
Abstract
Williams syndrome (WS) is a rare genetic condition characterized by high social interest and approach motivation as well as intellectual disability and anxiety. Despite the fact that social stimuli are believed to have an increased intrinsic reward value in WS, it is not known whether this translates to learning and decision making. Genes homozygously deleted in WS are linked to sociability in the general population, making it a potential model condition for understanding the social brain. Probabilistic reinforcement learning was studied with either social or non-social rewards for correct choices. Social feedback improved learning in individuals with Williams syndrome but not in typically developing controls or individuals with other intellectual disabilities. Computational modeling indicated that these effects on social feedback were mediated by a shift towards higher weight given to rewards relative to punishments and increased choice consistency. We conclude that reward learning in WS is characterized by high volatility and a tendency to learn how to avoid punishment rather than how to gain rewards. Social feedback can partly normalize this pattern and promote adaptive reward learning.
Similar content being viewed by others
Introduction
Williams syndrome (WS) is a rare genetic syndrome (prevalence 1: 75001) characterized by strikingly heightened social approach behaviors. Individuals with WS are typically described as “hypersocial”, with a strong social interest, friendliness, and attention to other’s2,3,4,5,6. Parallel to this, most individuals with the condition have an intellectual disability7 and challenges with social cognition8 as well as heightened risk of anxiety9,10 and atypical face perception11,12. The direct cause is a hemizygous deletion of 25–27 genes at 7q11.236. This locus includes genes implicated in the development of the oxytocin system and brain regions important for the social brain in humans such as the amygdala and the orbitofrontal cortex (OFC)13,14,15. The GTF2I and GTF2IRD1 genes typically deleted in WS have been linked to sociability in the general human population13 and the social phenotype of WS, an effect that may be mediated by altered oxytocin (OT) reactivity6,14,16.
Social motivation in Williams syndrome
Atypical social motivation is a common facet of neuropsychiatric conditions including autism and depression and may act as a causal mechanism or treatment target17,18. In contrast, WS is seemingly a rare example of a condition which leads to enhanced rather than reduced social motivation8. Studies of WS may therefore contribute to our understanding of sociability and its’ consequences at the genetic, neural, and behavioral level19. Importantly, the social phenotype of WS is complex and characterized by enhanced social motivation as well as multiple challenges in social domains, including difficulties with emotion recognition and understanding of other’s mental state8. Autistic symptoms are also common6,20,21,22.
Social motivation and learning
Social motivation is hypothesized to influence learning by modulating the intrinsic reward value of social stimuli17,23. In WS, enhanced social motivation has been described as a relative strength. At the same time, social motivation could lead individuals with WS to seek social contacts even if this exposes them to risks24. The above theories rely on the assumption that the increased social motivation commonly observed in WS is reflected by the way individuals with the condition learn from the environment. Surprisingly, research testing this assumption is extremely scarce. Preschoolers with WS were found to imitate actions more when performed by a socially engaging as compared to a neutral model25. Anecdotal evidence suggests that social feedback may improve classroom learning in WS26.
Social reinforcement learning
One of the most important forms of learning consists of adapting one’s actions to maximize the probability of desired outcomes (rewards). For example, a child may learn through trial and error which behaviors in the playground are most likely to result in positive interactions. Probabilistic reward learning is successfully explained by reinforcement learning models, in which action values are updated by prediction errors, or the mismatch between expected and received outcome. Reinforcement learning strategies of individuals or groups can be formalized using computational modeling27,28. Reinforcement learning parameters are in turn linked to dissociable brain regions, supporting their feasibility as biomarkers. Striatal dopaminergic neurons signal prediction errors29. Brain regions including the amygdala and medial prefrontal cortex seem to represent the subjective value of expected and received outcomes, and the balance between reward seeking and avoidance of aversive outcomes (losses)23,29. Prefrontal cortical regions are also implicated in regulation of approach related behaviors. Social rewards (such as positive facial expressions) modulate activity in regions involved in reinforcement learning such as the OFC and the striatum29,30,31. In typically developing populations, social rewards drive reinforcement learning much in the same way as symbolic, appetitive (e.g., food) or monetary rewards23,29,32 and with similar effectiveness30,32,33 (but see Ref.34. However, social feedback may be more effective than non-social feedback in tasks where the stated goal is to understand other’s preferences or mental state32,35,36.
Individuals with WS show structural and functional alterations in brain regions involved in reinforcement learning, including amygdala hypoactivation, structural changes in the amygdala and hippocampus, increased functional connectivity between the medial prefrontal cortex and visual cortical regions6,15,19. In the absence of formalized modelling, it is difficult to examine whether these alterations correspond to specific atypicalities in reward learning. Here, we report results from the first study examining social feedback effects on probabilistic value learning in WS. We hypothesized that social as compared to non-social feedback, would lead to more optimal learning in WS and that this facilitating effect would be stronger than in typically developing (TD) individuals and individuals with intellectual disability (ID) of other etiology. Cognitive modeling was used to characterize the computational mechanisms underlying reward learning under social as compared to non-social feedback.
