
Abstract
Mobile sensing-based depression severity assessment could complement the subjective questionnaires-based assessment currently used in practice. However, previous studies on mobile sensing for depression severity assessment were conducted on homogeneous mental health condition participants; evaluation of possible generalization across heterogeneous groups has been limited. Similarly, previous studies have not investigated the potential of free-living audio data for depression severity assessment. Audio recordings from free-living could provide rich sociability features to characterize depressive states. We conducted a study with 11 healthy individuals, 13 individuals with major depressive disorder, and eight individuals with schizoaffective disorders. Communication logs and location data from the participants’ smartphones and continuous audio recordings of free-living from a wearable audioband were obtained over a week for each participant. The depression severity prediction model trained using communication log and location data features had a root mean squared error (rmse) of 6.80. Audio-based sociability features further reduced the rmse to 6.07 (normalized rmse of 0.22). Audio-based sociability features also improved the F1 score in the five-class depression category classification model from 0.34 to 0.46. Thus, free-living audio-based sociability features complement the commonly used mobile sensing features to improve depression severity assessment. The prediction results obtained with mobile sensing-based features are better than the rmse of 9.83 (normalized rmse of 0.36) and the F1 score of 0.25 obtained with a baseline model. Additionally, the predicted depression severity had a significant correlation with reported depression severity (correlation coefficient of 0.76, \(p<\)0.001). Thus, our work shows that mobile sensing could model depression severity across participants with heterogeneous mental health conditions, potentially offering a screening tool for depressive symptoms monitoring in the broader population.
Similar content being viewed by others

Introduction
Depression is the most common mental health disorder, affecting about 5% of adults worldwide1,2. It is associated with poor health outcomes, increased risk of self-harm, difficulties in work and relationships, etc3,4. A timely diagnosis and treatment monitoring through periodic depression severity assessment can help manage the health risks and associated burdens of depression. Currently, depression severity assessment is based on questionnaires with self-reporting of symptoms. Patient health questionnaire (PHQ-9)5 is one such questionnaire frequently used in practice. The nine-item PHQ-9 questionnaire is based on reporting symptoms specified in the DSM-IV (Diagnostic and Statistical Manual of Mental Disorders) for depression/major depressive disorder (MDD). The symptoms are feeling sad, losing interest in activities, appetite changes, suicidal thoughts, etc2. PHQ-9 assesses depression severity effectively and helps to monitor treatment outcomes5,6. However, like any questionnaire-based assessment, PHQ-9 relies on subjective reporting, which might suffer from recall bias or have under-reporting/over-reporting. An objective method for depression severity assessment could complement the questionnaire-based assessments, bypassing the recall bias and allowing more frequent assessments.
Mobile sensing, using sensors from smartphones and wearables, can infer behavioral manifestations of depression and provide a potential objective method for depression severity assessment. Altered sociability patterns implicated in depressive symptoms can be inferred using mobile sensing solutions such as communication logs of call/text7 or audio/RFID-based in-person interaction measurements8,9,10. Similarly, sleep-related behaviors, physical activities, ambulatory stress, eating behaviors, and mobility patterns can be inferred using sensors readily available in today’s smartphones and wearables11,12. Previous studies have demonstrated the feasibility of mobile sensing-based depression severity assessment 11,13,14. However, most of the studies were conducted on participants with homogeneous mental health conditions. For instance, several studies have focused on the student population where most participants had no or only mild depression13,14. The studies on clinical populations, on the other hand, often did not include healthy participants or participants with a different primary diagnosis than MDD15,16,17. Meta-analysis combining data and results from multiple studies could help fill the scarcity of studies on mobile sensing-based depression severity assessment in heterogeneous populations. Various meta-analyses have investigated mental health assessment, e.g., cognition assessment, across heterogeneous mental health conditions18. However, a meta-analysis of mobile sensing-based depression severity assessment studies has been largely missing. A review of previous studies identified several mobile sensing-based features that could be useful for depression severity assessment, considering the reported association across studies on different population groups19. However, the review points to the heterogeneity in feature types, study design differences, and data reporting variability as limitations to currently pursuing meta-analysis. A previous work based on reviews of mobile sensing-based depression severity assessment has suggested that non-clinical (healthy) and clinical populations might need different mobile sensing features for depression severity modeling. Thus, clinical and non-clinical populations should be analyzed separately20. However, the need to group into healthy and clinical populations before depression severity modeling would run counter to the usefulness of an objective depression severity assessment method as a possible primary diagnostic tool. The need to know grouping would also be prohibitive in a transdiagnostic use setting where depressive symptoms can pervade across different mental health conditions (i.e., envisioned groups) and individuals gradually remit or relapse into healthy/clinical groups21. A generalized mobile sensing-based depression severity modeling across heterogeneous mental health conditions would provide the true diagnostic and monitoring value in a transdiagnostic setting.
Two commonly used mobile sensing modalities for depression severity assessments are communication logs and location data20. These modalities can represent sociability and mobility behaviors implicated in depression, such as social isolation7,11,13,15. Recent advancements in free-living audio analysis have further facilitated social interaction inferences and sociability behavior characterization9. Previous studies have shown an association between depression severity and fine-grained sociability features from smartphone audio, wearable audio recorder, or RFID tags9,10,13. Social network size and social ambiance estimated from audio recordings of free-living were found to have a significant association with depression severity9,22. Similarly, RFID and audio-based measurements showed an association between dyadic interactions of free-living and depression severity10,23. However, it remains to be investigated if sociability features derived from in-person interactions can predict depression severity and complement the communication logs and location data-based features for the prediction. Several previous studies have investigated audio/speech-based depression severity assessment, primarily based on features of speech obtained under controlled lab conditions. For example, the response time of participants in interviews at the clinic was found to correlate significantly with depression severity24. Several acoustic and semantic features of speech have been associated with depression severity25. In the context of speech-based markers of depression severity established in these earlier studies, free-living audio provides an additional opportunity to obtain social functioning measures. Social functioning is an important factor in depression and several other health disorders26,27,28,29. Free-living audio also provides an opportunity to obtain speech-based markers of depression severity in free-living conditions, relieving the overhead of obtaining speech under controlled conditions..
