
Abstract
Recent advances in computer vision and deep learning techniques have facilitated significant progress in video scene understanding, thus helping film and television practitioners achieve accurate video editing. However, so far, publicly available semantic segmentation datasets are mostly limited to indoor scenes, city streets, and natural images, often ignoring example objects in action movies, which is a research gap that needs to be urgently filled. In this paper, we introduce a large-scale, high-precision semantic segmentation dataset of props in Chinese martial arts movie clips, named ChineseMPD. Specifically, this dataset first establishes segmentation rules and general review criteria for audiovisual data, and then provides semantic segmentation annotations for six weapon props (Gun, Sword, Stick, Knife, Hook, and Arrow) with a summary of 32,992 objects.To the best of our knowledge, this dataset is the largest semantic segmentation dataset for movie props to date. ChineseMPD dataset not only significantly expands the application of traditional tasks of computer vision such as object detection and scene understanding, but also opens up new avenues for interdisciplinary research.
Similar content being viewed by others
Background & Summary
Semantic segmentation and scene understanding and have become important research directions in the field of computer vision1,2,3,4,5,6, with applications covering a wide range of areas including autonomous driving6, surface crack detection1, and so on. Among these task, semantic segmentation is crucial, as recognizing and classifying different instance objects at the pixel level is one of the most important methods for scene understanding. Chinese martial arts movies provide a unique and fascinating research area for semantic segmentation due to their rich visual and cultural heritage. These films are characterized by complex fight scenes and iconic props, elements that play a crucial role in narrative and aesthetics. However, although several seminal datasets such as Cityscapes7, PASCAL VOC 20128 and COCO Stuff9 datasets are available, they often focus on semantic segmentation of urban scenes or natural scenes, neglecting prop segmentation in movie scenes. Currently, semantic segmentation of props in Chinese martial arts movies is still challenging due to the lack of benchmark datasets.
Existing movie datasets can be divided into two categories. One category is movie description datasets. Heilbron et al.10 introduced ActivityNet, a movie video dataset for understanding human activities. The dataset contains 203 videos of different categories that can be used for human activity understanding, e.g., video categorization or activity detection. Tapaswi et al.11 proposed the MovieQA dataset for purposes aimed at evaluate the ability of algorithms to automatically understand video and text stories. It contains 14,944 multiple-choice questions and the corresponding 5 multiple-choice answers. Huang et al.12 used MovieNet, a multimodal dataset for movie comprehension, which contains annotations corresponding to different aspects of descriptive text, location and action labels, and detection frames. Although these video scenes are rich, they lack corresponding segmentation labels and are often used for classification tasks such as video classification, scene recognition and sentiment analysis.
There are very few available datasets for segmentation of video objects, except for movie descriptions. Pont-Tuset et al.13 proposed DAVIS, a public dataset and benchmark designed specifically for the task of video object segmentation.DAVIS contains dense semantic annotations for different objects in different life scenarios. Wei et al.14 proposed an actor-centered dataset for video object segmentation YouMVOS. This data is labeled only for the segmentation of multiple shots of the actors themselves. Similarly, Ding et al.15 proposed MOSE, a semantic segmentation dataset containing 5,200 video objects in 36 categories. This dataset aims to explore the ability of artificial intelligence (AI) algorithms for video object segmentation of common objects in complex scenarios. In summary, there is no publicly available dataset for martial arts props, and the only existing publicly available dataset for semantic segmentation of video objects not only differs from martial arts props in terms of object shapes and sizes, but also is not applicable to semantic segmentation of martial arts props.
