
Abstract
This article introduces an adaptive approach within the Bayesian Max-EWMA control chart framework. Various Bayesian loss functions were used to jointly monitor process deviations from the mean and variance of normally distributed processes. Our study proposes the mechanism of using a function-based adaptive method that picks self-adjusting weights incorporated in Bayesian Max-EWMA for the estimation of mean and variance. This adaptive mechanism significantly enhances the effectiveness and sensitivity of the Max-EWMA chart in detecting process shifts in both the mean and dispersion. The Monte Carlo simulation technique was used to calculate the run-length profiles of different combinations. A comparative performance analysis with an existing chart demonstrates its effectiveness. A practical example from the hard-bake process in semiconductor manufacturing is presented for practical context and illustration of the chart settings and performance. The empirical results showcase the superior performance of the Adaptive Bayesian Max-EWMA control chart in identifying out-of-control signals. The chart’s ability to jointly monitor the mean and variance of a process, its adaptive nature, and its Bayesian framework make it a useful and effective control chart.
Similar content being viewed by others
Introduction
Statistical process control (SPC) is a field dedicated to maintaining and enhancing the quality of products and processes. It provides a systematic structure that helps in monitoring and controlling the different process variations. Control charts, a basic but powerful tool in SPC, were introduced by Shewhart1. Control charts are used to identify the common causes and special causes present in the process. Shewhart control charts are widely used to monitor the shifts in the process mean. However, the Shewhart chart has limitations in detecting minor or gradual process parameter shifts. To address this, the Exponentially Weighted Moving Average (EWMA) chart assigns greater weights to recent data, increasing sensitivity to subtle mean shifts. Conversely, the Cumulative Sum (CUSUM) chart excels at swiftly detecting abrupt changes, responding to both magnitude and direction. These charts were introduced by Page2 and Robert3. Early control charts focused on single characteristics, but real-world quality standards often demand monitoring of both mean and variance. In practice, processes often exhibit simultaneous variations in mean and variance. Researchers have devised joint monitoring approaches to meet this need. Gan4 pioneered a joint monitoring scheme and later Chen and Cheng5 introduced the widely adopted Max chart, selecting the maximum absolute value from normalized mean and variance statistics. Chen et al.6 incorporated the Max approach with EWMA for joint detection of mean and variance Haq et al.7, Sanusi et al.8, and Chatterjee et al.9 proposed various joint monitoring schemes based on EWMA, CUSUM, and multivariate control charts. Jalilibal et al.10 conducted a comprehensive literature review on joint control schemes, highlighting the importance of developing effective and easy-to-use schemes. Joint monitoring schemes for statistical process monitoring remain in the limelight due to their ability to detect changes in both the process mean and dispersion.
The necessity for an adaptive approach in joint monitoring control charts stems from the dynamic nature of contemporary industrial processes. They adjust control limits based on observed data, making them more responsive to process changes. Capizzi and Masarotto11 introduced an adaptive approach in EWMA control charts for monitoring processes that exhibit time-varying behavior. Various researchers have worked to make different improvements in adaptive approach. Lee and Lin12 offered adaptive Max charts for monitoring the process mean and variability. Huang et al.13 evaluate the performance of the adaptive chart with classical charts. Abbas et al.14 introduce novel EWMA and CUSUM control charts using sign test statistic and arcsine transformation, demonstrating their performance under in-control and out-of-control processes via Monte Carlo simulation, revealing robustness against non-normality, with sign test statistic effective for small shifts and arcsine transformation for medium to large shifts, applied and assessed using artificial dataset. Abbas et al.15 introduce the PAEWMA chart, analyzing its performance under steady-state and zero-state conditions for detecting unknown shifts, comparing it with existing schemes using run-length profiles and quadratic loss measures, highlighting the superior performance of PAEWMA under steady-state conditions, and