
Abstract
Hot Jupiters are among the best-studied exoplanets, but it is still poorly understood how their chemical composition and cloud properties vary with longitude. Theoretical models predict that clouds may condense on the nightside and that molecular abundances can be driven out of equilibrium by zonal winds. Here we report a phase-resolved emission spectrum of the hot Jupiter WASP-43b measured from 5 μm to 12 μm with the JWST’s Mid-Infrared Instrument. The spectra reveal a large day–night temperature contrast (with average brightness temperatures of 1,524 ± 35 K and 863 ± 23 K, respectively) and evidence for water absorption at all orbital phases. Comparisons with three-dimensional atmospheric models show that both the phase-curve shape and emission spectra strongly suggest the presence of nightside clouds that become optically thick to thermal emission at pressures greater than ~100 mbar. The dayside is consistent with a cloudless atmosphere above the mid-infrared photosphere. Contrary to expectations from equilibrium chemistry but consistent with disequilibrium kinetics models, methane is not detected on the nightside (2σ upper limit of 1–6 ppm, depending on model assumptions). Our results provide strong evidence that the atmosphere of WASP-43b is shaped by disequilibrium processes and provide new insights into the properties of the planet’s nightside clouds. However, the remaining discrepancies between our observations and our predictive atmospheric models emphasize the importance of further exploring the effects of clouds and disequilibrium chemistry in numerical models.
Similar content being viewed by others

Main
Hot Jupiters are tidally synchronized to their host stars, with vast differences in irradiation between the dayside and nightside. Previous observations with the Hubble Space Telescope (HST) and the Spitzer Space Telescope show that these planets have cooler nightsides and weaker hotspot offsets than expected from cloud-free three-dimensional models1,2,3,4,5. The main mechanism believed to be responsible for this behaviour is the presence of nightside clouds, which would hide the thermal flux of the planet and lead to a sharp longitudinal gradient in brightness temperature3,4,6,7,8,9,10. Other mechanisms have been proposed, such as the presence of atmospheric drag due to hydrodynamic instabilities or magnetic coupling11,12,13, super-stellar atmospheric metallicity14,15, or interaction between the deep winds and the photosphere16, but these mechanisms are less universal than the cloud hypothesis17,18.
WASP-43b, a hot Jupiter with an orbital period of just 19.5 h (ref. 19), is an ideal target for thermal phase-curve observations. Its host star is a K7 main-sequence star 87 pc away with metallicity close to solar and weak variability20. Previous measurements of the planet’s orbital phase curve in the near-infrared have revealed a large temperature contrast between the dayside and nightside hemispheres, broadly consistent with the presence of nightside clouds3,21,22, which could be composed of magnesium silicates (Mg2SiO4/MgSiO2) and other minerals (for example, MnS, Na2S, metal oxides)23,24. Owing to the low nightside flux, the exact temperature and cloud properties were challenging to determine from previous observations4,25,26. With the mid-infrared capabilities of the JWST, we have the opportunity to measure the phase-resolved thermal spectrum with unprecedented sensitivity, particularly on the cold nightside. We observed a full orbit of WASP-43b in the 5–12 μm range with the JWST’s Mid-Infrared Instrument (MIRI)27 in low-resolution spectroscopy (LRS)28 slitless mode on 1 and 2 December 2022, as part of the Transiting Exoplanet Community Early Release Science Program (JWST-ERS-1366). This continuous observation lasted 26.5 h at a cadence of 10.34 s (9,216 integrations) and included a full phase curve with one transit and two eclipses.
Results
We performed multiple independent reductions and fits to these observations (see ‘Data reduction pipelines’ and ‘Light-curve fitting’ in Methods) to ensure robust conclusions. Our analyses all identified a strong systematic noise feature from 10.6 μm to 11.8 μm, the source of which is still unclear, and we were unable to adequately detrend these 10.6–11.8 μm data (see ‘Shadowed region effect’ in Methods). As shown in Extended Data Fig. 1, we also found that larger wavelength bins were required to accurately estimate our final spectral uncertainties (see ‘Spectral binning’ in Methods). As a result, our final analyses consider only the 5–10.5 μm data, which we split into 11 channels with a constant 0.5 μm wavelength spacing. Similar to the MIRI commissioning time-series observations, our data show a strong downwards exponential ramp in the first ~60 min and a weaker ramp throughout the observation29 (Extended Data Fig. 2). To minimize correlations with the phase variations, we removed the initial strong ramp by excluding the first 779 integrations (134.2 min) and then fitted a single exponential ramp model to the remaining data. A single ramp effectively removed the systematic noise, with the broadband light curve showing scatter ~1.25× the expected photon noise, while the spectroscopic light curves reach as low as ~1.1× the photon limit, probably due to improved decorrelation of wavelength-dependent systematics. Figure 1 shows the spectral light curves, broadband light curve, dayside spectra and nightside spectra from our fiducial reduction and fit.

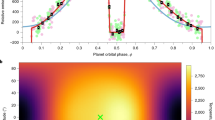
a, The observed spectroscopic light curves binned to a 0.5 μm wavelength resolution and after systematic noise removal, following the Eureka! v1 methods. The first 779 integrations have been removed from this figure and our fits as they were impacted by strongly decreasing flux. Wavelengths longer than 10.5 μm marked with a hatched region were affected by the ‘shadowed region effect’ (Methods) and could not be reliably reduced. b, The observed band-integrated light curve after systematic noise removal (grey points) and binned data with a cadence of 15 min (black points, with error bars smaller than the point sizes), compared with the best-fitting astrophysical model (red line). c,d, The measured dayside (c) and nightside (d) emission spectra are shown with black points and 1σ error bars, and black-body curves (dotted line denoted as ‘BB’, assuming a PHOENIX74,75,76 model for the star) are shown to emphasize planetary spectral features with black-body temperatures estimated by eye to match the continuum flux levels. Wavelengths longer than 10.5 μm were affected by the shadowed region effect and are unreliable.
From our Eureka! v1 analysis (Methods), we measure a broadband (5–10.5 μm) peak-to-trough phase variation of 4,180 ± 33 ppm with an eclipse depth of 5,752 ± 19 ppm and a nightside flux of 1,636 ± 37 ppm. Assuming a PHOENIX stellar model and marginalizing over the published stellar and system parameters30, the broadband dayside brightness temperature is 1,524 ± 35 K while the nightside is 863 ± 23 K. This corresponds to a day–night brightness temperature contrast of 659 ± 19 K, in agreement with the large contrasts previously observed4,21,22,25. The phase variations are well fitted by a sum of two sinusoids (the first and second harmonics), with two sinusoids preferred over a single sinusoid at 16σ (see ‘Determining the number of sinusoid harmonics’ in Methods) for the broadband light curve. The peak brightness of the broadband phase curve occurs at 7.34 ± 0.38° E from the substellar point (although individual reductions find offsets ranging from 7.34° E to 9.60° E), while previous studies have found offsets of 12.3 ± 1.0° E for HST Wide Field Camera 3’s (WFC3) 1.1–1.7 μm bandpass21, offsets ranging from 4.4° E to 12.2° E for Spitzer InfraRed Array Camera’s (IRAC) 3.6 μm filter22,25 and offsets ranging from 10.4° E to 21.1° E for Spitzer/IRAC’s 4.5 μm filter4,22,25,26,31,32. Overall, these broadband data represent roughly an order of magnitude in improved precision on the eclipse depth (6×), phase-curve amplitude (6×) and phase-curve offset (10×) over individual Spitzer/IRAC 4.5 μm observations of the system22,26,32; this improvement is largely driven by the JWST’s larger mirror (45×), about 12× less pointing jitter (per axis), about 4× improved stability in the width of the point spread function (PSF) along each axis and MIRI’s much broader bandpass.
Model interpretation
To interpret the measurements, we compared the observations with synthetic phase curves and emission spectra derived from general circulation models (GCMs). Simulations were gathered from five different modelling groups, amounting to 31 separate GCM realizations exploring a range of approaches and assumptions. Notably, in addition to cloud-free simulations, the majority of the GCMs modelled clouds with spatial distributions that were either fully predicted5,26,33 or simply limited to the planet’s nightside4. For the predictive cloud models, simulations favoured warmer, clearer daysides with cooler, cloudier nightsides, but the precise distributions varied with assumptions regarding cloud physics and compositions. In general, models with smaller cloud particles or extended vertical distributions tended to produce thicker clouds at the pressures sensed by the observations. Details of the different models are provided in Methods.
Despite fundamental differences in the models and the parameterizations they employ, simulated phase curves derived from models that include cloud opacity on the planet’s nightside provide a better match to the observed nightside flux compared with the clear simulations (Fig. 2). In contrast, the observed dayside fluxes (180° orbital phase) were matched similarly well by models with and without clouds. This implies the presence of widespread clouds preferentially on the planet’s nightside with cloud optical thicknesses sufficient to suppress thermal emission and cool the thermal photosphere. Specifically, models with integrated mid-infrared cloud opacities of roughly 2–4 above the 300 mbar level (that is, blocking ~87–98% of the underlying emission), best match the observed nightside flux.

The black points show the temporally binned broadband light curve. The solid lines represent modelled phase curves derived from the 31 GCM simulations, integrated over the same wavelength range as the data, and separated into two groups based on the inclusion of clouds. The cloudless GCMs (red lines) simulated completely cloud-free skies, whereas the cloudy GCMs (blue lines) included at least some clouds on the nightside of the planet. The red and blue shaded areas span the range of all the cloudless and cloudy simulations, respectively, with the spread of values owing to differences in the various model assumptions and parameterizations. On average, the cloudless GCM phase curves have a maximum planet-to-star flux ratio of 5,703 ppm and a minimum of 2,681 ppm. This matches the observed maximum of the phase curve well but does not match its observed minimum at 1,636 ± 37 ppm. On average, the cloudy GCM phase curves have a maximum of 5,866 ppm and a minimum of 1,201 ppm, in better agreement with the observed nightside emission, but their spread of maximum values is much larger than the cloudless simulations. The cloudy models are able to suppress the nightside emission and better match the data; however, not all cloud models fit equally well and those with the optically thickest nightside clouds suppress too much emission. The models do not include the eclipse signals (phases −0.5 and 0.5) or transit signal (phase 0.0).
Including nightside clouds also improved the agreement with the measured hotspot offset (7.34± 0.38° E). While cloudless models all produced eastward offsets greater than 16.6° (25.5° on average), simulations with clouds had offsets as low as 7.6° (with a mean of 16.4°). These reduced offsets were associated with decreases in the eastwards jet speeds of up to several kilometres per second, with maximum winds of roughly 2.0–2.5 km s−1 providing the best match (see Extended Data Table 1 for further details). This modelled jet-speed reduction is probably due to a disruption in the equatorwards momentum transport34 brought about by nightside clouds4,35,36. However, the resulting range of offsets seen in the suite of models suggests that this mechanism is quite sensitive to the details of cloud models, and other modelling factors (for example, atmospheric drag11,12,16, radiative timescales14,15,37) probably still play an important role.
