
Abstract
Extracting relevant properties of empirical signals generated by nonlinear, stochastic, and high-dimensional systems is a challenge of complex systems research. Open questions are how to differentiate chaotic signals from stochastic ones, and how to quantify nonlinear and/or high-order temporal correlations. Here we propose a new technique to reliably address both problems. Our approach follows two steps: first, we train an artificial neural network (ANN) with flicker (colored) noise to predict the value of the parameter, \(\alpha\), that determines the strength of the correlation of the noise. To predict \(\alpha\) the ANN input features are a set of probabilities that are extracted from the time series by using symbolic ordinal analysis. Then, we input to the trained ANN the probabilities extracted from the time series of interest, and analyze the ANN output. We find that the \(\alpha\) value returned by the ANN is informative of the temporal correlations present in the time series. To distinguish between stochastic and chaotic signals, we exploit the fact that the difference between the permutation entropy (PE) of a given time series and the PE of flicker noise with the same \(\alpha\) parameter is small when the time series is stochastic, but it is large when the time series is chaotic. We validate our technique by analysing synthetic and empirical time series whose nature is well established. We also demonstrate the robustness of our approach with respect to the length of the time series and to the level of noise. We expect that our algorithm, which is freely available, will be very useful to the community.
Similar content being viewed by others


Introduction
Chaotic and stochastic systems have been extensively studied and the fundamental difference between them is well known: in a chaotic system an initial condition always leads to the same final state, following a fixed rule, while in a stochastic system, an initial condition leads to a variety of possible final states, drawn from a probability distribution1. However, the signals generated by chaotic and stochastic systems are not always easy to distinguish and many methods have been proposed to differentiate chaotic and stochastic time series2,3,4,5,6,7,8,9,10.
A related important problem is how to appropriately quantify the strength and length of the temporal correlations present in a time series11,12,13,14. The performance of these methods varies with the characteristics of the time series. As far as we know, no method works well with all data types, because methods have different limitations, in terms of the length of the time series, the level of noise, the stationarity or seasonality of the underlying process, the presence of linear or nonlinear correlations, etc. Moreover, any time series analysis method will return, at least, one number. Therefore, to obtain interpretable results, the values obtained from the analysis of the time series of interest need to be compared with those obtained from other “reference” time series, where we have previous knowledge of the underlying system that generates the data. Here we use as “reference” model a well-known stochastic process: flicker noise (FN).
A FN time series is characterized by a power spectrum \(P(f) \propto 1/f^\alpha\), with \(\alpha\) being a quantifier of the correlations present in the signal15. Flicker noise has been extensively studied in diverse areas such as electronics16,17, biology18,19, physics20,21, economy22,23, meteorology24, astrophysics25, etc. Furthermore, related to this issue, many methods described in the literature are able to evaluate the time correlation quantification \(\alpha\), such as the Hurst exponent \({\mathscr {H}}\)2,11,12,13,15,21,26.
In this paper, we propose a new methodology that simultaneously allows to distinguish chaotic from stochastic time series, and to quantify the strength of the correlations. Our algorithm, based on an Artificial Neural Network (ANN)27, is easy to run and freely available28. We first train the ANN with flicker noise to predict the value of the \(\alpha\) parameter that was used to generate the noise. The input features to the ANN are probabilities extracted from the FN time series using ordinal analysis29, a symbolic method widely used to identify patterns and nonlinear correlations in complex time series30,31,32. Each sequence of D data points (consecutive, or with a certain lag between them), is converted into a sequence of D relative values (smallest to largest), which defines an ordinal pattern. Then, the frequencies of occurrence of the different patterns in the time series define the set of ordinal probabilities, which in turn allow to calculate information-theoretic measures such as the permutation entropy (PE, described in ”Methods”). The PE has been extensively used in the literature, due to the fact that is straightforward to calculate, and it is robust to observational noise. Interdisciplinary applications have been discussed in Ref.33 and, more recently, in a Special Issue34.
After training the ANN with different FN time series, \(x_s(\alpha )\), generated with different values of \(\alpha\), we input to the ANN ordinal probabilities extracted from the time series of interest, x, and analyze the output of the ANN, \(\alpha _{\mathrm {e}}\). We find that \(\alpha _{\mathrm {e}}\) is informative of the temporal correlations present in the time series x. Moreover, by comparing the PE values of x and of \(x_s(\alpha _{\mathrm {e}})\) (a FN time series generated with the value of \(\alpha\) returned by the ANN), we can differentiate between chaotic and stochastic signals: the PE values of x and \(x_s\) are similar when x is mainly stochastic, but they differ when x is mainly deterministic. Therefore, the difference of the two PE values serves as a quantifier to distinguish between chaotic and stochastic signals. We use several datasets to validate this approach. We also analyze its robustness with respect to the length of the time series and noise contamination.