demonstrating its applicability across artificial, past study, and aircraft accident monitoring datasets. Ugaz et al.16 proposed adaptive EWMA charts with time-varying smoothing parameters. Nazir et al.17 proposed robust adaptive EWMA charts for manufacturing processes to detect outliers and non-normality. Haq and Razzaq18 offered maximum weighted adaptive CUSUM charts for combined monitoring of multiple processes. Sarwar and Noor-ul-Amin19 proposed a new adaptive EWMA chart by incorporating a hybrid approach to monitor small and moderate shifts. These studies on adaptive control charts show its acceptance in a wide range of applications. In recent years, the usage of the Bayesian approach in the construction of control charts has drawn significant attention. This is due to the fact that Bayesian methods provide a flexible structure for integrating previous knowledge with the latest available data. Apley20 proposed posterior distribution charts for graphically exploring shifts in the process mean. Menzefricke21 used a combined EWMA approach based on the predictive distribution to detect shifts. Aunali and Venkatesan22 presented a comparative analysis of Bayesian and classical control charts in detecting small shifts. Ali23 formulated a predictive Bayesian approach with CUSUM and EWMA charts for monitoring the time between events. Aslam and Anwar24 introduced an improved version of the Bayesian Modified-EWMA location chart. Noor-ul-Amin and Noor25 developed an adaptive EWMA control chart for monitoring the process mean using different loss functions under the Bayesian approach. Bourazas et al.26 proposed predictive control charts (PCCs) using a Bayesian approach for online monitoring of short runs. Khan et al.27 implemented various ranked set sampling techniques in Bayesian control charts. These studies demonstrate the versatility of the Bayesian approach in developing control charts. As research on Bayesian control charts continues, it is likely that they will become increasingly common in a wide range of applications.
Bayesian control charts and joint monitoring Max-EWMA control charts are promising approaches for monitoring processes. However, adaptive control charts have not been widely used in conjunction with Max-EWMA joint monitoring. The adaptive weight in adaptive control charts allows them to be more responsive to process shifts. The combination of adaptive control charts and Max-EWMA joint monitoring could lead to the development of more effective control charts for monitoring time-varying processes. In this study, we focus on the comprehensive investigations of these two methodologies with a Bayesian approach to improve the joint monitoring process mean and dispersion.
The remaining article is structured as follows: In section “Bayesian approach”, we cover the Bayesian framework and its various loss functions. In section “Proposed methodology”, the proposed methodology is presented. In section “Major findings and results discussion”, “Real life data application”, and “Conclusion”, we present key findings, comparative study, and practical illustrations of real-life data applications. Finally, section “Conclusion” highlights the conclusion of the study.
Bayesian approach
There are two main approaches in statistical inference. In the traditional frequentist approach, parameters are considered fixed and unknown. In contrast, the Bayesian approach considers these parameters as probability distributions. In this way, Bayesian theory provides a unique and powerful structure for making inferences based on current and updated observed data. It continuously incorporates prior knowledge to update beliefs as new information emerges. These prior distributions can be broadly categorized into two groups: informative and non-informative. Informative priors depend on a family of distributions and are known as conjugate priors. On the other hand, non-informative priors depend on uniform priors and Jeffrey’s priors. In many fields, the process conditions do not remain fixed but keep changing during the process. Such situations can be better handled with the Bayesian approach. This flexible and intuitive approach is a powerful tool that can be used to develop more effective control charts for a wide range of applications. Let X be a variable of interest with mean \(\theta\) and variance \(\delta^{2}\). The normal prior distribution with parameters \(\theta_{0}\) and \(\delta_{0}^{2}\) is mathematical expressed as,
To construct the posterior distribution, we combine the information from the prior distribution and the observed data. This is achieved by setting a proportional relationship through multiplication which combines the likelihood function of the sample distribution with the prior distribution. The resulting posterior distribution