Methods and materials
Participants
Williams syndrome
Participants were recruited from family and patient organizations and habilitation services in Sweden. Initially, 32 individuals expressed interest in participating and 29 attempted the task. Of these, 3 found the task too demanding and did not complete it and one was excluded due to an ongoing psychotic disorder, resulting in a final sample size of n = 25 (for age and gender proportion, see Table 1).
Twenty-two of the 25 individuals with WS completed a larger clinical assessment. Genetic testing showed a typical deletion in all of these participants. A clinical psychologist or psychiatrist conducted a diagnostic interview for DSM-5 diagnoses with the individual and a caregiver using the Mini International Neuropsychiatric Interview (MINI)37 and rated the severity of anxiety symptoms using the Clinical Global Impression—Severity (CGI-S38), a seven-point scale ranging from “1 = normal, not at all ill” to “7 = among the most extremely ill patients”. For each participant, the highest CGI-S score for any anxiety diagnosis was used as a measure of anxiety severity. For details, see Ref.10. Co-occurring diagnoses were ADHD (n = 3) and autism (n = 4), TICS disorder (n = 1). In line with previous studies9, 15/22 individuals interviewed with the MINI had an on-going anxiety disorder.
Intellectual disability
Inclusion criteria in the ID group was a diagnosis of a rare genetic condition associated with intellectual disability but not hypersociability. Initially, 29 participants expressed interest to participate and 27 attempted the task, of which 3 found it too demanding and did not complete it. Hence, the final ID group included 24 individuals (22q11 deletion syndrome, n = 6; Coffin-Siris syndrome39 n = 10; Fragile X syndrome, n = 3, Sotos syndrome, n = 4). Co-occurring diagnoses were autism (n = 4), ADHD (n = 3), epilepsy (n = 1), specific language impairment (n = 2), and agenesis of the corpus callosum (n = 1). One adult individual who had a cerebellar tumor during early childhood was included, but exclusion of this participant did not change any of the results. Age and gender proportion are shown in Table 1.
Although the sample size was too small to allow statistical comparison between syndromes in the ID group, descriptive statistics are reported in the Supplementary materials (Table S1).
Typical controls (henceforth TD) were recruited through advertisements on university web pages, social media, and through addresses collected from the Swedish tax registry. Inclusion criteria were: no ongoing medication with known psychotropic effects, no psychiatric or neurological condition, and no diagnosed or suspected genetic condition. Initially, 65 individuals agreed to participate and completed the task. Of these, 9 participants older than 52 were excluded to create a comparison group within the age range of the WS and ID groups. The final sample size was n = 56 (age range 6–51) The overall majority of TD adults (n = 35) had completed a university education. Age and gender proportion are shown in Table 1.
Measures of adaptive and intellectual functioning
Parent ratings of adaptive behavior was collected in the ID and WS groups using the Adaptive Behavior Assessment Scale (ABAS, second edition40, n = 8, third edition, n = 2441), a normative sample mean of 100 (SD = 15). No significant group differences were found between the ID or WS groups in general adaptive functioning or in the cognitive or social functioning indices (Table 1). Full-scale IQ was assessed in 16 individuals with WS using the Wechsler intelligence scale for adults, 4th Ed (WISC-IV42, n = 13) or Wechsler Intelligence Scale for Children, 5th Ed (WISC-V43, n = 3) depending on the participants’ age.
TD participants were invited to complete screening of cognitive ability using the Vocabulary subtest of the Wechsler Intelligence Scale for Adults, 4th Edition (WAIS-IV) which is highly correlated with full scale IQ (r > 0.90)42. Scaled scores were converted to standard scores (population mean of 100 and SD = 15) using the formula IQ = 100 + 5*(standard score − 10) and used as a proxy measure for IQ. TD participants screened for IQ (n = 19) received an average score of 102.5 (SD = 10.49) which is close to population average.
Demographic comparisons
As can be seen in Table 1, groups did not differ significantly in age or gender proportion. The WS and ID group did not differ significantly in parent ratings of adaptive functioning whereas the TD group had higher cognitive ability than the WS group.
The Swedish Ethical Review Authority approved the study, which followed the tenets of the Declaration of Helsinki. Written informed consent was obtained from all participants, and from the parents of participants in the WS and ID groups.
