
Abstract
Brain extraction, or skull-stripping, is an essential data preprocessing step for machine learning approaches to brain MRI analysis. Currently, there are limited extraction algorithms for the neonatal brain. We aim to adapt an established deep learning algorithm for the automatic segmentation of neonatal brains from MRI, trained on a large multi-institutional dataset for improved generalizability across image acquisition parameters. Our model, ANUBEX (automated neonatal nnU-Net brain MRI extractor), was designed using nnU-Net and was trained on a subset of participants (N = 433) enrolled in the High-dose Erythropoietin for Asphyxia and Encephalopathy (HEAL) study. We compared the performance of our model to five publicly available models (BET, BSE, CABINET, iBEATv2, ROBEX) across conventional and machine learning methods, tested on two public datasets (NIH and dHCP). We found that our model had a significantly higher Dice score on the aggregate of both data sets and comparable or significantly higher Dice scores on the NIH (low-resolution) and dHCP (high-resolution) datasets independently. ANUBEX performs similarly when trained on sequence-agnostic or motion-degraded MRI, but slightly worse on preterm brains. In conclusion, we created an automatic deep learning-based neonatal brain extraction algorithm that demonstrates accurate performance with both high- and low-resolution MRIs with fast computation time.
Similar content being viewed by others


Introduction
Magnetic Resonance Imaging (MRI) allows for the acquisition of high-resolution images with exceptional soft tissue contrast1, making it especially useful for evaluation of the brain, where it often informs patient medical management. For neonates, brain MRI is particularly important for assessment of patients with neonatal encephalopathy, where both the presence and pattern of brain injury can assist prognostication and treatment planning2,3,4,5,6,7. Advances in artificial intelligence (AI) and machine learning (ML) have allowed accurate prediction of functional outcomes in infants using MRI data8,9,10,11 taking advantage of the imaging information beyond what is reasonably utilized by human visual inspection alone. Image preprocessing is an essential step in standardizing data inputs for AI/ML algorithms, and ensures faster, more robust data processing while minimizing potential confounding features12,13,14,15,16,17,18.
Brain extraction, otherwise known as skull-stripping, is an essential step for virtually all AI/ML approaches to brain MRI analysis. While this process is well-established in adult brain models, there are limited extraction algorithms available for the neonatal brain. Brain extraction refers to the process by which brain tissue is segmented, and non-brain tissue, including the skull and extracranial soft tissues, is removed12,14,16,18,19. Brain extraction facilitates data de-identification by removing three-dimensional face data, which mitigates bias by preventing AI/ML algorithms from focusing on extracranial and facial soft tissues. Accurate automated brain extraction tools are important for improving standardization of the skull-stripping step, as manual editing is prone to variability, is time-consuming, and could influence the accuracy of associated AI/ML models. Historically, automated brain extraction tools have been based on thresholding and binary morphological operations, shape analysis, and/or atlas registration techniques20,21,22,23,24,25,26,27,28; however, the most modern and accurate approaches are based on deep learning (DL) with convolutional neural networks (CNNs)29. Despite recent progress with ML16,29, there is still a need for improved MRI brain extraction tools designed specifically for neonatal brains30, which differ from adult brains based on differences in morphology, signal contrast, and the increased frequency of motion artifact13,15,17,18,24,29,31.
DL-based brain extraction algorithm performance relies heavily on its training data, and generalizability can be limited by small training set sizes and lack of training data heterogeneity. Though models may learn to perform well on institution specific data, there is a need for more generalizable algorithms that can perform well on MRI data with varying acquisition parameters, field strength, and vendor platforms. To address this need for generalizability, we present ANUBEX (automated neonatal nnU-Net brain MRI extractor), a publicly-available DL-based algorithm for neonatal brain extraction based on the domain-leading nnU-Net architecture and trained on a large multi-institution dataset. We compare the performance of our algorithm to five publicly available algorithms spanning conventional, machine learning, and deep learning methods using a multi-institution external dataset20,21,32,33.
