
Abstract
This study was designed to develop and validate an early warning system for sepsis based on a predictive model of critical decompensation. Data from the electronic medical records for 537,837 visits to a pediatric Emergency Department (ED) from March 2013 to December 2019 were collected. A multiclass stochastic gradient boosting model was built to identify early warning signs associated with death, severe sepsis, non-severe sepsis, and bacteremia. Model features included triage vital signs, previous diagnoses, medications, and healthcare utilizations within 6 months of the index ED visit. There were 483 patients who had severe sepsis and/or died, 1102 had non-severe sepsis, 1103 had positive bacteremia tests, and the remaining had none of the events. The most important predictors were age, heart rate, length of stay of previous hospitalizations, temperature, systolic blood pressure, and prior sepsis. The one-versus-all area under the receiver operator characteristic curve (AUROC) were 0.979 (0.967, 0.991), 0.990 (0.985, 0.995), 0.976 (0.972, 0.981), and 0.968 (0.962, 0.974) for death, severe sepsis, non-severe sepsis, and bacteremia without sepsis respectively. The multi-class macro average AUROC and area under the precision recall curve were 0.977 and 0.316 respectively. The study findings were used to develop an automated early warning decision tool for sepsis. Implementation of this model in pediatric EDs will allow sepsis-related critical decompensation to be predicted accurately after a few seconds of triage.
Similar content being viewed by others


Introduction
In the United States, hospitalizations for severe sepsis doubled between 2000 and 2008, with an overall annual healthcare cost of $146 billion1. In children, sepsis is associated with high morbidity and mortality, especially among vulnerable patients with chronic conditions, who often require intensive treatment to avoid preventable death2. Even the limited number of pediatric deaths caused by sepsis is understood as too heavy a loss to bear when one considers that early interventions could have prevented it. While preventable deaths are rare in pediatrics, the prevalence of severe sepsis in children is increasing across the globe because of the increasing prevalence of drug-resistant infections3. The earliest opportunity for intervention prior to critical decompensation often arises in the emergency department (ED), the first point of contact between many patients and the healthcare system. Despite a recent increase in clinicians’ awareness of critical decompensation and severe sepsis, as well as associated changes in the corresponding diagnostic criteria1,2,3,4, pediatric-specific tools remain poorly developed. Stratifying risk with the systemic inflammatory response syndrome (SIRS) criteria or quick sequential [sepsis-related] organ failure assessment (qSOFA) typically takes approximately 1 h5. Methods that facilitate early warning and decision making may lead to process improvements and associated reductions in morbidity and mortality6,7. A predictive model for predicting patient death is ideal for capturing critical decompensation because even false-positive predictions help to identify patients in need of critical attention. In this study, we used stochastic gradient boosting to develop a predictive model for critical decompensation in pediatric ED patients. Stochastic gradient boosting is an approach of using multiple regression tree-based models to predict an event of interest. In this case, the trees are built sequentially in such a way that each additional tree minimizes the error of the ensemble.
Methods
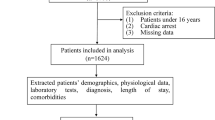
Triage data on all ED encounters from March 2013 to December 2019 at a tertiary pediatric institution were retrieved. To create an early warning tool with utility for non-emergency as well as emergency healthcare providers, outcome events were measured while the patients were in the ED or after admission to the hospital, when applicable. In evaluating the diagnosis codes entered into the electronic medical record (EMR), a multiclass outcome variable was created to capture: (1) patients who expired using all-cause mortality; (2) patients who had severe sepsis; (3) patients who had non-severe sepsis; (4) patients with positive bacteremia tests but no diagnosis of sepsis; (5) patients who experienced none of the four aforementioned events. Diagnostic codes (ICD-9-CM and ICD-10-CM) were used to identify patients with sepsis which facilitated the automated identification of sepsis—refer to the Supplemental Material for a list of codes.