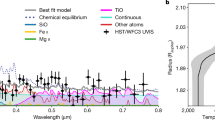
A comparison of the observed and modelled emission spectra further suggests that the majority of the cloud thermal opacity must be confined to pressures greater than ~10–100 mbar, because the presence of substantial cloud opacity at lower pressures dampens the modelled spectral signature amplitude below what is observed (Fig. 3). No distinct spectral signatures indicative of the cloud composition were evident in the observations. While no single GCM can match the emission spectra at all phases, spectra corresponding to nightside, morning and evening terminators appear qualitatively similar to GCM results that are intermediate between clear and cloudy simulations. In contrast, the absorption features indicative of water vapour (between ~5 μm and 8.5 μm) seen in the dayside emission spectrum are more consistent with an absence of cloud opacity at these mid-infrared wavelengths. Altogether, these findings represent new constraints on the spatial distribution and opacity of WASP-43b’s clouds.

a–c, The observed emission spectrum with 1σ error bars at phases 0.0 (a), 0.25 (b), 0.5 (c) and 0.75 (d), along with select modelled spectra derived from different cloudy and cloudless GCMs (described in Methods and listed in Extended Data Table 1). Although absolute brightness temperatures differ appreciably between models owing to various GCM assumptions, differences in the relative shape of the spectra are strongly dependent on the cloud and temperature structure found in the GCMs (Extended Data Fig. 7). Models with more isothermal profiles (like RM-GCM) or thick clouds at pressures of ≲10–100 mbar (like THOR cloudy, Generic PCM with 0.1 μm cloud particles) produce flatter spectra, while clearer skies yield stronger absorption features. The observed spectra from the nightside and terminators appear muted compared with the clear-model spectra, suggesting the presence of at least some clouds or weak vertical temperature gradients at pressures of ≲10–100 mbar. In contrast, the spectral structure produced by water vapour opacity (indicated by the purple shading) appears more consistent with models lacking clouds at these low pressures on the dayside. Under equilibrium chemistry, methane would also show an absorption feature at ~7.5–8.5 μm (shaded pink) for the colder models at phases 0.0 and 0.75. Finally, the median retrieved spectrum and 1σ contours from the HyDRA retrieval are shown in grey.
We further characterized the chemical composition of WASP-43b’s atmosphere by applying a suite of atmospheric retrieval frameworks to the phase-resolved emission spectra. The retrievals spanned a broad range of model assumptions, including free chemical abundances versus equilibrium chemistry, different temperature profile parameterizations and different cloud models (see ‘Atmospheric retrieval models’ in Methods). Despite these differences, the retrievals yielded consistent results for both the chemical and thermal constraints. We detected water vapour across the dayside, nightside, morning and evening hemispheres, with detection significances of up to ~3–4σ (Extended Data Fig. 3 and Extended Data Tables 2 and 3). The retrieved abundances of H2O largely lie in the 10–105 ppm range for all four phases and for all the retrieval frameworks (Fig. 4 and Extended Data Fig. 4), broadly consistent with the value expected for a solar composition (500 ppm) as well as previous observations22.

a, Temperature profile contours (68% confidence) constrained by the retrievals at each orbital phase (see legends). All frameworks produced consistent non-inverted thermal profiles that are consistent with two-dimensional radiative–convective equilibrium and photochemical models along the equator23 (black curves) over the range of pressures probed by the observations (black bars). b, H2O abundance posterior distributions (volume mixing ratios). The shaded areas denote the span of the 68% confidence intervals. The green and blue bars on each panel denote the abundances predicted by equilibrium and disequilibrium chemistry solar-abundance models23, respectively, at the pressures probed by the observations (1–10−3 bar, approximately). c, The same as in b but for CH4. The retrieved water abundances are consistent with either equilibrium or disequilibrium chemistry estimations for solar composition (500 ppm), whereas the retrieved upper limits to the CH4 abundance are more consistent with disequilibrium chemistry predictions.
We also searched for signatures of disequilibrium chemistry in the atmosphere of WASP-43b. While CH4 is expected to be present on the nightside under thermochemical equilibrium conditions, we did not detect CH4 at any phase (Fig. 4). In the pressure range probed by the nightside spectrum (1–10−3 bar; Extended Data Fig. 5), the equilibrium abundance of CH4 is expected to vary between ~1 ppm and 100 ppm for a solar C/O ratio23, compared with our 95% upper limits of 1–6 ppm (Extended Data Table 2). The upper limits we place on the nightside CH4 abundance are more consistent with disequilibrium models that account for vertical and horizontal transport23,24,38. In particular, two-dimensional photochemical models and GCMs predict the strongest depletion of CH4 on the nightside due to strong zonal winds (>1 km s−1) transporting gas-phase constituents around the planet faster than the chemical reactions can maintain thermochemical equilibrium, thus ‘quenching’ and homogenizing the global composition at values more representative of dayside conditions (see also refs. 39,40,41,42). We note, however, that a low atmospheric C/O ratio and/or clouds at photospheric pressures could also lead to a non-detection of CH4. We also searched for signatures of NH3, which is predicted to have a volume mixing ratio less than 0.1–1 ppm in both equilibrium and disequilibrium chemistry models, and find that the results are inconclusive and model-dependent with the current retrieval frameworks.
Given the strong evidence for clouds from comparison with GCMs, we also searched for signatures of clouds in the atmospheric retrieval. Formally, the retrievals do not detect clouds with statistical significance, indicating that strong spectral features uniquely attributable to condensates are not visible in the data (see ‘Atmospheric retrieval models’ in Methods and Extended Data Fig. 6). However, the retrievals may mimic the effects of cloud opacity with a more isothermal temperature profile, as both tend to decrease the amplitude of spectral features, but the cloud-free, more isothermal temperature profile requires fewer free parameters and is therefore statistically favoured. Indeed, while the retrieved temperature profiles on the dayside and evening hemispheres agree well with the hemispherically averaged temperature profiles from the GCMs, they are more isothermal than the GCM predictions for the nightside and morning hemispheres (Extended Data Fig. 7). This discrepancy may hint at the presence of clouds on the nightside and morning hemispheres, consistent with the locations of clouds found in the GCMs.
Taken together, our results highlight the unique capabilities of JWST/MIRI for exoplanet atmosphere characterization. Combined with a range of atmospheric models, the observed phase curve and emission spectra provide strong evidence that the atmospheric chemistry of WASP-43b is shaped by complex disequilibrium processes and provide new constraints on the optical thickness and pressure of nightside clouds. However, while cloudy GCM predictions match the data better than cloud-free models, none of the simulations simultaneously reproduced the observed phase curve and spectra within measured uncertainties. These remaining discrepancies underscore the importance of further exploring the effects of clouds and disequilibrium chemistry in numerical models, as JWST continues to place unprecedented observational constraints on smaller and cooler planets.
Methods
Observations and quality of the data
We observed a full orbit of WASP-43b with the JWST MIRI LRS slitless mode as a part of JWST-ERS-1366. We performed target acquisition with the F1500W filter and used the SLITLESSPRISM subarray for the science observation. The science observation was taken between 1 December 2022 at 00:54:30 UT and 2 December 2022 at 03:23:36 UT, for a total of 26.5 h. We acquired 9,216 integrations, which were split into 3 exposures and 10 segments per exposure. Each integration lasts 10.34 s and is composed of 64 groups, with 1 frame per group. The LRS slitless mode reads an array of 416 × 72 pixels on the detector (the SLITLESSPRISM subarray) and uses the FASTR1 readout mode, which introduces an additional reset between integrations.
Owing to the long duration of the observation, two high-gain antenna moves occurred 8.828 h and 17.661 h after the start of the science observation. They affect only a couple of integrations that we removed from the light curves. A cross-shaped artefact is present on the two-dimensional images at the short-wavelength end due to light scattered by detector pixels43. It is stable over the duration of the observation but it contaminates the background and the spectral trace up to ~6 μm. This ‘cruciform’ artefact is observed in all MIRI LRS observations; a dedicated analysis is underway to estimate and mitigate its impact.
In the broadband light curve, the flux decays by ~0.1% during the first 60 min and continues to decay throughout the observation. This ramp is well modelled with 1 or 2 exponential functions after trimming the initial ~780 integrations. Without trimming any data, at least two ramps are needed. In addition, a downwards linear trend in flux is observed over the whole observation with a slope of −39 ppm per hour. These two types of drift also appear in the spectroscopic light curves. The exponential ramp amplitude in the first 60 min changes with wavelength from −0.67% in the 5–5.5 μm bin (downwards ramp) to +0.26% in the 10–10.5 μm bin (upwards ramp). The ramp becomes upwards at wavelengths longer than 7.5 μm and its timescale increases to more than 1 h at wavelengths longer than 10.5 μm. The slopes as a function of wavelength vary from −16 ppm to −52 ppm, all downwards. Such drifts (initial ramp and linear or polynomial trend) are also observed in other MIRI LRS time-series observations29 but the strength of the trends differ for each observation. In these WASP-43b observations, we note that their characteristic parameters vary smoothly with wavelength, which may help identify their cause and build correction functions.
Over the course of the observation, the position of the spectral trace on the detector varies by 0.0036 pixels RMS (0.027 pixels peak to peak) in the spatial direction, and the Gaussian standard deviation of the spatial PSF varies by 0.00069 pixels RMS (root mean square; 0.0084 pixels peak to peak) following a sharp increase by 0.022 pixels during the first 600 integrations. Depending on the wavelength bin, that spatial drift causes noise at the level of 7–156 ppm, while variations in the PSF width cause noise at the level of 4–54 ppm (these numbers are obtained from a linear decorrelation). Overall, the MIRI instrument used in LRS slitless mode remains remarkably stable over this 26.5-h-long continuous observation and the data are of exquisite quality.
The noise in the light curve increases sharply at wavelengths beyond 10.5 μm and the transit depths obtained at these long wavelengths by different reduction pipelines are discrepant. These wavelengths were not used in the retrieval analyses and the final broadband light curve. The cause is unknown but it might be related to the fact that this region of the detector receives different illumination before the observation44 (see ‘Shadowed region effect’ below for more details).
Data reduction pipelines
Eureka! v1 reduction
The Eureka! v1 reduction made use of version 0.9 of the Eureka! pipeline45, CRDS version 11.16.16 and context 1018, and jwst package version 1.8.346. The gain value of 5.5 electrons per data number obtained from these CRDS reference files is known to be incorrect, and the actual gain is estimated to be ~3.1 electrons per data number although the gain may be wavelength dependent (S. Kendrew, private communication). A new reference file reflecting the updated gain is under development at STScI, which will improve the accuracy of photon-noise calculations. For the rest of this analysis, we assume a constant gain of 3.1 electrons per data number. The Eureka! control files and Eureka! parameter files files used in these analyses are available for download (https://doi.org/10.5281/zenodo.10525170) and are summarized below.
