
Abstract
Due to excessive streamflow (SF), Peninsular Malaysia has historically experienced floods and droughts. Forecasting streamflow to mitigate municipal and environmental damage is therefore crucial. Streamflow prediction has been extensively demonstrated in the literature to estimate the continuous values of streamflow level. Prediction of continuous values of streamflow is not necessary in several applications and at the same time it is very challenging task because of uncertainty. A streamflow category prediction is more advantageous for addressing the uncertainty in numerical point forecasting, considering that its predictions are linked to a propensity to belong to the pre-defined classes. Here, we formulate streamflow prediction as a time series classification with discrete ranges of values, each representing a class to classify streamflow into five or ten, respectively, using machine learning approaches in various rivers in Malaysia. The findings reveal that several models, specifically LSTM, outperform others in predicting the following n-time steps of streamflow because LSTM is able to learn the mapping between streamflow time series of 2 or 3 days ahead more than support vector machine (SVM) and gradient boosting (GB). LSTM produces higher F1 score in various rivers (by 5% in Johor, 2% in Kelantan and Melaka and Selangor, 4% in Perlis) in 2 days ahead scenario. Furthermore, the ensemble stacking of the SVM and GB achieves high performance in terms of F1 score and quadratic weighted kappa. Ensemble stacking gives 3% higher F1 score in Perak river compared to SVM and gradient boosting.
Similar content being viewed by others


Introduction
More people are being harmed by floods worldwide. According to UNISDR1, flooding is the primary cause of natural disasters globally, accounting for 90% of all catastrophes. Rivers in Malaysia exhibit significant seasonality, with most peak flows concentrating on torrential rains from the monsoon in the north-east and south-west due to their closeness to the equator2,3. Consequently, consistent rain causes rivers to overflow their banks, which causes a considerable volume of streamflow to pass through4. Malaysia has had several large floods throughout its history, most notably the worst floods ever in 2006 and 2007, which resulted in significant losses for the government and total economic devastation5. The recent rapid population growth within the river's basin diminishes river capacity and accelerates streamflow, increasing flood amplitude and duration6. These factors, along with climate changes, has further substantial the frequent occurrence of flood in Malaysia7. A simple and low-cost tool for monitoring flood occurrence is streamflow time series monitoring, an effective indicator of trends and changes in the hydro-climatic system8,9.
In a generic machine learning context, time series analysis may theoretically be viewed as either a classification or a regression situation. Machine learning streamflow regression has been the most often studied topic in streamflow predicting research10,11. Hydrologists often distinguish this form of prediction as numerical forecasting in streamflow regression tasks, where they generate a single-point estimate of its expected value. Early in the year, time series forecasting included models like ARIMA and ARIMAX. However, there is substantial evidence that models based on linearity assumption do not provide good forecasts in streamflow forecasting12. These models make predictions based on the dataset's correlation through autocorrelation and partial autocorrelation functions. Recognizing that the linear assumption is inadequate for complicated time series forecasting, researchers proposed an artificial neural network (ANN), which functions as a universal approximation function13. Other often used machine learning algorithms include random forest (RF)14,15 and gradient boosting (GB)16,17. And when uncertainty is factored in, the predicting process may be quantified using probability forecasting, another form of regression18. In practice, the over-fitting problem encountered makes it difficult for machine learning to forecast the continuous value with 100% accuracy19. A model that does well on both the training and testing datasets is often favorable in machine learning. In essence, the model gathers enough knowledge about the dataset from the inputs to make a generalized judgment20.
Contrastingly, a classification task focuses on classifying the prediction into one of the many predetermined categories21. The easiest way to categorize streamflow is as a binary task, where streamflow may either be increased or decreased. The theoretical complexity of the multi-class classification problem is greater than that of the binary task, as streamflow is divided into more than two class labels, necessitating additional decision-making19,22. The fact that streamflow classification considers more than simply whether or not the streamflow will change today should be stressed. The predicted streamflow classifications are linked to the likelihood of belonging to each class. However, transitioning a time series regression to a classification need careful planning since categorization entails a forced-choice presumptive decision with discrete, rather than stochastic, outcomes23. There are situations in the real world where something is not definite, such as "It will rain today," and categorization them is not the best course of action. Though—a streamflow classification can be beneficial, especially in reservoir operations, where it is sometimes necessary to discretize the storage stage in order to derive the operational rule for optimizing the reservoir system24. Recently, an illustration of streamflow classification may be seen in the study by Chong, Huang25, where they examined two distinct streamflow machine learning formulations. They discovered that scenario-based streamflow forecasts outperform point forecasts in terms of accuracy. However, they also noted that in the absence of other predictors or data-preprocessing techniques, their findings could be biased in favour of univariate streamflow. Given the constraints imposed by numerical point forecasting, classifying streamflow outputs would necessitate a more thorough analysis and potentially a better decision to develop streamflow forecasting.
Another crucial consideration is the choice of a hydrological model. The advent of machine learning may allow a data-driven model to function better compared to a process-driven model but at the price of the physical interpretation of hydrological processes26. The current transition to data-driven modeling may be due to the difficulty in fully comprehending the interactions that underlie the hydrological processes, which limits the efficacy of a process-driven model27. Despite the reformulation from regression to classification, we hypothesize that the streamflow time series still retain their temporally ordered structure, characterizing them from other TSCs that do not make any assumptions regarding temporal dependency. Typical classification algorithms are not well adapted to such a task since they do not incorporate the time component28. Developing an effective AI model to carry out this classification process is therefore necessary. Deep learning technologies, such as long short-term memory (LSTM), give additional feature extraction capabilities that might be used to supplement classic classifier algorithms' lack of time-dependent components. It may collect time series and memorize long-term associations using the memory storage capabilities of LSTM by applying many gates that regulate the information flow. Such qualities may be seen in a variety of applications where sequential information flow is crucial, including robotic control29, handwriting recognition30, and even time series prediction31.