Standard definitions for pediatric sepsis and severe sepsis have not been developed and validated. The Sepsis-1, Sepsis-2, and Sepsis-3 guidelines are for adult medicine with pediatric modifications8,9,10. The International Pediatric Sepsis Consensus Criteria (IPSCC) modified Sepsis-2 framework for specific pediatric age groups but the framework is complex, labor intensive, has limited overlap with sepsis diagnosed at the bedside, and is yet to be validated9,10,11. Also, less than 50% of children with septic shock were identified by the Sepsis-3 in a pediatric ICU study12. In July 2018, The US Centers for Disease Control and Prevention (CDC) convened a working group to outline a pediatric sepsis event case definition including a road map for future work needed to refine, validate, and apply the proposed algorithm11. The group, however, emphasized that recommendations for pediatrics were preliminary and subject to modification due to continued refinement and testing11.
A recent study indicated that (in adult medicine) diagnosis codes had greater specificity in identifying sepsis than implicit methods13, and that there is increasing consistency in the use of diagnosis codes14. Specificity may be more important than sensitivity in the definition of outcome variables for predictive modeling to reduce noise and the true false positive rates from the resulting model. In this study, we used both the ICD-10-CM R-codes (together with the corresponding ICD-9-CM codes) and explicit microbiological codes for sepsis. To compensate for potentially missed cases of sepsis and severe sepsis, we included a category of the response variable on all laboratory confirmed bacteremia.
Additional ED triage data retrieved included vital signs, use of supplemental oxygen, and skin assessment (description and color). The decision on the use of these triage data was driven by emergency physician recommendation, practical consideration of the data available, data likely to be available during triage, and the quality of data available from the triage form. After careful evaluation of the patient history as captured in the EMR, additional data such as previous diagnoses, medications administered (e.g., antibiotics), and past admission to the intensive care unit (ICU) were extracted. A complete list of variables included in the model can be seen in the summary statistics in Tables 1 and 2.
The data collected were randomly split into a training set (50%), a validation set (15%), and a test set (35%). We chose a greater percentage of data for the test set than the validation set to ensure that we can estimate model performance with higher statistical confidence. Extreme gradient boosting (an implementation of stochastic gradient boosting) was selected for development of the machine-learning algorithm due to its ability to model complex nonlinear systems with the automated management of missing data15. The seminar paper on stochastic gradient boosting by Friedman (2002) described the process succinctly as follows: “Gradient boosting constructs additive regression models by sequentially fitting a simple parameterized function (base learner) to current ‘pseudo’-residuals by least squares at each iteration. The pseudo-residuals are the gradient of the loss functional being minimized, with respect to the model values at each training data point evaluated at the current step”16. Ten-fold cross-validation was performed to select the optimal hyper-parameters from the parameter grid space (Table 3). Parameter values that improve learning on imbalanced datasets were selected to account for the rarity of pediatric deaths and severe sepsis in the dataset, while preserving the ability of the classifier to generate true probability values. Parameter space was designed to explore multiple interaction depths that controlled model complexity. Learning rate values were selected to control the rate convergence of the algorithm, and values for the minimum reduction in loss required to make an additional partition on the leaf node of a tree were specified. The minimum sum of instance weight needed in a child node, a subsample ratio of the training instances, a subsample ratio of columns/predictors when constructing a tree, and the maximum delta step allowed for each leaf output were also considered during hyper-parameter tuning15. When fitting the final model, the validation set was used to determine the optimal number of trees (or boosting iterations). The test set was used in evaluating unbiased model performances17, alert thresholds, confusion matrices17, and implementation strategies for the model.