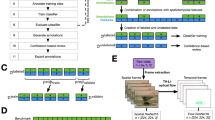
To address these gaps, this paper introduces ChineseMPD, a semantic segmentation dataset of props from classic Chinese martial arts movies. ChineseMPD provides pixel-level annotations for six categories, including Gun, Sword, Stick, Knife, Hook, and Arrow. Fine annotations are provided for the props in the images through fine-grained annotation and strict review process to ensure the high quality and authenticity of the dataset. The pipeline of our proposed Chinese martial arts film props dataset can be seen from the Fig. 1. Based on the video data of 8 action movies segments, the dataset provides a summary of 32,992 objects with fine annotations showing different scenes (e.g., fight scenes, training scenes, ritual scenes, rest scenes, and market scenes). The selected clips from Chinese martial arts films feature unique action sequences. Through continuous narrative blocks and a series of individual shots, these clips ultimately present the “chivalrous” plot, which combines aesthetics and storytelling. However, particularly with continuous frame images that contain narrative elements, it is challenging to annotate film clips using automated models. Firstly, due to the limitations of composition, shooting angles, and lighting, the model cannot distinguish between deliberate blurriness and occlusions. Secondly, the differences between continuous frame labels are significant and rely heavily on contextual semantic understanding, making it difficult to correlate the rich semantic information in films. Thirdly, the dynamic object labels within the film clips are often neglected. Our dataset employs fine-grained semantic segmentation techniques to deeply annotate props in Chinese martial arts films. In addition, we have established relevant rules and comments for the extraction and annotation of film clips. In order to more clearly visualize the content of our marks, Fig. 2 provides the specific distribution of various props in A-H movie clips.

Pipeline of Chinese martial arts film props dataset. (A) Data selection. Select the movie slice with plot and props to determine the category of semantic segmentation; (B) Rule establishment. Different colors are used to distinguish the semantic segmentation categories, and the rules for labeling props are established. (C) Data labeling. Label the props in film clips. (D) Data review. Experienced three more rigorous reviews.

Number of props annotations per clip. A–H represent 8 different Chinese martial arts classic movie clips.
Our dataset provides a new perspective to explore and analyze the complex interactions and dynamic changes in videos by complementing the existing semantic segmentation of movie objects. In addition, the establishment of the dataset promotes research in the field of computer vision on cutting-edge technologies such as motion recognition, scene reconstruction, and virtual reality, which offers the possibility of realizing a more intelligent and automated film and television post-production process. Meanwhile, it also provides rich materials for interdisciplinary research, promotes the integration of AI with cultural analysis, historical research and other fields, and opens up new ways for the digital protection and innovative inheritance of traditional cultural heritage.
Methods
This section reviews the process of our collection and implementation of the dataset of Chinese martial arts film props. The labeling of props was performed manually with AI assistance, which will be elaborated on in this section. At the same time, we have also established a special annotation and review method for the film props dataset.
Participants
A total of 21 people participated in data labeling and review. Among them, the data labeling personnel is composed of 11 undergraduates, and the reviewing personnel is composed of 3 junior auditors, 2 senior auditors and 5 acceptance personnel. The data labeling personnel received 7 days of theoretical training and labeled 2000 images. The data reviewing personnel conducted research and discussion on international standards and segmentation requirements in the early stage, and gained a comprehensive understanding of video labeling. Moreover, the participants jointly formulated the specification and criteria for the annotation and review of the dataset, such as the review rules for object contours and fuzzy images in the annotation of props.
Data collection
We selected film clips from the China Film Archive (https://www.cfa.org.cn) and Zhejiang Communication Television Art Archive (http://ysys.cuz.edu.cn) for labeling of film props. The resolution of selected films is 2560 × 1440 and 1920 × 1080. The selection process for film clips starts in October 2021 and ends in March 2022, and the annotation process starts in October 2021 and ends in August 2022. These clips were carefully selected following copyright reviews and are used solely for academic research purposes, adhering to academic standards. Specifically, according to Article 22 of the Copyright Law of the People’s Republic of China, the limited use of published works for teaching and research purposes is permitted under specific conditions. There are no copyright issues involved. Finally, we selected eligible clips from more than 700 movie clips to build our dataset16, each clip is about 2 minutes long. It is important to note that the total number of labeled props varies depending on the specific requirements of each film clip and the relevant scene. Swords and knives have more counts than others among the various props.
Data extraction
The plotshot division of the film clip was completed by a graduate student with rich editing experience. The film clip was roughly and finely cut with Adobe Premiere, the film image and audio were aligned, the subtitles of which blocked the images were removed. Finally, the movie clips are extracted at a rate of 4 frames per second. Each movie clip is saved as a JPG image with a resolution of 1920 × 1080 pixels.
Interactive annotation
To ensure the quality and time consuming are within our affordable range, we used interactive annotation tool EISeg17 to label frame images with high accuracy, which is able to annotate images in an interactive way. In addition, EISeg embedded segmentation algorithms for both the coarse and fine granularity levels, which facilitate the annotation procedure. As shown in Fig. 3, this method can generate an annotation mask, it is convenient to adjust the polygon vertices of the mask to further improve the accuracy.