Our goal in this study was two-fold. First, we aimed to investigate mobile sensing-based depression severity assessment in a diverse participant group comprising healthy individuals and individuals with depressive and psychotic disorders. Particularly, we aimed to examine if features obtained from the communication logs and location data can model depression severity assessed using the PHQ-9 score. Second, we aimed to evaluate whether audio-based sociability features complement the communication logs and location data-based features for depression severity assessment. In our analysis, several features obtained from the communication log and location data significantly correlated with depression severity. The mobile sensing-based depression severity assessment model had a low root mean squared error (rmse) of 6.07 (normalize rmse - nrmse of 0.22), compared to the rmse of 9.64 (nrmse of 0.36) with a baseline model. The predicted depression severity from the mobile sensing-based model significantly correlated with the reported depression severity of the participant (Pearson’s correlation coefficient of 0.76, \(p<\) 0.001). Audio modality complemented the conventional mobile sensing modalities of communication log and location data for depression severity prediction.
Results
We conducted a pilot study with 32 participants comprised of 13 healthy individuals (healthy group), 11 individuals with MDD (depression group), and eight individuals with schizoaffective disorders (psychosis group). Communication logs, location data, and continuous audio data of free-living were obtained from each participant using a wearable audioband over a monitoring period of one week. Participant’s depression severity was assessed using the PHQ-9 questionnaire.
We computed the Pearson’s correlation coefficient between the features obtained from the communication logs, location data, and the free-living audio data with the PHQ-9 sum score (depression severity). The result is shown in Table 1. Network size from text messaging logs (representing the number of unique contacts through text messaging), skewness and asymmetry coefficient of the call/text (capturing differences between the number of incoming and outgoing call/text), and normalized entropy from the location data (representing variability of visited locations) significantly correlated with depression severity. Higher depression severity was associated with a lower network size in text messaging-based communications (a significant negative correlation) and call-based communications (negatively correlated but insignificant). The skewness and asymmetry coefficient were positively correlated with depression severity, indicating that higher depression severity was associated with being more proactive (more outgoing calls and texts compared to incoming ones) in our study group. Conversational network size obtained from audio recordings of free-living, representing the average number of individuals the participant talked to on a day, was also significantly correlated with the participant’s depression severity. Higher depression severity was associated with a lower number of conversation partners assessed in free-living audio.
To better understand the mobile sensing-based features across participant groups, we analyzed the communication behavior and network size differences. The participants were stratified into two categories: reactive and proactive. The former had higher incoming calls/texts than outgoing, and the latter had higher outgoing than incoming, as defined in an earlier work characterizing phone-based communication patterns for depression severity modeling30. We observed both the reactive and proactive groups in our study, as shown in Figure 1. The psychosis group was more proactive than reactive. The healthy and depression groups, on the other hand, had a high percentage of groups’ members in both the reactive and proactive categories. While the communication log, capturing the call and text messaging information, provides an online social network size representation of an individual, the audio-based conversational network size provides in-person social network size. We compared the different network size representations from mobile sensing for the participant groups, as depicted in Fig. 2. The depression and psychosis group had a smaller network size in terms of their incoming or outgoing text messaging network, as well as their in-person conversational network sizes. The psychosis group, however, had a comparable network size as the healthy group in terms of their incoming or outgoing call network.

Number of daily incoming and outgoing calls and text messages for participants in our study. Reactive and proactive groups were present, defined as whether incoming or outgoing communication volume was higher. The label r/p above each participant’s incoming/outgoing plot indicates whether the participant was reactive or proactive. H, D, and P labels in the x-axis label of the figure indicate the group membership of each participant: healthy, depression, and psychosis respectively. Of the three participant groups, psychosis participants tended to be more proactive than reactive.

Incoming and outgoing network sizes of calls and text messages obtained from the communication log, and conversational network sizes obtained from the free-living audio for the healthy (H), depression (D), and psychosis (P) groups in our study. The depression group had a lower network size across text messaging, call, and in-person conversation modalities compared to the healthy group. The psychosis group had a lower network size than the healthy group for in-person conversations but a comparable or higher network size than the healthy group in their network size from call/text messaging data.
We obtained Pearson’s correlation coefficient between audio-based sociability features and the features from communication logs and location data to assess if the feature sets could be complementary. The result obtained is shown in Fig. 3. Only the conversational network size of the audio-based features significantly correlated with features from the communication log/location data.

Pearson’s correlation coefficient between audio-based features and the communication log/location data-based features. We analyzed the correlation to assess if audio-based features are independent of features from other commonly used mobile sensing modalities, suggesting likely complementarity since both feature sets are related to sociability behaviors. Only the conversational network size derived from audio significantly correlated with the entropy features from location data.
Given the correlations of mobile sensing features with depression severity and the feature differences across participant groups, we evaluated if mobile sensing features could predict depression severity. One of the aims of this study was to assess if audio-based sociability features complement the commonly used communication log/location data-based features for prediction. Thus, depression severity prediction in the following settings was evaluated:
-
Using features from the communication log and location data only (Model A)
-
Using audio-based sociability features only (Model B)
-
Using all features (communication log + location data features and audio-based sociability features) - Early fusion of Model A and Model B
-
Late fusion of prediction from Model A and Model B, obtained by averaging the predictions
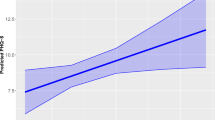
The prediction obtained from the abovementioned models in a leave-one-participant-out (LOPO) cross-validation is shown in Fig. 4. The models’ corresponding root mean squared error (rmse) and normalized rmse (nrmse) are given in Table 2. The nrmse is rmse normalized by the observed ranges of depression severity, as employed in previous works11. Communication log and location data-based depression severity prediction outperformed the baseline model. The baseline model provides the mean depression severity in the training set as its prediction. The simpler baseline helps assess whether mobile sensing has any predictive power for depression severity assessment. Similarly, adding audio-based sociability features further improved the model prediction. The model based on features from all modalities, i.e., communication log, location data, and audio, had a rmse of 6.02, nrmse of 0.22, and Pearson’s correlation coefficient of 0.76 (\(p<\)0.001) between reported and predicted depression severity.