Task and procedure
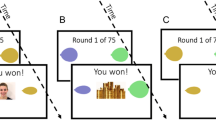
Participants completed two rounds of a probabilistic reward learning task (described in Fig. 1). Each round consisted of 75 trials where participants chose between two stimuli with a reward probability of 2/3 and 1/3, respectively. A correct choice is defined as selection of the stimulus with the highest reward probability. The 1/3 of trials on which the reward contingencies deviated from the overall pattern (i.e., a correct choice resulted in a loss and an incorrect choice in a gain) were predetermined in six unique reinforcement schedules, which were counterbalanced between participants and conditions.

(A,B) Overview of the experiment. Participants completed the social (A) and the non-social feedback condition in counterbalanced order. Each round consisted of 75 trials. Participants were instructed to collect points by choosing between two balloons, and told that one of the options was better. In both conditions, the reward probabilities of the stimuli were 2/3 and 1/3 respectively. Stimulus color and position of the better stimulus (left/right) were counterbalanced between participants and conditions. After selecting one of the two stimuli, participants received either social feedback (an animation of a smiling model, A), or non-social feedback (an animation of a pile of gold coins, B). (C–E) Effects of different values of reinforcement learning parameters. (C) Higher values of α increases the degree of updating of action values after each outcome, leading to increased choice volatility. (D) Higher values of β (exploitation/exploration balance) leads to more deterministic choices, so that participants prefer the stimulus (left, right) with higher action value. (D) The parameter d (loss/reward weight) determines the degree the relative subjective value of losses as compared to wins, so that an agent with d > 0.5 gives higher weight to losses, an agent with d < 0.5 gives higher weight to wins, and d = 0.5 means that equal weight is given to both outcomes.
Twelve participants (WS: n = 2, TD: n = 2, ID: n = 8) completed the task in a research facility, and the rest from home over the internet using a computer or tablet through Pavlovia, a validated system which allows stimulus presentation and reaction time measurement at millisecond precision44 Feedback for correct choice was a written message on the screen (“you won!”) and an animation of a smiling woman in the social condition or a pile of gold coins moving towards the participant in the non-social condition. Feedback for incorrect choice was always an animation of the letter X moving towards the participant together with the text “you lost!”. Condition order, reinforcement schedule, and the stimulus associated with the highest reward probability (right, left) was counterbalanced between participants. Animated facial stimuli were taken from the Amsterdam Dynamic Facial Expression Set (ADFES)45.
Individuals in the WS and ID groups were assisted by parents or habilitation service personnel who received the same written instructions about how to present the task. In this, they were told that they could assist the participant by reading and explaining the instructions and preparing the testing the environment, but that they should not give any help or advice on how to do the actual task. Instructions were also presented in written form at the screen. The instructions stated that the task was to collect points by choosing between two different balloons. Participants were informed that one of the balloons was better, and that they had to figure out which.
Directly following each round, participants rated their affective experience to winning a point, losing a point, and of seeing the model smile (e.g., the social feedback) and the pile of gold coins (e.g., the non-social feedback) (Fig. 1A,B) on an ascending seven grade Likert scale. All groups rated wins higher than losses, and rated both social and non-social feedback as positive (mean values > 3, see Table 1), indicating that the task was perceived as rewarding. Each round started with four practice trials. To validate the task, 10 participants (WS: n = 2, ID: n = 1, TD, n = 7) repeated the task in a research environment. The small sample size prevents meaningful statistical comparisons, but visualizations of the data indicated highly similar values for choice behavior and computational modeling parameters between measurements (see Supplementary materials).
Data rejection
Participants who did not explore both options of the task (> 90% choices of one stimulus, ID: n = 2, TD: n = 2, WS: n = 1) or whose behavior indicated random responses (TD: n = 3, WS: n = 1), were excluded from that condition but included in the other condition. Finally, we excluded data from one TD participant in a condition in which more than 50% of reaction times were quicker than 150 MS, indicating inattention.
Computational modeling
Mathematical modeling allows identification of plausible computational mechanisms underlying observed choice behavior and learning. The method is increasingly used in clinical populations28,48,49, but so far not in WS.
We compared model fit to the data of several reinforcement learning models and alternative, non-learning models (e.g., assuming that participants responded at random or switched between choice alternatives regardless of value feedback. Models were further validated through data simulations. Model comparison and parameter estimation were performed through maximum likelihood estimation using the fminbnd function in MATLAB. Following previous publications, data were analyzed in two stages33. First, for each model, the parameter values which maximized the log likelihood estimate (LLE) of the observed data were selected. In stage two, this procedure was repeated with parameters restrained using Gaussian priors generated in stage one. Specifically, the prior was parametrised with the mean and covariance (joint accross all participants) of the parameters from step 133. This approach has been shown to increase model fit and reduce the risk of extreme parameter values27,33,48. For a detailed description, see Supplementary materials.
