
Abstract
Nuclear magnetic resonance spectroscopy (MRS) allows for the determination of atomic structures and concentrations of different chemicals in a biochemical sample of interest. MRS is used in vivo clinically to aid in the diagnosis of several pathologies that affect metabolic pathways in the body. Typically, this experiment produces a one dimensional (1D) 1H spectrum containing several peaks that are well associated with biochemicals, or metabolites. However, since many of these peaks overlap, distinguishing chemicals with similar atomic structures becomes much more challenging. One technique capable of overcoming this issue is the localized correlated spectroscopy (L-COSY) experiment, which acquires a second spectral dimension and spreads overlapping signal across this second dimension. Unfortunately, the acquisition of a two dimensional (2D) spectroscopy experiment is extremely time consuming. Furthermore, quantitation of a 2D spectrum is more complex. Recently, artificial intelligence has emerged in the field of medicine as a powerful force capable of diagnosing disease, aiding in treatment, and even predicting treatment outcome. In this study, we utilize deep learning to: (1) accelerate the L-COSY experiment and (2) quantify L-COSY spectra. All training and testing samples were produced using simulated metabolite spectra for chemicals found in the human body. We demonstrate that our deep learning model greatly outperforms compressed sensing based reconstruction of L-COSY spectra at higher acceleration factors. Specifically, at four-fold acceleration, our method has less than 5% normalized mean squared error, whereas compressed sensing yields 20% normalized mean squared error. We also show that at low SNR (25% noise compared to maximum signal), our deep learning model has less than 8% normalized mean squared error for quantitation of L-COSY spectra. These pilot simulation results appear promising and may help improve the efficiency and accuracy of L-COSY experiments in the future.
Similar content being viewed by others

Introduction
Magnetic resonance imaging (MRI) is a popular imaging modality capable of providing valuable anatomical and functional information in vivo. By utilizing a strong magnetic field and radio-frequency (RF) waves, MRI successfully images hydrogen atoms in their local chemical environment, allowing for useful soft tissue contrast. One technique that allows for the metabolic investigation of different tissues is the magnetic resonance spectroscopy (MRS) method. In particular, single-voxel 1H MRS is capable of providing biochemical information from a volume of interest (VOI) in the human body1. MRS provides a 1H spectrum rich with peaks representative of various chemicals. Furthermore, this spectrum can be quantified by using a spectral fitting algorithm2,3,4,5,6 to yield chemical, or metabolite, concentrations. MRS, and more specifically the point resolved spectroscopy (PRESS) experiment, has been used to explore pathologies affecting the brain7, prostate8, liver9, breast10, as well as other sites, and is often used in combination with other imaging studies to discern how metabolic alterations in tissues correlate with anatomical abnormalities.
Unfortunately, one-dimensional (1D) spectroscopy techniques such as PRESS have a disadvantage when it comes to quantifying overlapping metabolite spectral signals. Since many metabolites are found in the body at very low concentrations, separating these signals from more dominant spectral peaks becomes very challenging. For this reason, several approaches have been developed to better quantify these lower concentrated metabolites, including J-editing techniques11,12,13,14 and two-dimensional (2D) spectral acquisitions15,16,17,18,19. In particular, 2D MRS offers the advantage of quantifying all metabolite signals in a single scan at the expense of increasing acquisition time. A typical 2D MRS experiment includes a time increment, \(t_1\), in the pulse sequence to acquire data from the indirect temporal dimension. Combined with the acquisition of the direct temporal dimension, \(t_2\), a 2D spectrum, S(\(F_2\),\(F_1\)), can be acquired by Fourier transforming the 2D temporal data, s(\(t_2\),\(t_1\)).
One popular 2D MRS technique is the localized correlated spectroscopy (L-COSY) experiment18. This experiment acquires data by using a 90\(^\circ\)-180\(^\circ\)-\(t_1\)-90\(^\circ\)-\(t_2\) sequence and yields several cross-peaks which can be used to identify and quantify overlapping resonances. However, there are two main limitations of the L-COSY technique. First, due to the \(t_1\) increment necessary to obtain the indirect dimension, the L-COSY scan time is very long. Second, because of the nature of an additional dimension, spectral fitting becomes more complex and therefore less ideal quantitation techniques such as peak integrals are often used. Several methods have been proposed to overcome these two challenges to improve L-COSY, including non-uniform sampling with reconstruction20 and 2D spectral fitting using prior-knowledge21,22.
Recently, deep learning and artificial intelligence have become more prominent in the medical field and radiology23,24,25,26. These methods are often used for segmenting medical images, aiding with diagnosis, and verifying image quality. In addition, these techniques have been applied to magnetic resonance spectroscopy in a variety of different applications. One area is in artifact removal and detection27,28, where it has been effective at detecting different types of ghosting artifacts and spectroscopic imaging artifacts. Quantitation is another area that has seen great progress due to deep learning, mainly focusing on 1D MRS quantification29,30. These publications demonstrate that deep learning is competitive and yields similar results to other fitting algorithms. Finally, deep learning has also impacted spectral reconstruction31,32,33, and has become a competitor to other reconstruction methods such as low rank Hankel matrix reconstruction34,35.