Illustration of annotated images. The annotated items are distinguished by different colors, and the edge annotation points are connected into a semantic segmentation outline.
Data generation
As shown in Fig. 4, to make our marked props more clear and more distinct, we have made corresponding annotation examples for the content interacting with the props. The dataset we provide also has relevant labels for obvious characters and scenes, which can provide research references. Specifically, through the previously selected label, the props are manually marked and the edges are corrected. Each segmented shot is annotated with contours referencing the format used in the COCO dataset. The annotations and corresponding labels are subsequently stored in JSON format once the contours are finalized. The default path for saving is the new label folder in the dataset folder, where JSON files of all marked points are stored at the same time. For the reason that it is not necessary to perform semantic segmentation by edge tracing points, but by clicking any part of the props, the method propsed by Benenson et al.18 was used to generate the mask. In order to ensure the quality of annotation, we have also established a set of annotation checking specifications for the segmentation of film and television elements and props, making our dataset16 more reliable.

Semantic segmentation dataset annotation of props in film clips. The props are Sword, Stick, Hook, Arrow, Knife and Gun. From left to right, they are Original, Colour mask and Foreground. The colour mask unifies the contents of the removed labels into a blue background; Foreground realizes the visualization of annotation types.
Annotation checking specifications
The semantic segmentation types of martial arts film props include Knife, Sword, Gun, Stick, Hook, and Arrow, as shown in Table 1. In the actual annotation process, we have established a set of standards for props semantic segmentation dataset annotation checking, as shown in Fig. 5. The composition of the audit team is as follows: primary audit (3 persons), senior audit (3 persons), and senior management (2 persons) to audit and correct the annotation effectively. Advanced audit returns unqualified datasets and corrects them according to the established rules, which can be stated as:

Pipeline of props annotation and corresponding checking specifications. (a) Procedure of props annotation. (b) Procedure of annotation inspection.
For the area of the image to be annotated, we define an indicator called Pixel Boundary Error (PBE), which can be formulated as: \(PBE=\frac{a\cap b}{a\cup b};\) where a ∩ b is the area of overlap between the actual props to be labeled and the presumed props; a ∪ b is the sum of the area for current labeled props and the actual props. Specifically, we require a PBE of not more than 0.75 for stationary objects and less than 0.85 for moving objects. The examples of unqualified annotations can be seen in Table 2.
Data Records
This section summarizes the entire processing flow of our dataset. The dataset16 is open to the public and provide the necessary ways to use and organize data. Researchers can register with ScienceDB to access the FTP download link to our dataset. For ScienceDB account authentication and registration procedures, see https://www.scidb.cn/en. The link to access our dataset is https://www.scidb.cn/en/anonymous/SlpaelFy.
Data selection
The film selection is related to each subsequent step, we chose Chinese martial arts film clips to build the dataset. There are a lot of fighting scenes in Chinese martial arts film clips, and the props interact with people to a large extent. The choice of martial arts props can also cover China’s classic weapons. The martial arts films we first selected are shots lasts about 2 minutes, no shading and blurring are shown in these shots, which ensures the authenticity of the screen. Based on selected shots, the movie clip images are then extracted under the a rate of 4 frames per second for one shot.
Data annotation
Film props account for a small proportion of the film screen. Although the semantic segmentation model has achieved high accuracy in today’s increasingly developed in-depth learning, to ensure that the quality of the dataset is under control, we invited experts with specialized technical backgrounds to participate in the project for early assessment.
Data organization
The organized dataset is composed of several folders. Each folder contains a specific sequence of data. For each of image, three labeled images will be generated, namely the pseudo color image, the grayscale image, and the cutout image. The purpose of generating three labeled images is to increase the intuitive understanding of the segmented image. The annotation points of the image are presented in a JSON file. As shown in Fig. 6, we name the similar movie clips as the same ID, such as “m00x”. “m00x_fen” is a frame image folder formed after four frames per second segmentation at the shot level. The same level also contains descriptions of segmentation specifications; It is described by “m00x_label.txt” (label semantics and numerical matching relationship information) and “m00x_details.xlsx” (details of labels and related descriptions). The next level is the dataset of x shots, named “m00x_fen00x_dataSet”, which contains m00x_ fen00038_00000001.jpg (the original frame used for annotation) and a label folder, which is used to store the annotated data. Each original frame image contains three labeled images, as well as a JSON file named “annotations.json” with the information about annotation points.