Methods
Study population
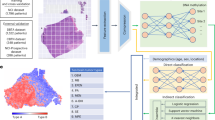
This was an Institutional Review Board approved ancillary study of the High-dose Erythropoietin for Asphyxia and Encephalopathy (HEAL) study34,35,36, which prospectively enrolled 501 neonates from 17 different institutions across the United States of America with moderate to severe encephalopathy at birth. Informed consent was previously obtained from all subjects and/or their legal guardian, and all methods were carried out in accordance with relevant guidelines and regulations. A subset of HEAL participants (N = 474) underwent neonatal MRI. Exclusion criteria included missing, incomplete, or severely artifact degraded T1-weighted MR imaging data (N = 41) resulting in a final study population of 433 participants from 17 different institutions (Fig. 1).

Flowchart describing the iterative brain masking process. * Studies were manually corrected. ** Iteration 1 used BET from FSL to generate automated brain masks. *** Iterations 2–4 used nnU-Net models to generate automated brain masks. Studies categorized as “borderline” were manually corrected. The nnU-Net models were subsequently retrained on the “acceptable” and newly corrected “borderline” studies, and new automated masks were regenerated for the “needs revision” studies. **** For iteration 5, all “borderline” and “needs revision” studies were manually corrected.
Study data
Imaging data used for this study consisted of T1-weighted, T2-weighted, and diffusion-weighted imaging of the brain acquired as part of the HEAL trial. Scan parameters varied based on the imaging site and scanner platform. T1-weighted images included both three-dimensional gradient echo and two-dimensional spin echo imaging. T2-weighted images were two-dimensional Fast Spin Echo (FSE) imaging and diffusion-weighted images were Echoplanar Imaging (EPI). Other than in-plane resolution and slice thickness, scan parameters were not collected as part of the HEAL trial and are not consistently available for these data.
Iterative deep learning model development
The ANUBEX architecture was designed using nnU-Net37, a self-configuring segmentation framework based on the popular U-Net architecture38, which is both widely used and has demonstrated domain leading segmentation performance on related tasks. Model training was accomplished using an iterative, human-in-the-loop AI approach. First, baseline automated brain masks were generated from T1-weighted images using a widely used tool for adult MRI brain extraction21. Next, all brain masks were manually reviewed by a single medical trainee (author JC) using ITK-SNAP39 and categorized as either “Acceptable,” “Borderline,” or “Needs Revision” using the following criteria:
Acceptable
Very little or no non-brain tissue included or brain tissue excluded; manual revision not expected to improve algorithm performance.
Borderline
Small amount of non-brain tissue included or brain tissue excluded; uncertain if manual revision will change algorithm performance.
Needs revision
Significant amount of non-brain tissue included or brain tissue excluded; manual revision expected to improve algorithm performance.
Studies labeled as “Borderline” were manually edited in ITK-SNAP by the same medical trainee. Next, all “Acceptable” and revised “Borderline” studies were used to train an instance of nnU-Net (single fold, random 80%/20% train/validation split). This model was then used to re-generate automated masks for the remaining “Needs revision” cases and the process was repeated for a total of five iterations, with each training instance reusing all previously labeled “Acceptable” and manually revised “Borderline” images. After five iterations, all remaining “Borderline” (N = 11) and “Needs revision” (N = 23) masks were manually edited to complete the training dataset.
Final model training using all the manually reviewed/corrected data (N = 433) was performed using a five-fold cross-validation approach with a standard random 80%/20% train/validation split for each fold. Model training was accomplished using a desktop computer equipped with two Nvidia RTX A600 40 GB graphics processing units running in parallel (one training fold per GPU). We developed two models, one trained on only T1-weighted imaging referred to as ANUBEX, and one trained on all three included sequences in a randomized manner referred to as ANUBEX Sequence Agnostic (ANUBEX-SA).
External validation
Performance of the fully trained ANUBEX model was evaluated using an out-of-sample, external test set consisting of N = 39 T1-weighted images from two different sources: N = 20 from the developing Human Connectome Project (dHCP)40 consisting of high-resolution three-dimensional gradient echo T1-weighted imaging, and N = 19 from the NIH Pediatric MRI study41 consisting predominantly of lower resolution two-dimensional spin echo T1-weighted imaging. Corresponding T2-weighted images were also obtained from the dHCP test set. A single reviewer (author JC) manually reviewed the test set and manually generated each mask, which were subsequently used as ground truth for assessing automated brain masks. The proposed model was applied to the external test set using an ensemble of all five training folds.