Parameters of the winning model are described in Fig. 1C–E. In short, participants update the expected value of the chosen action V(c) at each trial t after seeing the outcome r according to the delta rule (e.g., Ref.28)
Here, \(({r}_{t}-{V\left(c\right)}_{t})\) represents the prediction error and α the learning rate. The expected value of the non-chosen action (V(nc)) updated according to the same equation:
The fact that both actions are updated at each trial was theoretically motivated by the fact that participants were explicitly instructed to learn which of the actions was better, and also provided better fit to the data than models which updated only the chosen options (see Ref.50 for a similar model).
Following previous studies33,51, the outcome value was determined by the free parameter d, so that r = 1 − d if the trial resulted in a win, and r = − d if the trial resulted in a loss. The parameter d therefore indices the relative subjective value of rewards and losses, so that the relative weight given to losses is increased at higher values (henceforth referred to as loss/reward balance). Both outcomes are given equal weight if d = 0.5, an agent with d = 1 learns from losses only, and an agent with d = 0 learns only from wins (see Fig. 1E).
Expected values are transformed into choice probabilities with via the softmax function:
where P(ct) is the probability of choosing stimulus c at trial t, V(ct) is the expected value of stimulus c, and V(nct) the expected value of the other stimulus at trial t. The parameter \(\beta\) ranging from 0 to infinity determines the degree of exploration (Fig. 1B).
Statistical analysis
Parametric statistics were used since skewness and kurtosis of all variables were within the ± 2 and ± 6 range respectively. Linear mixed effects models (LMM) with random intercepts for participant were used to test interaction effects between group and condition and main effects of group (three levels). Results from LMMs and ANOVAs are identical for a perfectly balanced data set but in contrast to ANOVAs, LMMs can handle unbalanced data (i.e., when a participant has valid data from only one condition) without listwise deletion. P-values were computed using chi square tests, where a model containing the effect of interest was compared to the most complex null model without it46. Marginal f2 which represent the proportion of explained variance in the model as compared to the null is reported as effect size47.
Significant interaction effects were followed up using t-tests with p-values corrected for multiple comparisons within each variable using the Bonferroni method. Following previous studies48, we examined the following metrics: the probability of correct choices (p.correct), the probability to switch after wins (p.win-shift) and losses (p.lose-shift), and the overall proportion of repeated choices p.consistent). Average reaction time (lognormal mean) and reaction time variability (lognormal sigma) was calculated for each participant and condition.
Statistical analyses were conducted using R version 4.1.2 (R Core Team) with the level of statistical significance set to p = 0.05. The study had 80% power to detect medium to large effects (d > 0.4).
Results
Reaction times
Significant main effects of group were found on average reaction time and reaction time variability (p < 0.001). Follow-up tests showed that participants with WS and ID were slower and had more variable reaction times than the TD group across conditions (all p < 0.001). No main effects of condition or group x condition interactions were found (all p > 0.10; see Supplementary Materials, Table S2).
Choice behavior
Omnibus models including main effects of group and condition (social, non-social) and group × condition interactions were run for each dependent variable. Results are shown in Table 2. As can be seen, no significant main effects of condition were seen. Main effects of group were found on all choice behavior variables. Bonferroni-corrected pairwise comparisons showed that TD participants made more correct (p.correct) and consistent (p.consistent) choices and were less likely to switch after losses (p.lose-shift) than the WS and ID groups. TD participants were also less likely to switch after wins (p.win-shift) than WS participants, but did not differ from the ID group. No main effects of group were found in pairwise comparisons between WS and ID participants, indicating similar choice behavior when considered across conditions.
As predicted, significant group × condition effects were found on all choice behavior variables, indicating that the effects of condition differed between groups. Group × condition effects were followed up with Bonferroni corrected pairwise comparisons within each group separately to address the hypotheses. These are described in Table 3 and Fig. 2. As can be seen, in the social as compared to the non-social feedback condition, the WS group made more correct choices (p = 0.024, d = 0.58), and were more consistent (p = 0.003, d = 0.55), but did not show significant effects on p.win-shift or p.lose-shift. The ID and TD groups showed no significant effects of condition on any of the behavioral indices. For a visualization of the of p.correct over the course of the task, see Supplementary materials, Fig. S2.

Differences between the social and non-social conditions in choice behavior by group (Stars indicate significant differences from (paired samples t-test, Bonferroni-corrected) for multiple comparisons). Boxplots cover means and 25–75th percentile. *p < 0.05, **p < 0.01. Colored dots show individual participant values.