The relative importances of various predictors were measured using the “Gain”, which is a measure of the improvement in predictive power brought by a feature/variable to a given tree branch15,18. The Shapley Additive Explanation (SHAP) values19,20, a concept from game theory, was used to provide simplified inferences on how the variables/features in the model contribute to the risk of severe sepsis. The higher the SHAP value, the higher the contribution to the risk of severe sepsis. It should be noted that the simplified inference from the SHAP value does not indicate how the value of a vital sign is modified by age, gender, or other pertinent variables even though the corresponding effects have been modeled. We provide the area under the receiver operator characteristic curve (AUROC), which highlights model performance in terms of the sensitivity and specificity of the model; and the area under the precision-recall curve (AUCPR), which highlights performance in terms of the sensitivity and positive predictive values of the model.
In multiclass prediction problems, the class with the highest probability is often selected as the actual model predicted class. This approach is likely to result in sub-optimal performance in a prediction problem involving class imbalance, as is encountered when predicting the most severe measures of decompensation: death or severe sepsis. As a result, a novel stepwise multiclass classification strategy was developed to determine how patients will be classified by the model based on the predicted probabilities for each class of the outcome variable. First, each class of the outcome variable was treated as a one-versus-all system such that the sensitivity, specificity, positive predictive value (PPV), negative predictive value (NPV), relative risk, and the number needed to evaluate (NNE) can be estimated from the corresponding binary classification sub-problem. This way, per-class predicted probability thresholds can be selected to minimize per-class as well as overall model misclassification rates while preserving sensitivity on the rarest outcomes. The study team (including emergency medicine and other providers) selected levels of specificity for each class to minimize the error produced during positive classification for the class21,22, while maintaining acceptable levels of model sensitivity. A prioritization of the classes of the outcome variable was specified by the providers based on the perceived relative clinical significance of each class. The order of perceived clinical significance, in decreasing order, was established as severe sepsis, death, non-severe sepsis, and bacteremia. Severe sepsis was ranked as having higher clinical significance because of the expectation that patients who are indeed close to death are less likely to be missed by providers during triage than patients likely to have severe sepsis—and both are the most severe measures of decompensation in the model/study.
The study was carried out using the Cerner HealtheDataLab23 platform as well as the R Statistical Programming Language. Several R packages were used for the development of the machine learning model as well as estimating model performance and simplified inference15,18,24.
This study was approved by the Institutional Review Board of Children’s Hospital of Orange County, Orange, CA 92868 with Institutional Review Board approval number 180857. The need for informed consent was waived by the Institutional Review Board of Children’s Hospital of Orange County, Orange, CA 92868 and all aspect of the work were carried out in accordance with relevant guidelines/regulations including the Helsinki Declaration.
Results
There were 537,837 qualifying encounters: 213 patients died; 295 had severe sepsis; 1102 had non-severe sepsis; 1103 had bacteremia without sepsis. The mortality rate, incidence of severe sepsis, incidence of non-severe sepsis, and bacteremia were 0.04%, 0.05%, 0.20%, and 0.21% respectively. Among patients with severe sepsis, 20 (6.8%) died. A total of 2048 encounters were associated with at least one of these undesirable events and markers for potential decompensation. The median and interquartile range of the ages of the patients in the study were 4 and 8 years, respectively. There were 46·4% female patients and 62.4% Hispanic patients. Summary statistics of all 46 variables considered by mortality, severe sepsis, non-severe sepsis, and bacteremia without sepsis are shown in Tables 1 and 2. T-tests and Chi-squared tests were carried out to assess univariable (unadjusted) tests of association at an alpha level of 0.05. Firstly, all variables were associated with mortality except viral vaccines, body temperature, history of conditions affecting the ear and mastoid process, history of pregnancy or related conditions, and patient sex. Secondly, all variables were associated with severe sepsis except the use of supplemental oxygen device, history of conditions affecting the ear and mastoid process, and patient ethnicity. Thirdly, only history of conditions affecting the ear and mastoid process, history of pregnancy or related conditions, ethnicity, and patient sex did not achieve univariable significance with non-severe sepsis. Lastly, only history of conditions affecting the ear and mastoid process were not significant in relation to bacteremia. The large number of variables with univariable significance in the data may have been partly driven by the large sample size in this study.