One popular deep learning architecture is the UNet26, which is a fully convolutional network36 capable of image-to-image domain mapping. While UNet is often used for segmentation purposes, our group has recently demonstrated that a novel UNet architecture, the densely connected U-Net (D-UNet)37,38,39, is capable of reconstructing super-resolution spectroscopic images. In this study, we demonstrate that the D-UNet architecture can be used to: 1) reconstruct non-uniformly sampled (NUS) L-COSY acquisitions and 2) quantify fully sampled L-COSY spectra accurately. The D-UNet models were trained and evaluated using simulated L-COSY data. The first type of D-UNet model was trained to reconstruct NUS L-COSY. This reconstruction method was quantitatively compared to compressed sensing (\(\ell _1\)-norm) reconstruction40. The second type of D-UNet model was trained to quantify seventeen metabolites from a simulated fully sampled L-COSY spectrum. All reconstruction results were compared to the actual simulations to evaluate the errors of the reconstructions both qualitatively and quantitatively.
Methods
All of the experiments were simulation based (no animal or human subjects), and therefore no IRB or other committee approval was necessary. As shown in Fig. 1, the goal of this study was to perform two distinct tasks using the D-UNet architecture: (1) reconstruct NUS L-COSY spectra and (2) quantify L-COSY spectra. While each task used different data for training the models and testing the results, the initial simulation process to synthesize L-COSY spectra was identical for both applications.

Two proposed implementations for the D-UNet architecture are shown. (A) A non-uniformly sampled L-COSY experiment is reconstructed into the fully sampled spectrum. While under-sampling can be performed in both the \(t_2\) and \(t_1\) dimensions, this study analyzes the reconstruction of L-COSY spectra acquired using non-uniform sampling along only the \(t_1\) dimension. (B) Several metabolite spectra are identified from a fully sampled L-COSY spectrum using a D-UNet model. The intensities of the metabolite spectra directly correlate to concentration values, and therefore this study also investigates the potential application of deep learning to quantify L-COSY spectra. In total, 17 metabolites were quantified in this simulation study.
Simulation
GAMMA simulation41 was used to simulate seventeen different metabolites found in the human brain using the 90\(^\circ\)-180\(^\circ\)-\(t_1\)-90\(^\circ\)-\(t_2\) L-COSY sequence18. These metabolites included aspartate (Asp), choline (Ch), creatine at 3ppm (Cr3.0), creatine at 3.9ppm (Cr3.9), \(\gamma\)-butyric acid (GABA), glucose (Glc), glutamine (Gln), glutamate (Glu), glutathione (GSH), lactate (Lac), myo-Inositol (mI), N-acetyl aspartate (NAA), N-acetyl-asparate-g (NAAG), phosphocholine (PCh), phosphoethanolamine (PE), taurine (Tau), and threonine (Thr). Chemical shift values for the biochemicals were found in the literature42. The metabolites were simulated using the following experimental parameters: TE=30ms, \(t_2\) points = 2048, \(t_1\) points = 100, spectral bandwidth along the direct dimension (\(SBW_2\)) = 2000Hz, and spectral bandwidth along the indirect dimension (\(SBW_1\)) = 1250Hz. The magnetic field strength was chosen to be the field strength of a Siemen’s 3T scanner (Erlangen, Germany).
Then, L-COSY spectra were randomly generated by modifying the original metabolite simulations, also referred to as the basis set. Each metabolite in the basis set (\(B_m\)) was first line broadened in both the direct and indirect temporal dimensions using an exponential filter and a random phase was applied to the basis metabolite signal as well:
Above, \(B_{lb,m}\) is the new line-broadened metabolite, \(\phi _r\) is a random angle between 0 and 2\(\pi\), \(e^{-r_{1,m}}\) is an exponential filter applied to the \(t_1\) domain, and \(e^{-r_{2,m}}\) is an exponential filter applied to the \(t_2\) domain. Each metabolite was allowed to have separate line-broadening terms. The factors \(e^{-r_{2,m}}\) and \(e^{-r_{1,m}}\) resulted in effective line-broadenings of 5-25Hz and 0-15Hz, respectively, and were implemented in this fashion to mimic the range of common \(T_2\) values in vivo.
Next, the individual metabolites were combined linearly using random concentration values to produce an initial L-COSY spectrum, \(s_{init}\):
In Eq. (2), \(r_{3,m}\) is a random concentration value between 0 and 10, and is representative of the concentration value in mmol. The final L-COSY spectrum, \(s_f\), was created by adding noise to \(s_{init}\). The noise level could vary drastically from 0% to 25% of the maximum metabolite signal.
Non-uniform sampling and reconstruction
Non-uniform sampling was performed on the final \(s_f\) matrix along the \(t_1\) dimension utilizing an exponential probability density function43,44,45. This NUS scheme emphasized sampling earlier \(t_1\) points more due to the fact that these points have less \(T_2\) decay (more signal). The last \(t_1\) point was sampled for all of the NUS schemes. The three sampling masks used in this study are displayed in Fig. 2. A \(t_1\) point was sampled if the value in the mask was 1, and it was not sampled if the value in the mask was 0. The number of points sampled for each mask were 75, 50, and 25 resulting in a scan acceleration factor of 1.3x, 2x, and 4x, respectively.