The format of this paper is as follows: Section "Previous works" introduces the previous works related to this study; In Section "The significance of study", the significance of the study is discussed. Section "Materials and methods" describes the dataset used and demonstrates the machine learning and deep learning algorithms used. Section "Results and discussion" presents the results and discussion; Section “Conclusion and future work” summarises the conclusions and recommendations for future research.
Previous works
Probabilistic methods
In case water demand, allocation, and flooding event prediction, several studies have considered probabilistic methods to predict the chance of flood. Monte Carlo techniques have been utilized to estimate the probability of a region being impacted by a cyclone any year32. Monte Carlo method was found to be easy to implement and can continuously be improved with more data collected over years.
To respond to emergency cases and sudden rainstorms and flooding, integration of decision makers' emotions, dynamic Bayesian network and Dempster–Shafer (DS) evidence theory was proposed33. Bayesian network worked effectively to simulate the dynamic change process. Additionally, the DS evidence theory can reduce the subjectivity of the model in dealing with the uncertainty of the evolution process. Another study was demonstrated to help on “scenario-response" paradigm. The target heavy rain event was studied to examine the intricate evolution of emergency response utilizing a constructed scenario Bayesian network34. This network was built by fusing the knowledge meta-theory, scenario evolution and Dempster's rule.
To assess the risk and zone the flood disaster, another study was conducted35 to highlight the high-risk areas clarifying the reasons behind the potential hazards. The authors analysed the disaster system theory and established the flood disaster evaluation index system for urban agglomerations.
Machine Learning methods
Artificial neural networks (ANNs) have been used as a useful soft computing tool to predict future water availability from a catchment in real-world scenario36. The utilization of ANN was proposed due to the absence of intensive data, which are required for modelling practices in the context of hydrology. Levenberg–Marquardt ANN was able to give good prediction performance37.
Another study compared stacked model that combines random forest and multilayer perceptron through elastic net with bidirectional long short-term memory networks for multiple steps ahead streamflow prediction38. It was found that the stacked model outperformed the model based on bidirectional LSTM in many cases in predicting the highest flow rate but it was less accurate in predicting low flow rate. The prediction accuracy of both models decreased by increasing the length of the time series. The stacked model has shorter computation times than the bidirectional LSTM.
The evaluation and comparison between various deep learning models including convolutional neural networks (CNN), long short-term memory (LSTM), and self-attention (SA)-LSTM models, with simple extreme learning machine (ELM) model was demonstrated for monthly streamflow prediction39. The experiments targeted to predict an unprecedented hydrologic event such as no-flow events and extreme floods. SA–LSTM model was proved to be an effective streamflow prediction model for extreme events.
Explainable AI with long short-term memory (LSTM) has been explored in the literature to predict the streamflow40. In their study, the authors utilized the model's explainability using Shapley additive explanations method (SHAP). It was discovered that LSTM model's explainability in predicting the streamflow was enhanced by the SHAP method.
The significance of study
Forecasting streamflow lowers the risk of flooding and reservoirs while enhancing the management and planning of water resources. Due to its ability to detect the non-linarites and short- or long-term temporal interrelationship, statistical and machine learning techniques have been applied for streamflow forecasting challenges. However, the machine learning models with multivariate streamflow forecasting may be affected by over-fitting problem and inability to predict exact values of streamflow. To address the aforementioned issue, streamflow categorization approach has been proposed in this study to extract patterns from streamflow data and map these features to specific categories.
Due to the highly non-linear pattern, stochastic nature, and the extremely wide range of the streamflow in the selected rivers as shown in Tables 1 and 2, the water resources management strategy concluded to categorize the streamflow into different classes for each time increment and consider the streamflow class is operational constraints and the major component of the water management policy.
The motivation of this work is to study the possibility of formulating the streamflow prediction task as a classification problem by dividing streamflow into more than five and ten class labels.
The transfer from regression to classification opens the doors to implement various classification models to predict the levels of streamflow which helps for further decision making.
In light of the above, the current work's goal is to examine how deep learning performs in anticipating the streamflow levels in comparison to other classifier algorithms, namely, GB and SVM. Furthermore, an effective technique, stacking ensemble modelling, was also adopted to enhance the performance of the model. Several metrics were used to assess the performance of ML, including accuracy, precision, recall, F1 score, the area under the score, and Quadratic Weighted kappa (QWK).
Materials and methods
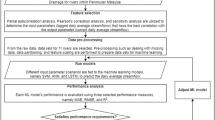
This section covers the methodology of the presented work, as illustrated in a flow chart in Fig. 1. To begin, we give an overview of data collected from eleven rivers used for flow classification. Second, the methods and classification models used for perdition purposes are detailed with their optimal architectures and hyperparameters.

Flow chart of our methodology for streamflow classification using machine learning models.
Data description
The data used for modelling in this work have daily streamflow values collected for a specific duration, as shown in Table 1. The period of data gathering varies from river to river. Kedah river included the most years of the dataset, with a total of 12,419 sample. In contrast, WPKL had the smallest number of years, with only one year’s worth of data, with only 365 samples. Table 2 shows the basic statistical parameters of the streamflow dataset of each river, which differ in sample size.