In Fig. 1, we show the feature importance of the variables/features in the model in decreasing order. The gradient boosting model consisted of 31 boosting iterations/trees, maximum tree depth of 8, learning rate of 0.3, and maximum delta step of 8. SHAP plots and simplified explanations of the clinical presentations that inflate the risk of severe sepsis for the top 12 most important variables are shown in Figs. 2 and 3.

Feature/variable importance.

Shapley additive explanation for severe sepsis: top 6 most important features.

Shapley additive explanations for severe sepsis: second 6 most important features.
The most important feature for predicting decompensation (mortality, severe sepsis, non-severe sepsis, and bacteremia) on ED triage was age. Older children are at higher risk of severe sepsis than their younger peers. The importance of age may lie in how the feature modifies others, such as vital signs. As expected, patients with abnormal vital signs were found to be at the highest risk for sepsis, as shown in Figs. 2 and 3. These figures were obtained by fixing the values of other variables at the average value for continuous variables and the most common categorical levels for categorical variables. This is a simplification of the nonlinear cross-dependences captured by the model between each vital sign and other vital signs and variables included in the model. This nonlinear cross-dependence is likely captured with a maximum tree depth of 8, indicating up to 7-way nonlinear interactions between variables in the model. This implies that the effect of a fever (or high heart rate etc.) on the risk of severe sepsis has been considered while factoring the age and sex of the patient as well as the values of other vital signs and variables in the model. This is the strength that machine learning models bring to the modeling of complex medical conditions or events.
We included some novel features/variables in the model that were among the 12 most important features. These include histories of the maximum value of previous hospital length of stay, diagnosis of sepsis, intravenous medications, non-topical antibiotics, and carbapenems. Averaged over the effect and interactions with other variables, there is increased risk for severe or sepsis-related decompensation among patients with history of longer hospital length of stay, sepsis, non-topical antibiotics, and carbapenems.
Model performance and risk stratification
The per-class one-versus-all AUROC mortality, severe sepsis, non-severe sepsis, and bacteremia were 0.979 (0.967, 0.991), 0.990 (0.985, 0.995), 0.976 (0.972, 0.981), and 0.968 (0.962, 0.974), respectively—see Fig. 4. The corresponding multi-class macro average AUROC and AUCPR were 0.977 and 0.316, respectively. The one-vs-all AUCPRs are provided in Fig. 5.

(a) One-versus-all areas under the receiver operator characteristic curves for mortality. (b) One-versus-all areas under the receiver operator characteristic curves for severe sepsis. (c) One-versus-all areas under the receiver operator characteristic curves for other/non-severe sepsis. (d) One-versus-all areas under the receiver operator characteristic curves for bacteremia.

(a) One-vs-all areas under the precision-recall curves for mortality. (b) One-vs-all areas under the precision-recall curves for severe sepsis. (c) One-vs-all areas under the precision-recall curves for other/non-severe sepsis. (d) One-vs-all areas under the precision-recall curves for bacteremia.
We used a stepwise approach for class selection that differs from simply choosing the output class with the highest predicted probability from the softmax (multi-class) output. We first selected a threshold for classifying a patient at high risk of severe sepsis using model performance statistics from a one-vs.-all approach to address the problem of class imbalance and ensure that model sensitivity is not lost to model specificity. Given the extreme class imbalance, we selected a specificity of 99.5%, resulting in a predicted probability threshold for severe sepsis of 0.0066. The resulting performance for predicting severe sepsis included sensitivity of 71.1% (62.1%, 80.2%), positive predictive value of 6.8% (5.3%, 8.4%), negative predictive value of 99.99% (99.98%, 99.99%), relative risk of 457.3 (296.0, 706.3), and an F-1 score of 0.125. In the same way, we fixed the specificity for mortality at 99.5% in a one-vs-all approach. The resulting performance for predicting mortality included sensitivity of 54.3% (43.0%, 63.5%), positive predictive value of 5.0% (3.6%, 6.3%), negative predictive value of 99.98% (99.97%, 99.98%), relative risk of 215.8 (143.9, 323.4), and F-1 score of 0.091. For the remaining 3 classes, we chose the class with the highest predicted probability if the conditions for flagging severe sepsis and death were not met. This approach resulted in balanced accuracy25,26 in predicting severe sepsis ranging from 52 to 85%. In a similar way, the balanced accuracy25,26 for predicting mortality increased from 54 to 62% using this modified approach.