A ground truth simulated L-COSY spectrum is shown (top). Sampling schemes were applied to the simulated spectrum using the sampling masks shown in the 1st column. These masks sampled 25, 50, and 75 \(t_1\) points out of a total 100 \(t_1\) points to yield 4x, 2x, and 1.3x acceleration factors, respectively. The 2nd column shows the under-sampled spectra in the (\(F_2, F_1\)) domain and the 3rd column shows the spectra reconstructed using a D-UNet model. Errors for each reconstruction are displayed as difference maps in the final column.
Aside from the D-UNet reconstruction of NUS data described below, data were also reconstructed using compressed sensing reconstruction40. The \(\ell _1\)-norm minimization reconstruction was performed by solving the following optimization problem:
Equation (3) is the general formulation for compressed sensing reconstruction. u is the reconstructed data in the (\(F_2\),\(F_1\)) spectral domain, M is the sampling mask along the \(t_1\) domain, F is the 2D Fourier transformation, f is the NUS data in the (\(t_2\),\(t_1\)) temporal domain, and \(\sigma ^2\) is the estimate of the noise variance. The noise variance was estimated from a noisy region of the spectrum, as previously described44,46,47,48.
Reconstructing NUS L-COSY with D-UNet
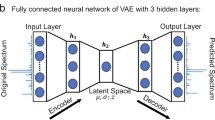
The densely connected UNet architecture utilized in this study was very similar to a previously reported model38, and the general architecture can be seen in Fig. 3. This model utilized the generic UNet architecture, which operates by learning important global and local features using a variety of convolutional layers. The first half of the UNet continuously uses convolutional and max pooling layers, and these layers help reduce the input matrix size. By reducing the size, the network learns the primary global features of the input images. The second half of the UNet uses deconvolutional and up-pooling layers, which restore the matrix size. This process helps learn local features that are vital to restoring the images on a finer scale. The architecture also leveraged densely connected convolutional layers, which aid in carrying important features throughout the learning process. All convolutional layers used a kernel size = 3 x 3, stride = 1, and a rectified linear unit (ReLU) activation function49.

The densely connected U-Net architecture from a previous publication38 is displayed. The densely connected flavor of this model allows for important features to be carried over throughout the entire training process.
The D-UNet model used for reconstructing the NUS L-COSY data was designed to take an NUS L-COSY spectrum as input and produce a reconstructed L-COSY spectrum as output. The NUS L-COSY data was produced by multiplying \(s_f\) by the sampling mask in the (\(F_2\),\(t_1\)) domain and then transforming this matrix back into the (\(F_2\),\(F_1\)) domain. The output was simply the \(s_f\) matrix without noise in the (\(F_2\),\(F_1\)) domain. Both the input and output matrix sizes were 512 x 32, and corresponded to spectral ranges of 0.5-4.5ppm in the direct spectral dimension (\(F_2\)), and 1.2-4.3ppm in the indirect spectral dimension (\(F_1\)). Additionally, the inputs and outputs were inserted as three different channels into the network with each channel representing the real, imaginary, and magnitude information of the spectrum. Finally, all inputs and outputs were normalized to be in between values of 0 and 1, and were normalized based on the maximum value of the magnitude images. The loss function was the mean squared error (MSE) between the reconstructed L-COSY (Recon) and the actual simulated L-COSY (Actual), which was defined as:
The Adam optimizer50 was used with a learning rate set to 1e\(^{-3}\). Three D-UNet models with identical architecture were trained to reconstruct spectra sampled using the masks shown in Fig. 2. A total of 40,000 simulated NUS L-COSY spectra were simulated for each sampling scheme, and 100 spectra were used to evaluate the results as an independent test set. The batch size for the training was 10 samples per batch.
Quantitation of L-COSY with D-UNet
The quantitation of fully sampled L-COSY data was performed in a similar manner to the method described above. The input to the quantitation D-UNet was the L-COSY spectrum as a 512 x 32 matrix with three channels representing the magnitude, real, and imaginary components of the spectrum. The input was scaled from 0 to 100 based on the maximum of the magnitude spectrum. The output of the network was a 512 x 32 matrix representative of each metabolite basis set. Therefore, since 17 metabolites were quantified, the output had 17 channels representing the magnitude spectrum for each metabolite. All other training parameters were identical to those described above. A total of 21,000 simulated L-COSY spectra were used for training, and 100 spectra were used for testing the results independently.
Evaluation
All of the results were compared to the actual simulated spectra by utilizing the MSE metric from Eq. (4). For the non-uniformly sampled spectral reconstruction, the MSE was calculated over all 100 test spectra and compared to the MSE of the \(\ell _1\)-norm reconstruction from Eq. (3) for all acceleration factors. Normalized MSE was also used, and errors were normalized based on the maximum signal intensity of the spectrum. In addition to MSE, the quantitation with D-UNet also investigated the effect of noise on the quantitative results. Specifically, ten different noise levels were evaluated on the same 100 spectra to determine how the signal-to-noise ratio (SNR) affects the model results and overall stability. These noise levels ranged from 0% to 25% of the maximum signal intensity. Finally, a water signal was introduced at various amplitudes (no water signal to high water signal) to investigate the affect that unknown signals may cause on quantitation. This water signal was also produced by GAMMA simulation, and appropriate line-broadening factors (8-20 Hz) were applied to the data in both spectral dimensions.