Figure 2 shows the histogram distribution of streamflow data of each river. As seen in Fig. 2, not all rivers have an identical distribution of streamflow data. The horizontal axis represents the streamflow, and the vertical axis represents the count of the specific range of flow values. The categories (labels) were set according to the range values of streamflow. It is clear that the streamflow samples were abundant in some labels while being scarce in others.

The histogram of streamflow values for eleven rivers.
Figure 3 depicts seasonal variations in streamflow. We can infer that November and December is when most rivers’ average streamflow are at their peak. Additionally, annual variations of streamflow are shown in Fig. 4. Another characteristic of the data is that the average streamflow of many rivers varies depending on the year. The number of years that have daily data collected is also different from one river to another.

The seasonal variations of streamflow values for eleven rivers.

The annual variations of streamflow values for eleven rivers.
Data partitioning
This section describes the experimental procedure and data partitioning. The streamflow dataset for models was split into three parts: training, validation, and testing, using a 60%, 20%, and 20% rule, respectively. Parallel to training data, validation data were used to tune the model’s hyperparameters to discover hidden patterns in the input series. It is crucial to have testing data since it allows for the evaluation of generalizability. Finally, the optimized models with the best architecture and hyperparameters were used to evaluate the model for comparison purposes using the testing dataset.
Feature scaling
MinMax scaler was used to scale the feature vector, including previous n-steps from streamflow time series. This scaler is able to avoid distortion in the data by preserving its shape. Each feature is translated as follows between zero and one as follows:
where min, max = feature range.
Category label annotation
The streamflow was separated into various ranges, with each category generated belonging to one class or label. This paper exhibited two scenarios regarding the number of classes, five and ten. Due to the different characteristics of each river, the modeling required to identify the hidden patterns differ significantly from one another. Tables 3, 4, and 6 show two methods of range division for five and ten categories as follows:
Data balanced method
This method divided the streamflow into ranges (categories), each with the same number of samples.
Equal range method
This method divided the streamflow into ranges using \((\mathrm{maximum }-\mathrm{ minimum})/ 5\) in five-category scenario or \((\mathrm{maximum }-\mathrm{ minimum})/10\) in ten-category scenario to have same length for all caegories.
Table 5 illustrates the algorithm used to formulate the streamflow prediction as a classification problem. This algorithm used ranges available in Tables 3 and 4 for the scenario of five categories utilizing the data balanced and the equal range method. The same algorithm has also been applied in the scenario of ten categories using only the balanced data method, as shown in Table 6.
The proposed classification models
This section discusses classification models used in this work to classify streamflow values into five or ten categories, along with the optimized architectures and hyperparameters. The models included Extreme Gradient Boosting (GB), Support Vector Machine, an ensemble stacked of SVM and GB, and Long Short-Term Memory (LSTM). For each model, several experiments were conducted to select the best architecture and hyperparameters. The criteria for evaluation and selection were based on classification performance metrics such as the F1 score and quadratic weighted kappa (QWK).
Support vector machine (SVM)
The support Vector Machine is one of the models used for the streamflow classification task. SVM is a supervised learning model that can be used for classification tasks. SVM works by separating data vectors at inputs to maximize the margins from these vectors. The transformation is done from a non-linear decision surface to a linear one for a higher number of dimension spaces. SVM offers a number of hyperparameters, including kernel and regularization parameter C. SVM’s kernel is a crucial hyperparameter to turn the inputs into the required form41. We tested various linear and non-linear kernel functions such as Gaussian (RBF), sigmoid, and polynomial kernels to select one that produced better results with validation data. We conducted experiments to select a regularization parameter and kernel carefully. These optimal values can generate the best performance indicators, such as F1 score and QWK. SVM using RBF kernel and regularization factor of 100 was determined to deliver the best F1 score.
During SVM training, the hyperplane is selected to enlarge the distance to the nearest vector. The objective is to minimize the loss function, which is as follows:
where W is a weight vector, b is a bias vector, ϕ is the identity function, and C is a regularization constant.
Non-linear classifiers result from non-linear kernels by computing the inner-product between two \(\phi\) functions as follows :
As a result of optimisation, the predicted class is calculated by summing all support vectors for samples within the margin. Where x is a given sample, α is the dual coefficient and equals zero for the samples outside the margin as follows:
C has an impact on the decision surface. SVM was trained by tuning C to balance between high value of C for correct classification and low value of for smooth decision surface.
The polynomial kernel is non-linear kernel calculated as follows:
where d is the degree.
Gaussian kernel which is called Radial Basis Function (RBF) is a non-linear kernel calculated as follows:
where σ is the standard deviation.
Gradient boosting (GB) classifier
The Gradient boosting is another powerful model used in this work for the streamflow classification task. GB, a tree learning system, is based on an ensemble learning approach42. Figure 5 illustrates the structure of the gradient boosting classifier. The performance of GB is significantly impacted by the hyperparameters, such as learning rate, number of decision trees, and maximum depth. Thus, they need to be tuned carefully to find an optimal architecture and hyperparameters. Several experiments were conducted to evaluate the GB performance for the classification of streamflow values and to find the optimal hyperparameters. These optimal hyperparameters values can generate the best classification performance indicators in terms of F1 score and QWK43,44. It was found that GB with 200 number of trees, 0.01 learning rate, and max depth of 5 outperformed other GB models in terms of F1 score.