This paper is organized as follows. In the main tex,t we present the results of the analysis of synthetic and empirical time series, which are described in “Datasets”. Typical examples of the time series analyzed are presented in Fig. 1. In ”Methods”, we describe the ordinal method and the implementation of the algorithm, schematically represented in Fig. 2.

Examples of time series analyzed, their probability density functions (PDFs) and power spectral densities (PSDs). (a,b) Time series generated by iteration of the \(\beta x\) map [Eq. (6) with \(\beta =2\)] and its PDF. (c,d) Uniformly distributed white noise and its PDF. We see that the PDF of the deterministic map is identical to the PDF of the noise. (e,f) PSD of the Schuster map, Eq. (8) with parameter \(z=1.5\), and of a Flicker noise with \(\alpha =1\). We note that the PSD of the Schuster map has a long decay that is very similar to a \(1/f^\alpha\) decay of the noise. (g) PDF of m summed logistic maps (Eq. 7 with \(r=4\)), which approaches a Gaussian as m increases. (h–k) Examples of empirical time series analyzed: (h) a stride-to-stride of an adult walking in a slow velocity, interpreted as an stochastic process; (i) daily number of sunspots as a function of time (in years), where its fluctuations are interpreted as stochastic; (k) voltage across the capacitor of an inductor-less Chua electronic circuit, whose oscillations are known to be chaotic.

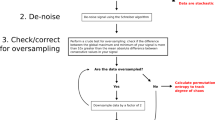
Schematic representation of the methodology. We compute the probabilities of the ordinal patterns and then use them as input features to the ANN. The ANN returns the temporal correlation coefficient \(\alpha _\text{e}\). Then we compare the permutation entropy of the analyzed time series with the permutation entropy of a FN time series generated with the same \(\alpha _\text{e}\) value. Based on this comparison, we use Eq. (1) to classify the time series as chaotic or stochastic.
Results
Analysis of synthetic datasets
The main result is depicted in Fig. 3. Panel (a) shows the normalized permutation entropy \({{\bar{S}}}(\alpha _\text{e})\) (Eq. 4) vs. the time-correlation coefficient \(\alpha _{\mathrm {e}}\). The filled (empty) symbols correspond to different types of stochastic (chaotic) time series, and the solid black line corresponds to FN time series generated with \(\alpha \in [-1,3]\), which is accurately evaluated by the ANN. For \(\alpha _\text{e} = 0\), FN has a uniform power spectrum, characteristic of an uncorrelated signal (white noise), with equal ordinal probabilities \({\mathscr {P}}(i) \approx 1/D!\) and, hence, \({{\bar{S}}} = 1\). Otherwise, for \(\alpha \ne 0\), some ordinal patterns occur in the time series more often than others, and the ordinal probabilities are not all equal, which decreases the permutation entropy. These results are consistent with those that have been obtained by using different methodologies7,10,26.
In Fig. 3, we note that fBm signals have larger time-correlation (\(\alpha _\text{e}\) closer to 2, a classic Brownian motion) than the other three stochastic systems \(\alpha _\text{e} \approx 0\). However, their permutation entropies are very close to those of the FN signals. The key observation is that stochastic time series all fall close to the FN curve, while chaotic ones do not, namely, \(\beta x\) map, Lorenz system, logistic map, skew tent map, and Schuster map. The distance to the FN curve thus serves to distinguish stochastic and chaotic time series. This is quantified by
where \({{\bar{S}}}\) is the permutation entropy of the analyzed time series and \({{\bar{S}}}_{\mathrm {fn}}(\alpha _{\mathrm {e}})\) is the PE of a flicker noise time series generated with the value of \(\alpha\) returned by the ANN, \(\alpha _{\mathrm {e}}\). The results are presented in Fig. 3b, where we see that stochastic signals have \(\Omega \approx 0\), and deterministic signals have \(\Omega > 0\). To summarize this finding, Table 1 depicts \(\alpha _\text{e}\) and \(\Omega\) for ten representative systems.

Temporal correlation and distinction of chaotic and stochastic synthetic signals. Panel (a) shows the normalized permutation entropy \({{\bar{S}}}\) as a function of \(\alpha _{\mathrm {e}}\), evaluated through the ANN, for different time-series (stochastic and chaotic). The black solid line represents FN signals, which are used for training and testing the ANN. Filled symbols represent different stochastic signals, which are very close to the FN curve. Empty symbols represent chaotic signals, which are far away. The distance to the FN curve is measured by \(\Omega\) (Eq. 1) and it is shown in panel (b) higher values of \(\Omega\) indicate chaotic time series, while lower, vanishing values indicate stochastic ones.
Next, we study the applicability of our methodology to noise-contaminated signals. We analyze the signal
where \(X_t\) is a deterministic (chaotic) signal “contaminated” by a uniform white noise, \(Y_{t}\), and \(\eta \in [0,1]\) controls the stochastic component of \(Z_t\). For \(\eta = 0 \, (1)\) the signal is fully deterministic (fully stochastic).