Model performance was compared to five different publicly available automated brain extraction methods: BET, BSE, CABINET, iBEATv2, and ROBEX20,21,22,32,33. Each algorithm was applied to the external test set using default parameters. These benchmark comparison methods were chosen based on the following criteria: (1) publicly available, (2) out-of-the-box functionality (i.e. single command that runs on native data), and (3) based on a variety of different methods (e.g. shape analysis, atlas registration, deep learning).
Sub-analyses
In addition to the primary external validation described in the previous section, we performed several sub-analyses to evaluate model performance in different scenarios including different MRI sequences, preterm brain MRIs, and motion degraded brain MRIs. To address performance on different MRI sequences we evaluated ANUBEX-SA on T2-weighted imaging from the dHCP test set only, as the NIH data does not consistently contain T2-weighted imaging. To address performance on preterm brain MRIs, we evaluated ANUBEX on 18 T1-weighted brain MRIs performed before 36 weeks that were available in the dHCP dataset. To address performance in the setting of motion artifact, we evaluated the performance of ANUBEX on motion degraded validation data from the fivefold cross-validation. We chose this approach because there were insufficient exams with motion artifact in the testing data for a meaningful analysis. We identified 92/433 (21%) exams with at least moderate motion artifact and 341/433 (79%) exams with either mild or no significant motion artifact using the following objective criteria (Fig. 2):

Examples of brain MRIs representing mild, moderate, and severe motion artifact.
Mild motion artifact
Slight motion artifact that does not obscure grey-white matter junction.
Moderate motion artifact
Motion artifact that incompletely obscures grey-white matter junction.
Severe motion artifact
Obvious motion artifact that completely obscures grey-white matter junction.
Evaluation metrics and statistical analyses
The Dice coefficient was chosen as the primary metric for comparing manual and automated brain masks. The Dice coefficient compares the degree of spatial overlap between two binary images, ranging between 0 (no overlap) to 1 (perfect agreement), and is calculated as: Dice coefficient (A,B) = 2(A ∩ B)/(A + B) where (A ∩ B) is the union of masks A and B. Secondary metrics included sensitivity and specificity, calculated as Sensitivity = TP/(TP + FN), and Specificity = TN/(FP + TN) where TP is the number of true positive voxels in the mask, TN the number of true negative voxels, FP the number of false positive voxels, and FN the number of false negative voxels. Dice coefficients were calculated using custom Python code, and statistical comparisons between average Dice scores were computed using a two-sample, two-tailed t-test with a significance threshold of p < 0.05. We controlled for multiple comparisons using the Benjamini and Hochberg False Discovery Rate correction method.
Ethical approval
This study was approved by the University of California, San Francisco Institutional Review Board as an ancillary study of the High-dose Erythropoietin for Asphyxia and Encephalopathy (HEAL) study.
Results
Study data and patient demographics
The final training dataset included N = 433 neonatal MRI studies from 17 institutions, 44% of which were female. The median gestational age (GA) at birth was 39.3 weeks (interquartile range [IQR] 38.1–40.3), with MRIs obtained between 96 and 144 h after birth36. The final external testing dataset included N = 39 neonatal MRI studies from two institutions, N = 20 from the dHCP and N = 19 from the NIH. The dHCP preterm sub-analysis data set included N = 18 MRIs. The median GA at scan of patients from the NIH, dHCP, and dHCP Preterm data sets, respectively, were 42.3 weeks (IQR 42.1–43.1), 40.6 weeks (IQR 39.7–40.9), and 34.5 weeks (IQR 34.0–35.3). The demographics of the NIH, dHCP, and dHCP Preterm data sets, respectively, were 53%, 30%, and 44% female. Basic participant demographic data is shown in Table 1. MRI resolution is shown in Table 2.