The structure and operation of GB (Hearst et al. 1998; Osman et al. 2021).
Stacked ensemble
The stacked ensemble is the third powerful model used in this work for the streamflow classification task. It is an ensemble learning method to find the optimal combination of a collection of classifiers using a stacking process. In order to get the optimum performance, the stacked ensemble also learns how to combine each of the classifiers45. This work investigated the stacked ensemble learning method, which employed a support vector machine and gradient boosting classifiers. The outputs of these classifiers were connected to the meta-learner of the logistic regression classifier to produce the final classification categories of streamflow. The structure of this stacked ensemble classifier is shown in Fig. 6.

The structure of stacked ensemble.
Long short-term memory (LSTM)
The fourth effective model applied for the streamflow classification task was the Long short-term memory model. Recurrent Neural Networks (RNNs) are usually utilized for sequence modeling to capture temporal correlations46. LSTM is one of the RNNs to model the long-range sequences using a memory cell, as shown in Fig. 7, which acts as an accumulator of state information supported by control gates. LSTM structure has the advantage of overcoming the problem of gradient vanishing47. The parameters of LSTM were tuned to fit the data. Table 7 describes the architecture of LSTM. Figure 7 shows the structure of LSTM.

The structure LSTM neural network47.
The LSTM model was trained with training data using the following hyperparameters:
-
(1)
the learning rate was set to 0.001
-
(2)
the batch size was set to 32
-
(3)
the number of epochs was set to 100.
-
(4)
the loss function was categorical cross-entropy
-
(5)
the optimizer was Adam.
In summary, the previously developed models were used to classify the streamflow. The category of streamflow is affected by different factors, such as the history of streamflow values, as will be discussed in the section on experimental results. Each model was trained and evaluated to find the best architecture and hyperparameters for comparison stated in the section on experimental results. Table 8 compares used methods and shows Pros and Cons for each.
Performance metrics
The classification performance was evaluated using several metrics such as Accuracy, Precision, Recall, F1 score, Area Under Curve (AUC), and Quadratic Weighted kappa (QWK).
1. Accuracy is a metric that calculates number of correctly predicted samples over total samples.
where TP: True Positive, TN: True Negative, FP: False Positive, FN: False Negative.
2. Precision (positive predictive value) is a metric to calculate the correctly identified positive samples over all predicted positive samples.
3. Recall (Sensitivity) is a measure that calculates correctly identified positive samples over all actual positive samples.
4. F1 score summarizes recall and precision in one metric.
5. Area Under Curve is a metric to show how much a classifier is robust with a varied threshold.
AUC is an area under receiver operating characteristic (ROC) curve that shows relation between false positive rate and true positive rate.
6. Quadratic Weighted kappa (QWK): Cohen's weighted kappa is a measure of agreement between observed rates, as shown in Table 9. A weighted Kappa is a metric to measure the similarity between predicted and actual values. An optimal score of 1.0 results from a complete match between predicted and actual values. The worst score, however, a -1, is the consequence of a significant difference between predicted and actual values. QWK considers the similarity between the classes beyond exclusively the class. This is suitable when ordinal or ranked variables are available, as presented in this work. The dataset used in this work has five or ten ratings that represent various streamflow value categories. The weight matrix that represents the difference between the ten categories in the ten classes scenario is shown in Table 10. The same concept can be applied to any number of classes.
We evaluated and compared the proposed models in this work using a bag of metrics. The training data was balanced because we used the balanced data method to select the ranges with the same number of samples in each class. However, classifiers evaluation and comparison were carried out using imbalanced testing data. Usually, accuracy is a proper metric to evaluate the performance of the classification model. However, accuracy has a drawback when the data is imbalanced and thus unable to evaluate performance in this work. Therefore, other evaluation metrics such as precision, recall, F1 score, AUC, and QWK were used. The larger values of these five metrics explain better data fitting and higher classification performance. The F1 score is considered an effective metric to measure classification performance with imbalanced data. The drawback of the F1 score is related to one fixed threshold used for classification. To address the previous limitation, AUC was another valuable metric utilized to highlight the robustness of the classification model with a varied threshold. Furthermore, a confusion matrix was also illustrated to show the details of four terms: true positive, true negative, false positive, and false negative.
Experimental setup
The SVM, GB, and stacked ensemble models were trained on an Intel i7-5500U CPU using the scikit learn framework. The LSTM model, on the other hand, was developed on Google Collaboratory on K80 GPU with12 GB of RAM using the TensorFlow framework.
Results and discussion
This section demonstrates various experiments carried out to train and evaluate several machine learning models, including support vector machine, gradient boosting, stacked ensemble, and long short-term memory. These experiments aim to evaluate models’ performance in terms of accuracy, precision, recall, F1 score, AUC, and QWK. In these experiments, the models’ hyperparameters were tuned to optimize the models and produce the best results. Two scenarios related to the number of categories were demonstrated: the streamflow values were divided into five categories in five class scenarios and ten categories in ten classes scenario. We aim to discover hidden patterns from the streamflow data for classification purposes.