Computational modeling parameters
Learning rate (α)
There was no significant main effect of condition (χ2 = 2.97, p = 0.226, f2 = 0.018), but a significant effect of group (χ2 = 20.71, p < 0.001, f2 = 0.001). The group × condition interaction was not significant (χ2 = 2.97, p = 0.226, f2 = 0.018). Pairwise follow-up comparisons showed that learning rate was higher in WS and ID than in TD across conditions, whereas no difference was found between the WS and ID groups (Table 4, Fig. 3).

Differences between the social (S) and non-social (N) conditions computational modeling parameters by group. Stars indicate significant differences between conditions (paired samples t-test, Bonferroni-corrected for multiple comparisons). Boxplots cover means and 25–75th percentile. *p < 0.05. Colored dots show individual participant values.
Exploitation/exploration balance (β)
No significant main or interaction effects were found on β (Table 4, Fig. 3).
Loss/reward weight (d)
No significant main effect of condition was found (χ2 = 0.01, p = 0.939, f2 = 0), but the main effect of group (χ2 = 23.62, p = 0, f2 = -0.004) and the group × condition interactions (χ2 = 10.85, p = 0.004, f2 = 0.031) were significant. Follow-up comparisons of the main effect showed that d was higher in the WS and ID groups than in TD across conditions, (all p < 0.01) whereas the WS and ID groups did not differ (Table 4, Fig. 3). Additional Bonferroni-corrected follow-up tests showed that the WS group had lower loss/reward weight in the social as compared to the non-social condition (t (44) = − 2.84, p = 0.027, d = − 0.44), indicating higher relative sensitivity to social rewards over losses. No significant effects of condition were found in the TD (t (108) = 1.72, p = 0.273, d = 0.25) or ID groups (t (40) = − 1.01, p = 0.969, d = − 0.13). For descriptive statistics see Fig. 3 and Supplementary materials, Table S3).
Linear relationships between loss/reward balance parameter values in the social and non-social conditions and CGI-S anxiety scores in the WS group were tested in a post hoc analysis. These relationships were non-significant (all p > 0.30).
Relation between reinforcement learning parameters and task performance
Within the WS group, a strong negative correlation between p.correct choices and loss/reward weight in the social condition was found, rs = − 0.88, p < 0.001. This indicates that better task performance after social feedback in WS was mediated through a shift in the relative subjective value of rewards as compared to losses. A significant, although smaller, correlation was also found in the TD group, rs = − 0.40, p = 0.003, but not in the ID group, rs = − 0.31, p = 0.18.
Discussion
WS is a rare genetic condition with a striking behavioral phenotype characterized by high social motivation, intellectual disability, and high rates of anxiety. This study demonstrates for the first time that social affiliative cues promote optimal decision making (higher probability of correct choices) and modulates reinforcement learning strategies in WS. Social feedback also increased choice consistency in individuals with WS. Computational modeling indicated that this effect could be explained by a shift in the relative subjective values of rewards and punishment towards higher weights given to rewards. Furthermore, at the individual level, lower reward/punishment weights in the social condition were strongly correlated with better task performance (proportion of correct choices) in the WS group.
Notably, the WS group was highly sensitive to losses in both conditions, reflected in reward-loss weights considerably above 0.5 and higher than the TD group (see Fig. 2). Together, these results suggest that in the absence of social feedback, probabilistic learning in WS is biased towards avoiding negative outcomes rather than gaining rewards. Positive social feedback may in turn partly normalize this bias. An interesting question for future longitudinal studies is whether this bias to learn primarily from negative outcomes in WS, is relatively independent of experience or emerges through interaction with the environment.
Social feedback affects loss/reward balance in WS
The WS group did not show an effect of social as compared to non-social feedback on learning rate or exploitation/exploration balance. Instead, social feedback affected the subjective balance between losses and rewards. That is, the beneficial effects of social feedback seem to operate by increasing the relative valuation or rewards versus losses rather than by updating of action values per se. This is in line with theories derived from autism research which suggests that the influence of social motivation on learning goes through an increase in salience of social stimuli17,18. Our results are therefore consistent with the idea that social motivation is increased in WS. Highly volatile performance and fluctuating attention is common in WS. Our results indicate that social feedback may be feasible as a means of reducing these difficulties52.
In contrast to WS, the ID group showed no clear effects of feedback type on behavioral measures or reinforcement learning parameters, demonstrating that the effects seen in WS are not explained by ID per se. Notably, the effects of social feedback seen in WS were also absent in the TD group in line with previous studies32,33,35. In this group, social as compared to non-social feedback reduced the likelihood of repeating a successful choice but did not affect the overall proportion of correct choices or reinforcement learning strategies. These findings again suggest that social feedback has specific effects of reinforcement learning in WS, which are not seen in TD or ID. Previous research in TD has typically shown that social feedback enhances learning to a similar degree as symbolic non-social rewards, although results are somewhat mixed30,35,36. For example, one study reported worse probabilistic learning following social than non-social rewards30. Improved probabilistic learning following social feedback was reported in a number of studies where tasks were presented as being about learning others’ preferences or mental states32,34,36. Since mental state attribution is challenging for many individuals with WS53, an interesting area for future studies is whether facilitating effects of social feedback would extend to this type of task.