Results
NUS L-COSY reconstruction
The NUS L-COSY spectra reconstructed using the D-UNet architecture can be seen in Fig. 2. The non-uniform sampling produces several \(F_1\) ridging artifacts present in the spectral domain, which are ultimately removed by using the D-UNet models. For training, the MSE loss function achieved a loss of approximately 3e\(^{-5}\) for each of the models. The final validation loss was a factor of 2-3 larger than the training loss MSE values for each model, but no signs of over-fitting were present as the validation loss mimicked the decline and stabilization of the training loss function. The errors as the difference between the Actual and Recon spectra are also shown for each acceleration factor.

A qualitative comparison between the D-UNet and the compressed sensing (\(\ell _1\)-norm) reconstructions is shown. The fully sampled L-COSY spectrum displayed in Fig. 2 was sampled using 25 \(t_1\) points (4x acceleration). The spectrum was then reconstructed using the trained deep learning model and optimization described in Eq. (3). Errors between the two reconstructions are displayed as differences between the actual spectrum and the reconstructions.
A qualitative comparison between the D-UNet reconstruction and \(\ell _1\)-norm minimization methods are shown in figures 4 and 5 for the 4x reconstructions. While the D-UNet reconstruction displays minimal errors surrounding the major peaks, the compressed sensing results show large errors. Due to the iterative reconstruction, several false cross-peaks also appear in the \(\ell _1\)-norm reconstructed spectra, which are not present in the D-UNet reconstruction. Also, a quantitative comparison between the two reconstruction methods is provided in Table 1. At lower acceleration factors where more points are sampled, \(\ell _1\)-norm minimization performs better than the D-UNet reconstruction. However, at higher acceleration factors where less points are sampled, the D-UNet mean error remains under 5%, whereas the \(\ell _1\)-norm minimization reconstruction error is larger than 20%. Once again, these values were calculated over 100 testing L-COSY data that were simulated independently of the training set.

The cross-peak from F2 = 3.6–3.9 ppm and F1 = 1.9–2.22 ppm is displayed for the 4x NUS spectrum (A), the actual spectrum (B), the D-UNet reconstructed spectrum (C), and the \(\ell _1\) reconstructed spectrum (D). The profiles shown in the spectra are displayed and compare the cross-peak reconstruction.
L-COSY quantitation
The capabilities of the D-UNet to identify metabolites from a given L-COSY spectrum are demonstrated in Fig. 6. From the given L-COSY spectrum, 9 metabolite reconstructions are shown and compared alongside the simulated ground truth spectra: NAA, PCh, Cr3.0, mI, Gln, Glu, GABA, GSH, and Asp. In the example spectrum displayed, NAA was simulated at a concentration level of approximately 8 mmol. For GSH, which was simulated closer to 1 mmol, the reconstruction results still have similar intensity values to the simulated ground truth. While only 9 metabolite reconstructions are shown, it is important to note that all 17 metabolites in the basis set are reconstructed and could be visualized.

The results for the quantitation D-UNet are displayed for an example fully sampled L-COSY spectrum. From the input spectrum (top), the deep learning model reconstructs each metabolite’s magnitude spectrum individually (Recon). For comparison, the actual simulated magnitude spectra (Actual) are plotted alongside the reconstructed spectra with the same intensity windows. While only 9 metabolites are displayed, the D-UNet model produces 17 metabolite spectra. The concentrations for these spectra are proportional to the signal intensities, as is standard for most fitting algorithms.
Of course, SNR can play a large role on the performance of any quantitation algorithm, and therefore errors resulting from high noise were investigated. Figure 7 displays the effect of noise levels on the calculated mean squared error for all 17 metabolite spectral reconstructions. As expected, degrading SNR results in larger MSE values for quantitation. In addition, an example spectrum is shown at two different noise levels: noise level 2 (5% noise) and noise level 8 (20% noise). It is clear that cross-peak intensities vary largely with noise, due to the fact that cross-peaks are low signal peaks for the L-COSY experiment.

The mean squared error is displayed as a function of noise level for the quantitation D-UNet results (left). These results were produced by analyzing MSE for 100 identical spectra at 10 different noise levels ranging from 0 to 25% noise relative to the maximum signal intensity. Two example spectra are shown displying 5% noise (middle) and 20% noise (right). Qualitatively, it is clear that cross-peak signal amplitude is greatly altered due to the added noise in the noise level = 8 spectrum.
The linear relationships between the actual and predicted measurements for all 100 test spectra and 17 metabolites were also analyzed. Figure 8 shows the linear relationships for 16 metabolites quantified from the test spectra with a noise level of 5% of the maximum signal intensity. Linear fits are shown on the correlation plots between the simulated ground truth (Actual) and the reconstructed (Recon) concentrated values. In order to produce the concentration results for Recon, the maximum intensity was used from the individually reconstructed metabolite spectra from the D-UNet quantitation model. The effect on quantitation due to varying levels of water signal are displayed in Fig. 9. As the amplitude of the water signal increases, the standard error increases as well.

The relationship between the actual metabolite concentration on the x-axis (Actual) and the reconstructed metabolite concentration on the y-axis (Recon) is shown for 16 metabolites for 100 test spectra. The spectra contained approximately 5% noise signal relative to the maximum signal intensity (noise level = 2). Overall, most metabolites displayed an expected linear relationship even at lower concentration values. Quantitative values for these results are tabulated in Table 2.

Water signal was introduced at different amplitudes to the spectra (left) to investigate how unknown signals impact D-UNet quantitation of the major metabolites. Standard error from fitting reconstructed and actual metabolite concentrations is displayed, and is higher as the water signal amplitude increases.