Eureka! makes use of the jwst pipeline for stages 1 and 2, and both stages were run with their default settings, with the exception of increasing the stage 1 jump step’s rejection threshold to 8.0 and skipping the photom step in stage 2 because it is not necessary and can introduce additional noise for relative time-series observations. In stage 3 of Eureka!, we then rotated the MIRI/LRS slitless spectra 90° anticlockwise so that wavelength increases from left to right like the other JWST instruments to allow for easier reuse of Eureka! functions. We then extracted pixels 11–61 in the new y direction (the spatial direction) and 140–393 in the new x direction (spectral direction); pixels outside of these ranges primarily contain noise that is not useful for our reduction. Pixels marked as ‘DO_NOT_USE’ in the DQ array were then masked as were any other unflagged NaN or inf pixels. A centroid was then fit to each integration by summing along the spectral direction and fitting the resulting one-dimensional profile with a Gaussian function; the centroid from the first integration was used for determining aperture locations, while the centroids and PSF widths from all integrations were saved to be used as covariates when fitting the observations.
Our background subtraction method is tailored to mitigate several systematic effects unique to the MIRI instrument. First, MIRI/LRS observations exhibit a ‘cruciform artefact’43 at short wavelengths caused by scattered light within the optics; this causes bright rays of scattered light which must be sigma-clipped to avoid over-subtracting the background. In addition, MIRI/LRS observations show periodic noise in the background flux, which drifts with time29 as well as 1/f noise47, which leads to correlated noise in the cross-dispersion direction; as a result, background subtraction must be performed independently for each integration and column (row in MIRI’s rotated reference frame). Furthermore, in both these observations and the dedicated background calibration observations from JWST-COM/MIRI-1053, we found that there was a linear trend in the background flux, with the background flux increasing with increasing row index (column index in MIRI’s rotated reference frame). To robustly remove this feature, we found that it was important to either (1) use the mean from an equal number of pixels on either side of the spectral trace for each column and integration, or (2) use a linear background model for each column and integration; we adopted the former as it resulted in less noisy light curves. To summarize, for each column in each integration we subtracted the mean of the pixels separated by ≥11 pixels from the centre of the spectral trace after first masking 5σ outliers in that column.
To compute the spatial profile for the optimal extraction of the source flux, we calculated a median frame, sigma-clipping 5σ outliers along the time axis and smoothing along the spectral direction using a 7-pixel-wide boxcar filter. During optimal extraction, we only used the pixels within 5 pixels of the fitted centroid and masked pixels that were 10σ discrepant with the spatial profile. Background exclusion regions ranging from 9 to 13 pixels and source aperture regions ranging from 4 to 6 pixels were considered, but our values of 11 and 5 pixels were selected as they produced the lowest median absolute deviation light curves before fitting.
Eureka! v2 reduction
The Eureka! v2 reduction followed the same procedure as the Eureka! v1 reduction except for the following differences. First, this reduction made use of version 1.8.1 of the jwst pipeline. For stage 1, we instead used a cosmic ray detection threshold of 5 and used a uniform ramp fitting weighting. For stage 2, we performed background subtraction using columns away from the trace on the left and on the right and subtracted the background for each integration29. Stage 3 was identical to Eureka! v1 reduction.
TEATRO reduction
We processed the data using the Transiting Exoplanet Atmosphere Tool for Reduction of Observations (TEATRO) that runs the jwst package, extracts and cleans the stellar spectra and light curves, and runs light-curve fits. We used the jwst package version 1.8.4, CRDS version 11.16.14 and context 1019. We started from the ‘uncal’ files and ran stages 1 and 2 of the pipeline. For stage 1, we set a jump rejection threshold of 6, turned off the ‘jump.flag_4_neighbors’ parameter and used the default values for all other parameters. For stage 2, we ran only the ‘AssignWcsStep’, ‘FlatFieldStep’ and ‘SourceTypeStep’; no photometric calibration was applied. The next steps were made using our own routines. We computed the background using two rectangular regions, one on each side of the spectral trace, between pixels 13 and 27 and between pixels 53 and 72 in the spatial direction, respectively. We computed the background value for each row (rows are along the spatial direction) in each region using a biweight location, averaged the two values and subtracted it from the full row. This background subtraction was done for each integration. Then, we extracted the stellar flux using aperture photometry by averaging pixels between 33 and 42 in each row to obtain the stellar spectrum at each integration. We also averaged pixels between 33 and 42 in the spatial direction and between 5 μm and 10.5 μm in the spectral direction to obtain the broadband flux. We averaged the spectra in 11 0.5-μm-wide wavelength channels. For each channel and for the broadband light curve, we normalized the light curve using the second eclipse as a reference flux, computed a running median filter using a 100-point window size, and rejected points that were more than 3σ away from that median using a 5-iteration sigma-clipping. To limit the impact of the initial ramp on the fitting, we trim the first 779 integrations from the broadband light curve and a similar number of integrations for each channel (the exact number depends on the channel). Finally, we subtracted 1 from the normalized light curves to have the secondary eclipse flux centred on 0. These cleaned light curves were used for phase curve, eclipse and transit fits.
SPARTA reduction
We reduced the data with the open-source Simple Planetary Atmosphere Reduction Tool for Anyone (SPARTA), first introduced in ref. 48 to analyse the MIRI LRS phase curve of GJ 1214b. We started from the uncalibrated data and proceeded all the way to the final results without using any code from the jwst or Eureka! pipelines. In stage 1, we started by discarding the first five groups as well as the last group, because these groups show anomalies due to the reset switch charge decay and the last-frame effect. We fitted a slope to the up-the-ramp reads in every pixel of every integration in every exposure. We calculated the residuals of these linear fits, and for every pixel, we computed a median residual for every group across all integrations. This ‘median residual’ array has dimensions Ngrp × Nrows × Ncols. This array was subtracted from the original uncalibrated data and the up-the-ramp fit was redone, this time without discarding any groups except those that were more than 5σ away from the best-fit line. Such outliers, which may be due to cosmic rays, were discarded and the fit recomputed until convergence. This procedure straightens out any nonlinearity in the up-the-ramp reads that is consistent across integrations, such as the reset switch charge decay, the last-frame effect or inaccuracies in the nonlinearity coefficients. After up-the-ramp fitting, we removed the background by removing the mean of columns 10–24 and 47–61 (inclusive, zero-indexed) for every row of every integration. As these two regions are of equal size and equally distant from the trace, any linear spatial trend in the background is naturally removed.
In the next step, we computed a pixel-wise median image over all integrations. This median image was used as a template to determine the position of the trace in each integration, by shifting and scaling the template until it matched the integration (and minimizes the χ2). It was also used as the point spread profile for optimal extraction, after shifting in the spatial direction by the amount calculated in the previous step. Outliers more than 5σ discrepant from the model image (which may be cosmic rays) were masked, and the optimal extraction was repeated until convergence. The z-scores image (image minus model image all divided by expected error, including photon noise and read noise) have a typical standard deviation of 0.88, compared with a theoretical minimum value of 1, indicating that the errors are being overestimated.
After optimal extraction, we gathered all the spectra and positions into one file. To reject outliers, we created a broadband light curve, detrended it by subtracting a median filter with a width 100 times less than the total data length and rejected integrations greater than 4σ away from 0 (which may be cosmic rays). Sometimes only certain wavelengths of an integration are bad, not the entire integration. We repaired these by detrending the light curve at each wavelength, identifying 4σ outliers and replacing them with the average of their two immediate temporal neighbours.
Spectral binning
To investigate the effects of spectral binning, we utilized the MIRI time-series commissioning observations of the transit of L168-9b (JWST-COM/MIRI-1033; ref. 29). L168-9b was chosen to have a clear transit signal while also having no detectable atmospheric signatures expected in its mid-infrared transmission spectrum; as a result, the observed scatter in the transmission spectrum can be used as an independent measurement of the uncertainties in the transit depths. The same procedure cannot be done on our WASP-43b science observations as there may be detectable atmospheric signatures.
Following the Eureka! reduction methods described by ref. 29, we tried binning the L168-9b spectroscopic light curves at different resolutions and compared the observed standard deviation of the transmission spectrum with the median of the transit depth uncertainties estimated from fitting the spectral light curves. As shown in Extended Data Fig. 1, the uncertainties in the pixel-level light curves underestimate the scatter in the transmission spectrum by a factor of about two. Because pairs of rows (in MIRI’s rotated reference frame) are reset together, it is reasonable to assume that there could be odd–even effects that would average out if combining pairs of rows; indeed, there do appear to be differences in the amplitude of the initial exponential ramp feature between odd and even rows. However, combining pairs of rows still leads to appreciable underestimation of the scatter in the transmission spectrum. Interestingly, the underestimation of the uncertainties appears to decrease with decreasing wavelength resolution. This is likely explained by wavelength-correlated noise that gets averaged out with coarse binning. A likely culprit for this wavelength-correlated noise may be the 390 Hz periodic noise observed in several MIRI subarrays, which causes clearly structured noise with a period of ~9 rows29 (M. Ressler, private communication); this noise source is believed to be caused by MIRI’s electronics and possible mitigation strategies are still under investigation. Until the source of the excess wavelength-correlated noise is definitively determined and a noise mitigation method is developed, we recommend that MIRI/LRS observations should be binned to a fairly coarse spectral resolution as this gives better estimates of the uncertainties and also gives spectra that are closer to the photon-limited noise regime. However, we caution against quantitative extrapolations of the uncertainty underestimation to other datasets; because we do not know the source of the excess noise, we do not know how it might change with different parameters such as groups per integration or stellar magnitude.
Ultimately, for each reduction method, we binned the spectra down to a constant 0.50-μm-wavelength grid spanning 5–12 μm, giving a total of 14 spectral channels. However, as is described below, we only end up using the 11 spectral channels spanning 5–10.5 μm for science. This 0.5-μm-binning scheme combines 7 wavelengths for the shortest bin and 25 wavelengths for the longest bin, which has the added benefit of binning down the noise at longer wavelengths where there are fewer photons. However, even for this coarse of a binning scheme, we do expect there to be some additional noise beyond our estimated uncertainties on the spectrum of WASP-43b (Extended Data Fig. 1). As the structure of this noise source is not well understood nor is the extent to which our error bars are underestimated, our best course of action was to consider error inflation when performing spectroscopic inferences (described in more detail below).