The AUROC overestimates the model performance while the AUCPR underestimates it. In Table 3, we provide an unbiased statistics to help better assess the model. The potential for alert fatigue at an acceptable level of sensitivity gives us more concrete and assessible way of evaluating the model. One patient in 15 flagged at risk for death will die with sensitivity of 67% (not counting patients with severe sepsis who later die). One patient in 16 flagged at risk for severe sepsis will develop severe sepsis with sensitivity of 85%. One in two patients flagged at risk for other (non-severe) sepsis or bacteremia will suffer the respective outcome. False positives for death and severe sepsis are also of interest to ED providers because they bear similarity to patients who die or had severe sepsis or may be suffering other forms of deterioration.
Discussion
Severe sepsis is a life-threatening response to infection and is a leading cause of death in children, with 75,000 cases resulting in 6500 deaths and a nearly $5 billion burden of care per year in the U.S. alone as well as a morbidity of 8–21%1,2,3,4. Early diagnosis and intervention significantly improves outcomes, however severe sepsis in children remains difficult to identify. Instances of severe sepsis continue to rise, and current rule-based models are insufficient in predicting its onset.
Accurate patient assessments within seconds of triage in the ED would allow clinicians to effectively manage patient decompensation, thus improving clinical outcomes and ultimately increasing the cost-effectiveness of the care administered. An effective algorithm would differentiate risk for critical events such as death and severe sepsis from risk for less critical events such as non-severe sepsis and bacteremia (without sepsis).
Several inpatient surveillance tools and rules-based systems such as the SIRS criteria and qSOFA are currently in widespread use5,9,27,28. In a 2017 study that compared the utility of the SIRS criteria and the qSOFA score, it was noted that the mean time from arrival at the ED to the identification of risk for decompensation was 47.1 min for SIRS documentation and 84·0 min for the qSOFA5. Clinicians must decrease the amount of time that elapses before patients at severe risk of decompensation are identified in order to deliver the most effective care and to help mitigate complications including death. On implementation of the model described here in the EMR of the corresponding author, the time from triage to prediction was between 5 and 7 s—a significantly earlier predictor for sepsis and related decompensation.
Previous studies have investigated the ability to predict general infection, sepsis, or severe sepsis among patients in the ED, intensive care unit, or general hospital ward using vital signs29,30,31,32,33. Vital signs and laboratory test results were used as predictors. In this study, we considered vital sign measurements captured during triage as well as the medical history of the patient during the 6 months prior to the index visit. We used these data to develop a real-time predictive model that could classify pediatric patients under a continuum of risk for critical decompensation.
The vital sign measurements obtained from the pediatric patients seen at our ED were similar to those reported previously. The machine-learning algorithm that we developed using stochastic gradient boosting learned the thresholds and interactions with age, other vital signs, and other relevant variables such as prior diagnoses. We identified a relationship between prior resource utilization and severe sepsis and decompensation. Patients with previous hospitalizations are generally at increased risk for sepsis with this risk increasing with the length of stay of these previous visits. Our results suggest that considerations of the patient’s history of previous sepsis diagnosis and treatment with antibiotics would improve the accuracy of tools currently used to screen for sepsis. Risk of severe sepsis is elevated in patients who had received carbapenem and other antibiotics during a previous hospitalization. This may indicate that there are lingering effects of past or recent bacterial infections treated with carbapenem that may elevate the risk of developing severe sepsis. This also suggests that certain patients are more susceptible to severe complications from infections. Identifying these high-risk patients in a timely manner can improve patient outcomes.