Finally, Table 2 compares the concentration values of the 17 metabolites at different SNR values. Ideally, if the quantitation was perfect, the slope would be one and the standard error would be zero. For many metabolites at noise level = 2, the slope and error are close to ideal values. However, at noise level = 8, slopes start to deviate largely from the ideal values and error also increases. The r\(^2\) metric displayed is the coefficient of determination and is the variance of the fit. Overall, the r\(^2\) values show that variance is low for the quantitative correlations at both noise levels, as demonstrated by r\(^2>\)0.8.
Discussion
From the results, it is clear that the D-UNet architecture is capable of both reconstructing non-uniformly sampled L-COSY data and quantifying L-COSY spectra after appropriate training. Figures 2 and 6 show this qualitatively whereas Tables 1 and 2 show this quantitatively. While deep learning has very recently been used for quantitation of 1D MRS29, to our knowledge this is the first application of deep learning for reconstructing and quantifying L-COSY MRS. For reconstruction at high acceleration factors, the D-UNet method greatly outperforms a standard compressed sensing method. Spectral quality plays a large role in determining the outcome of the quantitation method, and poor spectral quality results in higher errors, as seen in Fig. 7. Even though the model architecture for both applications is identical, the two models learn separate properties of the L-COSY spectrum.
The first model, which reconstructs NUS L-COSY data, learns to remove the artifacts produced from the application of a particular non-uniform sampling mask. Due to the non-uniform \(t_1\) sampling, various ridging artifacts are present in the \(F_1\) domain20. Depending on the sampling pattern, the artifacts will be mostly constant for each metabolite, but will still be a function of the metabolite concentration, line-broadening factor, and noise level. By providing enough example data, the network essentially learns how to identify the ridging artifacts and remove them appropriately for a given sampling mask and basis set. This is best illustrated in Fig. 2, where it is clear that ridging is removed in the reconstructed spectra for each acceleration factor. Table 1 demonstrates that the D-UNet reconstructions have similar errors over all acceleration factors, whereas \(\ell _1\)-norm minimization reconstruction errors progressively increase as the acceleration factor increases. This is mostly due to the fact that the D-UNet method is capable of learning different artifact patterns for the various acceleration factors, but may have slightly different performances based on the stochastic nature of training and the actual sampling masks.
On the other hand, the second model that quantifies metabolite concentrations from L-COSY spectra learns a different property of the L-COSY images. After adding all of the metabolites together to form a composite spectrum, several signals overlap and are hard to disentangle. Optimization problems are able to handle this issue by fitting overlapping peaks using several parameters, often including appropriate prior-knowledge21,22,51. Unfortunately, these algorithms take a very long time to calculate these parameters and often yield sub-par results if the quality of the L-COSY spectrum is low (high noise, low SNR, signal contamination, etc.). The quantitation model learns how to disentangle overlapping signals through analysis of the magnitude, real, and imaginary components of the input spectrum. By training on thousands of data, the model learns which signals best represent each metabolite even if the signal is buried in another peak and noise. Furthermore, the calculation is extremely fast and is on the order of seconds for a single spectrum. In terms of accuracy, even lower concentrated metabolites simulated at less than 1 mmol are accurate (error less than 3%) for most metabolites, as shown in Fig. 8. While these pilot results look promising for reconstruction and quantitation of L-COSY spectra, the current implementation of this method has several weaknesses.
First, the D-UNet model requires prior-knowledge for all metabolites present in the tissue for training as well as how these signals are affected by a particular non-uniform sampling pattern. Compressed sensing reconstructions do not require any spectral prior-knowledge, and therefore are more versatile for different sampling masks. This is not necessarily a weakness if: (1) the sampling mask used for acquisition matches the D-UNet sampling mask used for training and (2) all metabolites in the tissue are known a priori. For most experiments, (1) is easily satisfied. For healthy tissues and well documented pathologies, (2) is not an issue. However, (2) may become an issue for pathologies that are not well understood and involve unknown chemical changes. This problem may be alleviated by including prior-knowledge for all metabolites appearing in the analysis of ex vivo tissue samples of this pathology if available. For example, mass spectrometry of ex vivo tissues played a pivotal role in identifying 2-hydroxyglutarate (2HG) in certain glioma patients as a metabolite of interest52. Additional prior-knowledge can always be included into the training process to account for macromolecule signals or other signals that may be present in the spectrum retrospectively if necessary. It may be possible to have one model that performs both the reconstruction and quantitation aspects, which were treated as two unique problems in this work. This model may greatly benefit from a 3D D-UNet design, which would allow for better cross-channel (magnitude, real, imaginary channels) features to be identified. Therefore, the model design can be optimized in the future.
Another weakness of the current methodology is that water and fat contamination were not added to the training spectra. Due to water suppression pulses53, spectral distortions around the water region may affect metabolite quantitation. For 2D experiments, total removal of water signal while retaining metabolite signal is more challenging, and may affect the amplitudes of correlated cross-peaks close to water. This problem can be overcome through more advanced training, however the effects of water suppression and removal through common methods such as singular value decomposition (SVD) have to be well understood in order to be modeled correctly. Contaminating fat signal may affect quantitation of metabolites such as lactate and NAA, depending on severity. These fat signals can also be incorporated into the training process, however it is important to utilize the correct fat species. Figure 9 shows that even if a signal is not used in the training process, the model is still robust for quantitation as long as the unknown signal is not very large or overlapping with the spectrum (water for example). While lipids were not introduced in the experiment, it is also expected that unwanted lipid signals would have a negative impact on quantitative accuracy.