Support vector machine
The first set of experiments was conducted to demonstrate the impact of the history of previously observed streamflow to classify the future streamflow values one day ahead using a support vector machine. Using a balanced data method, we examined various values of history (number of previous days) in terms of F1 score, as shown in Tables 11 and 12 for five and ten categories, respectively. The maximum values are highlighted in bold font. The F1 scores were calculated considering the different history of streamflow values to predict one day ahead. The last one, three, five, seven, fifteen, or 30 days were evaluated to find the best F1 score of models in each river in each history value. It is clear that the scenario of 5 categories produced high performance in terms of maximum F1 scores of 81%, 84.0%, 82%, 75%, 62%, 80%, 66%, 80%, 73%, and 73% for Johor, Kedah, Kelantan, Melaka, N9, Pahang, Perak, Perlis, Selangor, Terengganu, respectively. On the other hand, due to the lack of data collected in WPKL, with only 365 samples for only one year, the F1 score is low at 37%. Additionally, the scenario of 10 categories produced a good performance in terms of maximum F1 scores of 66%, 69.0%, 64%, 60%, 65%, 56%, 61%, 58%, and 56% for Johor, Kedah, Kelantan, Melaka, Pahang, Perak, Perlis, Selangor, Terengganu, respectively. On the other hand, due to the lack of data collected in WPKL, with only 365 samples for only one year, the F1 score is low at 17%. Furthermore, the annual variation of N9 illustrates a small range of streamflow and the inability of SVM to capture any pattern in the N9 river’s stream data, resulting in a low F1 score of 34%.
The metrics of SVM, including average accuracy, average recall, average precision, and average F1 score, were calculated for each river data in two scenarios of five classes and ten classes using the balanced data method. In this method, the training samples were distributed evenly between all categories. However, testing data were imbalanced. The metrics shown in Tables 13 and 14 were found for the best model selected according to the maximum F1 score reported in Tables 11 and 12. The empty cells in the AUC column resulted from the unavailability of all classes in testing data, even if they are available in training data.
As discussed earlier, the testing data were imbalanced even though the training data were balanced in the balanced data method. Therefore, accuracy alone is not enough to measure model performance; thus, the F1 score was calculated. Additionally, as well known in machine learning classification methods, an increasing number of categories leads to more complex classification and lower F1 scores.
Gradient boosting
The second set of experiments used gradient boosting to illustrate the influence of previously observed streamflow on classifying the predicted streamflow values one day ahead. We compared various values of history (number of previous days) in terms of F1 score, as shown in Tables 15 and 16 for five and ten categories, respectively, with a balanced data method. The maximum values are highlighted in bold font. The F1 scores were calculated considering the different history of streamflow values to predict one day ahead. The last one, three, five, seven, or fifteen days were evaluated to find the best F1 score of models in each river in each history value. The scenario of 5 categories produced high performance in terms of maximum F1 scores of 80%, 83.0%, 82%, 78%, 64%, 79%, 67%, 80%, 76%, and 74% for Johor, Kedah, Kelantan, Melaka, N9, Pahang, Perak, Perlis, Selangor, Terengganu, respectively. On the other hand, as we mentioned in SVM, the small number of samples collected in WPKL (365 samples) was behind the low F1 score (34%). Additionally, the scenario of 10 categories produced a good performance in terms of maximum F1 scores of 64%, 68.0%, 62%, 60%, 61%, 57%, 63%, 58%, and 58% for Johor, Kedah, Kelantan, Melaka, Pahang, Perak, Perlis, Selangor, Terengganu, respectively. However, the poor F1 score (19%) in WPKL was due to only 365 samples used. The same explanation for the annual variation of N9 from SVM also applied to GB. Due to the narrow range of streamflow in the N9 river, GB was unable to identify the patterns, and as a result, the F1 score was low (47%).
Tables 17 and 18 show the classification report of GB for five and ten categories scenarios, respectively, with a balanced data method. In this method, the training samples were distributed evenly between all categories. Testing data, though, were imbalanced. For each river dataset, the macro average of precision, recall, and F1 score, as well as the average accuracy, were computed. The empty cells in the AUC column resulted from the unavailability of all classes in testing data even though they are available in training data. From previous classification reports, it can be deduced that the performance of the GB model with a balanced data method was high; thus, the GB was able to learn patterns from observed streamflow values.
Stacked ensemble
We carried out the third set of experiments to demonstrate the impact of the history of previously observed streamflow to classify the future streamflow values one day ahead in each river using a stacked ensemble. With a balanced data method, SVM, GB, and stacked ensemble were compared in terms of F1 score as shown in Table 19 for ten categories scenario. The best F1 values regarding various histories of streamflow for each river are highlighted in bold font. Stacked ensemble shows higher performance than SVM and GB in terms of F1 score in a scenario of 10 categories with 67%, 69%, 64%, 61%, 48%, 60%, 59%, and 59% for Johor, Kedah, Kelantan, Melaka, N9, Perak, Selangor, Terengganu, respectively.
The QWK for the stacked ensemble was calculated for ten categories with a data balanced method, as shown in Table 20. The values of QWK were more than 0.82 in all rivers except N9 and WPKL. The high values of QWK (> 0.82) refer to almost perfect agreement between actual and predicted classes. The high QWK evaluates the similarity between the classes in addition to the class. The 0.807 QWK in N9 refers to a substantial agreement, and the 0.31 QWK in WPKL refers to a fair agreement. On the other hand, the values of QWK for several rivers, such as Johor, Kedah, Kelantan, and Pahang, are more than 95% which means the superior performance of the stacked ensemble and its ability to learn informative patterns from streamflow data available in these rivers.
Figure 8 shows the confusion matrix for each river using a stacked ensemble for ten classes scenario. The high capability of the stacked ensemble to classify the streamflow values are so clear from these confusion matrixes. Since the categories in the streamflow prediction task are ordinal, QWK can be an appropriate metric to measure the model's success in classifying data.. The misclassification in this model occurred simply by predicting the incorrect class, which was so close to the actual one. As mentioned before, the testing data were imbalanced, as seen in the confusion matrixes in Fig. 8. Due to the limited streamflow classes in the testing data, Perils river showed only four outputs. The poor findings in WPL are due to a dearth of data from this river.