The model performance estimates were relatively good given the class imbalance (patients with sepsis compared to those without). But the relatively high number of false positives required to capture a true positive (as captured by the number needed to evaluate) would likely run the risk of alert fatigue for severe sepsis if the positive predictive values are not properly communicated to providers. However, further analyses of the false-positive predictions in the individual strata revealed that these groups of patients had high morbidity even without the diagnosis of severe sepsis. These false-positive patients included those requiring hospitalization and admission to the intensive care unit (ICU). In other words, even the model’s false positives for severe sepsis are of clinical utility to providers in the ED in predicting the risk of other decompensation events. This raises the question of whether the subject of deterioration is possibly more important to clinicians than just identification of sepsis or severe sepsis since screening and identification of criticality, of any kind, could be helpful to stimulate early and more general interventions. We believe that specific identification of sepsis and severe sepsis can prompt specific goal-directed interventions such as improved door to antibiotic times and early fluid resuscitation both of which are believed to be clinically important. Further, alerts generated on individual disease screening could be more useful than general alerts of criticality when it comes to achieving provider compliance with order sets.
This study had several limitations. Sepsis was identified using diagnosis codes and the corresponding model was created using a single center dataset. Additional studies based on the use of a larger multicenter dataset could provide a more accurate model. Although previous studies have demonstrated the utility of laboratory examinations and physician documentation for early sepsis identification34, we did not consider laboratory test values because laboratory results are not available at the time of triage. Another potential limitation, inherent in the use of electronic applications that depend on data, is the impact of bad or unexpected data. Data hastily entered during patient registration and during ED triage may invariably include errors that could result in unexpected failure, underestimation, or overestimation of risk. Also, patients who are likely to have sepsis, proceed to severe sepsis, and die will be captured in only one category. As a result, all 3 corresponding predictions should be taken seriously.
The performance of our model indicates that a high proportion of patients with severe sepsis will be captured by the model. Notably, even false-positive predictions are of clinical value. The quality of care of patients at risk of severe sepsis can be improved if the predictions of the model are used in tandem with intervention protocols for severe sepsis. It is well known that early antibiotics and fluid resuscitation can improve clinical outcomes and prevent death in patients with severe sepsis7. Early identification of this subset of patients will lead to better care. The inpatient ward can be notified much earlier regarding the transfer of a high-risk patient. This could improve the early allocation of resources for such hospitalizations as well as increase the amount of time available for the clinical team to prepare for these patients, who are likely to require intensive care and/or close monitoring. The stochastic gradient boosting algorithm, extreme gradient boosting, was selected for this prediction tasks because it can appropriately handle missing data without convoluted statistical imputation processes, and it is very competitive with other algorithms in terms of model performance. This model can be implemented electronically and automatically integrated within the electronic medical record to provide an early warning tool for patients at risk of severe sepsis and poor outcomes within a few seconds of ED triage. In conclusion, the development of an extreme gradient boosting model based on selected ED triage variables can be used as an early warning tool for severe sepsis.
Data availability
The dataset analyzed in this study are available from the corresponding authors on reasonable request and upon approval by the Institutional Review Board (IRB) of the corresponding authors’ institution to share the data.
References
Hartman, M. E., Linde-Zwirble, W. T., Angus, D. C. & Watson, R. S. Trends in the epidemiology of pediatric severe sepsis. Pediatr. Crit. Care Med. 14(7), 686–693 (2013).
Weiss, S. L. et al. Global epidemiology of pediatric severe sepsis: The sepsis prevalence, outcomes, and therapies study. Am. J. Respir. Crit. Care Med. 191(10), 1147–1157 (2015).
Balamuth, F. et al. Pediatric severe sepsis in US children’s hospitals. Pediatr. Crit. Care Med. 15(9), 798 (2014).
Ruth, A. et al. Pediatric severe sepsis: Current trends and outcomes from the Pediatric Health Information Systems database. Pediatr. Crit. Care Med. 15(9), 828–838 (2014).