Model training
Final model training lasted approximately 36 h. Training and validation loss (Dice) decreased appropriately throughout the training process. Final trained model weights are freely available online (https://github.com/ecalabr/nnUNet_models).
External validation and performance evaluation
External validation and performance evaluation were performed using the multi-institution external test dataset (N = 39). Processing time for all 39 studies in the external test set took 330.34 s or an average of 8.5 s per study using an Nvidia RTX A6000 GPU. Results from ANUBEX were compared to results from 5 other publicly available brain extraction tools: BET, BSE, CABINET, iBEATv2, and ROBEX20,21,22,32,33. Dice scores for all models evaluated on the testing dataset are provided in Table 3. Example brain masks generated by each algorithm are shown in Fig. 3. The Dice coefficient of our model was the highest of all methods tested with a mean ± standard deviation of 0.955 ± 0.017 (Fig. 4A). The next best performing model (iBEATv2) yielded an average Dice of 0.949 ± 0.017, followed by CABINET at 0.934 ± 0.015. Other evaluated methods yielded average Dice scores below 0.85. Our model showed a small but statistically significant improvement in performance compared to the two other deep learning algorithms CABINET (p < 0.001) and iBEATv2 (p = 0.012) and a larger statistically significant difference between the non-deep learning algorithms ROBEX, BSE, and BET. Sub-analysis of algorithm performance on the external test set by site revealed a trend towards better performance on the dHCP (3D) image data (Fig. 4C) compared to the NIH (2D) data (Fig. 4B). Notably, our algorithm showed the highest performance of all algorithms tested for both dHCP and NIH data.

Comparison of masks generated by 6 automatic brain segmentation tools on 2 randomly selected MRIs, one from the NIH dataset (left two columns) and one from the dHCP dataset (right two columns). Green pixels represent mask pixels that appropriately capture true brain as determined by gold standard manual segmentation. Red pixels represent mask pixels that capture nonbrain pixels. Blue pixels represent true brain that was not captured by mask pixels.

Box and whisker plots of Dice similarity coefficients across 6 unique automatic brain segmentation tools and 1 application of our model (ANUBEX-SA) for the (A) All, (B) NIH, (C) dHCP, and (D) dHCP Preterm datasets (refer to Table 3 for tabulated values). Paired two-tail T-tests were performed between ANUBEX and each comparator, with the Benjamini and Hochberg False Discovery Rate correction method applied to p-values to control for multiple comparisons.
Sub-analyses
Sub-analysis results are presented in Table 3 and Fig. 4. ANUBEX-SA (trained on T1-, T2-, and diffusion-weighted images) showed similarly high performance on T1-weighted imaging from both test sets (average Dice = 0.956 ± 0.012 for dHCP and Dice = 0.943 ± 0.014 for NIH) and performance on T2-weighted imaging from the dHCP test set was nearly identical (average Dice = 0.956 ± 0.008). We detected small but statistically significant decreases in performance of ANUBEX-SA compared to ANUBEX for the dHCP test set but not for the NIH test set or aggregate test set.
ANUBEX performance on the 18 preterm (< 36 weeks gestational age) brain MRIs from the dHCP yielded an average Dice = 0.947 ± 0.030, which was slightly worse compared to performance on term dHCP MRI data (p = 0.015). ANUBEX-SA performance was average Dice = 0.940 ± 0.028 for T1-weighted images and 0.925 ± 0.028 for T2-weighted images, which was not significantly different compared to regular ANUBEX performance on preterm T1-weighted images (Fig. 4D).
ANUBEX performance in the setting of moderate or severe motion artifact was evaluated on validation data from the fivefold cross-validation, which results in elevated Dice scores compared to test set data but still allows comparison of performance between MRIs with and without motion artifact. Average validation Dice score for ANUBEX was 0.986 ± 0.021 for the group with at least moderate motion artifact compared to 0.988 ± 0.020 in the group without significant motion artifact. This difference was not statistically significant (p = 0.470).