Figure 4a shows \(\Omega\) as a function of \(\eta\) for different chaotic signals. As expected, for \(\eta =0\), \(\Omega\) is high, but as \(\eta\) grows, the level of stochasticity increases and \(\Omega\) decreases. At \(\eta > 0.5\), the signal is strongly stochastic, as reflected by \(\Omega \approx 0.0\). For comparison, in Fig. 4a we also present results obtained by shuffling a chaotic time series. As expected, \(\Omega \approx 0\) for all \(\eta\) because temporal correlations are destroyed by the shuffling process.

Limits for identifying determinism. Panel (a) shows the influence of noise contamination: the quantifier \(\Omega\), Eq. (1) is plotted as a function of the level of noise, \(\eta\), in Eq. (2). We see that as \(\eta\) increases, \(\Omega\) decreases, but it remains, for high values of \(\eta\), different from the value obtained from shuffled data (black pentagons). Therefore, small values of \(\Omega\) can still reveal determinism in noise-contaminated signals. Panel (b) shows the effect of adding several independent chaotic signals: \(\Omega\) is plotted as a function of the number m of signals added. We see that as m increases, \(\Omega\) decreases, indicating that the deterministic nature of the signal can no longer be detected.
We expect that the addition of a sufficiently large number of independent chaotic signals gives a signal that is indistinguishable from a fully stochastic one. This is verified in Fig. 4b, where the horizontal axis represents the number, m, of independent chaotic signals added. Here a high value of \(\Omega\) is observed for \(m = 1\) (a single chaotic signal), but as m increases \(\Omega \rightarrow 0\) since the chaotic nature of added signals is no longer captured (examples of the PDFs of the time series obtained from the addition of m Logistic maps were presented in Fig. 1g, where we can observe a clear evolution towards a Gaussian shape).
To further explore the robustness of our methodology, we investigate the role of the length N of the analyzed time series in the evaluation of the \(\Omega\) quantifier (Eq. 1). Figure 5 shows \(\Omega\) as a function of N, where panel (a) depicts stochastic signals, and (b) chaotic ones. We see that even for \(N<10^{2}\), for all stochastic signals in panel (a) \(\Omega < 0.1\), which indicates that we can identify the stochastic nature of short signals. For the chaotic signals in panel (b), for \(N>10^2\) \(\Omega > 0.1\) (except for \(\beta x\) map), and for \(N \ge 10^{3}\), \(\Omega > 0.2\) for all signals, which demonstrates that our method can also detect determinism in short signals.

Robustness with respect to the time series length. We evaluate \(\Omega\) as a function of the time series length N for stochastic signals (a) and chaotic ones (b). In (a), we observe that even for \(N < 100\), \(\Omega < 0.1\), which confirms the stochastic nature of the signal. In (b), even for \(N < 100\), \(\Omega > 0.1\) (except for \(\beta x\) map). Also, \(\Omega > 0.2\) for all cases for \(N \ge 1000\), which classifies the signals as chaotic even with only 1000 datapoints. The error bars are the standard deviation over 1000 of samples. (c) Mean absolute error, \({\mathscr {E}}\), between the output of the ANN (\(\alpha _{\mathrm {e}}\)), and the parameter \(\alpha\) used to generate the time series of flicker noise (depicted in color-code) as a function of the length of the time series, N.
As discussed in ”Methods”, the ANN was trained with flicker noise signals with \(2^{20}\) data points. However, it is interesting to analyze how much data the trained ANN needs, in order to correctly predict the \(\alpha\) value of a flicker noise time series. To address this point, we generate \(L=1000\) FN time series and analyze the error of the ANN output, \(\alpha _{\mathrm {e}}\), as a function of the length of the time series, N, and of the value of \(\alpha\) used to generate the time series. The results are presented in panel (c) of Fig. 5 that displays the mean absolute error, \({\mathscr {E}} =\frac{1}{L} \sum _ {\ell =1}^ L|\alpha _{\mathrm{e}} - \alpha |\). We see that as N increases, \({\mathscr {E}}\) decreases. The error depends on both, \(\alpha\) and N, and tends to be larger for high \(\alpha\) due to non-stationarity and finite time sampling10. For FN time series longer than \(10^{4}\) datapoints, the ANN returns a very accurate value of \(\alpha\).
Analysis of empirical time series
Here we present the analysis of time series recorded under very different experimental conditions, as described in “Datasets”. Figure 6 displays the results in the plane (\(\alpha _{\mathrm {e}}\), \(\Omega\)). The \(\Omega\) values obtained for the Chua circuit data and for the laser data confirm their chaotic nature35,36 (\(\Omega \approx 0.55\) and \(\Omega \approx 0.20\) respectively). For the star light intensity \(\Omega \approx 0\), confirming the stochastic nature of the signal37. For the number of sunspots, which is a well-known long-memory noisy time series, \(\Omega \approx 0\). In this case the value of \(\alpha\) obtained (\(\alpha \approx 2\)) confirms the results of Singh et al.38 where a Hurst exponent close to 1 was found. Regarding the five time series of RR-intervals of healthy subjects, our algorithm identifies stochasticity (\(\Omega \approx 0\)) in all of them, which is consistent with findings of Ref.9.