Haydar, S., Spanier, M., Weems, P., Wood, S. & Strout, T. Comparison of QSOFA score and SIRS criteria as screening mechanisms for emergency department sepsis. Am. J. Emerg. Med. 35(11), 1730–1733 (2017).
Paul, R. et al. A quality improvement collaborative for pediatric sepsis: Lessons learned. Pediatr. Qual. Saf. 3(1), e051 (2018).
Rivers, E. P. & Ahrens, T. Improving outcomes for severe sepsis and septic shock: Tools for early identification of at-risk patients and treatment protocol implementation. Crit. Care Clin. 24(3 Suppl), S1-47 (2008).
Bone, R. C. et al. Definitions for sepsis and organ failure and guidelines for the use of innovative therapies in sepsis. Chest 101(6), 1644–1655 (1992).
Goldstein, B. et al. International pediatric sepsis consensus conference: Definitions for sepsis and organ dysfunction in pediatrics. Pediatr. Crit. Care Med. 6(1), 2–8 (2005).
Sankar, J. et al. Comparison of international pediatric sepsis consensus conference versus sepsis-3 definitions for children presenting with septic shock to a tertiary care center in India: A retrospective study. Pediatr. Crit. Care Med. Soc. Crit. Care Med. 20(3), e122–e129 (2019).
Hsu, H. E. et al. A national approach to pediatric sepsis surveillance. Pediatrics 144(6), 2019 (2019).
Sterling, S. A., Puskarich, M. A., Glass, A. F., Guirgis, F. & Jones, A. E. The impact of the Sepsis-3 septic shock definition on previously defined septic shock patients. Crit. Care Med. 45(9), 1436 (2017).
Fleischmann-Struzek, C. et al. Comparing the validity of different ICD coding abstraction strategies for sepsis case identification in German claims data. PLoS ONE 13(7), e0198847 (2018).
Bouza, C., Lopez-Cuadrado, T. & Amate-Blanco, J. M. Use of explicit ICD9-CM codes to identify adult severe sepsis: Impacts on epidemiological estimates. Crit. Care. 20(1), 1–12 (2016).
Chen, T. et al. xgboost: Extreme Gradient Boosting (Springer, 2019).
Friedman, J. H. Stochastic gradient boosting. Comput. Stat. Data Anal. 38(4), 367–378 (2002).
Luque, A., Carrasco, A., Martín, A. & de las Heras, A. The impact of class imbalance in classification performance metrics based on the binary confusion matrix. Pattern Recognit. 91, 216–231. https://doi.org/10.1016/j.patcog.2019.02.023 (2019).
Chen, T., He, T., Benesty, M. Xgboost: Extreme gradient boosting. R Packag version 04–3. Published online 2015. http://cran.fhcrc.org/web/packages/xgboost/vignettes/xgboost.pdf. Accessed 21 Mar 2018.
Shapley, L. S. A value for n-person games. Contrib. Theory Games. 2(28), 307–317 (1953).
Lundberg, S. M. & Lee, S.-I. A unified approach to interpreting model predictions. Adv. Neural Inf. Process. Syst. 1, 4765–4774 (2017).
Ehwerhemuepha, L., Finn, S., Rothman, M. J., Rakovski, C. & Feaster, W. A novel model for enhanced prediction and understanding of unplanned 30-day pediatric readmission. Hosp. Pediatr. 8(9), 578 (2018).
Ehwerhemuepha, L. et al. A statistical learning model for unplanned 7-day readmission in pediatrics. Hosp. Pediatr. 10(1), 43–51 (2020).
Ehwerhemuepha, L. et al. HealtheDataLab: A cloud computing solution for data science and advanced analytics in healthcare with application to predicting multi-center pediatric readmissions. BMC Med. Inform. Decis. Mak. 20(1), 1–12. https://doi.org/10.1186/s12911-020-01153-7 (2020).