To get the updated data values for the posterior predictive (PP) distribution, the posterior distribution serves as the initial reference. Thus, as a fundamental aspect of Bayesian theory, the PP distribution allows for the refinement of prior distributions using fresh data, say y. It can be expressed mathematically as,
Squared error loss functions
In Bayesian statistics, the SELF quantifies the difference between true parameter values and their estimates, aiding decision-making and parameter estimation. Minimizing this function involves finding estimators that provide close estimates to the true parameter on average. While analytically tractable, it can be sensitive to outliers due to squaring. Nonetheless, it remains a fundamental tool in Bayesian decision theory, guiding the selection of estimators and decision rules balancing bias and variance in estimation and decision-making One such method is the SELF, introduced by Gauss28. In this method, we square each value of the estimation error, thereby assigning more weight to larger errors—effectively imposing a greater penalty for greater loss. The ultimate objective is to obtain a posterior mean with a smaller loss. SELF yields robust results, particularly when the posterior follows a normal distribution. Let X be the variable of interest, θ is its unknown population parameter and \(\hat{\theta }\) is its such estimator that gives minimum loss. So, in this case, SLEF can be equated with the following expression,
The mathematical representation of this estimator that is using Bayes SELF is as follows:
Linex loss functions
One limitation of using SLEF is that it penalizes all error values, whether they are positive or negative. However, the Linex Loss Function (LLF) treats positive values and negative errors differently. It assigns varying weights to overestimations and underestimations, considering their relative costs. Each outcome may have a different cost, so incorporating its impact in the calculation makes the estimation more efficient. It provides a better way to manage the risk associated with Bayes estimation. This function was introduced by Varian29 and is mathematically defined as
Under LLF, the Bayesian estimator \(\hat{\theta }\) becomes as
Proposed methodology
In this section, we present the methodology for incorporating the adaptive approach and Max-EWMA control chart under the Bayesian framework. Here, we assume that the prior distribution is normal. Let X1, X2, … Xn be a sequence of normally distributed random variables that are random, independent, and identical. Their mean and variance are denoted by θ and \(\delta^{2}\). We also consider that the likelihood function is normally distributed. To obtain the posterior distribution, we multiply the prior distribution by the likelihood function. Under these conditions, when both the prior distribution and the likelihood function follow a normal distribution, the resultant posterior distribution will also follow a normal distribution with a mean (θ) and variance (\(\delta^{2}\)). The probability distribution function (pdf) of the posterior distribution in this case can be expressed as
where \(\theta_{n} = \frac{{n\overline{x} \delta_{0}^{2} + \delta^{2} \theta_{0} }}{{\delta^{2} + n\delta_{0}^{2} }}\) and \(\delta_{n}^{2} = \frac{{\delta^{2} \delta_{0}^{2} }}{{\delta^{2} + n\delta_{0}^{2} }}\) respectively.
Now we setup Max-EWMA under Bayesian environment. Let's collect different samples of size n corresponding to a variable of interest, say X, from our underlying process. We standardize these values by applying the following transformation regarding mean and variance. We can transform them using SELF as well as LLF.
Mean estimation under SELF and LLF
Under SELF, the new transformed expression for calculating the mean is given as
where \(\hat{\theta }_{(SELF)} = \frac{{n\overline{x} \delta_{0}^{2} + \delta^{2} \theta_{0} }}{{\delta^{2} + n\delta_{0}^{2} }}\) is the Bayes estimator for population mean using SELF.
Under LLF, the new transformed expression for calculating mean is expressed as
where \(\hat{\theta }_{{\left( {_{LLF} } \right)}} = \frac{{n\overline{x}_{{(RSS_{i} )}} \delta_{0}^{2} + \delta^{2} \theta_{0} }}{{\delta^{2} + n\delta_{0}^{2} }} - \frac{{C^{\prime}}}{2}\delta_{n}^{2}\) is the Bayes estimator for population mean using LLF.
Variance estimation under SELF and LLF
Under SLEF, the transformed variance is expressed as,
where \(\hat{\delta }_{(SELF)}^{2} = \frac{{\delta^{2} \delta_{0}^{2} }}{{\delta^{2} + n\delta_{0}^{2} }}\) is the Bayes estimators for population variance using SELF.