Altered reinforcement learning is commonly seen in anxiety disorders and may contribute to their etiology and symptom maintenance. Particularly, anxious populations were found to be more sensitive to losses than controls52,53. Given the high prevalence of anxiety disorders in WS, we speculate that the increased loss sensitivity observed in WS may be a risk factor for the development of anxiety disorders. An interesting question for future studies is how social and non-social feedback for losses would affect reinforcement learning in WS.
Limitations
Some limitations should be mentioned. Sample size in the WS and ID groups was small. The study data were largely collected online. While our results suggests that this is feasible in populations with rare genetic conditions and ID, a limitation of the study is the lack of exact control over the settings in which participants completed the task. However, it should be noted that data collected online and in the lab was highly similar. An additional limitation is that the small sample size in the ID group did not allow formal statistical comparisons between the included conditions (22q11 deletion syndrome, Fragile X syndrome, Coffin-Siris syndrome, and Sotos syndrome). Despite these limitations, the current study contributes to our understanding of WS and the extent to which the previously described social approach motivation in the condition generalizes to learning.
Data availability
Anonymized data will be made available to researchers upon reasonable request.
References
Stromme, P., Bjornstad, P. G. & Ramstad, K. Prevalence estimation of williams syndrome. J. Child. Neurol. 17, 269–271 (2002).
Järvinen, A., Korenberg, J. R. & Bellugi, U. The social phenotype of Williams syndrome. Curr. Opin. Neurobiol. 23, 414–422 (2013).
Jones, W. et al. II. Hypersociability in Williams Syndrome. J. Cogn. Neurosci. 12, 30–46 (2000).
Ng, R., Järvinen, A. & Bellugi, U. Toward a deeper characterization of the social phenotype of Williams syndrome: The association between personality and social drive. Res. Dev. Disabil. 35, 1838–1849 (2014).
Sampaio, A. et al. Insights on social behavior from studying Williams syndrome. Child Dev. Perspect. 12, 98–103 (2018).
Kozel, B. A. et al. Williams syndrome. Nat. Rev. Dis. Primers https://doi.org/10.1038/s41572-021-00276-z (2021).
Miezah, D., Porter, M., Batchelor, J., Boulton, K. & Campos Veloso, G. Cognitive abilities in Williams syndrome. Res. Dev. Disabil. https://doi.org/10.1016/j.ridd.2020.103701 (2020).
van Herwegen, J., Smith, T. J. & Dimitriou, D. Exploring different explanations for performance on a theory of mind task in Williams syndrome and autism using eye movements. Res. Dev. Disabil. 45–46, 202–209 (2015).
Royston, R., Howlin, P., Waite, J. & Oliver, C. Anxiety disorders in Williams syndrome contrasted. J. Autism. Dev. Disord. 47, 3765–3777 (2017).
Willfors, C. et al. Williams syndrome: On the role of intellectual abilities in anxiety. Orphanet. J. Rare Dis. 16, 1–10 (2021).
Kleberg, J. L., Riby, D., Fawcett, C., Björlin Avdic, H., Frick, M. A., Brocki, K. C. et al. Williams syndrome: reduced orienting to other’s eyes in a hypersocial phenotype. J. Autism Dev. Disord. 1–12 (2022).
D’Souza, D. et al. Face processing in Williams syndrome is already atypical in infancy. Front. Psychol. 6, 760 (2015).
Crespi, B. J. & Procyshyn, T. L. Williams syndrome deletions and duplications: Genetic windows to understanding anxiety, sociality, autism, and schizophrenia. Neurosci. Biobehav. Rev. 79, 14–26 (2017).
Barak, B. et al. Neuronal deletion of Gtf2i, associated with Williams syndrome, causes behavioral and myelin alterations rescuable by a remyelinating drug. Nat. Neurosci. 22, 700–708 (2019).
Barak, B. & Feng, G. Neurobiology of social behavior abnormalities in autism and Williams syndrome. Nat. Neurosci. 19, 647–655 (2016).
Procyshyn, T. L., Spence, J., Read, S., Watson, N. V. & Crespi, B. J. The Williams syndrome prosociality gene GTF2I mediates oxytocin reactivity and social anxiety in a healthy population. Biol. Lett. https://doi.org/10.1098/RSBL.2017.0051 (2017).
Bottini, S. Social reward processing in individuals with autism spectrum disorder: A systematic review of the social motivation hypothesis. Res. Autism Spectr. Disord. 45, 9–26 (2018).