Light-curve fitting
Detrending the initial exponential ramp
As with other MIRI/LRS observations29, our spectroscopic light curves showed a strong exponential ramp at the start of the observations. As shown in Extended Data Fig. 2, the strength and sign of the ramp varies with wavelength, changing from a strong downwards ramp at 5 μm to a nearly flat trend around 8 μm, and then becoming an upwards ramp towards longer wavelengths. From 10.6 μm to 11.8 μm, the ramp timescale became much longer and the amplitude of the ramp became much stronger; this region of the detector was previously discussed44 and is discussed in more detail below. In general, most of the ramp’s strength had decayed within ~30–60 min, but at the precision of our data, the residual ramp signature still had an important impact on our nightside flux measurements due to the similarity of the ramp timescale with the orbital period. Unlike in the case of the MIRI/LRS commissioning observations of L168-9b29, we were not able to safely fit the entire dataset with a small number of exponential ramps. When fitting the entire dataset, we found that non-trivial choices about the priors for the ramp amplitudes and timescales resulted in significantly different spectra at phases 0.75 (morning hemisphere) and especially 0.0 (nightside); because the dayside spectrum is measured again near the end of the observations, it was less affected by this systematic noise.
Ultimately, we decided to conservatively discard the first 779 integrations (134.2 min), leaving only one transit duration of baseline before the first eclipse ingress began. After removing the initial 779 integrations, we found that a single exponential ramp model with broad priors that varied freely with wavelength was adequate to remove the signature. In particular, after removing the first 779 integrations we found that our dayside and nightside emission spectra were not significantly affected by (1) fitting two exponential ramps instead of one, (2) adjusting our priors on the ramp timescale to exclude rapidly decaying ramps with timescales >15 d−1 instead of >100 d−1, (3) putting a uniform prior on the inverse timescale instead of the timescale, or (4) altering the functional form of the ramp by fitting for an exponential to which the time was raised. After removing the first ~2 h, we also found that the ramp amplitude and timescale did not vary strongly with wavelength (excluding the ‘shadowed region’ described below), although fixing these parameters to those fitted to the broadband light curve affected several points in the nightside spectrum by more than 1σ; we ultimately decided to leave the timescale and amplitude to vary freely with wavelength as there is no a priori reason to assume that they should be equal. With careful crafting of priors, it appeared possible to get results similar to our final spectra while removing only the first few integrations, but trimming more integrations and only using a single exponential ramp model required fewer carefully tuned prior assumptions for which we have little physical motivation.
Shadowed region effect
As was described in ref. 44, we also identified a strong discontinuity in the spectroscopic light curves spanning pixel rows 156–220 (10.6–11.8 μm) in these observations. In this range, the temporal behaviour of the detector abruptly changes to a large-amplitude, long-timescale, upwards ramp that appears to slightly overshoot before decaying back down and approaching an equilibrium. These pixels coincide with a region of the detector between the Lyot coronagraph region and the four-quadrant phase mask region, which is unilluminated except when the dispersive element is in the optical path; as a result, we have taken to calling this unusual behaviour as the ‘shadowed region effect’. Strangely, not all MIRI/LRS observations show this behaviour, with the MIRI/LRS commissioning time-series observations29 and the GJ 1214b phase-curve observations48 showing no such effect. In fact, we know of only two other observations that show similar behaviour: the observation of the transit of WASP-80b (JWST-GTO-1177; T. Bell, private communication) and the observation of the phase curve of GJ 367b (JWST-GO-2508; M. Zhang, private communication). Informatively, the eclipse observation of WASP-80b taken 36 h after the WASP-80b transit using the same observing procedure (JWST-GTO-1177; T. Bell, private communication) did not show the same shadowed region effect, indicating that the effect is unlikely to be caused by stray light from nearby stars or any other factors that stayed the same between those two observations. Our best guess at this point is that the effect is related to the illumination history of the detector and the filter used by the previous MIRI observation (because the detector is illuminated at all times, even when it is not in use), but this is still under investigation and at present there is no way of predicting whether or not an observation will be impacted by the shadowed region effect. It is important to note, however, that from our limited knowledge at present that the shadowed region effect appears to be either present or not, with observations either strongly affected or seemingly completely unaffected.
Using the general methods described in the Eureka! v1 fit, we attempted to model the shadowed region effect with a combination of different ramp models, but nothing we tried was able to cleanly separate the effect from the phase variations, and there was always some clear structure left behind in the residuals of the fit. Another diagnostic that our detrending attempts were unsuccessful was that the phase offset as a function of wavelength smoothly varied around ~10° E in the unaffected region of the detector, but in the shadowed region, the phase offset would abruptly change to ~5° W; such a sharp change in a suspect region of the detector seems highly unlikely to be astrophysical in nature. As a result, we ultimately chose to exclude the three spectral bins spanning 10.5–12 μm from our retrieval efforts.
Determining the number of sinusoid harmonics
To determine the complexity of the phase-curve model required to fit the data, we used the Eureka! v1 reduction and most of the Eureka! v1 fitting methods described below, with the exception of using the dynesty49 nested sampling algorithm (which computes the Bayesian evidence, \({{{\mathcal{Z}}}}\)) and a batman transit and eclipse model. Within dynesty, we used 256 live points, ‘multi’ bounds, ‘rwalk’ sampling, and ran until the estimated \(d\ln ({{{\mathcal{Z}}}})\) reached 0.1. We then evaluated first-, second- and fourth-order models for the broadband light curve, excluding all third-order sinusoidal terms from the fourth-order model as these terms are not likely to be produced by the planet’s thermal radiation50,51. We then compared the Bayesian evidences of the different models following refs. 52,53 and found that the second-order model was significantly preferred over the first-order model at 16σ (\({{\Delta }}\ln ({{{\mathcal{Z}}}})=128\)), while the second-order model was insignificantly preferred over the fourth-order model at 2.2σ (\({{\Delta }}\ln ({{{\mathcal{Z}}}})=1.3\)). This is also confirmed by eye where the first-order model leaves clear phase-variation signatures in the residuals, while the residuals from the second-order model leave no noticeable phase variations behind. Finally, we also compared the phase-resolved spectra obtained from different order phase-curve models; we found that our spectra significantly changed going from a first- to second-order model (altering one or more spectral points by >1σ), but the fourth-order model did not significantly change the resulting phase-resolved spectra compared with the second-order. As a result, the final fits from all reductions used a second-order model. The broadband light curves obtained from the four reductions and the associated phase-curve models are shown in Supplementary Fig. 1.
Eureka! v1 fitting methods
We first sigma-clipped any data points that were 4σ discrepant from a smoothed version of the data (made using a boxcar filter with a width of 20 integrations) to remove any obviously errant data points while preserving the astrophysical signals like the transit.
Our astrophysical model consisted of a starry54 transit and eclipse model, as well as a second-order sinusoidal phase-variation model. The complete astrophysical model had the form
where t is the time, F* is the received stellar flux (and includes the starry transit model), Fday is the planetary flux at mid-eclipse, E(t) is the starry eclipse model (neglecting eclipse mapping signals for the purposes of this paper), and Ψ(ϕ) is the phase-variation model of the form
where ϕ is the orbital phase in radians with respect to eclipse, and AmpCos1, AmpSin1, AmpCos2 and AmpSin2 are all fitted coefficients. The second-order phase-variation terms allow for thermal variations across the face of the planet that are more gradual or steep than a simple first-order sinusoid would allow. We numerically computed dayside, morning, nightside and evening spectra using the above Ψ(ϕ) function at ϕ = 0, π/2, π and 3π/2, respectively. To allow the starry eclipse function to account for light travel time, we used a stellar radius (R*) of 0.667 R⊙ (ref. 55) to convert the fitted a/R* (the scaled semi-major axis) to physical units. For our transit model, we used a reparameterized version of the quadratic limb-darkening model56 with coefficients u1 and u2 uniformly constrained between 0 and 1, and used a minimally informative prior on the planet-to-star radius ratio (Rp/R*).
Our systematics model consisted of a single exponential ramp in time to account for the idle-recovery drift documented for MIRI/LRS time-series observations29, a linear trend in time, and a linear trend with the spatial position and PSF width. The full systematics model can be written as
The linear trend in time is modelled as
where tl is the time with respect to the mid-point of the observations and where c0 and c1 are coefficients. The exponential ramp is modelled as
where tr is the time with respect to the first integration and where r0 and r1 are coefficients. The linear trends as a function of spatial position, y, are PSF width sy are modelled as
and
where f and g are coefficients. The linear trends as a function of spatial position and PSF width are with respect to the mean-subtracted spatial position and PSF width. Finally, we also fitted a multiplier (scattermult) to the estimated Poisson noise level for each integration to allow us to account for any noise above the photon limit as well as an incorrect value for the gain applied in stage 3.
With an initial fit to the broadband light curve (5–10.5 μm), we assumed a zero eccentricity and placed a Gaussian prior on the planet’s orbital parameters (period, P; linear ephemeris, t0; inclination, i; and scaled semi-major axis, a/R*) based on previously published values for the planet30. For the fits to the spectroscopic phase curves, we then fixed these orbital parameters to the estimated best fit from the broadband light curve fit to avoid variations in these wavelength-independent values causing spurious features in the final spectra. We fitted the observations using the No U-Turns Sampler (NUTS) from PyMC357 with 3 chains, each taking 6,000 tuning steps and 6,000 production draws with a target acceptance rate of 0.95. We used the Gelman–Rubin statistic58 to ensure the chains had converged. We then used the 16th, 50th and 84th percentiles from the PyMC3 samples to estimate the best-fit values and their uncertainties.
Eureka! v2 fitting methods
For the second fit made with Eureka!, we proceeded very similarly to the Eureka! v1 fit. We clipped the light curves using a boxcar filter of 20 integrations wide with a maximum of 20 iterations and a rejection threshold of 4σ to reject these outliers. We also modelled the phase curve using a second-order sinusoidal function, but we modelled the transit and eclipse using batman59 instead of starry. Like in the Eureka! v1 fit, we modelled instrumental systematics with a linear polynomial model in time (equation (4)), an exponential ramp (equation (5)), a first-order polynomial in y position (equation (6)) and a first-order polynomial in PSF width in the sy direction (equation (7)).
We fitted the data using the emcee sampler60 instead of NUTS, with 500 walkers and 1,500 steps. The jump parameters that we used were the same as in the Eureka! v1 fit: Rp/R*, Fday, u1, u2, AmpCos1, AmpSin1, AmpCos2, AmpSin2, c0, c1, r0, r1, f, g and scattermult (multiplier to the estimated Poisson noise level for each integration like in the Eureka! v1 fit). We used uniform priors on u1 and u2 from 0 to 1, uniform priors on AmpCos1, AmpSin1, AmpCos2, AmpSin2 from −1.5 to 1.5 and broad normal priors and all other jump parameters. Convergence, mean values and uncertainties were computed in the same way as for the Eureka! v1 fit.