Under LLF, the transformed expression to estimate the variance becomes
where \(\hat{\delta }_{{\left( {LLF} \right)}}^{2} = \frac{{\delta^{2} \delta_{0}^{2} }}{{\delta^{2} + n\delta_{0}^{2} }}.\) is the Bayes estimators for population variance using LLF.
In both Eqs. (8) and (9), \(H\left( {n,\;\nu } \right)\) follows a chi-square distribution with v degrees of freedom and \(\phi^{ - 1}\) represents the inverse of the standard normal distribution function.
Computation of EWMA
We use these transformed values to compute the EWMA statistic for process mean and variance. The expression for EWMA for mean under any LF can be written as
and the expression for EWMA for a variance under any LF can be written as
where \(P_{0}\) and \(Q_{0}\) show the initial values for the EWMA sequences Pt and Qt respectively and \(\lambda\) is chart’s smoothing constant that can be set within the range 0 and 1. When the process is in a stable and in control situation, then both Pt and Qt are independent and each follows a normal distribution with 0 mean and \(\delta_{{P_{t} }}^{2}\) and \(\delta_{{Q_{t} }}^{2}\) variances respectively. The simplified expression for variance is
Integration of adaptive approach
Next, we incorporate the adaptive approach. Let \({\text{X}}_{{\text{t}}}\) be a normally distributed random variable, taken at time t with a sample of size \(n\), with mean as \({\upmu }_{{\text{X}}}\) and variance as \({\upsigma }_{{\text{X}}}^{2}.{\text{ i.e}}.,{{\text{X}}}_{{\text{t}}}\sim {\text{N}}\left({\upmu }_{{\text{X}}}, {\upsigma }_{{\text{X}}}^{2}\right)\).
Jiang et al.30 proposed an estimator to estimate the shift size by the following expression
where \({\uppsi }\) is the smoothing constant and its range is \(\left( {0,1} \right]\). In real-world scenarios, it's uncommon to have prior knowledge of the exact magnitude of a shift. To handle this, we first estimate its value. To calculate this Haq et al.31 proposed an unbiased estimator, say \(\hat{\delta }_{{\text{t}}}^{{**}}\), which can be expressed as
where \({\text{E}}\left( {\hat{\delta }_{{\text{t}}}^{{**}} } \right) = {\updelta } = 0\). The process remains stable for a certain period of time, say t ≤ t0. In practical situations, the true magnitude is often unknown. Instead, δ is estimated by considering \({\tilde{\delta }}_{{\text{t}}} = \left| {\hat{\delta }_{{\text{t}}}^{{**}} } \right|\).
The detection is achieved by recursively calculating the following EWMA statistic, which is referred to as the proposed chart statistic, in the following manner:
where \({\text{A}}_{0}\) = 0 set as the initializing value. Instead of considering fixed value for smoothing constant, here we use a function that can adapt different values according to the process changing conditions. The self-adjusting weighting factor η(\({\tilde{\omega }}_{{\text{t}}}^{*}\)) is given as
where η(\(\tilde{\omega }_{t}^{*}\)) is a random variable determined by a continuous function, optimizing our chart’s performance for detecting shifts. When \(\tilde{\delta }_{t}\) ≤ 2.7, η() is tailored for ssitivity to small to moderate shifts. Our adaptive chart excels at detecting shifts of any size, outperforming other methods. If the shift exceeds \(\tilde{\delta }_{t}\)≥ 2.7, our chart acts like a Shewhart chart, detecting larger shifts with \(\tilde{\delta }_{t}\) = 2.7 as the pivot point. It offers flexibility for adjusting the model and incorporating additional factors.
Instead of using fixed \(\lambda\) in Eqs. (10) and (11) and assuming that it stays constant throughout the process, we use the self-adapting function of Eq. (16) and recursively update Eqs. (10) and (11) to compute the individual EWMA under adaptive approach. So, the equation becomes,
Finally, these values are plugged in Max-EWMA given by Chen and Change5 for jointly monitoring the process mean and variance in a single chart. So, the plotting can be expressed as
where Max is the function to get the maximum value of the given inputs.