Folder level. The entire dataset is divided into four levels. The upper part is the description of the dataset, and the lower part is the actual name. The sections marked black are folders, and the others are in corresponding formats.
Technical Validation
As for the technical verification of dataset, a technical team composed of 5 experts conducted manual checking and sampled the labeled props at the interval of three images. Each expert conducted an independent visual inspection of all labels to ensure the accuracy. The props in this study were manually annotated, so a set of strict technical methods is also established during the inspection. This method takes into account the continuity and consistency between the frames and establishes a judgment standard for the possible fuzziness of props. Images with high dynamic blur are not considered, because they are not useful for the content that may be studied.
During the technical inspection, we use the annotation tool EISeg to visualize the labeled image stacked on the original image, which can help us not to omit other information during the inspection. In addition, we have specified relevant parameters setting for annotation tool before labeling, which can reduce the variance in manual operation. Specifically, the technical standard of sampling can be described as: for dynamic fuzzy or high-speed moving annotation objects, the pixel error is within 3 pixels. For ordinary annotation objects such as props interacting with the scene or stationary props, the pixel error is within 5 pixels. The parameters of EISeg are set as follow: the segmentation threshold is set as 0.5, the label transparency is set as 0.75, and the visualization radius is set as 3.
For quality assurance, five experts will conduct a total of two rounds of visual inspection of the labeled masks according to the above standards, and the labeled images that do not meet the standards will be re-labeled. Table 2 shows the images which do not meet the standard and the corresponding problems, number of error pixels and items. Both two rounds of expert inspection need to meet the above criteria to ensure that the final high quality labels and usage availability. Fig. 7(a),(b) shows the error bars before and after the expert team’s verification in first and second inspection round. It can be conclude that after two rounds of expert inspection, the annotation errors of all classes of props in our dataset reduced from the 2-4 mm to 1.5-3.5 mm, which demonstrates the validity of our proposed criteria, and also proves the effectiveness and great contribution of expert inspection in indicating the quality of the labeling of our dataset.

Boxplots of annotation errors in all classes of props. (a) The first round inspection by the expert group; (b) The second round inspection by the expert group.
In order to prove the validity of our proposed dataset, four classical semantic segmentation models: DeepLabv3+19, FCN20, PSPNet21, and SegFormer22 were applied to evaluate the four semantic segmentation metric of aAcc, mIoU, mAcc and mDice, respectively. The definition of these metrics can be formulated as:
where TP, TN, FP, FN stand for the true positive, true negative, false negative, and false negative, respectively. N stands for the total number of classes. ωc stands for the total number of pixels in the class c. It it worth noting that both aAcc and mAcc show the average pixels classification performance of the model. However, the former does not take into account the difference in the number of pixels in different classes, while the latter uses the number of pixels in different classes to perform a weighted calculation. Moreover, both mIoU and mDice measure the average overlap between the model’s prediction results and the real labels in each category, which can well reflect the classification accuracy of the model at the pixel level. The difference is that mDice is less sensitive to noise and boundaries because it focuses more on the overall overlap; mIoU, on the other hand, is more sensitive to the boundary region, because the calculation of the union includes the region of the prediction error.
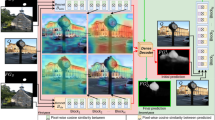
For the evaluation performance of the baseline models, It can be seen from the Table 3 and Fig. 8 that the performance of each baseline model is different for various metrics. It is worth noting that all the baseline models were not fine-tuned in our dataset, but were directly evaluated using the model weights pre-trained on other datasets to obtain the metric performance. For aAcc, the performance of each model exceeds 94%, showing strong foreground-background pixel classification ability. However, for mIoU and mDice, the evaluation performance of each model is significantly reduced, indicating that our dataset face challenges in dealing with complex, diverse, and culturally specific foreground item segmentation. These challenges can stem from items blocking each other, small size, high visual similarity, and a lack of clear boundaries, especially when the item does not have a high contrast to the background.