The last empirical set analyzed reveals the nature of the dynamics of human gait: regardless of the age of the subjects, \(\Omega \approx 0\) confirming the stochastic behavior discussed in39. In the inset we show that the \(\alpha _\text{e}\) value returned by the ANN decreases with the age, which is also in line with the results presented in40, obtained with Detrended Fluctuation Analysis (see Fig. 6 of Ref.40). The authors interpret this variation as due to an age-related change in stride-to-stride dynamics, where the gait dynamics of young adults (healthy) appears to fluctuate randomly, but with less time-correlation in comparison to young children40.

Analysis of empirical time series. Results obtained from each time series are presented in the plane (\(\alpha _{\mathrm {e}}\), \(\Omega\)). Deterministic signals are the Chua circuit data (brown triangle) and the laser data (orange ‘X’ marker) that have \(\Omega > 0.0\). The other signals [the light intensity of a star (yellow dot), the number of sunspots (cyan diamond), the heart variability of healthy subjects (magenta thin diamond), and the different groups of human gait dynamics (green, blue, red, and black squares)] are stochastic and have \(\Omega \approx 0\). For the human gait, the inset depicts the \(\alpha _\text{e}\) as a function of the age of each subject. Consistent with40, the correlation coefficient \(\alpha _\text{e}\) decrease with the ages.
Discussion
We have proposed a new time series analysis technique that allows to differentiate stochastic from chaotic signals, and also, to quantify temporal correlations. We have demonstrated the methodology by using synthetic and empirical signals.
Our method is based on locating a time series in a two dimensional plane determined by the permutation entropy and the value of a temporal correlation coefficient, \(\alpha _e\), returned by a machine learning algorithm. In this plane, stochastic signals are very close to a curve defined by Flicker noise, while chaotic signals are located far from this curve. We have used this fact to define a quantifier, \(\Omega\), that is the distance to the FN curve. \(\Omega\) serves to distinguish stochastic and chaotic time series, and it can be used to analyze time series, even when they are very short (with time series of 100 datapoints we found that \(\Omega <0.1\) or \(\Omega >0.1\), if the time series is stochastic or chaotic respectively, Fig. 5). We also found that small values of \(\Omega\) can be used to identify underlying determinism in noise-contaminated signals, and in signals that result from the addition of a number of independent chaotic signals (Fig. 4). We have also used our algorithm to analyze six empirical datasets, and obtained results that are consistent with prior knowledge of the data (Fig. 6). Taken together, these results show that the proposed methodology allows answering the questions of how to quantify stochasticity and temporal correlations in a time series.
Our algorithm is fast, easy-to-use, and freely available28. Thus, we believe that it will be a valuable tool for the scientific community working on time series analysis. Existing methods have limitations in terms of the characteristics of the data (length of the time series, level of noise, etc.). A limitation of our algorithm lies in the analysis of noise-contaminated periodic signals, because their temporal structure may not be distinguished from the temporal structure of a fully stochastic signal with a large \(\alpha\) value. Future work will be directed at trying to overcome this limitation. Here, for a “proof-of-concept” demonstration, we have used a well-known machine learning algorithm (a feed-forward ANN), a rather simple training procedure, and a popular entropy measure (the permutation entropy). We have not tried to optimize the performance of the algorithm. We expect that different machine learning algorithms, training procedures, and entropy measures can give different performances, depending on the characteristics of the data analyzed. Therefore, the methodology proposed here has a high degree of flexibility, which can allow to optimize performance for the analysis of particular types of data.
Methods
Ordinal analysis and permutation entropy
Ordinal analysis allows the identification of patterns and nonlinear correlations in complex time series29. For each sequence of D data points in the time-series (consecutive, or with a certain lag between them), their values are replaced by their relative amplitudes, ordered from 0 to \(D-1\). For instance, a sequence \(\{0,5,10,13\}\) in the time series transforms into the ordinal pattern “0123”, while \(\{0,13,5,10\}\) transforms into “0312”. As an example, Fig. 7 shows the ordinal patterns formed with \(D=4\) consecutive values..
We evaluate the frequency of occurrence of each word, defined as the ordinal probability \({\mathscr {P}}(i)\) with \(\sum _{i=1}^{D!}{\mathscr {P}}(i)=1\), where i represents each possible word. Then, we evaluate the Shannon entropy, known as permutation entropy29:
The permutation entropy varies from \(S(D)=0\) if the j-th state \({\mathscr {P}}(j)=1\) (while \({\mathscr {P}}(i)=0\) \(\forall \; i\ne j\)) to \(S(D)=\ln ({D!})\) if \({\mathscr {P}}(i)=1/D!\) \(\forall \; i\). The normalized permutation entropy used in this work is given by:
In this work, to calculate the ordinal patterns, we have used the algorithm proposed by Parlitz and coworkers32. We have used \(D = 6\) and no lag, i.e., \(D-1\) values overlap in the definition of two consecutive ordinal patterns. Therefore, we use as features to the ANN (see below) the \(D!=720\) probabilities of the ordinal patterns. For a robust estimation of these probabilities, a time series of length \(N>>D!\) is needed. However, as we show in Fig. 5, the algorithm returns meaningful values even for time series that are much shorter.