As the Adaptive Bayesian Max-EWMA statistic is a positive value, we are required to plot only the upper control limit for jointly monitoring the process mean and variance. The plotting statistic is compared with the UCL threshold. If its value is below UCL then the process is in control. If the value is above the UCL then the process is out of control either by mean, variance, or both.
Major findings and results discussion
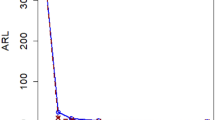
The Tables 1, 2, 3, 4, 5, 6 provides a comprehensive overview of results obtained through the application of the Adaptive Bayesian Max-EWMA control chart method. These evaluations are conducted within the framework of informative priors and based on 50,000 replicates, allowing us to calculate both the ARL and SDRL. We utilized smoothing constants with λ values set at 0.15 and 0.20. Moreover, our study explores a wide range of combinations involving mean shift values (α) ranging from 0.00 to 3.00 and variance shift values (β) ranging from 1.00 to 3.00. These different combinations are used to measure the performance of the Adaptive Bayesian Max-EWMA control chart method in the monitoring of process mean and variance jointly.
Effect of mean shift on ARL and SDRL
As the mean is shifted from 0.00 to 3.00, there is a noticeable trend in both the ARL and SDRL. ARL values decrease considerably with the higher mean shifts. These results show that the method becomes more sensitive to shifts in data as the mean shift increases. On the other hand, SDRL is decreased with the increase in mean shifts. This behavior of SDRL is aligned with ARL observations. The performance of the chart becomes more consistent and less variable, which is a desirable characteristic in real-world applications where stable and reliable change detection is essential.
Effect of variance shift on ARL and SDRL
Similar to the mean shift, variance shift exhibits a consistent influence on ARL and SDRL as it increases from 1.00 to 3.00. ARL decreases with higher v shift values, indicating that the algorithm becomes more efficient at detecting changes when variance shift is increased. This result aligns with the observed behavior of mean shift and suggests that a higher v shift can lead to faster change detection. Correspondingly, the decrease in SDRL as variance shift increases implies that the algorithm's detection performance becomes more stable and predictable. This predictability is valuable in applications where consistent and reliable change detection is paramount.
Effect of sample size on ARL and SDRL
The sample size (n) in the table has a noticeable impact on the results. Larger sample sizes (e.g., n = 7) consistently lead to quicker and more stable change detection, as evidenced by lower ARL and SDRL values. This increased responsiveness and reliability in detecting changes make larger sample sizes a favorable choice in practical applications where timely and consistent detection is crucial. However, it's essential to consider computational resources and time constraints when selecting the sample size, as larger samples may come with increased processing demands.
Effect of smoothing constant on ARL and SDRL
The different values of the smoothing constant were also compared, specifically λ = 0.15 and λ = 0.20. We can see notable differences in the ARL and SDRL values. For λ = 0.15, the adaptive Bayesian Max-EWMA control chart method generally exhibits higher ARL values across varying mean shift and variance shift scenarios. In contrast, with λ = 0.20, the Adaptive method consistently achieves lower ARL values, indicating faster change detection. This observation suggests that a higher λ value enhances the chart's sensitivity which leads to quicker detection.
The results from Tables 4, 5, 6 are computed under the LLF. The analysis of the ARL and SDRL under LLF also shows the similar observation as found in Table 1, 2, 3 under SELF. We can say that our proposed control chart performs equally well under both loss functions namely SELF and LLF.
Comparative study
In this study, we conduct a comparative analysis of the two control charts: the Bayesian Max-EWMA chart and our proposed Adaptive Bayesian Max-EWMA chart. Control charts are vital tools for quality control and process monitoring. The Bayesian Max-EWMA chart is a well-established method, while our Adaptive Bayesian Max-EWMA chart is integrated with an adaptive approach to changing process conditions. The examination of ARL and SDRL values under various scenarios provides insights into the performance of these charts. Following are the findings from the results.