Team RC. R: A Language and Environment for Statistical Computing. Published online 2017.
Brodersen, K. H., Ong, C. S., Stephan, K. E., & Buhmann, J. M. The balanced accuracy and its posterior distribution. 2010 20th International Conference on Pattern Recognition (3121–3124). (2010).
Garcia, V., Mollineda, R. A., Sánchez, J. S. Index of balanced accuracy: A performance measure for skewed class distributions. Iberian Conference on Pattern Recognition and Image Analysis (2009).
Fischer, J. & Fanconi, S. Systemic Inflammatory Response Syndrome (SIRS) in Pediatric Patients. Intensive Care in Childhood 239–254 (Springer, 1996).
Vincent, J.-L., Martin, G. S. & Levy, M. M. qSOFA does not replace SIRS in the definition of sepsis. Crit Care. 20(1), 210 (2016).
Mao, Q. et al. Multicentre validation of a sepsis prediction algorithm using only vital sign data in the emergency department, general ward and ICU. BMJ Open 8(1), e017833 (2018).
Shashikumar, S. P. et al. Early sepsis detection in critical care patients using multiscale blood pressure and heart rate dynamics. J. Electrocardiol. 50(6), 739–743 (2017).
Kamaleswaran, R. et al. Applying artificial intelligence to identify physiomarkers predicting severe sepsis in the PICU. Pediatr. Crit. Care Med. 19(10), e495–e503 (2018).
Nachimuthu, S. K., Haug, P. J. Early detection of sepsis in the emergency department using Dynamic Bayesian Networks. AMIA Annual Symposium Proceedings, Vol 2012. (2012).
Masino, A. J. et al. Machine learning models for early sepsis recognition in the neonatal intensive care unit using readily available electronic health record data. PLoS ONE 14(2), e0212665 (2019).
Lamping, F. et al. Development and validation of a diagnostic model for early differentiation of sepsis and non-infectious SIRS in critically ill children: A data-driven approach using machine-learning algorithms. BMC Pediatr. 18(1), 112 (2018).
Author information
Authors and Affiliations
Contributions
L.E. conceived of the study, built the corresponding machine-learning model, led the technical parts of model implementation, and drafted the initial manuscript. He reviewed and revised the final manuscript. T.H. conceived of the study, assisted with model interpretation and alerting strategy development, and oversaw implementation of the model. He drafted portions of the manuscript and reviewed and revised the final manuscript. R.M. assisted with model interpretation, alerting strategy development, and reviewed and revised the final manuscript. M.J.P. assisted with model interpretation, alerting strategy development, and reviewed and revised the final manuscript. A.A. assisted with model interpretation, alerting strategy development, and reviewed and revised the final manuscript. K.L. conceived of the study and assisted with model interpretation. He reviewed and revised the final manuscript. J.H. conceived of the study, assisted with model interpretation, and reviewed and revised the final manuscript. J.C. assisted with model interpretation and alerting strategy development. He reviewed and revised the final manuscript. K.H. assisted in drafting, reviewing, and revising the paper, and worked with L.E. on finalizing the draft paper. W.F. conceived of the study and assisted with model development/adoption and interpretation. He oversaw model implementation and alerting strategy development. He reviewed and revised the draft and final manuscripts. L.E. and T.H. verified the underlying data used for this study.
Corresponding author
Ethics declarations
Competing interests
The authors declare no competing interests.
Additional information
Publisher's note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Supplementary Information
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Ehwerhemuepha, L., Heyming, T., Marano, R. et al. Development and validation of an early warning tool for sepsis and decompensation in children during emergency department triage. Sci Rep 11, 8578 (2021). https://doi.org/10.1038/s41598-021-87595-z
Received:
Accepted:
Published:
DOI: https://doi.org/10.1038/s41598-021-87595-z
Comments
By submitting a comment you agree to abide by our Terms and Community Guidelines. If you find something abusive or that does not comply with our terms or guidelines please flag it as inappropriate.