Semantic segmentation evaluation performance for four popular baseline models. The original images and corresponding ground truth are also given. Quantitative results show that the SegFormer performs the best.
In terms of advantages, our dataset provides detailed labeling of traditional Chinese martial arts props, which poses new challenges for developing refined high-precision small-target semantic segmentation models. In addition, our dataset shows a high degree of cultural relevance, which creates a basis for the development of future style-specific generation models and models that require the recognition of specific cultural objects.
Usage Notes
Our open data complies with the license statement under CC BY 4.0, and the datasets16 should refer to this article when using or referencing research objects. The license allows readers to distribute, remix, tweak and build works, but not to use the dataset for commercial purposes. Researchers using this dataset are required to provide a link to this License Agreement and indicate whether modifications have been made to the original work. We hope that ChinesePMD dataset will be available to more researchers and encourage more authors to publish their optimized codes and models, which will contribute to the development of semantic segmentation research in the film and television industry.
Code availability
Our datasets16 is public available in Science DB (http://www.scidb.cn/en), input link (https://www.scidb.cn/anonymous/SlpaelFy) or https://doi.org/10.57760/sciencedb.07008. The JSON file is in the label folder under the lens dataset. In the label folder, you can also see some visual annotation content after segmentation. If you want to use it, you can directly call the JSON file named “annotations.json” in each dataset. The code for technical validation is public code, the dataset is accessible via the DOI of science DB, and the software EISeg for annotation is open source.
References
Siriborvornratanakul, T. Downstream semantic segmentation model for low-level surface crack detection. Advances in Multimedia 2022, 3712289 (2022).
Nilsson, D. Data-efficient learning of semantic segmentation. Lund University (2022).
Bressan, P. O. et al. Semantic segmentation with labeling uncertainty and class imbalance applied to vegetation mapping. International Journal of Applied Earth Observation and Geoinformation 108, 102690 (2022).
Kittipongdaja, P. & Siriborvornratanakul, T. Automatic kidney segmentation using 2.5 d resunet and 2.5 d denseunet for malignant potential analysis in complex renal cyst based on ct images. EURASIP Journal on Image and Video Processing 2022, 5 (2022).
Monasterio-Exposito, L., Pizarro, D. & Macias-Guarasa, J. Label augmentation to improve generalization of deep learning semantic segmentation of laparoscopic images. IEEE Access 10, 37345–37359 (2022).
Abdigapporov, S., Miraliev, S., Kakani, V. & Kim, H. Joint multiclass object detection and semantic segmentation for autonomous driving. IEEE Access 11, 37637–37649 (2023).
Dataset, C. Semantic understanding of urban street scenes. Germany: City Shapes (2016).
Everingham, M., Gool, L. V., Williams, C. K. I., Winn, J. M. & Zisserman, A. The pascal visual object classes (VOC) challenge. Int. J. Comput. Vis. 88, 303–338, https://doi.org/10.1007/s11263-009-0275-4 (2010).
Lin, T. et al. Microsoft COCO: common objects in context. In Fleet, D. J., Pajdla, T., Schiele, B. & Tuytelaars, T. (eds.) Computer Vision - ECCV 2014 - 13th European Conference, Zurich, Switzerland, September 6-12, 2014, Proceedings, Part V, vol. 8693 of Lecture Notes in Computer Science, 740–755, https://doi.org/10.1007/978-3-319-10602-1_48 (Springer, 2014).
Caba Heilbron, F., Escorcia, V., Ghanem, B. & Carlos Niebles, J. Activitynet: A large-scale video benchmark for human activity understanding. In Proceedings of the ieee conference on computer vision and pattern recognition, 961–970 (2015).
Tapaswi, M. et al. Movieqa: Understanding stories in movies through question-answering. In Proceedings of the IEEE conference on computer vision and pattern recognition, 4631–4640 (2016).
Huang, Q., Xiong, Y., Rao, A., Wang, J. & Lin, D. Movienet: A holistic dataset for movie understanding. In Computer Vision–ECCV 2020: 16th European Conference, Glasgow, UK, August 23–28, 2020, Proceedings, Part IV 16, 709–727 (Springer, 2020).