Confusion matrix for each river using stacked ensemble for ten classes scenario for Johor, Kedah, Kelantan, Melaka, N9, Pahang, Perak, Perlis, Selangor, Terengganu, WPKL ordered from eft to right and from top to down.
Long short-term memory
The results of the fourth set of experiments demonstrated how the LSTM classified the future streamflow one day in advance, given the history of previously observed streamflow. According to Table 21, we utilized the data balanced method to compare various historical streamflow values based on the F1 score for the ten categories to predict one, three and five days ahead. The ten categories scenario yielded strong results, with maximum F1 scores of 66%, 69.0%, 64%, 61%, 63%, 59%, 62%, 60%, and 57% for Johor, Kedah, Kelantan, Melaka, Pahang, Perak, Perlis, Selangor, Terengganu, respectively. In contrast, the poor F1 score (16%) in WPKL was owing to the limited 365 samples. Due to a narrow range of streamflow in the N9 river, which is also the cause for the annual variation of N9, LSTM was unable to capture the patterns, and thus F1 score was low (47%).
The QWK for long short-term memory was calculated for ten categories with a data balanced method, as shown in Table 22. The values of QWK were more than 0.82 in all rivers except N9 and WPKL. The high values of QWK (> 0.82) referred to almost perfect agreement between actual and predicted classes. The 0.79 QWK in N9 denoted to a substantial agreement, but the 0.35 QWK in WPKL implied a fair agreement.
Classification of few days ahead
We added another experiment to explore the capability of a stacked ensemble to generalize and learn new patterns to predict the category of few days ahead. The F1 score of category prediction one-to-three-time steps ahead (days) is shown in Table 23. It is clear that the category prediction of the streamflow one day ahead of SF + 1 outperformed the prediction of the streamflow two days or three days ahead (SF + 2 and SF + 3) in terms of F1 score and QWK. Table 24 shows QWK to predict various days ahead. It is clear that the F1 score and QWK for predictions of 3 days ahead are not high because of complex hidden patterns that are not easy to be discovered for the n days ahead prediction task.
Comparison between models for streamflow classification
Figures 9 and 10 depict the F1 score GB, SVM, and LSTM two and three days ahead of classification, respectively. In the scenario of ten categories for most rivers, including Johor, Kelantan, Melaka, Perak, Perlis, Selangor, and Terengganu, it was discovered that LSTM outperformed GB and SVM. It is crucial to act proactively to avoid risks earlier owing to the model’s capacity to anticipate streamflow class for n ahead days. The LSTM was able to learn the mapping between streamflow time series of 2 or 3 days ahead more than SVM and GB. The performance of SVM and GB is different from one river to another. In other words, in some rivers, SVM outperformed GB, and in others, GB surpassed SVM in terms of F1 score.

Comparison between GB, SVM, and LSTM in terms of F1 score for classification of 2 days ahead in ten classes scenario.

Comparison between GB, SVM, and LSTM in terms of F1 score for classification of 3 days ahead in ten classes scenario.
In summary, the findings in this paper are summarized as follows:
-
(1)
The streamflow prediction was formulated as a time series classification with discrete ranges of values, each representing a class to classify streamflow into five or ten.
-
(2)
Prediction of classes into five categories is more accurate than prediction of 10 categories.
-
(3)
LSTM outperformed others in predicting n-time steps of streamflow because LSTM is able to learn the mapping between streamflow time series of 2 or 3 days ahead more than support vector machine (SVM) and gradient boosting (GB).
-
(4)
Stacked ensemble learning of the SVM and GB achieved higher performance than SVM and GB in terms of F1 score and quadratic weighted kappa.
Conclusion and future work
An investigation of streamflow regression as a classification machine learning approach has been described. Two scenarios-based streamflow classifications were evaluated using four AI-based techniques, namely, SVM, GB, and LSTM, an ensemble stacking model in the majority of the main rivers in Malaysia. Forecasting multiple rivers is essential as it provides spatial forecast information for efficient basin-wide reservoir management. The findings demonstrated that, despite having been used to solve a streamflow classification problem, LSTM's memory-storing capabilities allow it to extract the temporal pattern from the streamflow time series, as evidenced by the highest F1 score in all the selected rivers. In addition, this work's findings could be exploited in any situation where a time series regression is to be transitioned to classification, provided that the forecast outputs are deterministic or mechanical (e.g., reservoir operation). The limitation in this streamflow prediction task is related to uncertainty and complex hidden patterns available in each river. These patterns should be extracted well to produce high performance and accuracy. This leads to inability to build one predictive model for modelling all rivers at the same time. In other words, each river requires a specific predictive model that is able to fit its own patterns. For future works, we intend to explore recent attention based deep learning models after collecting more streamflow data to improve the prediction accuracy. The impact of dam construction on regional precipitation has been investigated in the literature confirming the correlation between dam construction and regional precipitation48. This correlation study can be useful in our future study to explore the correlation between the dam construction and streamflow level categories which plays a significant role to plan the water resources.
Data availability
The finding data of this study is available from the corresponding author upon request.
Code availability
All code used in this study is available from the corresponding author upon request.
References
UNISDR, U. Sendai framework for disaster risk reduction 2015–2030. Proceedings of the 3rd United Nations World Conference on DRR, Sendai, Japan (2015).