Depression severity prediction from three different models: (i) using communication log and location data-based features only, (ii) using sociability features derived from audio only, and (iii) fusion model combining features from communication log, location data, and audio, (iv) fusion model combining predictions (averaging) from two models: model with communication log and location data-based features and model with audio-derived features.
Depression severity from the PHQ-9 score sum ranges from 0 to 27. The score is usually mapped into five categories of depression severity: 0–4 (none), 5–9 (mild), 10–14 (moderate), 15–19 (moderately severe), and 20–27 (severe). We also evaluated depression category prediction models predicting the depression severity category (classification problem instead of the regression problem). The classification performance obtained with different model settings (using different feature sets) is shown in Table 3. The classification model with all modalities, i.e., the communication log, location data, and audio-based features (Model C), had a higher F1 prediction score than models trained on these modalities individually or the baseline model. The F1 score for Model C was 0.46 (specificity of 0.76 and sensitivity of 0.46, weighted across class). In contrast, the model with features from the communication log and location data only, i.e., Model A, had an F1 score of 0.34 only (specificity of 0.77 and sensitivity of 0.34, weighted across class). The model with audio-based sociability features only (Model B) also had an F1 score of 0.34 (specificity of 0.82 and sensitivity of 0.30, weighted across class). The baseline model for prediction provided the dominant class in the training set as its prediction. The chosen ordinal logistic regression model resulted in a higher F1 score than the logistic regression model for classification. The latter does not acknowledge the ordinal relation between different depression categories.
A two-class depression detector (depression present or absent) could also be of clinical utility. Accordingly, we evaluated a two-class depression detector with the following criteria: depression present if the PHQ-9 score is greater or equal to 5. In this two-class classification setup, the F1 scores from Model A, Model B, and Model C were 0.50, 0.57, and 0.66, respectively, with the F1 score of a baseline classification model (always predicting the dominant class) being 0.42.
Discussion
Behavioral changes associated with depression can be inferred using mobile sensing based on sensors in smartphones or wearables. Thus, mobile sensing could aid depression severity assessment. In this work, we investigated mobile sensing-based depression severity assessment in a diverse participant group comprising healthy individuals and individuals with depressive and schizoaffective disorders. Three mobile sensing modalities were considered: communication log (call/text), location data, and free-living audio. As observed in previous studies7,11,15, several features from communication log and location data significantly correlated with depression severity in our study too (Table 1). Additionally, features from free-living audio also correlated significantly with depression severity and complemented other modalities to improve depression severity prediction.
Mobile sensing features are associated with depression severity across heterogeneous mental health conditions
Despite the heterogeneity in the mental health conditions of participants, several mobile sensing-based features significantly correlated with depression severity, showing the robustness of mobile sensing to represent depression severity across mental health conditions. In the communication log-based features, the network size of text messaging, i.e., the unique number of people one communicates with through text messaging, had a significant negative correlation with depression severity. In contrast, the network size of the call did not show a significant association with depression severity. The psychosis group, which exhibited higher depression severity than the healthy group in our study, had a lower text messaging-based network size but comparable call network size as the healthy group (Fig. 2), driving the low correlation between call network size and depression severity. An increased call activity, especially in the evening, was associated with increased psychotic symptoms in an earlier work too31. Thus, observing higher sociability behavior through increased phone calls could be a characteristic of the psychotic group despite higher depression severity. The difference in call network features for the depression and psychosis groups, with both groups exhibiting high depression severity, shows that heterogeneous groups should be considered to identify reliable features for the mobile sensing-based depression severity prediction model.
Besides the network size, the asymmetry in the incoming and outgoing communication, characterized by the asymmetry and skewness coefficients, significantly correlated with depression severity. In contrast to a previous study30, we observed a positive association (Table 1). Depressed individuals tended to have more outgoing calls/texts than incoming ones in our study group, while the opposite was reported in the previous study30. This discrepancy could be due to the duration of monitoring or the study group differences between ours and the previous study30. The previous study30 observed phone-based communication behaviors over multiple months in an older (geriatric) population. In comparison, our study had a monitoring period of a week. The asymmetry in phone-based communication could be different across different time scales of evaluation and needs further investigation. The PHQ-9 questionnaire used to assess depression severity asks to reflect on one’s behavior over the past two weeks. Therefore, feature dynamics in weeks might be more suited when considering depression severity prediction. Long-term behavioral patterns could reflect one’s nature/personality rather than behavioral patterns in light of symptom changes. Similarly, the psychosis group in our study, which was not included in the previous study30, had higher communication log activities despite higher depression severity, which might have led to differing communication behaviors and asymmetry patterns as a function of depression severity in our study. The discrepancy of observations in our work compared to previous observations that did not include heterogeneous groups further highlights the need to include heterogeneous groups to discover robust mobile sensing-based features and depression severity relations.
From the location data, the normalized entropy had a significant negative correlation with depression severity. This finding aligns with observations in earlier studies11 and the consensus across multiple studies that entropy is reduced with depression severity20. However, a large-scale study observed that location data-based features for depression prediction do not scale to the general population32. The association of location-based features to depression severity could be specific to a particular study group, dictated by a study site’s mobility patterns, infrastructure, or cultural inclinations. Further studies across multiple sites, regions, populations, age groups, etc., would elucidate the robustness of location data-based feature’s relation to depression severity.