The final weakness of the current methodology is the broadening model and random concentrations used to produce the training and testing data. Currently, only an exponential line-broadening term was used for this pilot study. While exponential line-broadening may be a great first approximation for peak shapes, gaussian, lorentzian and even voigt lineshapes may be present in the final experimental peaks51. Due to the increased number of parameters introduced with these added lineshapes, the training data size would need to be much larger for adequate training of the model. In addition, the number of features present in the model may need to be increased in order to handle the complexity of the additional broadening parameters. Furthermore, random frequency shifts were not introduced during the training and testing process. It is known that pH differences can cause frequency drifts, which may affect reconstruction and quantitation results for various metabolites. These were not incorporated into this study because the experimental spectral resolution was so low that this would not impact the results. However, this may be a very important factor to include depending on experimental parameters and the application. Random concentrations are very useful for expanding the solution space of the model, and allow it to develop more robustness to unknown signals. However, accuracy can be improved by limiting the concentration values of metabolites to those expected in vivo, and this is recommended when implementing this technique clinically.
Even with these weaknesses, the methodology presented here can easily be applied to other 2D MRS experiments and to iterative MRS experiments in general. The J-resolved spectroscopy (JPRESS) experiment is another useful 2D MRS technique16,17, and this method may be applied to this application as well. Other 2D experiments include the nuclear overhauser effect spectroscopy (NOESY), total correlation spectroscopy (TOCSY), as well as others. Iterative MRS experiments include diffusion weighted spectroscopy54,55,56, J-editing spectroscopy, and any multi-TE spectroscopy57. In addition, this methodology could be refined for the application of super-resolution spectroscopy, including covariance spectroscopy58,59. However, super-resolution may be unnecessary if accurate quantitative results can already be obtained from low resolution spectra.
Simulation results are certainly powerful for evaluating the feasibility of potential applications, and this study demonstrates that the D-UNet is capable of reconstructing NUS L-COSY data and quantifying L-COSY spectra. However, these methods need to be further validated in vitro and in vivo. Also, these methods have to be compared to state of the art techniques for each application. For reconstruction, the D-UNet model should ideally be compared to compressed sensing, maximum entropy48,60, or other reconstruction methods34,35. It is important to note that while many reconstruction methods require certain sampling schemes (random, non-uniform, etc.), the D-UNet is capable of reconstructing any sampling pattern with the correct training approach. While an exponential sampling scheme was used in this study, a skewed-squared sine-bell sampling scheme may be better to implement in the future48. For quantitation, it is important to compare the deep learning method to other 2D in vivo fitting algorithms to assess accuracy and reproducibility22. After further validation, these models may easily be combined together to create a single deep learning model capable of simultaneously reconstructing and quantifying L-COSY spectra. With further improvements, this method will hopefully have the same acquisition duration as a 1D single-voxel scan (3-5 minutes), which will make this method extremely useful clinically for discerning overlapping metabolite signals.
Conclusion
We present a deep learning approach capable of reconstructing non-uniformly sampled L-COSY spectra and quantifying fully sampled L-COSY spectra. Overall, the results demonstrate accurate reconstruction and quantitation with normalized mean squared error less than 5% for most SNR levels. This technique was evaluated using simulated data, and further studies will validate this method for in vitro and in vivo measurements, and compare this method to state of the art techniques.
References
Bottomley, P. A. Spatial localization in NMR spectroscopy in vivo. Ann. N. Y. Acad. Sci. 508, 333–348 (1987).
Provencher, S. W. Estimation of metabolite concentrations from localized in vivo proton NMR spectra. Magn. Reson. Med. 30, 672–679 (1993).
Ratiney, H. et al. Time-domain semi-parametric estimation based on a metabolite basis set. NMR Biomed. 18, 1–13 (2005).
Naressi, A. et al. Java-based graphical user interface for the MRUI quantitation package. Magn. Reson. Mater. Phys. Biol. Med. 12, 141–152 (2001).
Vanhamme, L., van den Boogaart, A. & Van Huffel, S. Improved method for accurate and efficient quantification of MRS data with use of prior knowledge. J. Magn. Reson. 129, 35–43 (1997).
Wilson, M., Reynolds, G., Kauppinen, R. A., Arvanitis, T. N. & Peet, A. C. A constrained least-squares approach to the automated quantitation of in vivo 1h magnetic resonance spectroscopy data. Magn. Reson. Med. 65, 1–12 (2011).
Soares, D. & Law, M. Magnetic resonance spectroscopy of the brain: Review of metabolites and clinical applications. Clin. Radiol. 64, 12–21 (2009).
Costello, L., Franklin, R. & Narayan, P. Citrate in the diagnosis of prostate cancer. The Prostate 38, 237 (1999).
Fischbach, F. & Bruhn, H. Assessment of in vivo 1h magnetic resonance spectroscopy in the liver: A review. Liver Int. 28, 297–307 (2008).
Bolan, P. J., Nelson, M. T., Yee, D. & Garwood, M. Imaging in breast cancer: Magnetic resonance spectroscopy. Breast Cancer Res. 7, 149–152 (2005).