TEATRO fitting methods
To measure the planet’s emission as a function of longitude, we modelled the light curves with a phase-variation model, an eclipse model, a transit model and an instrument systematics model. The phase-curve model, Ψ(t), consists of two sinusoids: one at the planet’s orbital period, P, and one at P/2 to account for second-order variations. The eclipse model, E(t), and transit model, T(t), are computed with the exoplanet61 package that uses the starry package54. We save the eclipse depth, δe, and normalize E(t) to a value of 0 during the eclipse and 1 out of the eclipse, which we then call EN(t). We used published transit ephemerides62, a null eccentricity and published stellar parameters63. The planet-to-star radius ratio, Rp/R*, impact parameter, b, and mid-transit time, t0, are obtained from a fit to the broadband light curve. The systematics model, S(t), is composed of a linear function to account for a downwards trend and an exponential function to account for the initial ramp. The full model is expressed as:
where Ψ(te) is the value of Ψ at the mid-eclipse time, te.
We fit our model to the data using a Markov chain Monte Carlo (MCMC) procedure based on the PyMC3 package57 and gradient-based inference methods as implemented in the exoplanet package61. We set normal priors for t0, Rp/R*, the stellar density (ρ*), aΨ, bΨ, cS and dS with mean values obtained from an initial nonlinear least-squares fit, a normal prior for aS with a zero mean, uniform priors for the surface brightness ratio between the planet’s dayside and the star (s), b, cΨ and dΨ, uninformative priors for the quadratic limb-darkening parameters56, and allowed for wide search ranges. We ran two MCMC chains with 5,000 tuning steps and 100,000 posterior samples. Convergence was obtained for all parameters (except in one case where aS was negligible and bS was unconstrained). We merged the posterior distributions of both chains and used their median and standard deviation to infer final values and uncertainties for the parameters. We also verified that the values obtained from each chain were consistent.
For the spectroscopic light-curve fits, we fixed all physical parameters to those obtained from the broadband light-curve fit except the surface brightness ratio, s, that sets the eclipse depth, we masked the transit part of the light curve, and used a similar procedure. After the fits, we calculated the eclipse depth, δe, as s × (Rp/R*)2, and computed Ψ(t) for the final parameters, Ψf(t). The planetary flux is Ψf(t) − Ψf(te) + δe. We computed the uncertainty on the eclipse depth in two different ways: from the standard deviation of the posterior distribution of s × (Rp/R*)2, and from the standard deviation of the in-eclipse points divided by \(\sqrt{{N}_{{\mathrm{e}}}}\), where Ne is the number of in-eclipse points, and took the maximum of the two. To estimate the uncertainty on the planet’s flux, we computed the 1σ interval of Ψ(t) based on the posterior distributions of its parameters, computed the 1σ uncertainty of dS, and added them in quadrature to the uncertainty on the eclipse depth to obtain more conservative uncertainties.
The spectra presented in this paper and used in the combined spectra are based on system parameters that were derived from a broadband light curve obtained in the 5–12 μm range, a transit fit in which the stellar mass and radius were fixed, a simpler additive model in which the phase curve was not turned off during the eclipse, and an MCMC run that consisted in two chains of 10,000 tuning steps and 10,000 posterior draws. Updated spectra based on system parameters derived from the broadband light curve obtained in the 5–10.5 μm range, a transit fit that has the stellar density as a free parameter, the light-curve model shown in equation (8), and two MCMC chains of 5,000 tuning steps and 100,000 posterior draws are consistent within 1σ at every point with those shown here. As we average four reductions and inflate the uncertainties during the retrievals, the impact of these updates on our results are expected to be marginal.
SPARTA fitting methods
We use emcee60 to fit a broadband light curve with the transit time, eclipse time, eclipse depth, four phase-curve parameters (C1 and D1 for the first-order, and C2 and D2 for the second-order sinusoids), transit depth, a/R*, b, flux normalization, error-inflation factor, instrumental ramp amplitude (A) and 1/timescale (τ), linear slope in time (m) with respect to the mean of the integration times \((\overline{t})\), and linear slope with trace y position (cy) as free parameters. The best-fit transit and eclipse times, a/R* and b are fixed for the spectroscopic light curves.
For the spectroscopic fits, we then use emcee to fit the free parameters: the eclipse depth, four phase-curve parameters, error-inflation factor, flux normalization, instrumental ramp amplitude and 1/timescale, linear slope with time, and linear slope with trace y position. All parameters are given uniform priors. 1/timescale is given a prior of 5–100 d−1, but the other priors are unconstraining. In summary, the instrumental model is:
while the planetary flux model is:
where E is the eclipse depth and ω = 2π/P is the planet’s orbital angular frequency. Note that the phase variations were set to be zero during eclipse.
Combining independent spectra
Comparing the phase-resolved spectra from each reduction (Supplementary Fig. 2), we see that for wavelengths below 10.5 μm, the spectra are typically consistent, while larger differences arise in the >10.5 μm region affected by the shadowed region effect. For our final, fiducial spectrum, we decided to use the median spectrum and inflated our uncertainties to account for disagreements between different reductions. The median phase-resolved spectra were computed by taking the median Fp/F* per wavelength. The uncertainties were computed by taking the median uncertainty per wavelength, and then adding in quadrature the RMS between the individual reductions and the median spectrum; this minimally affects the uncertainties where there is minimal disagreement and appreciably increases the uncertainties where the larger disagreements arise.
Each reduction also computed a transmission spectrum (Supplementary Fig. 2), which appears quite flat (within uncertainties) with minimal differences between reductions. WASP-43b is not an excellent target for transmission spectroscopy, however, and these transmission spectra are not expected to be overly constraining.
Atmospheric forward models
GCMs were used to simulate atmospheric conditions, from which synthetic phase curves and emission spectra were forward modelled and compared with the observations. The GCMs used in this study are listed in Supplementary Table 1, and details of each simulation are provided in Extended Data Table 1 and the following sections.
Generic PCM
The Generic Planetary Climate Model (Generic PCM) is a three-dimensional global climate model designed for modelling the atmosphere of exoplanets and for palaeoclimatic studies. The model has been used for the study of planetary atmospheres of the Solar System64,65,66, terrestrial exoplanets67, mini-Neptunes68 and hot Jupiters69. The dynamical core solves the primitive equations of meteorology on a Arakawa C grid. The horizontal resolution is 64 × 48 (that is, 5.625 × 3.75°) with 40 vertical levels, equally spaced in logarithmic scale between 10 Pa and 800 bars. Along with the various parameterizations of physical processes described in refs. 64,65,66,67,68, the Generic PCM treats clouds as radiatively active tracers of fixed radii.
The model is initialized using temperature profiles from the radiative–convective one-dimensional model Exo-REM70. The radiative data are computed offline using the out-of-equilibrium chemical profiles of the Exo-REM run. We use 27 frequency bins in the stellar channel (0.261–10.4 μm) and 26 in the planetary channel (0.625–324 μm), all bins including 16 k-coefficients. We start the model from a rest state (no winds), with a horizontally homogeneous temperature profile. Models are integrated for 2,000 days, which is long enough to complete the spin-up phase of the simulation above the photosphere. We do not include Rayleigh drag in our models. The simulations are performed including clouds of Mg2SiO4, with varying cloud radii (0.1, 0.5, 1, 3 and 5 μm). We also computed cloudless and Mg2SiO4 models with a 10× solar metallicity and the same radii for the cloud particles. Regardless of the composition and size of the clouds, our model clearly indicates that there is no cloud formation on the dayside. Asymmetric limbs are a natural result of our model, with the eastern terminator being warmer while the western limb is cloudier and cooler. Spectral phase curves were produced using the Pytmosph3R code71.
SPARC/MITgcm with radiative transfer post-processing by gCMCRT
SPARC/MITgcm couples a state-of-the-art non-grey, radiative-transfer code with the MITgcm33. The MITgcm solves the primitive equations of dynamical meteorology on a cubed-sphere grid72. It is coupled to the non-grey radiative-transfer scheme based on the plane-parallel radiative-transfer code of ref. 73. The stellar irradiation incident on WASP-43b is computed with a PHOENIX model74,75,76. We use previously published opacities77, including more recent updates78,79, and the molecular abundances are calculated assuming local chemical equilibrium80. In the GCM simulations, the radiative-transfer calculations are performed on 11 frequency bins ranging from 0.26 μm to 300 μm, with 8 k-coefficients per bin statistically representing the complex line-by-line opacities3. The strong visible absorbers TiO and VO are excluded in our k tables similar to our previous GCMs of WASP-43b3,23 that best match the observed dayside emission spectrum and photometry.
Clouds in the GCM are modelled as tracers that are advected by the flow81 and can settle under gravity. Their formation and evaporation are subjected to chemical equilibrium predictions, that is, the condensation curves of various minerals described in ref. 80. The conversion between the condensable ‘vapour’ and clouds is treated as a simple linear relaxation over a short relaxation timescale of 100 s. The scattering and absorption of the spatial- and time-dependent clouds are included in both the thermal and visible wavelengths of the radiative transfer. A similar dynamics–cloud–radiative coupling has been developed in our previous GCMs with simplified radiative transfer and has been used to study the atmospheric dynamics of brown dwarfs9,82 and ultrahot Jupiters83. Clouds are assumed to follow a log-normal size distribution84, which is described by the reference radius r0 and a non-dimensional deviation σ: \(n(r)=\frac{{{{\mathcal{N}}}}}{\sqrt{2\uppi }\sigma r}\exp \left(-\frac{{[\ln (r/{r}_{0})]}^{2}}{2{\sigma }^{2}}\right)\), where n(r) is the number density per radius bin of r and \({{{\mathcal{N}}}}\) is the total number density. σ and r0 are free parameters and the local \({{{\mathcal{N}}}}\) is obtained from the local mass mixing ratio of clouds. The size distribution is held fixed throughout the model and is the same for all types of cloud.
Our GCMs do not explicitly impose a uniform radiative heat flux at the bottom boundary but rather relax the temperature of the lowest model layer (that is, the highest pressure layer) to a certain value over a short timescale of 100 s. This assumes that the deep GCM layer reaches the convective zone and the temperature there is set by the interior convection that ties to the interior structure of the planet. This lowest-layer temperature is in principle informed by internal structure models of WASP-43b, which are run by MESA hot Jupiter evolution modules12 to match the present radius of WASP-43b. In most models, this lowest-layer temperature is about 2,509 K at about 510 bars. The horizontal resolution of our GCMs is typically C48, equivalent to about 1.88° per grid cell. The vertical domain is from 2 × 10−4 bar at the top to 700 bars at the bottom and is discretized to 53 vertical layers. We typically run the simulation for over 1,200 days and average all physical quantities over the last 100 days of the simulations.