In terms of depression severity prediction, our results are comparable to earlier works that evaluated patient-independent models (using a leave-one-participant-out model). For example, our reported nrmse of 0.25 with communication log and location data-based features only for depression severity prediction matches the reported nrmse of 0.25 in a previous work11, despite our study including a diverse participant group representing different mental health conditions. Our work shows that mobile sensing-based features could potentially model depression severity even in heterogeneous groups.
Free-living audio-based features complement other mobile sensing modalities to model depression severity
With the addition of audio-based features for depression severity prediction, we reduced the rmse of prediction from 6.80 to 6.07. The corresponding nrmse of 0.22 is lower than the nrmse of 0.25 reported in earlier work11 that did not employ audio-based modalities. We also obtained better prediction of depression severity category when audio-based sociability features were included(Table 1, 3 Fig. 4). Some representation of audio-based sociability features could be obtained from communication logs or location-based features. For example, the conversational network size inferred from the audio was significantly correlated with the location-based entropy feature, as seen in Fig. 3. Conceptually, higher entropy in location data is associated with more variability in one’s location. This variability could be linked with meeting new people and, thus, higher conversational network size. Still, some aspect of one’s sociability relevant for depression severity is uniquely captured from free-living audio as demonstrated by the reduced rmse in depression severity prediction and increased accuracy of depression category prediction. Audio-based sociability features are thus complementary to communication log and location data commonly employed to model depression severity.Improved depression severity prediction with multimodal features could facilitate a depression screening tool for a broader population as the depression severity prediction model is validated in a heterogeneous participant group, as pursued in our work. However, our work only considered a cross-sectional study design. Future work should also investigate the value of mobile sensing technology for longitudinal monitoring of depression severity changes within a participant.
Previous studies usually report the F1 score of depression classification in a binary classification setting. The F1 score for the binary depression classification (depression absent or present) was 0.66 in our classification pipeline. In previous work on mobile sensing-based binary depression classification33, an F1 score of 0.77 was reported. However, the authors binarized depression severity with only the moderate and severe depression categorized as depression category. In a similar categorization, we also obtain an F1 score of 0.77 for classification, indicating the competitiveness of our classification pipeline despite participant heterogeneity. Similar F1 scores of classification were reported in other studies on student population31,34. Yet, there are also other studies reporting F1 scores ranging from a low value of 0.62 to a high value of 0.8234. The broad range of F1 scores reported in previous work indicates that further understanding of mobile sensing’s capability to predict depression in different population characteristics needs further investigation.
Limitations
A limitation of our study, shared by other earlier related works on mobile sensing-based depression severity assessment7,11,15, is the smaller number of participants. A larger study with more participants and extended monitoring would further validate mobile sensing-based depression severity assessment models. The results from our pilot are encouraging to pursue such larger studies in the future. Some earlier studies have noted that mobile sensing-based depression severity assessment might not scale to a larger population32. The observations from our study might not translate across different regions, cultures, or settings where different sociability and mobility patterns might exist. A multi-site study and features invariant to confounding variables such as locality, culture, etc., could help improve generalizability and should be investigated in future studies. Meta-analysis of results from multiple studies could also help answer questions regarding the generalizability of mobile sensing-based depression severity prediction across different populations.
In this work, we evaluated only limited features characterizing the mobile sensing data. The features were manually computed (handcrafted) based on the observations in the previous works7,11,15,30. We did not pursue feature engineering or the exploration of new features due to the small study size. Previous works have shown that end-to-end models with automatic feature/representation learning could complement or outperform handcrafted features in mobile sensing-based prediction tasks35,36. Such representation learning-based approach can also use ordinal losses for training37, the training property that was found helpful from our classification experiments (Table 3). This work did not explore representation learning approaches, e.g., using deep learning models, because of the limited dataset size. We will seek further feature exploration and end-to-end prediction models with automatic representation learning in future studies with a larger participant group or by pooling data from multiple existing studies. New features identification in future studies should also explore alternative sensing modalities, such as non-contact sensing38,39 in home-based monitoring setup, to understand how a broader sensing modality compares for mental health applications.
Continuous audio-based monitoring could raise ethical and privacy concerns as the technology can be considered intrusive. We designed a privacy-preserving speech processing pipeline that did not infer any spoken content for the analysis presented in this work. The participants also had high acceptability of the technology and raised no concerns about audio-based monitoring technology. Despite the care taken in our study design and execution, the scalability of the audio-based monitoring solution could be a limitation and needs further consideration in future work. For example, future work should investigate the general acceptability of audio-based technology on a broader population. The current study was executed in a single site and the observed acceptability could be biased. Similarly, future work should investigate how features informative to mental health could be inferred without violating privacy concerns. Previous studies have shown how speech’s emotional and semantic content has relevance in mental health prediction tasks40. However, extracting this rich feature space could also mean more privacy-sensitive information is obtained. Privacy and ethical considerations of audio-derived features should be investigated in parallel with further technical advancements for better mental health monitoring technologies.
Another limitation shared by mobile sensing-based depression modeling studies, including our study, is that various confounding factors apart from depression severity could affect mobile sensing features. The effects of confounding factors could be severe in cross-sectional modeling studies. For example, communication log-based features such as number of calls/texts or network size could differ widely across participants irrespective of their underlying depression severity. Features such as asymmetry and skewness coefficient used in our work avoid the issue by considering the intra-individual differences only. Asymmetry and skewness coefficients use the normalized difference between incoming and outgoing communications. The non-normalized features (i.e., those considering absolute and not relative values), such as the number of calls/texts and network sizes, were still found to be significantly correlated with depression severity7,15,20,41, even when no possible inter-individual factors influencing these features are accounted. As most studies on mobile sensing-based depression assessment are single-site, it could be the case that absolute values communication volume or network sizes are still comparable across the participants. Besides multi-site large-scale studies, longitudinal studies in the future could evaluate the predictive power of mobile sensing-based features for modeling depression severity changes within an individual.