Schematic illustration of 24 ordinal patterns that can be defined from \(D=4\) consecutive data values in a time series.
Artificial neural network
Deep learning is part of a broader family of machine learning methods based on artificial neural networks (ANNs)41. In this work, we use the deep learning framework Keras42 to compile and train an ANN. Since we want to regress the information of the features into a real value (classical scalar regression problem43) an appropriate option is a feed-forward ANN. The ANN is trained to evaluate the time correlation coefficient considering as features the 720 probabilities of the ordinal patterns. We connect the input layer to a single dense layer with 64 output units connected to a final layer, regressing all the information of the inputs into a real number. Other combinations were tested with different numbers of units (\(16,\,512,\,1024\)) and layers. We found that a single layer with 64 units was sufficient to accurately predict the \(\alpha\) value. The ANN parameters and the compilation setup are given in Table 2. As explained in the discussion we have used the feed-forward ANN as a simple option for a “proof-of-concept” demonstration. Other deep learning/machine learning methods or a different compilation setup may give better results depending on the type of data that is analyzed.
The training stage of the ANN is performed using a dataset of 50,000 flicker noise time series with \(N=2^{20}\) points, where the parameter \(\alpha\) of each time series is randomly chosen in \(-1\le \alpha \le 3\) (see “Datasets” for details). We separate the dataset into two sets: the training dataset (\(L_\text{train}=40{,}000\)), and the test dataset (\(L_\text{test}=10{,}000\)). To quantify the error between the output of the ANN and the target, \(\alpha\), we use the mean absolute error:
where L is the number of samples. The training stage is concluded and then the parameters of the ANN are fixed. After that, we apply the ANN to the test dataset, and the error in the evaluation of \(\alpha _{\mathrm {e}}\) regarding \(\alpha\) is \({\mathscr {E}}(L_\text{test}) \approx 0.01\).
Datasets
Stochastic systems
In this paper, we use three types of stochastic signals: flicker noise (FN), fractional Brownian motion (fBm) and fractional Gaussian noise (fGn). Flicker noise (FN) or colored noise time series are used for the training of the Artificial Neural Network. They are generated with the open Python library colorednoise.py44,45. fBm and fGn time series are generated with the Python library fmb.py46. Both time series depend on a Hurst index \({\mathscr {H}}\)47. For the fBm \({\mathscr {H}} = 0.5\) corresponds to the classical Brownian motion. If \({\mathscr {H}} > 0.5\) (\({\mathscr {H}} < 0.5\)) the time-series is positively (negatively) correlated. For fGn \({\mathscr {H}} = 0.5\) characterizes a white noise47; if \({\mathscr {H}}>0.5\) (\({\mathscr {H}}<0.5\)) the fGn time series exhibits long-memory (short-memory). The Hurst index is related to the \(\alpha\) of flicker noise: for a fBm stochastic process, \(\alpha = 2{\mathscr {H}}+1\) and \(1<\alpha <3\); for fGn, \(\alpha = 2{\mathscr {H}}-1\) and \(-1<\alpha <1\)47.
Chaotic systems
In this paper, we analyze time series generated by five chaotic systems:
-
1.
The generalized Bernoulli chaotic map, also known as \(\beta x\) map, described by:
$$\begin{aligned} x_{t+1} = \beta x_t \; \mathrm {(mod1)}, \end{aligned}$$(6)where \(\beta\) controls the dynamical characteristic of the map. Throughout this paper, we use \(\beta = 2\), which leads to a chaotic signal1.
-
2.
The well-known logistic map1:
$$\begin{aligned} x_{t+1} = r x_t(1-x_t), \end{aligned}$$(7)we use \(r = 4\) to obtain a chaotic signal1.
-
3.
The Schuster map48, which exhibits intermittent signals with a power spectrum \(P(f)\sim 1/f^{z}\). It is defined as:
$$\begin{aligned} x_{t+1} = x_t + x^z _t \; \mathrm {(mod1)}, \end{aligned}$$(8)where we use \(z = 0.5\).
-
4.
The skew tend map, which is defined as
$$\begin{aligned} x_{t+1} = {\left\{ \begin{array}{ll} x_t/\omega &{}\text{ if } x_t \in [0,\omega ], \\ (1-x_t)/(1-\omega ) &{} \text{ if } x_t \in (\omega ,1]. \end{array}\right. } \end{aligned}$$(9)Here, we use \(\omega = 0.1847\) in order to obtain a chaotic signal3.
-
5.
