and modeling anatomicofunctional relations more reliably and reproducibly. We proposed a DL model for acute ischemic lesion detection and segmentation trained and tested on 2348 clinical DWIs from patients with acute stroke, the largest dataset employed so far. We further tested this model on an independent, external dataset of 280 images (STIR). The utilization of a large, biologically, and technically heterogeneous dataset, overcomes previous limitations of DL models developed in much smaller datasets, as their questionable generalization potential36. The use of real clinical data, which usually imposes extra challenges to image processing, such as low resolution, low signal to noise, and lack information from multiple contrasts, guarantees the robustness of the developed models for large-scale, real scenario applications.
Our proposed model (DAGMNet) showed superior performance than generic models such as UNet and FCN, and DeepMedic, in our independent testing dataset. Our method was significantly superior on segmenting small lesions, a great challenge for previous approaches, while presenting low rate of false-positive detection. This might be a result of the use of large amounts of training data, as well as a contribution of the attention gates and the full utilization of brain morphology by our 3D network, which increases the robustness to technical and biological DWI artifacts. This superiority was evidenced by our method’s high performance in vascular territories that contains small lesions and are artifact-prone such as ACA and VB (illustrative examples in Fig. 7). The balanced precision and sensitivity, and the lower dependence on stroke volume and location compared to other methods, make our model well suited not only for lesion segmentation but also for detection, an important component for clinical applications. In addition, our proposed pipeline showed stable performance regardless the affected hemisphere, population profile and scanner characteristics, other important conditions for large-scale applications.

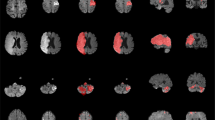
Columns from the left to the right: DWI, ADC, and overlays on DWI of the manual delineation (red), DeepMedic Predicts (yellow), DAGMNet_CH3 (our proposed model) predicts (blue), UNet_Ch3 (green), and FCN_CH3 (purple). A Typical lesion. B Case with inhomogeneity between DWI slices; note the high agreement of our proposed model with the manual annotation. C Multifocal lesions. D Small cortical lesion, detected exclusively by DeepMedic and our proposed attention model. E–G Typical false positives (arrows) of other models (DeepMedic in particular) in areas of: E “physiological" high DWI intensities; F DWI artifacts in tissue interfaces; in addition to the cortical areas, this was vastly observed in the basal brain, along the sinuses interfaces, and in the plexus choroids; G in possible chronic microvascular white matter lesions. H, I Cases in which the retrospective analysis favored the automated prediction, rather than the human evaluation for: H lesion delineation, and I lesion prediction (this case was initially categorized by evaluators as “not visible" lesion, but the small lesion predicted by our model was confirmed by follow-up). J Lesion of high-intense core but subtle boundary contrast, which ameliorates the discriminative power of all 3D networks. In this case, the patch-wise DeepMedic had the best agreement with manual annotation in the boundaries at the cost of detecting false positives (arrow).
In the external testing dataset (STIR), our method’s performance was again superior or rivaled with that of others. An exception was the lowest Dice achieved in STIR 1, compared to DeepMedic. STIR 1 contains patients with hyperacute strokes (subtle hyperintense or normal intense lesions in DWI). These types of lesions are less frequent in patients with acute and early subacute strokes in our training dataset and particularly challenging for whole-brain-wise networks, compared to local patch-wise networks like DeepMedic. Similarly, our method produced less accurate segmentation in a few cases (n = 4) with large, late subacute lesions in STIR 2, that presented subtle intensity contrast in their boundaries (example J in Fig. 7). Note, however, that the advantage of segmenting hyperacute lesions and lesions with subtle contrast was traded-off by the low precision and high false-positive rate of DeepMedic in SITR. The incorporation of the patients with hyperacute strokes in our training dataset, a follow-up local patch-wise segmentation network, and/or using DL techniques like transform learning might ameliorate these issues and are in our future plans. Last, a common source of failure for all methods was errors in skull stripping that increased false positives outside the brain contour. This only occurred in a small number of STIR images (n = 7) that presented a high level of background noise due to an outdated acquisition protocol, therefore, is unlikely an issue for future applications.
The automated DL models (our proposed DAGMNet, DeepMedic, and Unet) achieved comparable lesion quantification performance to our experienced evaluators, because their agreement with human delineation was close to the interevaluator agreement (Dice: 0.76 ± 0.14, as described in Methods). Among all the tested models, our proposed model showed the highest correlation between the contrast of the predicted lesion and the human-defined lesion, indicating the highest agreement with human evaluation. Still, we noticed circumstantial disagreements of our method with the human evaluators in 24 cases (5% of the testing set), in which the retrospective radiological evaluation favored the results of the automated segmentation, particularly regarding to the boundaries definition (Fig. 7H). Similarly, by reviewing the “false-positive subjects” (cases in which models’ predicted lesions but were initially classified as “not visible” lesions by visual radiological inspection), we identified 29 cases in which the lesion was identified in retrospect, in the light of our method’s prediction (example in Fig. 7I). This illustrates the possible advantages of automated methods in reliability and reproducibility.