Discussion
In this study, we evaluated ANUBEX, a new deep learning-based model for neonatal MRI brain extraction based on the widely used nnU-Net architecture. Model performance was evaluated on an independent, multi-institution, external dataset and results were compared to five other publicly available brain extraction methods including deep learning-based and non-deep learning-based methods: BET, BSE, CABINET, iBEATv2, and ROBEX. Compared to the other methods we evaluated, our model demonstrated superior brain extraction performance on both 2D and 3D neonatal brain MRIs. Specifically, there was a small but significant improvement in performance compared to the other two deep learning-based methods (CABINET and iBEATv2) and a larger significant difference compared to the non-deep learning-based methods. Based on sub-analysis results, our model performs slightly worse on brain MRIs of preterm infants as compared to term infants, an expected outcome given our model was trained on term and near-term infants. We did not find significant differences in performance between our T1-weighted model (ANUBEX) or our sequence agnostic model (ANUBEX-SA) whether evaluated on T1- or T2-weighted images, and model validation performance was not significantly different in moderately to severely motion degraded versus non to mildly motion degraded images.
Our approach to model generation has several potential advantages that may have contributed to the observed performance increase. First, we employed an iterative semi-automated approach to ground truth brain mask generation, which allowed increased efficiency and consistency. Second, we utilized a multi-institutional dataset from the HEAL trial as training data for our deep learning algorithm in order to create a more generalizable model across different institutions. By training with a larger and more heterogeneous sample including variation in MRI manufacturer, model, software, and imaging parameters36, our model can potentially achieve higher accuracy in neonatal skull stripping across various institutions in comparison to studies performed with a smaller and institution specific dataset. For example, our model showed improved performance with both high-resolution (0.8 × 0.8 × 1.6 mm) 3D imaging (dHCP) and thicker slice (1.0 × 1.0 × 3.0 mm) 2D imaging (NIH), which is likely attributable to the training data heterogeneity. Comparatively, iBEATv2 was trained on only the high-resolution Baby Connectome Project dataset (resolution 0.8 × 0.8 × 0.8 mm), and ROBEX was trained on a proprietary dataset of 92 healthy adult subjects (downsampled to lower resolution 1.5 × 1.5 × 1.5 mm)33. Finally, our model was generated using the widely used nnU-Net architecture, which has “out-of-the-box” functionality and has shown domain-leading performance in other medical image segmentation tasks. The use of nnU-Net also allows straightforward sharing of trained model weights and can lower barriers to implementation and use in future research projects.
This study has several important limitations. First, the use of data from the HEAL trial limits the scope of brain pathology included in the training data. HEAL study participants all had moderate to severe encephalopathy and did not have other major structural brain abnormalities. While several other intracranial pathologies were present in HEAL participants (e.g., infarcts, hemorrhages, hydrocephalus) these were not rigorously documented nor was the model specifically tested for brain extraction performance in the setting of any brain abnormality. Therefore, performance in the setting of brain structural pathology may be degraded. Second, we focused exclusively on the early neonatal period (< 44 weeks GA at scan) and therefore performance in patients older than 44 weeks GA may be degraded. Finally, comparison with other publicly available models was not exhaustive as several previously published algorithms had webpages that were inactive or code that was non-functional on modern software stacks.
Because accurate brain tissue segmentation is key to subsequent image analysis and volumetric measurements, necessary future steps would include further evaluation of the accuracy of our model on patients outside of the neonatal age range, such as in young children or adults, and assessing our model’s utility on brains with diverse structural pathology. We were not able to uniformly perform sub-analyses on all other algorithms because of varying abilities to support T2-weighted imaging.
In conclusion, we propose an application of nnU-Net to create a newer high-accuracy automatic neonatal brain extraction algorithm trained on a large multi-institutional dataset to improve generalizability across MRI acquisition parameters. Our model demonstrates accurate performance with both high- and low-resolution MRIs and is designed to have a lower barrier to use as an “out-of-the-box” ready software with fast computational time.