The also well-known Lorenz system, defined as:
$$\begin{aligned} \frac{dx(t)}{dt}= & {} \sigma (y-x),\end{aligned}$$(10)$$\begin{aligned} \frac{dy(t)}{dt}= & {} x(R-z) -y,\end{aligned}$$(11)$$\begin{aligned} \frac{dz(t)}{dt}= & {} xy-bz. \end{aligned}$$(12)with parameters \(\sigma = 16\), \(R = 45.92\), and \(b = 4\), which lead to a chaotic motion49. For analyze the time series of consecutive maxima of the x variable.
Empirical datasets
We test our methodology with empirical datasets recorded from diverse chaotic or stochastic systems. Additional information of the datasets can be found in Table 3. These are:
Dataset E-I: Data recorded from an inductorless Chua’s circuit constructed as50. The circuit was set up and the data was kindly sent to us by Vandertone Santos Machado51. The voltages across the capacitors depict chaotic oscillations. To detect this chaoticity we compute the maxima values of the first capacitor \(C_1\).
Dataset E-II: Fluctuations in a chaotic laser data approximately described by three coupled nonlinear differential equations36. To detect the chaoticity of the laser, we compute the maxima values of the time series. The data is available in52.
Dataset E-III: Light intensity of a variable dwarf star (PG1599-035)36 with 17 time-series (segments). These variations may be caused by an intrinsic change in emitted light (superposition of multiple independent spherical harmonics36), or by an object partially blocking the brightness as seen from Earth. The fluctuations in the intensity of the star have been observed to result in a noisy signal36. The data is open and freely available in53.
Dataset E-IV: Three time-series of the sunspots numbers for the period of 1976–201338, the daily sunspots numbers depicts a noisy “pseudo-sinusoidal” behavior. It is accepted that magnetic cycles in the Sun are generated by a solar dynamo produced through nonlinear interactions between solar plasmas and magnetic fields54,55. However, the fluctuations in the period in the cycles is still difficult to understand56. This type of data has been analyzed in38, where its stochastic fluctuations depict a Hurst exponent \({\mathscr {H}} \approx 1\), meaning the data carries memory. The data can be found at57,58,59.
Dataset E-V: Five RR-interval time-series from healthy subjects. Each time series have \(\sim 100{,}000\) RR intervals (the signals were recorded using continuous ambulatory electrocardiograms during 24 h). It still a debate if the heart rate variability is chaotic or stochastic9. While some studies suggest that heart rate variability is a stochastic process9,60,61. Much chaos-detection analysis has been identified as a chaotic signal9,62. The dataset is open and freely available in63.
Dataset E-VI: Fractal dynamics of the human gait as well as the maturation of the gait dynamics. The stride interval variability can exhibit randomly fluctuations with long-range power-law correlations, as observed in39. Moreover, this time-correlation tends to decrease in older children39,40. The analyzed dataset is then separated into 3 groups, related to the subjects’ ages. Group No. 1 has data for \(n = 14\) subjects with 3- to 5-years old; Group No. 2 has data for \(n = 21\) subjects with 6- to 8-years old; Group No. 3 has data for \(n = 15\) subjects with 10 - to 13-years old; Group No. 4 has data for \(n = 10\) subjects with 18- to 29-years old39. The data is open and freely available in64,65,66.
References
Ott, E. Chaos in Dynamical Systems (Cambridge University Press, 2002).
Ikeguchi, T. & Aihara, K. Difference correlation can distinguish deterministic chaos from 1/f \(\alpha\)-type colored noise. Phys. Rev. E 55, 2530 (1997).
Rosso, O. A., Larrondo, H. A., Martin, M. T., Plastino, A. & Fuentes, M. A. Distinguishing noise from chaos. Phys. Rev. Lett. 99, 154102 (2007).
Lacasa, L. & Toral, R. Description of stochastic and chaotic series using visibility graphs. Phys. Rev. E 82, 036120 (2010).
Zunino, L., Soriano, M. C. & Rosso, O. A. Distinguishing chaotic and stochastic dynamics from time series by using a multiscale symbolic approach. Phys. Rev. E 86, 046210 (2012).
Ravetti, M. G., Carpi, L. C., Gonçalves, B. A., Frery, A. C. & Rosso, O. A. Distinguishing noise from chaos: Objective versus subjective criteria using horizontal visibility graph. PLoS ONE 9, e108004 (2014).
Kulp, C. & Zunino, L. Discriminating chaotic and stochastic dynamics through the permutation spectrum test. Chaos Interdiscip. J. Nonlinear Sci. 24, 033116 (2014).
Quintero-Quiroz, C., Pigolotti, S., Torrent, M. & Masoller, C. Numerical and experimental study of the effects of noise on the permutation entropy. New J. Phys. 17, 093002 (2015).
Toker, D., Sommer, F. T. & D’Esposito, M. A simple method for detecting chaos in nature. Commun. Biol. 3, 1–13 (2020).