Conclusion
Our work shows that mobile sensing provides a potential objective depression severity assessment method across heterogeneous mental conditions. The audio modality complements commonly used mobile sensing modalities of phone communication logs and location data for depression severity prediction and thus should be considered in future mobile sensing solutions. Our work provides a step towards a scalable solution to diagnose and monitor depressive symptoms across cross-sectional populations. Future studies should further assess mobile sensing-based depression severity assessment in a larger population and a longitudinal monitoring setting.
Methods
Dataset
We conducted a pilot study with 32 participants (average age: 45.2 ± 13.6 years, 19 female/13 male) consisting of the following group: (i) 11 healthy participants, (ii) 13 participants diagnosed with major depressive disorders, and (iii) eight participants with schizoaffective disorders. We pursued a cross-sectional observational study for the pilot to understand if features derived from objective measurement could model depression severity across individuals with heterogeneous mental health conditions. The cohort of healthy participants was age-matched with the cohort of participants with mental health disorders. The participants with mental health disorders were all stable for outpatient management so that their natural behavior in free-living would be captured during the monitoring period. The participants were racially and ethnically diverse. 50% of participants were Black or African American, 21.88% were Hispanic, and 18.75% were white. The study was approved by the Institutional Review Boards at Rice University, Baylor College of Medicine, and Harris Health Systems (protocol No. H-41811). The study was performed in accordance with the relevant guidelines and regulations for studies involving human subjects. All participants provided written informed consent for the study. The participant group and the data collected from each participant are shown in Fig. 5. We obtained the communication logs (call and text messaging information) and location data (GPS coordinates) from each participant for a monitoring period of a week. The data was obtained using a smartphone application developed in our previous mobile sensing-based studies7,15. We also obtained continuous audio recordings of free-living from each participant during the monitoring period. The recordings were obtained using a wearable audioband that the participants wore throughout the day. The audioband had enough memory to store the audio data from the monitoring period. We assessed the participant’s depression severity with the patient health questionnaire-9 (PHQ-9)5.

A pilot sociability study in a diverse participant group comprising of healthy individuals and individuals with depressive and schizoaffective disorders. Communication logs and location data (GPS) were obtained from each participant’s smartphone. We also obtained continuous audio recordings using a wearable audioband during the day.
Mobile sensing-based sociability and mobility features
We processed the communication logs, location data, and the free-living audio data to compute features representing the sociability and mobility behaviors of the participants.
Communication log-based features
The smartphone application developed for the study logged incoming and outgoing calls on the participants’ phones during the monitoring period. Only the call origin time and the duration of the calls were logged. Similarly, all the incoming and outgoing text messages were also logged with timings. The phone number associated with incoming/outgoing calls/texts was one-way hashed for privacy. The call and text messages could also be jointly viewed as a single phone communication modality. Accordingly, we computed features from three phone communication-based modalities: calls, text messages, and the combined call+text modality.
The number of daily calls and text messages have been used as possible features correlated with depression severity scores in previous works7,15,41. Accordingly, we considered the absolute volume of communication as one of the features. The network size features are computed as the number of unique individuals connected over calls or text messages on a given day. A higher network size, in general, indicates a wider social network of an individual.
Besides the communication volume, the relative differences between the number of incoming and outgoing communications could also be relevant to represent depression-related behaviors30. The asymmetry and skewness coefficients characterize this difference between the number of incoming and outgoing communications and have been associated with depression severity in an earlier study30.
The asymmetry coefficient (AC) is defined as:
, Similarly, the skewness coefficient (SC) is defined as: \(SC=sign(out-in) (1-H(out,in))\), where H(out, in) is the Shannon entropy defined as:
We calculated the following five features from each modality:
-
Average daily number of communications (calls/texts/call+text)
-
Asymmetry coefficient
-
Skewness coefficient
-
Average network size for daily incoming communications
-
Average network size for daily outgoing communications
As the duration information was also available for each call, we computed the average call duration per day as an additional feature. Thus, 16 features are calculated from the communication logs - five features from the call, text messages, and call+text modality each, with an additional average call duration feature.
Mobility features from the location data
Based on the observation in previous studies11,16, we computed mobility features from the GPS logs recorded by the study smartphone application. The mobility features characterized the total movement of the participants and the variability of their movement patterns. The GPS logs were obtained for 19 of the participants. The GPS logs were processed using the typical processing steps to get mobility features as in previous works7,11,32.
First, the movement speed for each GPS datapoint was estimated using distance and time elapsed compared to the previous measurement. We used Vincenty’s formula42 to compute distance from GPS coordinates. Mobility feature calculations from GPS require identifying stationary and transitional periods (higher instantaneous speed periods indicating the person might be commuting, e.g., driving)11,16,32. We used the speed threshold of 1.4m/s, as proposed in earlier work32 based on a person’s walking speed, to identify all the stationary points in the GPS log. As one mobility feature, the average distance traveled in a day, the sum of distances for each stationary point in a day normalized by the number of monitoring points, was computed. The location variance for the monitoring period was also computed, which is defined as \(log(\sigma _{latitude}^2 + \sigma _{longitude}^2)\) as used in previous studies7,11,32. Similarly, we obtained other mobility features based on location clustering. First, all the GPS data points of the stationary period were clustered using DBSCAN, as employed in previous work32. From the identified clusters, cluster entropy was computed as \(entropy=-\sum _{i=1}^{k}t_i(log(t_i))\), where k is the number of location clusters identified and \(t_i\) is the time the participant spends in a given cluster i. Then, the normalized cluster entropy feature was computed as: \(normalized\ entropy = \frac{entropy}{log(k)}\)
Thus, the following features characterized the participant’s mobility during the study period:
-
Average distance traveled per day
-
Location variance (\(log(\sigma _{latitude}^2 + \sigma _{longitude}^2)\))
-
Normalized cluster entropy (\(\frac{-\sum _{i=1}^{k}t_i(log(t_i))}{log(k)}\), k : number of location clusters; \(t_i:\) time spent in a cluster i)
Sociability features from continuous free-living audio
Sociability features are implicated in depression and other health disorders43,44,45. One sociability feature commonly assessed in relation to mental health is one’s social network size, the total number of individuals - friends, co-workers, relatives, etc. - with which one communicates regularly and seeks advice or help. We computed various sociability features from free-living audio using a deep neural network-based architecture, ECoNet9.