In addition to be accurate on lesions detection and segmentation, robust to data perturbs (e.g., DWI artifacts, low-resolution sequences, low signal to noise ratio, heterogeneous datasets), and generalizable to external data, our proposed method is fast: it utilizes half of the memory required by its closest competitor, DeepMedic, inferring lesions in half of the time (less than a minute, in CPUs) (see Table 2). All these factors make it potentially suitable for real-time applications. Regardless of all these advantages, a method has no massive utility if only the developers or highly expert analysts are able to use it. Therefore, we made our method publicly accessible on https://www.nitrc.org/projects/ads51 and ref. 52 and readily useful to run in CPUs with a single command line, and minimal installation requirements. To the best of our knowledge, this study provides the first DL networks for lesion detection and segmentation, trained, and tested over 2000 clinical 3D images, available to users with different levels of access to computational resources and expertise, therefore representing a powerful tool for clinical and translational research.
Data availability
The source data for the main result figures in the manuscript are available at https://zenodo.org52. The original images used for training and testing the models derive from retrospective clinical MRIs and are not publicly available, due to their sensitive information that could compromise research participant privacy. These data can be requested with appropriate ethical approval by contacting Dr. Andreia V. Faria (afaria1@jhmi.edu). The STIR data were used under approval from the STIR steering committee for the current study, and so are not publicly available. These data are however available from the STIR/Vista Investigators upon reasonable request to Dr. Marie Luby (lubym@ninds.nih.gov).
Code availability
The tool described in this study is publicly available at https://www.nitrc.org/projects/ads51 and at https://zenodo.org52.
References
Virani, S. S. et al. Heart disease and stroke statistics-"2021 update: a report from the American Heart Association. Circulation 143, e254–e743 (2021).
Albers, G. W. et al. A multicenter randomized controlled trial of endovascular therapy following imaging evaluation for ischemic stroke (defuse 3). Int. journal stroke: official journal Int. Stroke Soc. 12, 896–905 (2017).
Saver, J. L. et al. Solitaire™ with the intention for thrombectomy as primary endovascular treatment for acute ischemic stroke (swift prime) trial: protocol for a randomized, controlled, multicenter study comparing the solitaire revascularization device with iv tpa with iv tpa alone in acute ischemic stroke. Int. J. Stroke 10, 439–448 (2015).
Lees, K. R. et al. Time to treatment with intravenous alteplase and outcome in stroke: an updated pooled analysis of ecass, Atlantis, ninds, and epithet trials. Lancet 375, 1695–1703 (2010).
Jovin, T. G. et al. Diffusion-weighted imaging or computerized tomography perfusion assessment with clinical mismatch in the triage of wake up and late presenting strokes undergoing neurointervention with trevo (dawn) trial methods. Int. J. Stroke 12, 641–652 (2017).
Karnath, H.-O., Sperber, C. & Rorden, C. Mapping human brain lesions and their functional consequences. Neuroimage 165, 180–189 (2018).
Jones, P. S. et al. Does stroke location predict walk speed response to gait rehabilitation? Hum. Brain Mapping 37, 689–703 (2016).
Munsch, F. et al. Stroke location is an independent predictor of cognitive outcome. Stroke 47, 66–73 (2016).
Zhu, L. L., Lindenberg, R., Alexander, M. P. & Schlaug, G. Lesion load of the corticospinal tract predicts motor impairment in chronic stroke. Stroke 41, 910–915 (2010).
Laredo, C. et al. Prognostic significance of infarct size and location: the case of insular stroke. Sci. Rep. 8, 1–10 (2018).
Reza, S., Pei, L. & Iftekharuddin, K. Ischemic stroke lesion segmentation using local gradient and texture features. Ischemic Stroke Lesion Segmentation 23, 23–26 (2015).
Vupputuri, A., Ashwal, S., Tsao, B. & Ghosh, N. Ischemic stroke segmentation in multi-sequence MRI by symmetry determined superpixel based hierarchical clustering. Comput. Biol. Med. 116, 103536 (2020).
Nabizadeh, N. Automated Brain Lesion Detection and Segmentation Using Magnetic Resonance Images (University of Miami, 2015).
Nazari-Farsani, S. et al. Automated segmentation of acute stroke lesions using a data-driven anomaly detection on diffusion weighted MRI. J. Neurosci. Methods 333, 108575 (2020).