Data availability
Trained model weights are available through the corresponding author or online at: https://github.com/ecalabr/nnUNet_models
Abbreviations
- JVC:
-
Study design, literature search, data acquisition or analysis, manuscript drafting, manuscript figures/tables, manuscript revision
- YL:
-
Study design, data acquisition or analysis, manuscript drafting, manuscript revision
- FT:
-
Data acquisition or analysis, manuscript drafting, manuscript figures/tables, manuscript revision
- GC:
-
Data acquisition or analysis, manuscript revision
- CL:
-
Manuscript revision
- AL:
-
Manuscript revision
- AMR:
-
Manuscript revision
- APH:
-
Manuscript figures/tables, manuscript revision
- YWW:
-
Data acquisition or analysis, manuscript revision
- EC:
-
Study design, literature search, data acquisition or analysis, manuscript drafting, manuscript figures/tables, manuscript revision
References
Plewes, D. B. & Kucharczyk, W. Physics of MRI: A primer. J. Magn. Reson. Imaging 35(5), 1038–1054. https://doi.org/10.1002/jmri.23642 (2012).
Wu Y. W. Clinical features, diagnosis, and treatment of neonatal encephalopathy. UpToDate (2023).
Meijler, G. & Steggrda, S. Overview of cerebellar injury and malformations in neonates. UpToDate (2022).
Heinz, E. R. & Provenzale, J. M. Imaging findings in neonatal hypoxia: A practical review. AJR Am. J. Roentgenol. 192(1), 41–47. https://doi.org/10.2214/ajr.08.1321 (2009).
Miller, S. P. et al. Patterns of brain injury in term neonatal encephalopathy. J. Pediatr. 146(4), 453–460. https://doi.org/10.1016/j.jpeds.2004.12.026 (2005).
Barnette, A. R. et al. Neuroimaging in the evaluation of neonatal encephalopathy. Pediatrics 133(6), e1508-1517. https://doi.org/10.1542/peds.2013-4247 (2014).
Chau, V., Poskitt, K. J. & Miller, S. P. Advanced neuroimaging techniques for the term newborn with encephalopathy. Pediatr. Neurol. 40(3), 181–188. https://doi.org/10.1016/j.pediatrneurol.2008.09.012 (2009).
Mostapha, M. & Styner, M. Role of deep learning in infant brain MRI analysis. Magn. Reson. Imaging 64, 171–189. https://doi.org/10.1016/j.mri.2019.06.009 (2019).
Saha, S. et al. Predicting motor outcome in preterm infants from very early brain diffusion MRI using a deep learning convolutional neural network (CNN) model. Neuroimage 215, 116807. https://doi.org/10.1016/j.neuroimage.2020.116807 (2020).
Baker, S. & Kandasamy, Y. Machine learning for understanding and predicting neurodevelopmental outcomes in premature infants: A systematic review. Pediatr. Res. 93(2), 293–299. https://doi.org/10.1038/s41390-022-02120-w (2023).
Scheinost, D. et al. Machine learning and prediction in fetal, infant, and toddler neuroimaging: A review and primer. Biol. Psychiatry S0006–3223(22), 01706–01711. https://doi.org/10.1016/j.biopsych.2022.10.014 (2022).
Fatima, A., Shahid, A. R., Raza, B., Madni, T. M. & Janjua, U. I. State-of-the-art traditional to the machine- and deep-learning-based skull stripping techniques, models, and algorithms. J. Digit. Imaging 33(6), 1443–1464. https://doi.org/10.1007/s10278-020-00367-5 (2020).
Khalili, N. et al. Automatic extraction of the intracranial volume in fetal and neonatal MR scans using convolutional neural networks. Neuroimage Clin. 24, 102061. https://doi.org/10.1016/j.nicl.2019.102061 (2019).
George, M. M. & Kalaivani, S. A view on atlas-based neonatal brain MRI segmentation. In ICTMI 2017 (eds Gulyás, B. et al.) 199–214 (Singapore, Springer, 2019). https://doi.org/10.1007/978-981-13-1477-3_16.
Wang, G. et al. Impacts of skull stripping on construction of three-dimensional T1-weighted imaging-based brain structural network in full-term neonates. BioMed. Eng. OnLine 19(1), 41. https://doi.org/10.1186/s12938-020-00785-0 (2020).