Mescher, M., Merkle, H., Kirsch, J., Garwood, M. & Gruetter, R. Simultaneous in vivo spectral editing and water suppression. NMR Biomed. 11, 266–272 (1998).
Edden, R. A., Puts, N. A. & Barker, P. B. Macromolecule-suppressed gaba-edited magnetic resonance spectroscopy at 3t. Magn. Reson. Med. 68, 657–661 (2012).
Chan, K. L., Puts, N. A., Schär, M., Barker, P. B. & Edden, R. A. Hermes: Hadamard encoding and reconstruction of mega-edited spectroscopy. Magn. Reson. Med. 76, 11–19 (2016).
Chan, K. L. et al. Echo time optimization for j-difference editing of glutathione at 3t. Magn. Reson. Med. 77, 498–504 (2017).
Aue, W., Bartholdi, E. & Ernst, R. R. Two-dimensional spectroscopy. Application to nuclear magnetic resonance. J. Chem. Phys. 64, 2229–2246 (1976).
Ryner, L. N., Sorenson, J. A. & Thomas, M. A. Localized 2d j-resolved 1 h mr spectroscopy: Strong coupling effects in vitro and in vivo. Magn. Reson. Imaging 13, 853–869 (1995).
Kreis, R. & Boesch, C. Spatially localized, one-and two-dimensional NMR spectroscopy and in vivo application to human muscle. J. Magn. Reson. Ser. B 113, 103–118 (1996).
Thomas, M. A. et al. Localized two-dimensional shift correlated MR spectroscopy of human brain. Magn. Reson. Med. 46, 58–67 (2001).
Dreher, W. & Leibfritz, D. Detection of homonuclear decoupled in vivo proton NMR spectra using constant time chemical shift encoding: Ct-press. Magn. Reson. Imaging 17, 141–150 (1999).
Schmieder, P., Stern, A. S., Wagner, G. & Hoch, J. C. Application of nonlinear sampling schemes to cosy-type spectra. J. Biomol. NMR 3, 569–576 (1993).
Schulte, R. F. & Boesiger, P. Profit: two-dimensional prior-knowledge fitting of j-resolved spectra. NMR Biomed. 19, 255–263 (2006).
Martel, D., Koon, K. T. V., Le Fur, Y. & Ratiney, H. Localized 2d cosy sequences: Method and experimental evaluation for a whole metabolite quantification approach. J. Magn. Reson. 260, 98–108 (2015).
LeCun, Y. et al. Backpropagation applied to handwritten zip code recognition. Neural Comput. 1, 541–551 (1989).
LeCun, Y., Bengio, Y. & Hinton, G. Deep learning. Nature 521, 436 (2015).
Goodfellow, I., Bengio, Y., Courville, A. & Bengio, Y. Deep Learning Vol. 1 (MIT Press, Cambridge, 2016).
Ronneberger, O., Fischer, P. & Brox, T. U-net: Convolutional networks for biomedical image segmentation. in International Conference on Medical Image Computing and Computer-Assisted Intervention 234–241 (Springer, 2015).
Gurbani, S. S. et al. A convolutional neural network to filter artifacts in spectroscopic MRI. Magn. Reson. Med. 80, 1765–1775 (2018).
Kyathanahally, S. P., Döring, A. & Kreis, R. Deep learning approaches for detection and removal of ghosting artifacts in MR spectroscopy. Magn. Reson. Med. 80, 851–863 (2018).
Hatami, N., Sdika, M. & Ratiney, H. Magnetic resonance spectroscopy quantification using deep learning. arXiv preprint arXiv:1806.07237 (2018).
Gurbani, S. S., Sheriff, S., Maudsley, A. A., Shim, H. & Cooper, L. A. Incorporation of a spectral model in a convolutional neural network for accelerated spectral fitting. Magn. Reson. Med. 81, 3346–3357 (2019).
Lee, H. H. & Kim, H. Intact metabolite spectrum mining by deep learning in proton magnetic resonance spectroscopy of the brain. Magn. Reson. Med. 82, 33–48 (2019).
Lee, H. H. & Kim, H. Deep learning-based target metabolite isolation and big data-driven measurement uncertainty estimation in proton magnetic resonance spectroscopy of the brain. Magn. Reson. Med. 84, 1689–1706 (2020).
Qu, X. et al. Accelerated nuclear magnetic resonance spectroscopy with deep learning. Angew. Chem. Int. Ed. 59, 10297–10300 (2020).
Lu, H. et al. Low rank enhanced matrix recovery of hybrid time and frequency data in fast magnetic resonance spectroscopy. IEEE Trans. Biomed. Eng. 65, 809–820 (2017).
Qiu, T., Wang, Z., Liu, H., Guo, D. & Qu, X. Review and prospect: NMR spectroscopy denoising and reconstruction with low-rank Hankel matrices and tensors. Magn. Reson. Chem. 59, 324–345 (2020).
Long, J., Shelhamer, E. & Darrell, T. Fully convolutional networks for semantic segmentation. in Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition 3431–3440 (2015).
Huang, G., Liu, Z., Weinberger, K. Q. & van der Maaten, L. Densely connected convolutional networks. in Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, vol. 1 3 (2017).
Iqbal, Z. et al. Super-resolution 1h magnetic resonance spectroscopic imaging utilizing deep learning. Front. Oncol. 9, 1010 (2019).