Chevallier, C., Kohls, G., Troiani, V., Brodkin, E. S. & Schultz, R. T. The social motivation theory of autism. Trends Cogn. Sci. 16, 231–239 (2012).
Meyer-Lindenberg, A., Mervis, C. B. & Faith Berman, K. May): Neural mechanisms in Williams syndrome: A unique window to genetic influences on cognition and behaviour. Nat. Rev. Neurosci. 7, 380–393 (2006).
Glod, M., Riby, D. M. & Rodgers, J. Short report: Relationships between sensory processing, repetitive behaviors, anxiety, and intolerance of uncertainty in autism spectrum disorder and Williams syndrome. Autism Res. 12, 759–765 (2019).
Klein-Tasman, B. P., Phillips, K. D., Lord, C., Mervis, C. B. & Gallo, F. J. Overlap with the autism spectrum in young children with Williams syndrome. J. Dev. Behav. Pediatr. 30, 289–299 (2009).
Klein-Tasman, B. P., van der Fluit, F. & Mervis, C. B. Autism spectrum symptomatology in children with Williams syndrome who have phrase speech or fluent language. J. Autism Dev. Disord. 48, 3037–3050 (2018).
Olsson, A., Knapska, E. & Lindström, B. The neural and computational systems of social learning. Nat. Rev. Neurosci. 21, 197–212 (2020).
Ridley, E., Riby, D. M., Leekam, S. R. A cross-syndrome approach to the social phenotype of neurodevelopmental disorders: Focusing on social vulnerability and social interaction style. (2020). https://doi.org/10.1016/j.ridd.2020.103604.
Vivanti, G., Hocking, D. R., Fanning, P. & Dissanayake, C. Social affiliation motives modulate spontaneous learning in Williams syndrome but not in autism. Mol. Autism 7, 1–13 (2016).
Reis, S. M., Schader, R., Milne, H. & Stephens, R. Music & minds: Using a talent development approach for young adults with Williams syndrome. Except. Child. 69, 293–313 (2003).
Daw, N. D. Trial-by-trial data analysis using computational models. In Decision Making, Affect, and Learning: Attention and Performance XXIII. (eds. Delgado, M. R., Phelps, E. A., Robbins, T. W.) (Oxford University Press, 2011).
Zhang, L., Lengersdorff, L., Mikus, N., Gläscher, J. & Lamm, C. Using reinforcement learning models in social neuroscience: Frameworks, pitfalls and suggestions of best practices. Soc. Cogn. Affect Neurosci. 15, 695–707 (2020).
Ruff, C. C. & Fehr, E. The neurobiology of rewards and values in social decision making. Nat. Rev. Neurosci. 15, 549–562 (2014).
Lin, A., Adolphs, R. & Rangel, A. Social and monetary reward learning engage overlapping neural substrates. Soc. Cogn. Affect. Neurosci. 7, 274–281 (2012).
Ferdinand, N. K. & Hilz, M. Emotional feedback ameliorates older adults’ feedback-induced learning. PLoS One https://doi.org/10.1371/journal.pone.0231964 (2020).
Frey, A. L., Frank, M. J. & McCabe, C. Social reinforcement learning as a predictor of real-life experiences in individuals with high and low depressive symptomatology. Psychol. Med. https://doi.org/10.1017/S0033291719003222 (2019).
Hurlemann, R. et al. Behavioral/systems/cognitive oxytocin enhances amygdala-dependent, socially reinforced learning and emotional empathy in humans. J. Neurosci. 30, 4999–5007 (2010).
Gorlick, M. A. et al. Attenuating age-related learning deficits: Emotional valenced feedback interacts with task complexity. Emotion 13, 250–261 (2013).
Colombo, M., Stankevicius, A. & Seriès, P. Benefits of social vs. non-social feedback on learning and generosity. Results from the Tipping Game. Front. Psychol. https://doi.org/10.3389/fpsyg.2014.01154 (2014).
Sheehan, D. V. et al. The Mini-International Neuropsychiatric Interview (M.I.N.I.): The development and validation of a structured diagnostic psychiatric interview for DSM-IV and ICD-10.—PsycNET. J. Clin. Psychiatry 59(Suppl 20), 22–33 (1998).
Zaider, T. I., Heimberg, R. G., Fresco, D. M., Schneier, F. R. & Liebowitz, M. R. Evaluation of the Clinical Global Impression Scale among individuals with social anxiety disorder. Psychol. Med. 33, S0033291703007414 (2003).
Sluijs, P. J. et al. The ARID1B spectrum in 143 patients: From nonsyndromic intellectual disability to Coffin–Siris syndrome. Genet. Med. https://doi.org/10.1038/s41436 (2022).