The processing steps used in ECoNet are shown in Figure 6. ECoNet first identifies all the speech segments in an audio recording using a voice activity detector (VAD). The VAD used is a PyanNet architecture-based neural network model46, which identifies a speech segment based on the frequency spectrum of the audio segment. The speech segments are then clustered in an unsupervised setting. For this, ECoNet transforms speech segments into speaker embeddings using a neural network trained to identify speakers. The embedding generation network is a time-delay neural network model47 trained using a public dataset consisting of speech samples from thousands of speakers48. The embeddings of speech segment are a fixed dimensional vector, the activations in the penultimate layer of the trained embedding generation network, for the input speech sample. Embeddings from the same speakers (even if unseen by the network) are closer, and those from different speakers are farther apart. With the unsupervised clustering of speech segments, each speech segment is assigned a unique speaker label. ECoNet has a random forest-based machine learning model to detect spurious speaker labeling arising in noisy/unconstrained recordings of free-living. Similarly, it has a speaker tracking mechanism to identify the same speaker across different hours and days in a multi-day audio recording.

Audio processing steps used in ECoNet to infer speakers and their associated speech segment. The processing from ECoNet can be used to infer sociability features such as conversational network size, nature of interactions, etc.
A multi-day audio recording labeled with ECoNet, with each speech segment assigned a speaker label, can be used to extract the sociability features of the individual. Conversational network size, for example, could be a proxy of social network size or sociability associated with depression severity9. Similarly, the top speakers’ speech duration is another possible sociability feature, obtained as the speech duration of the two most frequent speakers (\(t_{top-2-speakers-speech}\)) normalized by total speech encountered (\(t_{total-speech}\)). The top speakers’ speech duration characterizes the dyadic nature of interactions and relates to depression severity since depressed individuals are more likely to have dyadic interactions9,10. The time taken to respond to conversations in a dyadic interaction could also characterize interaction type or the psychomotor retardation relevant for depression severity assessment23. Previous studies only investigated the correlation of the audio-based sociability features with depression severity9,23. This work assessed the predictive capability of audio-based sociability features for depression severity assessment. We evaluated whether audio-based sociability features complement the commonly used communication log and location data-based features in predicting depression severity. The free-living audio was processed to extract the following audio-based sociability features:
-
conversational network size
-
top speakers’ speech ratio (\(\frac{t_{top-2-speakers-speech}}{t_{total-speech}}\))
-
response time in dyadic interaction
Depression severity prediction model
We evaluated communication logs and location data-based features in a depression severity prediction model. The possible complementary nature of sociability features from free-living audio to improve depression severity prediction was also assessed. The depression severity prediction model was based on a linear regression model with L2 regularization(ridge regression)11. The linear model was chosen because of the model simplicity, as the training dataset is simple. The regularization helps address possible overfitting when the feature set is large, e.g., when features from different modalities are fused. We evaluated the model in a leave-one-participant-out (LOPO) cross-validation setting so that the training set is completely independent of the participant in the test set. The prediction model was evaluated with different feature sets but always operated in the \(p<n\) regime, i.e., the number of features was less than the number of observations, irrespective of the feature set used. The features computed from each modality were already guided based on the observation from earlier studies that investigated the association of the features from the modalities of communication log, location data, and audio with depression severity7,9,11,30. Even when all modalities were used (the largest feature set possible), the number of features was still less than the number of observations. No feature selection approaches were used, but rather, we relied on the model regularization to account for larger feature sets. We used the ridge regression implementation in the scikit-learn library. The value of the regularization weight (\(\alpha \)) was obtained with cross-validation within the training set - training set, validation set (used for parameter evaluation), and the test set were non-overlapping. The depression severity prediction model using the mobile sensing feature was compared with a baseline model that provides the mean depression severity score of the training set as its prediction in the cross-validation evaluation. The models were evaluated on 26 participants with both communication logs and audio data available. Among these participants, only 19 participants had the location data. The missing location data-based features were imputed using the k-nearest neighbor imputer (k=3) trained in the training set within the cross-validation loop. The k-nearest neighbor imputer imputes the data based on the closest participants to a given participant in the feature space for available modalities who likely share similar behavioral characteristics in the missing modality space, too. Imputation using k-nearest neighbor has been used in previous mobile sensing-based studies49 and outperformed alternate approaches using mean and median imputation in our dataset (Supplementary Table S-III). We evaluated the depression severity prediction model using the root mean squared error metric (rmse). The prediction obtained for different participants in the test set across cross-validation runs were pooled to compute the rmse metric. Normalized rmse (nrmse) was also calculated by normalizing the rmse with the observed range of target labels, i.e., depression severity, as employed in previous work11.
The depression severity represented by the PHQ-9 score maps into five depression severity categories, namely none, mild, moderate, moderately-severe, severe. We also trained a depression category classification model, predicting the depression severity categories instead of the raw PHQ-9 scores, using various feature sets. We used an ordinal logistic regression model (OrdLogReg)50 as a classifier since the five depression categories have ordinal relations. For example, the mild depression class is closer to none depression class than it is to the severe depression class. The OrdLogReg model uses the natural order of the classes for prediction. The all-threshold variant of the OrdLogReg model was used, which has been shown to outperform the alternative immediate-threshold variant50. We also evaluated a logistic regression (LogReg) with \(L_2\) loss as a classifier to assess the need for ordinal modeling. The LogReg model uses logistic loss on the affine mapping of predictors in a multinomial setting to predict the probability of the class without forcing an ordinal relation between the classes. In contrast, the OrdLogReg model uses a penalty term based on how far the predicted affine mapping lies from the learned threshold defining the region of an ordinal class, with a non-linearly increasing penalty for classes that are further apart50. Our baseline model for the depression category classification model always predicts the most dominant class in the training set. The prediction performance of the models was evaluated using the F1 score, with the weighted averaging across the classes (scikit-learn library in Python). We chose the F1 score rather than accuracy since the classes were imbalanced.