Saadi, Z., Shahid, S., Ismail, T., Chung, E.-S. & Wang, X.-J. Trends analysis of rainfall and rainfall extremes in Sarawak, Malaysia using modified Mann-Kendall test. Meteorol. Atmos. Phys. 131(3), 263–77 (2019).
Payus, C. et al. Impact of extreme drought climate on water security in North Borneo: Case study of Sabah. Water 12(4), 1135 (2020).
Zhang, Y. & Najafi, M. R. Probabilistic numerical modeling of compound flooding caused by Tropical Storm Matthew over a data-scarce coastal environment. Water Resour. Res. 56(10), e2020WR28565 (2020).
Chan, N. W. Impacts of disasters and disaster risk management in Malaysia: The case of floods. In Resilience and Recovery in Asian disasters 239–65 (Springer, 2015).
Swain, D. et al. Increased flood exposure due to climate change and population growth in the United States. Earth’s Future. 8(11), e202EF0001778 (2020).
Essam, Y. et al. Predicting streamflow in Peninsular Malaysia using support vector machine and deep learning algorithms. Sci. Rep. 12(1), 1–26 (2022).
Liu, D., Jiang, W., Mu, L. & Wang, S. Streamflow prediction using deep learning neural network: Case study of Yangtze River. IEEE access. 8, 90069–90086 (2020).
Muste, M., Kim, D. & Kim, K. A flood-crest forecast prototype for river floods using only in-stream measurements. Commun. Earth Environ. 3(1), 1–10 (2022).
Wei, Y. et al. Investigation of Meta-heuristics Algorithms in ANN Streamflow Forecasting. KSCE J. Civ. Eng., 2297–2312 (2023).
Chong, K.L. et al. Investigation of cross-entropy-based streamflow forecasting through an efficient interpretable automated search process. Appl Water Sci 13, 6. https://doi.org/10.1007/s13201-022-01790-5 (2023).
Jin, X.-B. et al. Deep hybrid model based on EMD with classification by frequency characteristics for long-term air quality prediction. Mathematics 8(2), 214 (2020).
Nguyen, X. H. Combining statistical machine learning models with ARIMA for water level forecasting: The case of the Red river. Adv. Water Resour. 142, 103656 (2020).
Vishwakarma, S., Zhang, X. & Lyubchich, V. Wheat trade tends to happen between countries with contrasting extreme weather stress and synchronous yield variation. Commun. Earth Environ. 3(1), 1–9 (2022).
Abed, M., Imteaz, M., Ahmed, A. N., Huang, Y. F. Modelling monthly pan evaporation utilising Random Forest and deep learning algorithms. Scientific Reports 12(1). https://doi.org/10.1038/s41598-022-17263-3 (2022).
Kambalimath, S. S. & Deka, P. C. Performance enhancement of SVM model using discrete wavelet transform for daily streamflow forecasting. Environ. Earth Sci. 80(3), 1–16 (2021).
Gibson, P. B. et al. Training machine learning models on climate model output yields skillful interpretable seasonal precipitation forecasts. Commun. Earth Environ. 2(1), 1–13 (2021).
Zhang, W., Quan, H. & Srinivasan, D. Parallel and reliable probabilistic load forecasting via quantile regression forest and quantile determination. Energy 160, 810–819 (2018).
Sarker, I. H. Machine learning: Algorithms, real-world applications and research directions. SN Comput. Sci. 2(3), 1–21 (2021).
Von Rueden, L. et al. Informed Machine Learning: A Taxonomy and Survey of Integrating Knowledge into Learning Systems. arXiv preprint arXiv:190312394 (2019).
Nisbet, R., Miner, G. & Yale, K. Chapter 9 - Classification. In Handbook of Statistical Analysis and Data Mining Applications 2nd edn (eds Nisbet, R. et al.) 169–186 (Academic Press, 2018).
AlDahoul, N. et al. A comparison of machine learning models for suspended sediment load classification. Eng. Appl. Comput. Fluid Mech. 16(1), 1211–1232. https://doi.org/10.1080/19942060.2022.2073565 (2022).
Wynants, L. et al. Three myths about risk thresholds for prediction models. BMC Med. 17(1), 1–7 (2019).
Ma, Y. et al. Spark-based parallel dynamic programming and particle swarm optimization via cloud computing for a large-scale reservoir system. J. Hydrol. 598, 126444 (2021).
Chong, K. et al. Investigation of cross-entropy-based streamflow forecasting through an efficient interpretable automated search process. Appl. Water Sci. 13(1), 1–32 (2023).
Kim, T. et al. Can artificial intelligence and data-driven machine learning models match or even replace process-driven hydrologic models for streamflow simulation?: A case study of four watersheds with different hydro-climatic regions across the CONUS. J. Hydrol. 598, 126423 (2021).
Jia, Y. et al. Water quality modeling in sewer networks: Review and future research directions. Water Res. 202, 117419 (2021).
Pelletier, C., Webb, G. I. & Petitjean, F. Temporal convolutional neural network for the classification of satellite image time series. Remote Sens. 11(5), 523 (2019).
Chen, C.-W., Tseng, S.-P., Kuan, T.-W. & Wang, J.-F. Outpatient text classification using attention-based bidirectional LSTM for robot-assisted servicing in hospital. Information 11(2), 106 (2020).
Shewalkar, A. Performance evaluation of deep neural networks applied to speech recognition: RNN, LSTM and GRU. J. Artif. Intell. Soft Comput. Res. 9(4), 235–245 (2019).