All our GCMs assume a solar composition. We performed a baseline cloudless model and one case with only MnS and Na2S clouds with r0 = 3 μm, and then a few cases with MnS, Na2S and MgSiO3 clouds with r0 = 1, 1.5, 2 and 3 μm. The σ is held fixed at 0.5 in all our cloudy GCMs.
We post-process our GCM simulations with the state-of-the-art gCMCRT code, which is a publicly available hybrid Monte Carlo radiative transfer (MCRT) and ray-tracing radiative-transfer code. The model is described in detail in ref. 85 and has been applied to a range of exoplanet atmospheres83,86. gCMCRT can natively compute albedo, transmission and emission spectra at both low and high spectral resolution. gCMCRT uses custom k tables, which take cross-section data from both HELIOS-K87 and EXOPLINES88. Here, we apply gCMCRT to compute low-resolution emission spectra and phase curves at R ≈ 300 from our GCM simulations. We use the three-dimensional temperature and condensate cloud tracer mixing ratio from the time-averaged end-state of each case. We assume the same cloud particle size distribution as our GCMs.
expeRT/MITgcm
The GCM expeRT/MITgcm uses the same dynamical core as SPARC/MITgcm and solves the hydrostatic primitive equations on a C32 cubed-sphere grid72. It resolves the atmosphere above 100 bar on 41 log-spaced cells between 1 × 10−5 bar and 100 bar. Below 100 bar, 6 linearly spaced grid cells between 100 bar and 700 bar are added. The model expeRT/MITgcm thus resolves deep dynamics in non-inflated hot Jupiters like WASP-43b16,89.
The GCM is coupled to a non-grey radiative-transfer scheme based on petitRADTRANS90. Fluxes are recalculated every fourth dynamical time step. Stellar irradiation is described by the spectral fluxes from the PHOENIX model atmosphere suite74,75,76. The GCM operates on a precalculated grid of correlated k-binned opacities. Opacities from the ExoMol database91 are precalculated offline on a grid of 1,000 logarithmically spaced temperature points between 100 K and 4,000 K for every vertical layer. We further include the same species as shown in ref. 89 except TiO and VO to avoid the formation of a temperature inversion in the upper atmosphere. These are: H2O (ref. 92), CH4 (ref. 93), CO2 (ref. 94), NH3 (ref. 95), CO (ref. 96), H2S (ref. 97), HCN (ref. 98), PH3 (ref. 99), FeH (ref. 100), Na (refs. 74,101) and K (refs. 74,101). For Rayleigh scattering, the opacities are H2 (ref. 102) and He (ref. 103), and we add the following collision-induced absorption (CIA) opacities: H2–H2 (ref. 104) and H2–He (ref. 104). We use for radiative-transfer calculations in the GCM the same wavelength resolution as SPARC/MITgcm (S1), but incorporate 16 instead of 8 k-coefficients. Two cloud-free WASP-43b GCM simulations were performed, one with solar and one with 10× solar element abundances. Each simulation ran for 1,500 days to ensure that the deep wind jet has fully developed. The GCM results used in this paper were time averaged over the last 100 simulation days.
Spectra and phase curves are produced from our GCM results in post-processing with petitRADTRANS90 and prt_phasecurve89 using a spectral resolution of R = 100 for both the phase curve and the spectra.
RM-GCM
Originally adapted from the GCM of ref. 105 by refs. 106,107,108, the RM-GCM model has been applied to numerous investigations of hot Jupiters and mini-Neptunes35,109,110,111. The GCM’s dynamical core solves the primitive equations of meteorology using a spectral representation of the domain, and it is coupled to a two-stream, double-grey radiative-transfer scheme based on ref. 112. Recent updates have added aerosol scattering35 with radiative feedback8,36. Following ref. 8, aerosols are representative of condensate clouds and are treated as purely temperature-dependent sources of opacity, with constant mixing ratios set by the assumed solar elemental abundances. The optical thicknesses of the clouds are determined by converting the relative molecular abundances (or partial pressures) of each species into particles with prescribed densities and radii8. The model includes up to 13 different cloud species of various condensation temperatures, abundances and scattering properties. Places where clouds overlap have mixed properties, weighted by the optical thickness of each species.
Simulations from this GCM included a clear atmosphere and two sets of cloudy simulations. Following ref. 8, one set of cases included 13 different species: KCl, ZnS, Na2S, MnS, Cr2O3, SiO2, Mg2SiO4, VO, Ni, Fe, Ca2SiO4, CaTiO2 and Al2O3; the other set omitted ZnS, Na2S, MnS, Fe and Ni, based on considerations of nucleation efficiency113. For both cloud composition scenarios, the models explored the observational consequences of variations in the cloud deck’s vertical thickness through a series of simulations with clouds tops truncated over a range of heights at 5-layer intervals (roughly a scale height), ranging from 5 to 45 layers of the 50-layer model. This effectively mimics a range of vertical mixing strengths. From the complete set published in ref. 26, we selected a subset, with clouds of maximum vertical extents between two and nine scale heights from each of the two cloud composition scenarios.
Simulations were initialized with clear skies, no winds and no horizontal temperature gradients. We ran the simulations for over 3,500 planetary orbits, assuming tidal synchronization. Resulting temperature, wind and cloud fields of the GCM were then post-processed114,115 to yield corresponding emission phase curves.
THOR
THOR116,117 is an open-source GCM developed to study the atmospheres and climates of exoplanets, free from Earth- or Solar System-centric tunings. The core that solves the fluid flow equations, the dynamical core, solves the non-hydrostatic compressible Euler equations on an icosahedral grid116,118. THOR has been validated and used to simulate the atmosphere of Earth116,119, Solar System planets120,121 and exoplanets116,117,122.
For this work, THOR used the same configuration as with previously published simulations to study the atmospheric temperature structure, cloud cover and chemistry of WASP-43b4,38,123. Two simulations were conducted, one with a clear atmosphere and another with a cloud structure on the nightside of the planet. To represent the radiative processes, THOR uses a simple two-band formulation calibrated to reproduce the results from more complex non-grey models on WASP-43b3,124. A simple cloud distribution on the nightside of the planet and optical cloud properties are parameterized4 and adapted to reproduce previous HST21 and Spitzer4,22 observations. These simulations on WASP-43b with THOR have also been used to test the performance of future Ariel phase-curve observations125.
Both simulations, with clear and cloudy atmospheres, started with isothermal atmospheres (1,440 K, equilibrium temperature) and integrated for roughly 9,400 planetary orbits (assuming a tidally locked configuration) until a statistically steady state of the deep atmosphere thermal structure was reached. The long integration avoids biasing the results towards the set initial conditions120.
The multiwavelength spectra are obtained from post-processing the three-dimensional simulations with a multiwavelength radiative-transfer model126. The disk-averaged planet spectrum is calculated at each orbital phase by projecting the outgoing intensity for each geographical location of the observed hemisphere. The spectra include cross-sections of the main absorbers in the infrared, drawn from the ExoMOL (H2O (ref. 92), CH4 (ref. 127), NH3 (ref. 128), HCN (ref. 129) and H2S (ref. 97)), HITEMP130 (CO2 and CO) and HITRAN131 (C2H2) databases. The Na and K resonance lines132 are also added, as were H2–H2 and H2–He CIA104. The atmospheric bulk composition was assumed to have solar abundance (consistent with HST/WFC3 spectrum observations), and each chemical species concentration was calculated with the FastChem model133. The PHOENIX models74,75,76 were used for the WASP-43 star spectrum.
Atmospheric retrieval models
We perform atmospheric retrievals on the phase-resolved emission spectra using six different retrieval frameworks, each described in turn below. The chemical constraints from these analyses are summarized in Extended Data Tables 2 and 3, and the spectral fits obtained are shown in Extended Data Fig. 3. Across the six retrieval analyses, we use an error-inflation parameter to account for the effects of unknown data and/or model uncertainties. This free parameter is wavelength independent and multiplies the 1σ error bars in the calculation of the likelihood function in the Bayesian sampling algorithm.
HyDRA retrieval framework
The HyDRA atmospheric retrieval framework134 consists of a parametric atmospheric forward model coupled to PyMultiNest135,136, a nested sampling Bayesian parameter estimation algorithm137. HyDRA has been applied to hydrogen-rich atmospheres138,139, and further adapted for secondary atmospheres140 and high-resolution spectroscopy in both one and two dimensions141,142. The input parameters for the atmospheric forward model include constant-with-depth abundances for each of the chemical species considered, six temperature profile parameters corresponding to the temperature profile model of ref. 143, and a constant-with-wavelength multiplicative error-inflation parameter to account for model uncertainties. We additionally include a dilution parameter, AHS, for the dayside, morning and evening hemispheres, which multiplies the emission spectrum by a constant factor <1 and accounts for temperature inhomogeneities in each hemisphere144.
We consider opacity contributions from the chemical species that are expected to be present in hot Jupiter atmospheres and that have opacity in the MIRI LRS wavelength range: H2O (ref. 130), CH4 (refs. 127,145), NH3 (ref. 128), HCN (refs. 98,129), CO (ref. 130), CO2 (ref. 130), C2H2 (refs. 131,146), SO2 (ref. 147), H2S (refs. 97,148) and CIA due to H2–H2 and H2–He (ref. 104). The line-by-line absorption cross-sections for these species are calculated following the methods described in ref. 134, using data from each of the references listed. We further explore retrievals with a simple silicate cloud model, which includes the modal particle size, cloud particle abundance, cloud base pressure and a pressure exponent for the drop-off of cloud particle number density with decreasing pressure. The opacity structure of the cloud is calculated using the absorption cross-sections of ref. 149.
Given the input chemical abundances, temperature profile and cloud parameters, the forward model calculates line-by-line radiative transfer to produce the thermal emission spectrum at a resolution of R ≈ 15,000. The spectrum is then convolved to a resolution of 100, binned to the same wavelength bins as the observations and compared with the observed spectrum to calculate the likelihood of the model instance. The nested sampling algorithm explores the parameter space using 2,000 live points, and further calculates the Bayesian evidence of the retrieval model, which can be used to compare different models52. In particular, we calculate the detection significance of a particular chemical species by comparing retrievals that include/exclude that species, fixing the value of the error-inflation parameter to be the median retrieved value found with the full retrieval model.
Across the four phases, the only chemical species detected with statistical significance (≳3σ) is H2O. The retrieved H2O abundances are in the range ~30–104 ppm (1σ uncertainties), with detection significances varying between ~3σ and ~4σ (Extended Data Table 2). We do not detect CH4 at any phase, and place an upper limit of 16 ppm on the nightside CH4 abundance, potentially indicating disequilibrium chemistry processes as described in the main text. We do not detect NH3 at any phase either, consistent with the very low NH3 abundances predicted by both chemical equilibrium and disequilibrium models23. The retrievals do not favour cloudy models over clear models with statistical significance, with extremely weak preferences of <1σ at all phases. In addition, the posterior probability distributions for the cloud parameters are unconstrained. Extended Data Fig. 5 shows the pressure ranges of the atmospheric model probed by the observations.