Lopes, S. R., Prado, T. D. L., Corso, G., Lima, G. Z. D. S. & Kurths, J. Parameter-free quantification of stochastic and chaotic signals. Chaos Solitons Fractals 133, 109616 (2020).
Simonsen, I., Hansen, A. & Nes, O. M. Determination of the hurst exponent by use of wavelet transforms. Phys. Rev. E 58, 2779 (1998).
Weron, R. Estimating long-range dependence: Finite sample properties and confidence intervals. Phys. A 312, 285–299 (2002).
Carbone, A. Algorithm to estimate the hurst exponent of high-dimensional fractals. Phys. Rev. E 76, 056703 (2007).
Witt, A. & Malamud, B. D. Quantification of long-range persistence in geophysical time series: Conventional and benchmark-based improvement techniques. Surv. Geophys. 34, 541 (2013).
Beran, J., Feng, Y., Ghosh, S. & Kulik, R. Long-Memory Processes (Springer, 2016).
Voss, R. F. & Clarke, J. Flicker (1 f) noise: Equilibrium temperature and resistance fluctuations. Phys. Rev. B 13, 556 (1976).
Hooge, F., Kleinpenning, T. & Vandamme, L. Experimental studies on 1/f noise. Rep. Prog. Phys. 44, 479 (1981).
Peng, C.-K. et al. Long-range correlations in nucleotide sequences. Nature 356, 168–170 (1992).
Peng, C.-K. et al. Long-range anticorrelations and non-gaussian behavior of the heartbeat. Phys. Rev. Lett. 70, 1343 (1993).
Bak, P., Tang, C. & Wiesenfeld, K. Self-organized criticality: An explanation of the 1/f noise. Phys. Rev. Lett. 59, 381 (1987).
da Silva, S., Prado, T. D. L., Lopes, S. & Viana, R. Correlated Brownian motion and diffusion of defects in spatially extended chaotic systems. Chaos Interdiscip. J. Nonlinear Sci. 29, 071104 (2019).
Granger, C. W. & Ding, Z. Varieties of long memory models. J. Econom. 73, 61–77 (1996).
Mandelbrot, B. B. The variation of certain speculative prices. In Fractals and Scaling in Finance 371–418 (Springer, 1997).
Koscielny-Bunde, E. et al. Indication of a universal persistence law governing atmospheric variability. Phys. Rev. Lett. 81, 729 (1998).
Press, W. H. Flicker noises in astronomy and elsewhere. Comments Astrophys. 7, 103–119 (1978).
Olivares, F., Zunino, L. & Rosso, O. A. Quantifying long-range correlations with a multiscale ordinal pattern approach. Phys. A 445, 283–294 (2016).
Koza, J. R., Bennett, F. H., Andre, D. & Keane, M. A. Automated design of both the topology and sizing of analog electrical circuits using genetic programming. In Artificial Intelligence in Design’96 151–170 (Springer, 1996).
Repository with the ANN:. https://github.com/brunorrboaretto/chaos_detection_ANN/.
Bandt, C. & Pompe, B. Permutation entropy: A natural complexity measure for time series. Phys. Rev. Lett. 88, 174102 (2002).
Rosso, O. A. & Masoller, C. Detecting and quantifying stochastic and coherence resonances via information-theory complexity measurements. Phys. Rev. E 79, 040106 (2009).
Rosso, O. & Masoller, C. Detecting and quantifying temporal correlations in stochastic resonance via information theory measures. Eur. Phys. J. B 69, 37–43 (2009).
Parlitz, U. et al. Classifying cardiac biosignals using ordinal pattern statistics and symbolic dynamics. Comput. Biol. Med. 42, 319–327 (2012).
Zanin, M., Zunino, L., Rosso, O. A. & Papo, D. Permutation entropy and its main biomedical and econophysics applications: A review. Entropy 14, 1553–1577 (2012).
Rosso, O. A. Permutation entropy and its interdisciplinary applications. https://www.mdpi.com/journal/entropy/special_issues/Permutation_Entropy.
Chua, L. O. Chua’s circuit: An overview ten years later. J. Circ. Syst. Comput. 4, 117–159 (1994).
Gershenfeld, N. A. & Weigend, A. S. The Future of Time Series (Xerox Corporation, Palo Alto Research Center, 1993).
Weigend, A. S. Time Series Prediction: Forecasting the Future and Understanding the Past (Routledge, 2018).
Singh, A. & Bhargawa, A. An early prediction of 25th solar cycle using hurst exponent. Astrophys. Sp. Sci. 362, 1–6 (2017).
Hausdorff, J. M. et al. Fractal dynamics of human gait: Stability of long-range correlations in stride interval fluctuations. J. Appl. Physiol. 80, 1448–1457 (1996).
Hausdorff, J. M., Zemany, L., Peng, C.-K. & Goldberger, A. L. Maturation of gait dynamics: Stride-to-stride variability and its temporal organization in children. J. Appl. Physiol. 86, 1040–1047 (1999).
Framework to deep learning Keras. https://keras.io.