Data availability
The features and codes used for the analysis have been made available in the following GitHub repository: https://github.com/lbishal/mobilesensing. Raw data logs are not available due to possible privacy violations. Corresponding author Bishal Lamichhane can be contacted at bishal.lamichhane@rice.edu for any data-related queries.
References
Vos, T. et al. Global, regional, and national incidence, prevalence, and years lived with disability for 301 acute and chronic diseases and injuries in 188 countries, 1990–2013: A systematic analysis for the global burden of disease study 2013. Lancet 386, 743–800 (2015).
Evans-Lacko, S. et al. Socio-economic variations in the mental health treatment gap for people with anxiety, mood, and substance use disorders: results from the who world mental health (wmh) surveys. Psychol. Med. 48, 1560–1571 (2018).
Keenan-Miller, D., Hammen, C. L. & Brennan, P. A. Health outcomes related to early adolescent depression. J. Adolesc. Health 41, 256–262 (2007).
Haw, C., Houston, K., Townsend, E. & Hawton, K. Deliberate self harm patients with depressive disorders: Treatment and outcome. J. Affect. Disord. 70, 57–65 (2002).
Kroenke, K., Spitzer, R. L. & Williams, J. B. The phq-9: Validity of a brief depression severity measure. J. Gen. Intern. Med. 16, 606–613 (2001).
Lowe, B., Unutzer, J., Callahan, C. M., Perkins, A. J. & Kroenke, K. Monitoring depression treatment outcomes with the patient health questionnaire-9. Med. Care 42, 1194–1201 (2004).
Cao, J. et al. Tracking and predicting depressive symptoms of adolescents using smartphone-based self-reports, parental evaluations, and passive phone sensor data: Development and usability study. JMIR Mental Health 7, e14045 (2020).
Xu, C. et al. Crowd++ unsupervised speaker count with smartphones. In: Proc. 2013 ACM international joint conference on Pervasive and ubiquitous computing, 43–52 (2013).
Lamichhane, B., Moukaddam, N., Patel, A. B. & Sabharwal, A. Econet: Estimating everyday conversational network from free-living audio for mental health applications. IEEE Pervasive Comput. 21, 32–40 (2022).
Elmer, T. & Stadtfeld, C. Depressive symptoms are associated with social isolation in face-to-face interaction networks. Sci. Rep. 10, 1444. https://doi.org/10.1038/s41598-020-58297-9 (2020).
Saeb, S. et al. Mobile phone sensor correlates of depressive symptom severity in daily-life behavior: An exploratory study. J. Med. Internet Res. 17, e175 (2015).
Smets, E. et al. Large-scale wearable data reveal digital phenotypes for daily-life stress detection. NPJ Digit. Med. 1, 67 (2018).
Wang, R. et al. Studentlife: assessing mental health, academic performance and behavioral trends of college students using smartphones. In: Proc. 2014 ACM international joint conference on pervasive and ubiquitous computing, 3–14 (2014).
Wang, R. et al. Tracking depression dynamics in college students using mobile phone and wearable sensing. Proc. ACM Interact. Mob. Wear. Ubiquitous Technol. 2, 1–26 (2018).
Moukaddam, N., Truong, A., Cao, J., Shah, A. & Sabharwal, A. Findings from a trial of the smartphone and online usage-based evaluation for depression (solvd) application: What do apps really tell us about patients with depression? concordance between app-generated data and standard psychiatric questionnaires for depression and anxiety. J. Psychiatr. Pract. 25, 365–373 (2019).
Cao, J. Objective Sociability Measures from Multi-modal Smartphone data and Unconstrained Day-long Audio Streams (Rice University, 2019).
Pedrelli, P. et al. Monitoring changes in depression severity using wearable and mobile sensors. Front. Psychiatry 11, 584711 (2020).
Lavigne, K. M. et al. Remote cognitive assessment in severe mental illness: A scoping review. Schizophrenia 8, 14 (2022).
De Angel, V. et al. Digital health tools for the passive monitoring of depression: A systematic review of methods. NPJ Digit. Med. 5, 3 (2022).
Rohani, D. A., Faurholt-Jepsen, M., Kessing, L. V. & Bardram, J. E. Correlations between objective behavioral features collected from mobile and wearable devices and depressive mood symptoms in patients with affective disorders: systematic review. JMIR Mhealth Uhealth 6, e9691 (2018).
Dalgleish, T., Black, M., Johnston, D. & Bevan, A. Transdiagnostic approaches to mental health problems: Current status and future directions. J. Consult. Clin. Psychol. 88, 179 (2020).
Chen, W., Sabharwal, A., Taylor, E., Patel, A. B. & Moukaddam, N. Privacy-preserving social ambiance measure from free-living speech associates with chronic depressive and psychotic disorders. Front. Psych. 12, 670020 (2021).
Lamichhane, B., Moukaddam, N., Patel, A. B. & Sabharwal, A. Dyadic interaction assessment from free-living audio for depression severity assessment. In: INTERSPEECH (2022).
Yamamoto, M. et al. Using speech recognition technology to investigate the association between timing-related speech features and depression severity. PLoS ONE 15, e0238726 (2020).
Cummins, N. et al. A review of depression and suicide risk assessment using speech analysis. Speech Commun. 71, 10–49 (2015).
Bell-Dolan, D. J., Reaven, N. M. & Peterson, L. Depression and social functioning: A multidimensional study of the linkages. J. Clin. Child Psychol. 22, 306–315 (1993).
Hirschfeld, R. et al. Social functioning in depression: A review. J. Clin. Psychiatry 61, 268–275 (2000).
Kennedy, D. P. & Adolphs, R. The social brain in psychiatric and neurological disorders. Trends Cogn. Sci. 16, 559–572 (2012).