Guo, D. et al. Automated lesion detection on MRI scans using combined unsupervised and supervised methods. BMC Medical Imaging 15, 1–21 (2015).
Maier, O., Wilms, M., von der Gablentz, J., Krämer, U. & Handels, H. Ischemic stroke lesion segmentation in multi-spectral MR images with support vector machine classifiers. In Medical Imaging 2014: Computer-Aided Diagnosis, Vol. 9035, (eds Aylward, S. & Hadjiiski, L. M.) 903504 (International Society for Optics and Photonics, 2014).
Gautam, A. & Raman, B. Segmentation of ischemic stroke lesion from 3d MR images using random forest. Multimedia Tools Appl. 78, 6559–6579 (2019).
Winzeck, S. et al. Isles 2016 and 2017-benchmarking ischemic stroke lesion outcome prediction based on multispectral MRI. Front. Neurol. 9, 679 (2018).
Woo, I. et al. Fully automatic segmentation of acute ischemic lesions on diffusion-weighted imaging using convolutional neural networks: comparison with conventional algorithms. Korean J. Radiol. 20, 1275 (2019).
Liu, L. et al. Deep convolutional neural network for automatically segmenting acute ischemic stroke lesion in multi-modality MRI. Neural Computing Appl. 32, 6545–6558 (2020).
Ronneberger, O., Fischer, P. & Brox, T. U-net: convolutional networks for biomedical image segmentation. in International Conference on Medical Image Computing and Computer-assisted Intervention. (eds Navab, N., Hornegger, J., Wells, W. M. & Frangi, A. F.) 234–241 (Springer, 2015).
Mehta, R. & Sivaswamy, J. M-net: a convolutional neural network for deep brain structure segmentation. in 2017 IEEE 14th International Symposium on Biomedical Imaging (ISBI 2017). (ed. ISBI’17) 437–440 (IEEE, 2017).
Zhou, Z., Siddiquee, M. M. R., Tajbakhsh, N. & Liang, J. Unet++: a nested u-net architecture for medical image segmentation. in Deep Learning in Medical Image Analysis and Multimodal Learning for Clinical Decision Support. (eds Stoyanov, D. et al.) 3–11 (Springer, 2018).
Huang, H. et al. Unet 3+: a full-scale connected unet for medical image segmentation. in ICASSP 2020-2020 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). (ed. ICASSP’20) 1055–1059 (IEEE, 2020).
Fu, J. et al. Dual attention network for scene segmentation. in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. (ed. CVPR’19) 3146–3154 (IEEE, 2019).
Schlemper, J. et al. Attention gated networks: Learning to leverage salient regions in medical images. Med. Image Analysis. 53, 197–207 https://doi.org/10.1016/j.media.2019.01.012 (2019).
Khanh, T. L. B. et al. Enhancing u-net with spatial-channel attention gate for abnormal tissue segmentation in medical imaging. Appl. Sci. 10, 5729 (2020).
Yu, Y. et al. Use of deep learning to predict final ischemic stroke lesions from initial magnetic resonance imaging. JAMA Netw. Open 3, e200772–e200772 (2020).
Yu, Y. et al. Tissue at risk and ischemic core estimation using deep learning in acute stroke. Am. J. Neuroradiol. 42, 1030–1037 (2021).
Chen, L., Bentley, P. & Rueckert, D. Fully automatic acute ischemic lesion segmentation in DWI using convolutional neural networks. NeuroImage: Clin. 15, 633–643 (2017).
Karthik, R., Gupta, U., Jha, A., Rajalakshmi, R. & Menaka, R. A deep supervised approach for ischemic lesion segmentation from multimodal MRI using fully convolutional network. Appl. Soft Comput. 84, 105685 (2019).
Xue, Y. et al. A multi-path 2.5 dimensional convolutional neural network system for segmenting stroke lesions in brain MRI images. NeuroImage: Clin. 25, 102118 (2020).
Bernal, J. et al. Deep convolutional neural networks for brain image analysis on magnetic resonance imaging: a review. Artificial Intell. Med. 95, 64–81 (2019).
Ito, K. L., Kim, H. & Liew, S.-L. A comparison of automated lesion segmentation approaches for chronic stroke t1-weighted MRI data. Hum. Brain Mapping 40, 4669–4685 (2019).
Zhang, R. et al. Automatic segmentation of acute ischemic stroke from DWI using 3-d fully convolutional densenets. IEEE Transac. Med. Imaging 37, 2149–2160 (2018).
Geirhos, R. et al. Shortcut learning in deep neural networks. Nat. Machine Intell. 2, 665–673 (2020).