PyratBay retrieval framework
PyratBay is an open-source framework that enables atmospheric modelling, spectral synthesis, and atmospheric retrievals of exoplanet observations150. The atmospheric model consists of parametric temperature, composition and altitude profiles as a function of pressure, for which emission and transmission spectra can be generated. The radiative-transfer module considers opacity from alkali lines151, Rayleigh scattering152,153, Exomol and HITEMP molecular line lists130,154 pre-processed with the REPACK package155 to extract the dominant line transitions, CIA156 and cloud opacities. The PyratBay retrieval framework has the ability to stagger model complexity and explore a hierarchy of different model assumptions. Temperature models range from an isothermal profile to physically motivated parameterized models143,157. Composition profiles range from the simpler constant-with-altitude ‘free abundance’ to the more complex ‘chemically consistent’ retrievals, the latter accomplished via the TEA code158; while cloud condensate prescriptions range from the classic ‘power law + grey’ to a ‘single-particle-size’ haze profile, a partial-coverage factor ‘patchy clouds’159, and the complex parameterized Mie-scattering thermal stability cloud (TSC) model (J.B. et al., manuscript in preparation). The TSC cloud prescription, initially inspired by refs. 84,160, has additional flexibility in the location of the cloud base and was further improved for this analysis (see below). The formulation utilizes a parameterized cloud shape, effective particle size and gas number density below the cloud deck, while the atmospheric mixing and settling are wrapped up inside the cloud extent and the condensate mole fraction as free parameters. This cloud model was applied to WASP-43b JWST/MIRI phase-curve simulations23, generated during the JWST preparatory phase, in anticipation of the actual WASP-43b JWST/MIRI observations. We showed that the TSC model has the ability to distinguish between MgSiO3 and MnS clouds on the nightside of the planet.
For this analysis, we conducted a detailed investigation using various model assumptions. We started by exploring simple temperature prescriptions and gradually moved towards more complex ones. Initially, we considered opacity contributions from all chemical species expected to be observed in the MIRI wavelength range (H2O, CH4, NH3, HCN, CO, CO2, C2H2, SO2, H2S), but eventually focused on only those that are fit by the data. We also implemented the dilution parameter144 and an error-inflation factor, which account for some additional model and data uncertainties. The constraints on H2O (together with the detection significance161) and the upper limit for CH4 for all phases are given in Extended Data Table 2. The abundances of these species across all phases were largely model independent. However, the tentative constraints on NH3, which we saw in multiple phases, were strongly model dependent, and were completely erased with the inclusion of the dilution parameter and the error inflation, thus we do not report them here. WASP-43b emission spectra were computed at a resolution of R ≈ 15,000 utilizing opacity sampling of high-resolution pre-computed cross-sections (R ≈ 106) of considered species. Furthermore, we thoroughly examined the possibility of detecting clouds in each of the four-quadrant phases, with a special emphasis on the nightside of the planet. To do this, we employed the TSC model, as in our previous analysis23, and explored a range of cloud species, MgSiO3, MnS, ZnS and KCl, that would condense under the temperature regimes expected for WASP-43b162 (Extended Data Fig. 6, left). We also introduced the effective standard deviation of the log-normal distribution84 as a free parameter (σlog), allowing for even more flexibility in our cloud model (Extended Data Fig. 6, right, last subpanel). To thoroughly explore the parameter space, we used two Bayesian samplers, the differential-evolution MCMC algorithm163, implemented following ref. 164, and the nested sampling algorithm, implemented through PyMultiNest135,136, utilizing 15 million models and 2,000 live points, respectively. Our investigation did not provide constraints on any of the cloud parameters for any of the explored cloud condensates at any of the planetary phases, indicating the absence of detectable spectral features from clouds in the observations (Extended Data Fig. 6, right).
NEMESIS retrieval framework
NEMESIS165,166 is a free retrieval framework that uses a fast correlated-k167 forward model, combined with either an optimal estimation or nested sampling retrieval algorithm. It has been used to perform retrievals on spectra of numerous planetary targets, both inside and outside the Solar System168,169. In this work, we use the PyMultiNest sampler136 with 500 live points. The retrieval model presented includes four spectrally active gases, H2O (ref. 92), CO (ref. 96), CH4 (ref. 93) and NH3 (ref. 95), with k tables calculated as in ref. 91; we did not include CO2 or H2S after initial tests indicated these were not required to fit the spectrum. All gases are assumed to be well mixed in altitude. CIA from H2 and He is taken from refs. 156,170. The spectrum is calculated at the resolution of the observation, using optimized channel integrated k tables generated from original k tables with a resolving power R = 1,000. The temperature profile is modelled as a three-parameter Guillot profile, after ref. 157, with free parameters κ, γ and β (α is fixed to be zero). We include a well-mixed, spectrally grey cloud with a scalable total optical depth with a cloud top at 12.5 mbar. The other retrieved parameters are a hotspot dilution factor for phases 0.25, 0.5 and 0.75, following ref. 144, and an error-inflation term.
To calculate the detection significance for H2O, we run the retrieval with and without H2O, with all other aspects of the run identical. We then take the difference of the PyMultiNest global log-evidence values for the two scenarios, and convert from log(Bayesian evidence) to sigma following ref. 52. The 99% upper limit for CH4 is calculated from the equally weighted posterior distribution. We also attempt to retrieve CO and NH3 abundances. CO is generally poorly constrained, and NH3 is unconstrained for phases 0 and 0.75; for log(NH3), we recover a 99% upper limit of −2.2 at phase 0.25 and −3.9 at phase 0.5. The cloud opacity is also generally unconstrained, with the total optical depth able to span several orders of magnitude. We stress that this model is very crude as it has only one variable cloud parameter, and further exploration of suitable cloud models for mid-infrared phase curves is warranted in future work.
SCARLET retrieval framework
We perform atmospheric retrievals on the four phase-resolved spectra using the SCARLET framework160,171. The planetary disk-integrated thermal emission, Fp, is modelled for a given set of atomic/molecular abundances, temperature–pressure profile and cloud properties. We compare our model spectra with the observations by normalizing the thermal emission Fp using a PHOENIX74,75,76 stellar model spectrum with effective temperature Teff = 4,300 K and surface gravity log g = 4.50. The model spectra are computed at a resolving power of R = 15,625, convolved to the resolving power of MIRI/LRS and then binned to the 11 spectral bins (<10.5 μm) considered in the analysis, assuming the throughput to be uniform over a single bin.
The atmospheric analysis is performed considering thermochemical equilibrium, where the metallicity [M/H] (\({{{\mathcal{U}}}}[-3,3]\)) and carbon-to-oxygen ratio (\({{{\mathcal{U}}}}[0,3]\)) are free parameters that dictate the overall atmospheric composition. We use a free parameterization of the temperature–pressure profile172 by fitting for N = 4 temperature points (\({{{\mathcal{U}}}}[100,4400]\,{\mathrm{K}}\)) with a constant spacing in log-pressure. The temperature–pressure profile is interpolated to the 50 layers (P = 102–10−6 bar) considered in the model using a spline function to produce a smooth profile. We use a grid of chemical equilibrium abundances produced with FastChem2173 to interpolate the abundance of species as a function of temperature and pressure for given values of [M/H] and C/O. The species considered in the equilibrium chemistry are H, H− (refs. 174,175), H2, He, H2O (ref. 92), OH (ref. 130), CH4 (ref. 127), C2H2 (ref. 176), CO (ref. 130), CO2 (ref. 130), NH3 (ref. 95), HCN (ref. 98), PH3 (ref. 99), TiO (ref. 177) and VO (ref. 178). All opacities for these species are considered when computing the thermal emission. We account for potential spatial atmospheric inhomogeneities in the planetary disk that are observed at a given phase by including an area fraction parameter AHS (\({{{\mathcal{U}}}}[0,1]\)), which is meant to represent the possibility of a fraction of the disk contributing to most of the observed thermal emission144. This parameter is considered for all phases with the exception of the nightside, which is expected to be relatively uniform. Finally, we fit for an error-inflation parameter kσ (\({{{\mathcal{U}}}}[0.1,10]\)) to account for potential model and data uncertainty, which results in a total of 8 (7 for the nightside) free parameters. We consider 8 walkers per free parameter for the retrievals which are run for 30,000 steps. The first 18,000 steps are discarded when producing the posterior distributions of the free parameters.
PLATON retrieval framework
PLATON179, Planetary Atmosphere Tool for Observer Noobs, is a Bayesian retrieval tool that assumes equilibrium chemistry. We adopt the temperature–pressure profile parameterization of ref. 180, and use the dynesty nested sampler49 to retrieve the following free parameters: stellar radius; stellar temperature; the log metallicity, log(Z); C/O; 5 temperature–pressure parameters (log(κth), log(γ), log(γ2), α, β); and an error multiplier. The stellar radius and temperature are given Gaussian priors with means and standard deviations set by the measurements in ref. 55: 4,400 ± 200 K and 0.667 ± 0.011 R⊙, respectively. The combination of the two have a similar effect to the dilution parameter of other retrieval codes, which multiplies the emission spectrum by a constant. For phase 0.0, we obtain a significantly better fit when methane opacity is set to zero (thus removing all spectral features from methane). We therefore adopt this as the fiducial model, whereas for other phases, we do not zero out any opacities.
For all retrievals, we use nested sampling with 1,000 live points. The opacities (computed at R = 10,000) and the line lists used to compute them are listed in ref. 179. We include all 31 species in retrieval, notably including H2O, CO, CO2, CH4 (except on the nightside), H2S and NH3.
ARCiS retrieval framework
ARCiS (Artful modelling code for exoplanet science) is an atmospheric modelling and Bayesian retrieval code181,182 that utilizes the MULTINEST135 Monte Carlo nested sampling algorithm. The code was used in previous retrievals of the atmosphere of WASP-43b in transmission183, using the observations of ref. 184, and in phase-resolved emission185, using the observations of refs. 21,22,25,186. Reference 183 found some evidence that AlO improves the fit of the transmission spectra of WASP-43b in the 1.1–1.6 μm region. We therefore include in our models for this work the following set of molecules in our free molecular retrievals: H2O (ref. 92), CO (ref. 96), CO2 (ref. 94), NH3 (ref. 95), CH4 (ref. 93) and AlO (ref. 187). The molecular line lists are from the ExoMol154,188 or HITEMP130 databases as specified, and k tables from the ExoMolOP opacity database91. CIA for H2 and He are taken from refs. 156,170. We explore the inclusion of a variety of additional molecules that have available line list data with spectral features in the region of our observations, including HCN (ref. 98), SiO (ref. 189) and N2O (ref. 130). We use the Bayes factor, which is the difference between the nested sampling global log-evidence (log E) between two models, to assess whether the inclusion of a particular parameter is statistically significant. For this, we run a retrieval with the base set of species only and another with the base set plus the molecule being assessed. The difference in log E between the two models is converted to a significance in terms of σ using the metric of ref. 52. We explore the inclusion of a simple grey, patchy cloud model, which parameterizes cloud top pressure and degree of cloud coverage (from 0 for completely clear to 1 for completely covered). We use 1,000 live points and a sampling efficiency of 0.3 in MULTINEST for all retrievals.