Nguyen, D. et al. Three-dimensional radiotherapy dose prediction on head and neck cancer patients with a hierarchically densely connected u-net deep learning architecture. arXiv preprint arXiv:1805.10397 (2018).
Lustig, M., Donoho, D. & Pauly, J. M. Sparse MRI: The application of compressed sensing for rapid MR imaging. Magn. Reson. Med. 58, 1182–1195 (2007).
Smith, S., Levante, T., Meier, B. H. & Ernst, R. R. Computer simulations in magnetic resonance. An object-oriented programming approach. J. Magn. Reson. Ser. A 106, 75–105 (1994).
Govindaraju, V., Young, K. & Maudsley, A. A. Proton NMR chemical shifts and coupling constants for brain metabolites. NMR Biomed. 13, 129–153 (2000).
Macura, S. & Brown, L. R. Improved sensitivity and resolution in two-dimensional homonuclear j-resolved NMR spectroscopy of macromolecules. J. Magn. Reson. 53, 529–535 (1983).
Wilson, N. E., Iqbal, Z., Burns, B. L., Keller, M. & Thomas, M. A. Accelerated five-dimensional echo planar j-resolved spectroscopic imaging: Implementation and pilot validation in human brain. Magn. Reson. Med. 75, 42–51 (2016).
Iqbal, Z., Wilson, N. E. & Thomas, M. A. 3d spatially encoded and accelerated te-averaged echo planar spectroscopic imaging in healthy human brain. NMR Biomed. 29, 329–339 (2016).
Wilson, N. E., Burns, B. L., Iqbal, Z. & Thomas, M. A. Correlated spectroscopic imaging of calf muscle in three spatial dimensions using group sparse reconstruction of undersampled single and multichannel data. Magn. Reson. Med. 74, 1199–1208 (2015).
Burns, B. L., Wilson, N. E. & Thomas, M. A. Group sparse reconstruction of multi-dimensional spectroscopic imaging in human brain in vivo. Algorithms 7, 276–294 (2014).
Burns, B., Wilson, N. E., Furuyama, J. K. & Thomas, M. A. Non-uniformly under-sampled multi-dimensional spectroscopic imaging in vivo: Maximum entropy versus compressed sensing reconstruction. NMR Biomed. 27, 191–201 (2014).
Krizhevsky, A., Sutskever, I. & Hinton, G. E. Imagenet classification with deep convolutional neural networks. Adv. Neural Inf. Process. Syst. 25, 1097–1105 (2012).
Kingma, D. P. & Ba, J. Adam: A method for stochastic optimization. arXiv preprint arXiv:1412.6980 (2014).
Fuchs, A., Boesiger, P., Schulte, R. F. & Henning, A. Profit revisited. Magn. Reson. Med. 71, 458–468 (2014).
Dang, L. et al. Cancer-associated idh1 mutations produce 2-hydroxyglutarate. Nature 462, 739 (2009).
Ogg, R. J., Kingsley, R. & Taylor, J. S. Wet, a t 1-and b 1-insensitive water-suppression method for in vivo localized 1 h NMR spectroscopy. J. Magn. Reson. Ser. B 104, 1–10 (1994).
Cao, P. & Wu, E. X. In vivo diffusion MRS investigation of non-water molecules in biological tissues. NMR Biomed. 30, e3481 (2017).
Nicolay, K., Braun, K. P., de Graaf, R. A., Dijkhuizen, R. M. & Kruiskamp, M. J. Diffusion NMR spectroscopy. NMR Biomed. 14, 94–111 (2001).
Ronen, I. & Valette, J. Diffusion-weighted magnetic resonance spectroscopy. eMagRes (2015).
Hurd, R. et al. Measurement of brain glutamate using te-averaged press at 3t. Magn. Reson. Med. 51, 435–440 (2004).
Brüschweiler, R. & Zhang, F. Covariance nuclear magnetic resonance spectroscopy. J. Chem. Phys. 120, 5253–5260 (2004).
Iqbal, Z., Verma, G., Kumar, A. & Thomas, M. A. Covariance j-resolved spectroscopy: Theory and application in vivo. NMR Biomed. 30, e3732 (2017).
Mobli, M., Stern, A. S. & Hoch, J. C. Spectral reconstruction methods in fast NMR: Reduced dimensionality, random sampling and maximum entropy. J. Magn. Reson. 182, 96–105 (2006).
Author information
Authors and Affiliations
Contributions
Z.I., M.A.T. and S.J. conceived the experiments, D.N. designed the deep learning architecture, Z.I. and D.N. conducted the deep learning experiments, Z.I. and M.A.T. simulated and processed the data, Z.I. and S.J. analyzed the results. All authors reviewed the manuscript.
Corresponding author
Ethics declarations
Competing interests
The authors declare no competing interests.
Additional information
Publisher's note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Iqbal, Z., Nguyen, D., Thomas, M.A. et al. Deep learning can accelerate and quantify simulated localized correlated spectroscopy. Sci Rep 11, 8727 (2021). https://doi.org/10.1038/s41598-021-88158-y
Received:
Accepted:
Published:
DOI: https://doi.org/10.1038/s41598-021-88158-y
Comments
By submitting a comment you agree to abide by our Terms and Community Guidelines. If you find something abusive or that does not comply with our terms or guidelines please flag it as inappropriate.