Alegría, M., NeMoyer, A., Falgàs Bagué, I., Wang, Y. & Alvarez, K. Social determinants of mental health: Where we are and where we need to go. Curr. Psychiatry Rep. 20, 1–13 (2018).
Aubourg, T., Demongeot, J., Renard, F., Provost, H. & Vuillerme, N. Association between social asymmetry and depression in older adults: A phone call detail records analysis. Sci. Rep. 9, 1–10 (2019).
Wang, R. et al. Predicting symptom trajectories of schizophrenia using mobile sensing. Proc. ACM Interact. Mob. Wear. Ubiquitous Technol. 1, 1–24 (2017).
Muller, S. R., Chen, X. L., Peters, H., Chaintreau, A. & Matz, S. C. Depression predictions from gps-based mobility do not generalize well to large demographically heterogeneous samples. Sci. Rep. 11, 1–10 (2021).
Lu, J. et al. Joint modeling of heterogeneous sensing data for depression assessment via multi-task learning. Proc. ACM Interact. Mob. Wear. Ubiquitous Technol. 2, 1–21 (2018).
Chikersal, P. et al. Detecting depression and predicting its onset using longitudinal symptoms captured by passive sensing: A machine learning approach with robust feature selection. ACM Trans. Comput.-Hum. Interact. (TOCHI) 28, 1–41 (2021).
Chieregato, M. et al. A hybrid machine learning/deep learning covid-19 severity predictive model from ct images and clinical data. Sci. Rep. 12, 4329 (2022).
Lamichhane, B., Zhou, J. & Sano, A. Psychotic relapse prediction in schizophrenia patients using a personalized mobile sensing-based supervised deep learning model. IEEE J. Biomed. Health Inform. 27, 3246–57 (2023).
Zhang, S., Yang, L., Mi, M. B., Zheng, X. & Yao, A. Improving deep regression with ordinal entropy. Preprint at arXiv:2301.08915 (2023).
Schultebraucks, K., Yadav, V., Shalev, A. Y., Bonanno, G. A. & Galatzer-Levy, I. R. Deep learning-based classification of posttraumatic stress disorder and depression following trauma utilizing visual and auditory markers of arousal and mood. Psychol. Med. 52, 957–967 (2022).
Ma, C. et al. Tremor detection transformer: An automatic symptom assessment framework based on refined whole-body pose estimation. Eng. Appl. Artif. Intell. 125, 106645 (2023).
Cummins, N., Epps, J., Breakspear, M. & Goecke, R. An investigation of depressed speech detection: Features and normalization. Proceedings of the Annual Conference of the International Speech Communication Association, INTERSPEECH 2997–3000 (2011).
Razavi, R., Gharipour, A. & Gharipour, M. Depression screening using mobile phone usage metadata: A machine learning approach. J. Am. Med. Inform. Assoc. 27, 522–530 (2020).
Vincenty, T. Direct and inverse solutions of geodesics on the ellipsoid with application of nested equations. Surv. Rev. 23, 88–93 (1975).
Brinkhues, S. et al. Socially isolated individuals are more prone to have newly diagnosed and prevalent type 2 diabetes mellitus-the maastricht study-. BMC Public Health 17, 1–12 (2017).
Santini, Z. I. et al. Social disconnectedness, perceived isolation, and symptoms of depression and anxiety among older americans (nshap): A longitudinal mediation analysis. Lancet Public Health 5, e62–e70 (2020).
Gianfredi, V. et al. Association between social network characteristics and prevalent and incident depression: The maastricht study. J. Affect. Disord. 293, 33846 (2021).
Bredin, H. et al. Pyannote. audio: Neural building blocks for speaker diarization. In ICASSP 2020–2020 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP) (ed. Bredin, H.) 7124–7128 (IEEE, 2020).
Snyder, D., Garcia-Romero, D., Sell, G., Povey, D. & Khudanpur, S. X-vectors: Robust dnn embeddings for speaker recognition. In: 2018 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), 5329–5333, https://doi.org/10.1109/ICASSP.2018.8461375 (2018).
Chung, J. S., Nagrani, A. & Zisserman, A. Voxceleb2: Deep speaker recognition. CoRR abs/1806.05622 arXiv: 1806.05622 (2018).
Pires, I. M., Hussain, F., Marques, G. & Garcia, N. M. Comparison of machine learning techniques for the identification of human activities from inertial sensors available in a mobile device after the application of data imputation techniques. Comput. Biol. Med. 135, 104638 (2021).
Rennie, J. D. & Srebro, N. Loss functions for preference levels: Regression with discrete ordered labels. In: Proc. IJCAI multidisciplinary workshop on advances in preference handling, vol. 1 (Citeseer, 2005).
Author information
Authors and Affiliations
Contributions
N.M. and A.S. conceived and conducted the experiment(s). B.L. curated the dataset, wrote the analysis codes, and developed the prediction models. All authors analyzed the results. B.L. prepared the first draft of the paper and all authors reviewed the manuscript.
Corresponding author
Ethics declarations
Competing interests
The authors declare no competing interests.
Additional information
Publisher's note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Supplementary Information
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution-NonCommercial-NoDerivatives 4.0 International License, which permits any non-commercial use, sharing, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if you modified the licensed material. You do not have permission under this licence to share adapted material derived from this article or parts of it. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by-nc-nd/4.0/.
About this article

Cite this article
Lamichhane, B., Moukaddam, N. & Sabharwal, A. Mobile sensing-based depression severity assessment in participants with heterogeneous mental health conditions. Sci Rep 14, 18808 (2024). https://doi.org/10.1038/s41598-024-69739-z
Received:
Accepted:
Published:
DOI: https://doi.org/10.1038/s41598-024-69739-z
Keywords
Comments
By submitting a comment you agree to abide by our Terms and Community Guidelines. If you find something abusive or that does not comply with our terms or guidelines please flag it as inappropriate.