-
i.
As the mean shift increases the ARL and SDRL values of both charts get decrease. However, the decrease in ARL and SDRL values is more prominent in the proposed Adaptive chart. This shows its higher sensitivity to detect changes in the process.
-
ii.
As the variance shift increases, it generally leads to higher ARL values for both charts. The proposed Adaptive chart consistently shows better performance than the counterpart chart. It shows lower ARL values across different shift levels of variance.
-
iii.
Overall, the proposed Adaptive Bayesian Max-EWMA chart consistently has lower ARL values compared to the Bayesian Max-EWMA chart. In most cases, the SDRL values for the Adaptive chart are also lower than those for the counterpart chart. This show stability in the repeated results. The Adaptive chart consistently performs better in terms of faster detection and lower variability in run length.
Real life data application
In this section, we apply the proposed Adaptive Bayesian Max-EWMA chart to real-life data and compare its performance with the existing Bayesian Max-EWMA chart. In semiconductor manufacturing, integrated circuits (ICs) are placed on a thin slice-like material called a wafer. The flow width of the photoresist is a critical dimension that must be controlled to ensure the proper functioning of the ICs. By monitoring the flow width of the photoresist, engineers can ensure that the process is producing high-quality results. Montgomery32 provides an example of a hard baking process in semiconductor manufacturing. The dataset consists of 45 samples, each with 5 values, and each sample is collected every hour. The first 30 values serve as in-control values, while the last 15 values are contaminated with impurities. Both charts are used to monitor the process variations in the mean and variance, and the computed results are presented in Table 7. In this demonstration, we have used SELF only.
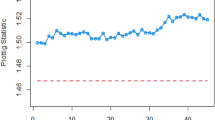
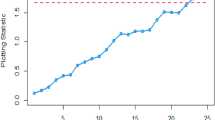
Table 7 shows the values of phases I and II and the application of existing and proposed charts. It shows the process remains in control for the first 30 values. In phase II, for testing purposes, impurities in the process are introduced by a shift magnitude of 1.00 (\({\Delta }_{{\text{X}}}\) = 1.00). The Bayesian MaxEWMA under the SELF method detects this shift at the 40th sampling unit which is also evident from Fig. 1. On the other hand, our proposed Adaptive Bayesian Max-EWMA control chart which incorporates the adaptive values for smoothing constant detects this change in process at an earlier stage. It gives out of control signal at the 37th sample unit. These results are presented in Table 7. The visual illustration of both charts is presented in Figs. 1 and 2. It clearly shows that the proposed chart has a better capability of monitoring the process changes, this early detection shows that the process monitoring has improved and the proposed control chart is quicker at capturing the shifted behavior of the process. It highlights that our integration of the adaptive approach has enhanced the speed and sensitivity of the control chart in detecting shifts in the process mean and variance.

Bayesian Max-EWMA under SELF with \(\lambda\) = 0.20.

Proposed Adaptive Bayesian Max-EWMA under SELF with \(\lambda\) = 0.20.
Conclusion
In this study, we focus on a comprehensive investigation of the adaptive approach and Bayesian methodology to enhance joint process monitoring. We introduce a novel Adaptive Bayesian Max-EWMA control chart that seamlessly integrates an adaptive approach within the Bayesian framework. It utilizes prior and posterior distributions under the SLEF and LLF loss functions. This method is further enhanced with an adaptive approach. The effectiveness of the proposed chart was evaluated through rigorous simulations. Our meticulous analysis, encompassing various parameters, unequivocally demonstrates that the Adaptive Bayesian Max-EWMA chart consistently outperforms its conventional counterpart. To reinforce our conclusions, we conducted a real-life case study. This practical application not only supports the chart's exceptional performance but also provides tangible evidence of its effectiveness in real-world scenarios. The proposed chart's key contributions are as follows: it seamlessly integrates an adaptive approach within the Bayesian framework, allowing it to learn from incoming data and adjust its charting parameters accordingly. It enhances sensitivity to both mean and variance shifts, making it a valuable tool for detecting a wide range of process disturbances. It exhibits superior adaptability to changing process conditions, ensuring its effectiveness even in non-stationary environments. The proposed chart can be applied across a wide range of industries. By providing early warnings of potential process problems, the chart can help reduce scrap, rework, and warranty costs, ultimately improving product quality and customer satisfaction. Future research directions could include investigating the chart's performance under more complex process dynamics, such as non-linear shifts and autocorrelated data. Researchers may also explore the development of adaptive Bayesian control charts for monitoring other process parameters or integrating the chart with multivariate or high-dimensional data.