Chollet, F. Deep learning with python (2017).
Library to generate a flicker noise. https://github.com/felixpatzelt/colorednoise.
Timmer, J. & Koenig, M. On generating power law noise. Astron. Astrophys. 300, 707 (1995).
Library to generate fbm and fgn. https://github.com/crflynn/fbm/.
Zunino, L. et al. Characterization of gaussian self-similar stochastic processes using wavelet-based informational tools. Phys. Rev. E 75, 021115 (2007).
Schuster, H. G. & Just, W. Deterministic Chaos: An Introduction (Wiley, 2006).
Wolf, A., Swift, J. B., Swinney, H. L. & Vastano, J. A. Determining Lyapunov exponents from a time series. Phys. D 16, 285–317 (1985).
Torres, L. & Aguirre, L. Inductorless Chua’s circuit. Electron. Lett. 36, 1915–1916 (2000).
Chua’s circuit data. The data is available from our colleague Vandertone Santos Machado (under request). vsm1985@gmail.com.
Santa Fé Time Series Competition: Dataset A. Fluctuations in a Far-Infrared Laser. https://www.comp-engine.org/browse/category/real/physics/laser.
Santa Fé time series competition: Dataset E. A set of measurements of the time variation intensity of ma variable white dwarf star. https://www.comp-engine.org/browse/category/real/astrophysics/light-curve.
Allen, E. J. & Huff, C. Derivation of stochastic differential equations for sunspot activity. Astronomy Astrophys. 516, A114 (2010).
Choudhuri, A. R. The current status of kinematic solar dynamo models. J. Astrophys. Astron. 21, 373–377 (2000).
Passos, D. & Lopes, I. A low-order solar dynamo model: Inferred meridional circulation variations since 1750. Astrophys. J. 686, 1420 (2008).
The observations of the number of sunspots collected by the the official website of NASA’s Space Physics Data Facility. https://omniweb.gsfc.nasa.gov/ow.html.
The observations of the number of sunspots collected by the Solar Division, aavso. https://www.ngdc.noaa.gov/stp/solar/.
Daily total sunspot number collected by the sunspot index and long-term solar observations, silso. http://www.sidc.be/silso/infosndtot.
Baillie, R. T., Cecen, A. A. & Erkal, C. Normal heartbeat series are nonchaotic, nonlinear, and multifractal: New evidence from semiparametric and parametric tests. Chaos Interdiscip. J. Nonlinear Sci. 19, 028503 (2009).
Zhang, J., Holden, A., Monfredi, O., Boyett, M. R. & Zhang, H. Stochastic vagal modulation of cardiac pacemaking may lead to erroneous identification of cardiac “chao’’. Chaos Interdiscip. J. Nonlinear Sci. 19, 028509 (2009).
Glass, L. Introduction to controversial topics in nonlinear science: Is the normal heart rate chaotic? (2009).
Is the normal heart rate chaotic?. https://archive.physionet.org/challenge/chaos/.
Goldberger, A. L. et al. Physiobank, physiotoolkit, and physionet. Circulation 101, e215–e220. https://doi.org/10.1161/01.CIR.101.23.e215 (2000).
Gait maturation database and analysis. https://archive.physionet.org/physiobank/database/gait-maturation-db/.
Long-term recordings of gait dynamics. https://physionet.org/content/umwdb/1.0.0/.
Acknowledgements
The authors thank Vandertone Santos Machado for providing the deterministic data of a chaotic Chua circuit. B.R.R.B., R.C.B, K.L.R., T.L.P. and S.R.L acknowledge partial support of Conselho Nacional de Desenvolvimento Científico e Tecnológico, CNPq, Brazil, Grant No. 302785/2017-5, 308621/2019-0 and the Coordenação de Aperfeiçoamento de Pessoal de Nível Superior, Brasil (CAPES), Finance Code 001. C.M. acknowledges funding by the Spanish Ministerio de Ciencia, Innovacion y Universidades (PGC2018-099443-B-I00) and the ICREA ACADEMIA program of Generalitat de Catalunya.
Author information
Authors and Affiliations
Contributions
B.R.R. performed the analysis and prepared the figures, all authors wrote and reviewed the manuscript.
Corresponding author
Ethics declarations
Competing interests
The authors declare no competing interests.
Additional information
Publisher's note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Boaretto, B.R.R., Budzinski, R.C., Rossi, K.L. et al. Discriminating chaotic and stochastic time series using permutation entropy and artificial neural networks. Sci Rep 11, 15789 (2021). https://doi.org/10.1038/s41598-021-95231-z
Received:
Accepted:
Published:
DOI: https://doi.org/10.1038/s41598-021-95231-z
This article is cited by
-
Asynchronous secure communication scheme using a new modulation of message on optical chaos
Optical and Quantum Electronics (2023)
Comments
By submitting a comment you agree to abide by our Terms and Community Guidelines. If you find something abusive or that does not comply with our terms or guidelines please flag it as inappropriate.