Pont-Tuset, J. et al. The 2017 davis challenge on video object segmentation. arXiv preprint arXiv:1704.00675 (2017).
Wei, D. et al. Youmvos: an actor-centric multi-shot video object segmentation dataset. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 21044–21053 (2022).
Ding, H. et al. Mose: A new dataset for video object segmentation in complex scenes. In Proceedings of the IEEE/CVF International Conference on Computer Vision, 20224–20234 (2023).
Wang, Y. et al. Semantic segmentation dataset of Chinese martial arts classic movie props. ScienceDB https://doi.org/10.57760/sciencedb.07008 (2023).
Liu, Y. et al. Paddleseg: A high-efficient development toolkit for image segmentation 2101.06175 (2021).
Benenson, R., Popov, S. & Ferrari, V. Large-scale interactive object segmentation with human annotators. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, 11700–11709 (2019).
Chen, L., Zhu, Y., Papandreou, G., Schroff, F. & Adam, H. Encoder-decoder with atrous separable convolution for semantic image segmentation. In Ferrari, V., Hebert, M., Sminchisescu, C. & Weiss, Y. (eds.) Computer Vision - ECCV 2018 - 15th European Conference, Munich, Germany, September 8-14, 2018, Proceedings, Part VII, vol. 11211 of Lecture Notes in Computer Science, 833–851 https://doi.org/10.1007/978-3-030-01234-2_49 (Springer, 2018).
Long, J., Shelhamer, E. & Darrell, T. Fully convolutional networks for semantic segmentation. In IEEE Conference on Computer Vision and Pattern Recognition, CVPR 2015, Boston, MA, USA, June 7-12, 2015, 3431–3440 https://doi.org/10.1109/CVPR.2015.7298965 (IEEE Computer Society, 2015).
Zhao, H., Shi, J., Qi, X., Wang, X. & Jia, J. Pyramid scene parsing network. In 2017 IEEE Conference on Computer Vision and Pattern Recognition, CVPR 2017, Honolulu, HI, USA, July 21-26, 2017, 6230–6239, https://doi.org/10.1109/CVPR.2017.660 (IEEE Computer Society, 2017).
Xie, E. et al. Segformer: Simple and efficient design for semantic segmentation with transformers. In Ranzato, M., Beygelzimer, A., Dauphin, Y. N., Liang, P. & Vaughan, J. W. (eds.) Advances in Neural Information Processing Systems 34: Annual Conference on Neural Information Processing Systems 2021, NeurIPS 2021, December 6-14, 2021, virtual, 12077–12090, https://proceedings.neurips.cc/paper/2021/hash/64f1f27bf1b4ec22924fd0acb550c235-Abstract.html (2021).
Acknowledgements
This research is supported in part by the Zhejiang Provincial Natural Science Foundation of China (No.LTGG24F030002); the National Natural Science Foundation of China (No. 62206242); the Public Welfare Technology Application Research Project of Zhejiang Province, China (No. LGF21F010001).
Author information
Authors and Affiliations
Contributions
Suiyu Zhang is responsible for collecting film and television data, organizing related materials, dataset buliding, and funding acquisition. Rong Wang is responsible for original draft writing and graphic drawing. Yaqi Wang was responsible for funding acquisition, supervision, and data curation. Xiaoyu Ma was responsible for the technical verification of the dataset. Chengyu Wu is responsible for manuscript revision and data visualization, Hongyuan Zhang is responsible for manuscript revision and language rewriting. Zhi Li is responsible for content grammar checking. Dingguo Yu is responsible for supervision, project administration and funding acquisition.
Corresponding authors
Ethics declarations
Competing interests
The authors declare no competing interests.
Additional information
Publisher’s note Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution-NonCommercial-NoDerivatives 4.0 International License, which permits any non-commercial use, sharing, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if you modified the licensed material. You do not have permission under this licence to share adapted material derived from this article or parts of it. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by-nc-nd/4.0/.
About this article

Cite this article
Zhang, S., Wang, R., Wang, Y. et al. ChineseMPD: A Semantic Segmentation Dataset of Chinese Martial Arts Classic Movie Props. Sci Data 11, 882 (2024). https://doi.org/10.1038/s41597-024-03701-6
Received:
Accepted:
Published:
DOI: https://doi.org/10.1038/s41597-024-03701-6