Karevan, Z. & Suykens, J. A. Transductive LSTM for time-series prediction: An application to weather forecasting. Neural Netw. 125, 1–9 (2020).
Xie, X., Xie, B., Cheng, J., Chu, Q. & Dooling, T. A simple Monte Carlo method for estimating the chance of a cyclone impact. Nat. Hazards 107(3), 2573–2582. https://doi.org/10.1007/s11069-021-04505-2 (2021).
Xie, X., Tian, Y. & Wei, G. Deduction of sudden rainstorm scenarios: Integrating decision makers’ emotions, dynamic Bayesian network and DS evidence theory. Nat. Hazards https://doi.org/10.1007/s11069-022-05792-z (2022).
Xie, X., Huang, L., Marson, S. M. & Wei, G. Emergency response process for sudden rainstorm and flooding: scenario deduction and Bayesian network analysis using evidence theory and knowledge meta-theory. Nat. Hazards 117(3), 3307–3329. https://doi.org/10.1007/s11069-023-05988-x (2023).
Gao, C. et al. Risk assessment and zoning of flood disaster in Wuchengxiyu Region, China. Urban Clim. 49, 101562. https://doi.org/10.1016/j.uclim.2023.101562 (2023).
Karunanayake, C., Gunathilake, M. B. & Rathnayake, U. Inflow forecast of Iranamadu reservoir, Sri Lanka, under Projected climate scenarios using artificial neural networks. Appl. Comput. Intell. Soft Comput. 2020, 8821627. https://doi.org/10.1155/2020/8821627 (2020).
Najah, A., El-Shafie, A., Karim, O. A. & Jaafar, O. Integrated versus isolated scenario for prediction dissolved oxygen at progression of water quality monitoring stations. Hydrology and Earth System Sciences 15(8), 2693–2708. https://doi.org/10.5194/hess-15-2693-2011 (2011).
Granata, F., Di Nunno, F. & de Marinis, G. Stacked machine learning algorithms and bidirectional long short-term memory networks for multi-step ahead streamflow forecasting: A comparative study. J. Hydrol. 613, 128431 (2022).
Forghanparast, F. & Mohammadi, G. Using deep learning algorithms for intermittent streamflow prediction in the headwaters of the Colorado River, Texas. Water 14, 2972. https://doi.org/10.3390/w14192972 (2022).
Sushanth, K., Mishra, A., Mukhopadhyay, P. & Singh, R. Real-time streamflow forecasting in a reservoir-regulated river basin using explainable machine learning and conceptual reservoir module. Sci. Total Environ. 861, 160680. https://doi.org/10.1016/j.scitotenv.2022.160680 (2023).
Hearst, M. A., Dumais, S. T., Osuna, E., Platt, J. & Scholkopf, B. Support vector machines. IEEE Intell. Syst. Appl. 13(4), 18–28 (1998).
Friedman, J. H. Greedy function approximation: A gradient boosting machine. Ann. Stat. 29, 1189–232 (2001).
Cohen, J. A coefficient of agreement for nominal scales. Educ. Psychol. Measur. 20(1), 37–46 (1960).
Pontius, R. G. Jr. & Millones, M. Death to Kappa: Birth of quantity disagreement and allocation disagreement for accuracy assessment. Int. J. Remote Sens. 32(15), 4407–4429 (2011).
Wolpert, D. H. Stacked generalization. Neural Netw. 5(2), 241–259 (1992).
AlDahoul, N. et al. Suspended sediment load prediction using long short-term memory neural network. Sci. Rep. 11(1), 1–22 (2021).
Hochreiter, S. & Schmidhuber, J. Long short-term memory. Neural Comput. 9(8), 1735–1780 (1997).
Zhu, X. et al. Impact of dam construction on precipitation: a regional perspective. Mar. Freshw. Res. https://doi.org/10.1071/MF22135 (2022).
Acknowledgements
The authors are grateful to the Department of Irrigation and Drainage (DID) Malaysia for providing data to conduct this study.
Author information
Authors and Affiliations
Contributions
N.A.: Methodology, Software, Writing—Original draft preparation; M.A.M.: Software, Visualization, Formal analysis; K.L.C.: Writing—Original draft preparation, Formal analysis; A.N.A.: Conceptualization, Validation, Data Curation, Writing—Review & Editing; Y.F.H.: Writing—Original draft preparation; M.S.: Validation, Resources, Writing- Original draft preparation; A.E.: Writing—Original draft preparation, supervision.
Corresponding author
Ethics declarations
Competing interests
The authors declare no competing interests.
Additional information
Publisher's note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
AlDahoul, N., Momo, M.A., Chong, K.L. et al. Streamflow classification by employing various machine learning models for peninsular Malaysia. Sci Rep 13, 14574 (2023). https://doi.org/10.1038/s41598-023-41735-9
Received:
Accepted:
Published:
DOI: https://doi.org/10.1038/s41598-023-41735-9
This article is cited by
-
An evaluation of statistical and deep learning-based correction of monthly precipitation over the Yangtze River basin in China based on CMIP6 GCMs
Environment, Development and Sustainability (2024)
-
Predicting daily wind speed using coupled multi-layer perceptron model with water strider optimization algorithm based on fuzzy reasoning and Gamma test
Soft Computing (2024)
Comments
By submitting a comment you agree to abide by our Terms and Community Guidelines. If you find something abusive or that does not comply with our terms or guidelines please flag it as inappropriate.