Data availability
The datasets used and/or analyzed during the current study are available from the corresponding author on reasonable request.
References
Shewhart, W. A. The application of statistics as an aid in maintaining quality of a manufactured product. J. Am. Stat. Assoc. 20(152), 546–548 (1925).
Page, E. S. Continuous inspection schemes. Biometrika 41(1/2), 100–115 (1954).
Roberts, S. Control chart tests based on geometric moving averages. Technometrics 42(1), 97–101 (1959).
Gan, F. F. Joint monitoring of process mean and variance. Nonlinear Anal. Theory Methods Appl. 30(7), 4017–4024 (1997).
Chen, G., Cheng, S. W. & Xie, H. Monitoring process mean and variability with one EWMA chart. J. Qual. Technol. 33(2), 223–233 (2001).
Chen, G., Cheng, S. W. & Xie, H. A new EWMA control chart for monitoring both location and dispersion. Qual. Technol. Quant. Manag. 1(2), 217–231 (2004).
Haq, A., Brown, J. & Moltchanova, E. New exponentially weighted moving average control charts for monitoring process mean and process dispersion. Qual. Reliab. Eng. Int. 31(5), 877–901 (2015).
Sanusi, R. A., Teh, S. Y. & Khoo, M. B. Simultaneous monitoring of magnitude and time-between-events data with a Max-EWMA control chart. Comput. Ind. Eng. 142, 106378 (2020).
Chatterjee, K., Koukouvinos, C. & Lappa, A. A joint monitoring of the process mean and variance with a TEWMA-Max control chart. Commun. Stat. Theory Methods 52(22), 8069–8095 (2023).
Jalilibal, Z., Amiri, A. & Khoo, M. B. A literature review on joint control schemes in statistical process monitoring. Qual. Reliab. Eng. Int. 38(6), 3270–3289 (2022).
Capizzi, G. & Masarotto, G. An adaptive exponentially weighted moving average control chart. Technometrics 45(3), 199–207 (2003).
Lee, P. H. & Lin, C. S. Adaptive Max charts for monitoring process mean and variability. J. Chin. Inst. Ind. Eng. 29(3), 193–205 (2012).
Huang, W., Shu, L. & Su, Y. An accurate evaluation of adaptive exponentially weighted moving average schemes. IIE Trans. 46(5), 457–469 (2014).
Abbas, Z. et al. A comparative study on the nonparametric memory-type charts for monitoring process location. J. Stat. Comput. Simul. 93(14), 2450–2470 (2023).
Abbas, Z., Nazir, H. Z., Riaz, M., Shi, J. & Abdisa, A. G. An unbiased function-based Poisson adaptive EWMA control chart for monitoring range of shifts. Qual. Reliab. Eng. Int. 39(6), 2185–2201 (2023).
Ugaz, W., Sánchez, I. & Alonso, A. M. Adaptive EWMA control charts with time-varying smoothing parameter. Int. J. Adv. Manuf. Technol. 93, 3847–3858 (2017).
Nazir, H. Z., Hussain, T., Akhtar, N., Abid, M. & Riaz, M. Robust adaptive exponentially weighted moving average control charts with applications of manufacturing processes. Int. J. Adv. Manuf. Technol. 105, 733–748 (2019).