STIR. http://stir.dellmed.utexas.edu/ (2021).
MRI Studio. https://www.mristudio.org (2021).
Hirte, A. U. et al. Realistic generation of diffusion-weighted magnetic resonance brain images with deep generative models. Magn. Reson. Imaging. 81, 60–66 https://doi.org/10.1016/j.mri.2021.06.001 (2021).
Fadnavis, S., Batson, J. & Garyfallidis, E. Patch2self: Denoising diffusion mri with self-supervised learning. Adv. neural information processing systems (2020).
Klambauer, G., Unterthiner, T., Mayr, A. & Hochreiter, S. Self-normalizing neural networks. in Proceedings of the 31st International Conference on Neural Information Processing Systems. (eds Guyon, I. et al.) 972–981 (2017).
Crum, W. R., Camara, O. & Hill, D. L. Generalized overlap measures for evaluation and validation in medical image analysis. IEEE Transac. Med. Imaging 25, 1451–1461 (2006).
Abadi, M. et al. TensorFlow: large-scale machine learning on heterogeneous systems. https://www.tensorflow.org/. Software available from tensorflow.org (2015).
Chollet, F. et al. Keras. https://github.com/fchollet/keras (2015).
nibabel. https://doi.org/10.5281/zenodo.41097916 (2020).
Virtanen, P. et al. SciPy 1.0: fundamental algorithms for scientific computing in Python. Nat. Methods 17, 261–272 (2020).
Garyfallidis, E. et al. Dipy, a library for the analysis of diffusion MRI data. Front. Neuroinform. 8, 8 (2014).
Van der Walt, S. et al. scikit-image: image processing in python. PeerJ 2, e453 (2014).
Pedregosa, F. et al. Scikit-learn: machine learning in python. J. Machine Learning Res. 12, 2825–2830 (2011).
iSchemaViewRAPID. http://www.i-rapid.com/home (2021).
Liu, C. F. & Faria, A. V. Acute-stroke detection segmentation (ADS). https://www.nitrc.org/projects/ads/ (2021).
Liu, C. F. & Faria, A. V. Acute-stroke detection segmentation (ADS). https://doi.org/10.5281/zenodo.5579390 (2021).
Acknowledgements
This research was supported in part by the National Institute of Deaf and Communication Disorders, NIDCD, through R01 DC05375, R01 DC015466, P50 DC014664 (A.H., A.V.F.), the National Institute of Biomedical Imaging and Bioengineering, NIBIB, through P41 EB031771 (M.I.M., A.V.F.), and the Department of Neurology, University of Texas at Austin, the National Institute of Neurological Disorders and Stroke, NINDS, National Institutes of Health, NIH (STIR/Vista Imaging Investigators).
Author information
Authors and Affiliations
Consortia
Contributions
A.V.F. and C.L. conceived and designed the study, analyzed, and interpreted the data, drafted the work. J.H., X.X., S.R., and V.W. analyzed the data. A.E.H. acquired part of the data and substantially revised the draft. M.I.M. revised the draft. The STIR and VISTA investigators provided part of the data.
Corresponding author
Ethics declarations
Competing interests
M.I.M. owns “AnatomyWorks”. This arrangement is managed by Johns Hopkins University in accordance with its conflict-of-interest policies. The remaining authors declare no competing interests.
Peer review information
Communications Medicine thanks King Chung Ho and the other, anonymous, reviewer(s) for their contribution to the peer review of this work. Peer reviewer reports are available.
Additional information
Publisher’s note Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Supplementary information
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons license, and indicate if changes were made. The images or other third party material in this article are included in the article’s Creative Commons license, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons license and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this license, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Liu, CF., Hsu, J., Xu, X. et al. Deep learning-based detection and segmentation of diffusion abnormalities in acute ischemic stroke. Commun Med 1, 61 (2021). https://doi.org/10.1038/s43856-021-00062-8
Received:
Accepted:
Published:
DOI: https://doi.org/10.1038/s43856-021-00062-8
This article is cited by
-
Modeling diffusion-weighted imaging lesion expansion between 2 and 24 h after endovascular thrombectomy in acute ischemic stroke
Neuroradiology (2024)
-
Artificial intelligence in neurology: opportunities, challenges, and policy implications
Journal of Neurology (2024)
-
Deep Learning for Perfusion Cerebral Blood Flow (CBF) and Volume (CBV) Predictions and Diagnostics
Annals of Biomedical Engineering (2024)
-
Automatic comprehensive aspects reports in clinical acute stroke MRIs
Scientific Reports (2023)
-
A large public dataset of annotated clinical MRIs and metadata of patients with acute stroke
Scientific Data (2023)