Serag, A. et al. Accurate Learning with Few Atlases (ALFA): An algorithm for MRI neonatal brain extraction and comparison with 11 publicly available methods. Sci. Rep. 6, 23470. https://doi.org/10.1038/srep23470 (2016).
Gao, Y. et al. A multi-view pyramid network for skull stripping on neonatal T1-weighted MRI. Magn. Reson. Imaging 63, 70–79. https://doi.org/10.1016/j.mri.2019.08.025 (2019).
Alansary, A. et al. Infant brain extraction in T1-weighted MR images using BET and refinement using LCDG and MGRF models. IEEE J. Biomed. Health Inform. 20(3), 925–935. https://doi.org/10.1109/JBHI.2015.2415477 (2016).
Zhang, Q., Wang, L., Zong, X., Lin, W,. Li, G. & Shen, D. Frnet: Flattened residual network for infant MRI skull stripping. In 2019 IEEE 16th International Symposium on Biomedical Imaging. vol. 2019 (2019) 999–1002. https://doi.org/10.1109/ISBI.2019.8759167
Shattuck, D. W., Sandor-Leahy, S. R., Schaper, K. A., Rottenberg, D. A. & Leahy, R. M. Magnetic resonance image tissue classification using a partial volume model. Neuroimage 13(5), 856–876. https://doi.org/10.1006/nimg.2000.0730 (2001).
Smith, S. M. Fast robust automated brain extraction. Hum. Brain Mapp. 17(3), 143–155. https://doi.org/10.1002/hbm.10062 (2002).
Iglesias, J. E., Liu, C.-Y., Thompson, P. M. & Tu, Z. Robust brain extraction across datasets and comparison with publicly available methods. IEEE Trans. Med. Imaging 30(9), 1617–1634. https://doi.org/10.1109/TMI.2011.2138152 (2011).
Eskildsen, S. F. et al. BEaST: Brain extraction based on nonlocal segmentation technique. Neuroimage 59(3), 2362–2373. https://doi.org/10.1016/j.neuroimage.2011.09.012 (2012).
Devi, C. N., Chandrasekharan, A., Sundararaman, V. K. & Alex, Z. C. Neonatal brain MRI segmentation: A review. Comput. Biol. Med. 64, 163–178. https://doi.org/10.1016/j.compbiomed.2015.06.016 (2015).
Ségonne, F. et al. A hybrid approach to the skull stripping problem in MRI. Neuroimage. 22(3), 1060–1075. https://doi.org/10.1016/j.neuroimage.2004.03.032 (2004).
Brummer, M. E., Mersereau, R. M., Eisner, R. L. & Lewine, R. J. Automatic detection of brain contours in MRI data sets. IEEE Trans. Med. Imaging. 12(2), 153–166. https://doi.org/10.1109/42.232244 (1993).
Somasundaram, K. & Kalaiselvi, T. Fully automatic brain extraction algorithm for axial T2-weighted magnetic resonance images. Comput. Biol. Med. 40(10), 811–822. https://doi.org/10.1016/j.compbiomed.2010.08.004 (2010).
Kalavathi, P. & Prasath, V. B. S. Methods on skull stripping of MRI head scan images-a review. J. Digit. Imaging 29(3), 365–379. https://doi.org/10.1007/s10278-015-9847-8 (2016).
Makropoulos, A., Counsell, S. J. & Rueckert, D. A review on automatic fetal and neonatal brain MRI segmentation. Neuroimage 170, 231–248. https://doi.org/10.1016/j.neuroimage.2017.06.074 (2018).
Salehi, S. S. M., Erdogmus, D. & Gholipour, A. Auto-context Convolutional Neural Network (Auto-Net) for brain extraction in magnetic resonance imaging. IEEE Trans. Med. Imaging 36(11), 2319–2330. https://doi.org/10.1109/TMI.2017.2721362 (2017).
Chen, J. V. et al. Factors and labor cost savings associated with successful pediatric imaging without anesthesia: A Single-Institution Study. Acad. Radiol. S1076–6332(22), 00697–00703. https://doi.org/10.1016/j.acra.2022.12.041 (2023).