Haq, A. & Razzaq, F. Maximum weighted adaptive CUSUM charts for simultaneous monitoring of process mean and variance. J. Stat. Comput. Simul. 90(16), 2949–2974 (2020).
Sarwar, M. A. & Noor-ul-Amin, M. Design of a new adaptive EWMA control chart. Qual. Reliab. Eng. Int. 38(7), 3422–3436 (2022).
Apley, D. W. Posterior distribution charts: A Bayesian approach for graphically exploring a process mean. Technometrics 54(3), 279–293 (2012).
Menzefricke, U. Combined exponentially weighted moving average charts for the mean and variance based on the predictive distribution. Commun. Stat. Theory Methods 42(22), 4003–4016 (2013).
Aunali, A. S. & Venkatesan, D. Comparison of Bayesian method and classical charts in detection of small shifts in the control charts. Int. J. 6(2), 101–114 (2017).
Ali, S. A predictive Bayesian approach to EWMA and CUSUM charts for time-between-events monitoring. J. Stat. Comput. Simul. 90(16), 3025–3050 (2020).
Aslam, M. & Anwar, S. M. An improved Bayesian Modified-EWMA location chart and its applications in mechanical and sport industry. PLoS One 15(2), e0229422 (2020).
Noor-ul-Amin, M. & Noor, S. An adaptive EWMA control chart for monitoring the process mean in Bayesian theory under different loss functions. Qual. Reliab. Eng. Int. 37(2), 804–819 (2021).
Bourazas, K., Kiagias, D. & Tsiamyrtzis, P. Predictive Control Charts (PCC): A Bayesian approach in online monitoring of short runs. J. Qual. Technol. 54(4), 367–391 (2022).
Khan, I., Noor-ul-Amin, M., Khan, D. M., AlQahtani, S. A. & Sumelka, W. Adaptive EWMA control chart using Bayesian approach under ranked set sampling schemes with application to Hard Bake process. Sci. Rep. 13(1), 9463 (2023).
Gauss, C. Methods Moindres Carres Memoire sur la Combination des Observations, 1810 Translated by J. In: Bertrand (1955).
Varian, H. R. A Bayesian approach to real estate assessment. In Studies in Bayesian Econometric and Statistics in Honor of Leonard J. Savage, 195–208 (1975).
Jiang, W., Shu, L. & Apley, D. W. Adaptive CUSUM procedures with EWMA-based shift estimators. Iie Trans. 40(10), 992–1003 (2008).
Haq, A., Gulzar, R. & Khoo, M. B. An efficient adaptive EWMA control chart for monitoring the process mean. Qual. Reliab. Eng. Int. 34(4), 563–571 (2018).
Montgomery, D. C. Introduction to Statistical Quality Control 8th edn. (Wiley, 2023).
Author information
Authors and Affiliations
Contributions
A.A.Z., M.N.A., and I.K. conducted mathematical analyses and numerical simulations for the manuscript. J.I. and S.H. conceptualized the main idea, performed data analysis, and contributed to manuscript restructuring. A.A.Z. and I.K. ensured result validation, manuscript revision, and secured funding. Furthermore, S.H. and M.N.A. improved the manuscript language and conducted additional numerical simulations. The final version, prepared for submission, reflects a consensus among all authors.
Corresponding author
Ethics declarations
Competing interests
The authors declare no competing interests.
Additional information
Publisher's note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Zaagan, A.A., Noor-ul-Amin, M., Khan, I. et al. An adaptive Bayesian approach for improved sensitivity in joint monitoring of mean and variance using Max-EWMA control chart. Sci Rep 14, 9948 (2024). https://doi.org/10.1038/s41598-024-60625-2
Received:
Accepted:
Published:
DOI: https://doi.org/10.1038/s41598-024-60625-2
Keywords
Comments
By submitting a comment you agree to abide by our Terms and Community Guidelines. If you find something abusive or that does not comply with our terms or guidelines please flag it as inappropriate.