Harrison, P., Oakland, T. Adaptive Behavior Assessment System—Second Edition (ABAS-II) (Harcourt Assessment, 2003).
Harrison, P., Oakland, T. Adaptive Behavior Assessment System, 3d.Ed. (ABAS-3) (Western Psychological Services, 2015).
Wechsler, D. Wechsler Adult Intelligence Scale—Fourth Edition. (Pearson, 2008).
Wechsler, D. Wechsler Intelligence Scale for Children 5th edn. (Pearson, 2014).
Bridges, D., Pitiot, A., MacAskill, M. R. & Peirce, J. W. The timing mega-study: Comparing a range of experiment generators, both lab-based and online. PeerJ 8, e9414 (2020).
van der Schalk, J., Hawk, S. T., Fischer, A. H. & Doosje, B. Moving faces, looking places: Validation of the Amsterdam Dynamic Facial Expression Set (ADFES). Emotion 4, 907 (2011).
Baayen, R. H., Davidson, D. J. & Bates, D. M. Mixed-effects modeling with crossed random effects for subjects and items. J. Mem. Lang. https://doi.org/10.1016/j.jml.2007.12.005 (2008).
Nakagawa, S. & Cuthill, I. C. Effect size, confidence interval and statistical significance: A practical guide for biologists. Biol. Rev. 82, 591–605 (2007).
den Ouden, H. E. M. et al. Dissociable effects of dopamine and serotonin on reversal learning. Neuron 80, 1090–1100 (2013).
Guath, M. et al. Pupil dilation during negative prediction errors is related to brain choline concentration and depressive symptoms in adolescents. Behav. Brain Res. 436, 114060 (2023).
Klein, T. A., Ullsperger, M. & Jocham, G. ARTICLE Learning relative values in the striatum induces violations of normative decision making. Nat. Commun. 8, 16033 (2017).
Gold, J. M. et al. Negative symptoms and the failure to represent the expected reward value of actions behavioral and computational modeling evidence. Arch. Gen. Psychiatry 69, 129–138 (2012).
Shalev, N. et al. Dynamic sustained attention markers differentiate atypical development: The case of Williams syndrome and Down’s syndrome. Neuropsychologia 132, 107148 (2019).
Pike, A. C. & Robinson, O. J. Reinforcement learning in patients with mood and anxiety disorders vs control individuals: A systematic review and meta-analysis. JAMA Psychiat. https://doi.org/10.1001/jamapsychiatry.2022.0051 (2022).
Mineka, S. & Zinbarg, R. A contemporary learning theory perspective on the etiology of anxiety disorders: It’s not what you thought it was. Am. Psychol. 61, 10–26 (2006).
Acknowledgements
We are grateful to the patients, their families and participants in the control group who helped us to collect the data. We thank Ågrenska National Centre of Competence for Rare Diseases for giving us access to Ågrenska and mediating contact with the patients and their families. Several authors of this publication are members of the European Reference Network on Rare Congenital Malformations and Rare Intellectual Disability ERN-ITHACA [EU Framework Partnership Agreement ID: 3HP-HP-FPA ERN-01-2016/739516]. This work was supported by grants from the Swedish Research Council, the Region Stockholm, Karolinska Institutet, the Swedish Brain Foundation, the Swedish Rare Diseases Research Foundation (Sällsyntafonden), The Hållsten Research Foundation, Sävstaholm foundation, the Promobilia foundation, the Sunnerdahl foundation, the Strategic Research Area Neuroscience (StratNEURO) and the Crown Princess Lovisa Foundation.
Funding
Open access funding provided by Stockholm University.
Author information
Authors and Affiliations
Contributions
J.L.K. designed the task with contributions from C.S. and M.G. J.L.K., C.W., and A.N. designed the study. J.L.K. analyzed the data with contributions from C.S. and M.G. All authors contributed to the interpretation of the results and reviewed the manuscript .
Corresponding author
Ethics declarations
Competing interests
The authors declare no competing interests.
Additional information
Publisher's note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Supplementary Information
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Kleberg, J.L., Willfors, C., Björlin Avdic, H. et al. Social feedback enhances learning in Williams syndrome. Sci Rep 13, 164 (2023). https://doi.org/10.1038/s41598-022-26055-8
Received:
Accepted:
Published:
DOI: https://doi.org/10.1038/s41598-022-26055-8
This article is cited by
-
No transfer of arousal from other’s eyes in Williams syndrome
Scientific Reports (2023)
-
Reduced effects of social feedback on learning in Turner syndrome
Scientific Reports (2023)
Comments
By submitting a comment you agree to abide by our Terms and Community Guidelines. If you find something abusive or that does not comply with our terms or guidelines please flag it as inappropriate.