CABINET | Zenodo. https://zenodo.org/record/7843888. Accessed June 22, 2023.
Wang, L. et al. iBEAT V2.0: A multi-site applicable, deep learning-based pipeline for infant cerebral cortical surface reconstruction. Nat. Protoc. 18(5), 1488–1509. https://doi.org/10.1038/s41596-023-00806-x (2023).
Wu, Y. W. et al. Trial of erythropoietin for hypoxic-ischemic encephalopathy in newborns. N Engl. J. Med. 387(2), 148–159. https://doi.org/10.1056/NEJMoa2119660 (2022).
Juul, S. E. et al. High-dose erythropoietin for asphyxia and encephalopathy (HEAL): A randomized controlled trial—background, aims, and study protocol. Neonatology 113(4), 331–338. https://doi.org/10.1159/000486820 (2018).
Wisnowski, J. L. et al. Integrating neuroimaging biomarkers into the multicentre, high-dose erythropoietin for asphyxia and encephalopathy (HEAL) trial: Rationale, protocol and harmonisation. BMJ Open 11(4), e043852. https://doi.org/10.1136/bmjopen-2020-043852 (2021).
Isensee, F., Jaeger, P. F., Kohl, S. A. A., Petersen, J. & Maier-Hein, K. H. nnU-Net: A self-configuring method for deep learning-based biomedical image segmentation. Nat. Methods 18(2), 203–211. https://doi.org/10.1038/s41592-020-01008-z (2021).
Ronneberger, O., Fischer, P. & Brox, T. U-Net: Convolutional networks for biomedical image segmentation. arXiv: https://doi.org/10.48550/arXiv.1505.04597 (2015).
Yushkevich, P. A. et al. User-guided 3D active contour segmentation of anatomical structures: Significantly improved efficiency and reliability. Neuroimage 31(3), 1116–1128. https://doi.org/10.1016/j.neuroimage.2006.01.015 (2006).
Edwards, A. D. et al. The developing human connectome project neonatal data release. Front. Neurosci. https://doi.org/10.3389/fnins.2022.886772 (2022).
Evans, A. C. & The, N. I. H. MRI study of normal brain development. NeuroImage 30(1), 184–202. https://doi.org/10.1016/j.neuroimage.2005.09.068 (2006).
Acknowledgements
The authors would like to thank and acknowledge all the members of the HEAL MRI committee who harmonized, processed, and curated the MRI data used in this study: Jessica Wisnowski, Bob McKinstry, and Amit Mathur
Author information
Authors and Affiliations
Contributions
J.V.C.: study design, literature search, data acquisition or analysis, manuscript drafting, manuscript figures/tables, manuscript revision. Y.L.: study design, data acquisition or analysis, manuscript drafting, manuscript revision. F.T.: data acquisition or analysis, manuscript drafting, manuscript figures/tables, manuscript revision. G.C.: data acquisition or analysis, manuscript revision. C.L.: manuscript revision. A.L.: manuscript revision. AMR: manuscript revision. A.P.H.: manuscript figures/tables, manuscript revision. Y.W.W.: data acquisition or analysis, manuscript revision. E.C.: study design, literature search, data acquisition or analysis, manuscript drafting, manuscript figures/tables, manuscript revision. All authors reviewed and approved final manuscript.
Corresponding author
Ethics declarations
Competing interests
Authors have no relevant disclosures. AMR otherwise discloses, unrelated to this work: Research support from GE Healthcare; Consulting income from Arterys, Inc (now Tempus).
Additional information
Publisher's note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Chen, J.V., Li, Y., Tang, F. et al. Automated neonatal nnU-Net brain MRI extractor trained on a large multi-institutional dataset. Sci Rep 14, 4583 (2024). https://doi.org/10.1038/s41598-024-54436-8
Received:
Accepted:
Published:
DOI: https://doi.org/10.1038/s41598-024-54436-8
Comments
By submitting a comment you agree to abide by our Terms and Community Guidelines. If you find something abusive or that does not comply with our terms or guidelines please flag it as inappropriate.