We run retrievals both including and not including a retrieved error-inflation parameter. The error-inflation parameter is implemented as per ref. 190 to account for underestimated uncertainties and/or unknown missing forward model parameters. All phases apart from 0.0 retrieved a parameter that increases the observational error bars by two to three times their original values. The pressure–temperature profile parameterization of ref. 191 is used in all cases. We find evidence for the inclusion of H2O for all four phases, although this evidence goes from strong to weak when error inflation is included for the morning phase (0.75). We find no strong evidence for CH4 at any phase, with 95% confidence upper limits on the log of the volume mixing ratio (VMR) of −4.9, −2.9, −3.2 and −2.2 for phases 0.0, 0.25, 0.5 and 0.75, respectively. We find some model-dependent hints of moderate evidence (based on the metric of ref. 52) of 4.4σ for NH3 at phase 0.5 (constrained to \(\log{{\mathrm{VMR}}}={-4.5}_{-0.5}^{+0.7}\)), 3.1σ for CO at phase 0.5 (\(\log{{\mathrm{VMR}}}={-1.7}_{-0.7}^{+0.5}\)) and 2.6σ for CO at phase 0.25 (\(\log{{\mathrm{VMR}}}={-4.0}_{-0.4}^{+0.3}\)). However, these disappear when the error-inflation parameter is introduced. We are not able to constrain any of the cloud parameters for any phase, and so do not find a statistical reason to include our simple cloud parameterization in the models to better fit the observations.
Data availability
The data used in this paper are associated with JWST DD-ERS programme 1366 (principal investigators N.M.B., J.L.B. and K.B.S.; observation 11) and are publicly available from the Mikulski Archive for Space Telescopes (https://mast.stsci.edu). Additional intermediate and final results from this work are archived on Zenodo at https://doi.org/10.5281/zenodo.10525170 (ref. 192).
Code availability
We used the following codes to process, extract, reduce and analyse the data: STScI’s JWST Calibration pipeline46, Eureka!45, TEATRO, SPARTA48, Generic PCM64,65,66,67,68, SPARC/MITgcm9,33,81,82, expeRT/GCM16,72,89, RM-GCM8,35,106,107,108, THOR4,116,117,124,126,193, HyDRA134, PyratBay150, NEMESIS165,166, SCARLET160,171, PLATON179, starry54, exoplanet61, PyMC357, emcee60, dynesty49, numpy194, astropy195,196 and matplotlib197.
References
Keating, D., Cowan, N. B. & Dang, L. Uniformly hot nightside temperatures on short-period gas giants. Nat. Astron. 3, 1092–1098 (2019).
Beatty, T. G. et al. Spitzer phase curves of KELT-1b and the signatures of nightside clouds in thermal phase observations. Astron. J. 158, 166 (2019).
Kataria, T. et al. The atmospheric circulation of the hot Jupiter WASP-43b: comparing three-dimensional models to spectrophotometric data. Astrophys. J. 801, 86 (2015).
Mendonça, J. M., Malik, M., Demory, B.-O. & Heng, K. Revisiting the phase curves of WASP-43b: confronting re-analyzed Spitzer data with cloudy atmospheres. Astron. J. 155, 150 (2018).
Parmentier, V. & Crossfield, I. J. M. in Handbook of Exoplanets (eds Deeg, H. J. & Belmonte, J. A.) 1419–1440 (Springer, 2018).
Hu, R., Demory, B.-O., Seager, S., Lewis, N. & Showman, A. P. A semi-analytical model of visible-wavelength phase curves of exoplanets and applications to Kepler-7b and Kepler-10b. Astrophys. J. 802, 51 (2015).
Shporer, A. & Hu, R. Studying atmosphere-dominated hot Jupiter Kepler phase curves: evidence that inhomogeneous atmospheric reflection is common. Astron. J. 150, 112 (2015).
Roman, M. T. et al. Clouds in three-dimensional models of hot Jupiters over a wide range of temperatures. I. Thermal structures and broadband phase-curve predictions. Astrophys. J. 908, 101 (2021).
Tan, X. & Showman, A. P. Atmospheric circulation of brown dwarfs and directly imaged exoplanets driven by cloud radiative feedback: effects of rotation. Mon. Not. R. Astron. Soc. 502, 678–699 (2021).
Parmentier, V., Showman, A. P. & Fortney, J. J. The cloudy shape of hot Jupiter thermal phase curves. Mon. Not. R. Astron. Soc. 501, 78–108 (2021).
Perna, R., Menou, K. & Rauscher, E. Magnetic drag on hot Jupiter atmospheric winds. Astrophys. J. 719, 1421–1426 (2010).
Komacek, T. D. & Youdin, A. N. Structure and evolution of internally heated hot Jupiters. Astrophys. J. 844, 94 (2017).
Rogers, T. M. Constraints on the magnetic field strength of HAT-P-7 b and other hot giant exoplanets. Nat. Astron. 1, 0131 (2017).
Kataria, T., Showman, A. P., Fortney, J. J., Marley, M. S. & Freedman, R. S. The atmospheric circulation of the super Earth GJ 1214b: dependence on composition and metallicity. Astrophys. J. 785, 92 (2014).
Zhang, X. & Showman, A. P. Effects of bulk composition on the atmospheric dynamics on close-in exoplanets. Astrophys. J. 836, 73 (2017).
Carone, L. et al. Equatorial retrograde flow in WASP-43b elicited by deep wind jets? Mon. Not. R. Astron. Soc. 496, 3582–3614 (2020).
Showman, A. P., Tan, X. & Parmentier, V. Atmospheric dynamics of hot giant planets and brown dwarfs. Space Sci. Rev. 216, 139 (2020).
Helling, C. et al. Cloud property trends in hot and ultra-hot giant gas planets (WASP-43b, WASP-103b, WASP-121b, HAT-P-7b, and WASP-18b). Astron. Astrophys. 649, A44 (2021).
Hellier, C. et al. WASP-43b: the closest-orbiting hot Jupiter. Astron. Astrophys. 535, L7 (2011).
Scandariato, G. et al. Phase curve and geometric albedo of WASP-43b measured with CHEOPS, TESS, and HST WFC3/UVIS. Astron. Astrophys. 668, A17 (2022).
Stevenson, K. B. et al. Thermal structure of an exoplanet atmosphere from phase-resolved emission spectroscopy. Science 346, 838–841 (2014).
Stevenson, K. B. et al. Spitzer phase curve constraints for WASP-43b at 3.6 and 4.5 μm. Astron. J. 153, 68 (2017).
Venot, O. et al. Global chemistry and thermal structure models for the hot Jupiter WASP-43b and predictions for JWST. Astrophys. J. 890, 176 (2020).
Helling, C. et al. Mineral cloud and hydrocarbon haze particles in the atmosphere of the hot Jupiter JWST target WASP-43b. Astron. Astrophys. 641, A178 (2020).
Morello, G., Danielski, C., Dickens, D., Tremblin, P. & Lagage, P. O. An independent analysis of the Spitzer/IRAC phase curves of WASP43 b. Astron. J. 157, 205 (2019).
Murphy, M. M. et al. A lack of variability between repeated Spitzer phase curves of WASP-43b. Astron. J. 165, 107 (2023).
Wright, G. S. et al. The mid-infrared instrument for jwst and its in-flight performance. Publ. Astron. Soc. Pac. 135, 048003 (2023).
Kendrew, S. et al. The Mid-Infrared Instrument for the James Webb Space Telescope, IV: the low-resolution spectrometer. Publ. Astron. Soc. Pac. 127, 623 (2015).
Bouwman, J. et al. Spectroscopic time series performance of the Mid-infrared Instrument on the JWST. Publ. Astron. Soc. Pac. 135, 038002 (2023).
Esposito, M. et al. The GAPS programme with HARPS-N at TNG. XIII. The orbital obliquity of three close-in massive planets hosted by dwarf K-type stars: WASP-43, HAT-P-20 and Qatar-2. Astron. Astrophys. 601, A53 (2017).
May, E. M. & Stevenson, K. B. Introducing a new Spitzer master BLISS map to remove the instrument systematic phase-curve-parameter degeneracy, as demonstrated by a reanalysis of the 4.5 μm WASP-43b phase curve. Astron. J. 160, 140 (2020).
Bell, T. J. et al. A comprehensive reanalysis of Spitzer’s 4.5 μm phase curves, and the phase variations of the ultra-hot Jupiters MASCARA-1b and KELT-16b. Mon. Not. R. Astron. Soc. 504, 3316–3337 (2021).
Showman, A. P. et al. Atmospheric circulation of hot Jupiters: coupled radiative-dynamical general circulation model simulations of HD 189733b and HD 209458b. Astrophys. J. 699, 564–584 (2009).
Showman, A. P. & Polvani, L. M. Equatorial superrotation on tidally locked exoplanets. Astrophys. J. 738, 71 (2011).
Roman, M. & Rauscher, E. Modeling the effects of inhomogeneous aerosols on the hot Jupiter Kepler-7b’s atmospheric circulation. Astrophys. J. 850, 17 (2017).
Roman, M. & Rauscher, E. Modeled temperature-dependent clouds with radiative feedback in hot Jupiter atmospheres. Astrophys. J. 872, 1 (2019).
Cowan, N. B. et al. Thermal phase variations of WASP-12b: defying predictions. Astrophys. J. 747, 82 (2012).
Mendonça, J. M., Tsai, S.-m, Malik, M., Grimm, S. L. & Heng, K. Three-dimensional circulation driving chemical disequilibrium in WASP-43b. Astrophys. J. 869, 107 (2018).
Agúndez, M., Parmentier, V., Venot, O., Hersant, F. & Selsis, F. Pseudo 2D chemical model of hot-Jupiter atmospheres: application to HD 209458b and HD 189733b. Astron. Astrophys. 564, A73 (2014).
Tsai, S.-M. et al. Inferring shallow surfaces on sub-Neptune exoplanets with JWST. Astrophys. J. Lett. 922, L27 (2021).
Moses, J. I., Tremblin, P., Venot, O. & Miguel, Y. Chemical variation with altitude and longitude on exo-Neptunes: predictions for Ariel phase-curve observations. Exp. Astron. 53, 279–322 (2022).
Baeyens, R., Konings, T., Venot, O., Carone, L. & Decin, L. Grid of pseudo-2D chemistry models for tidally locked exoplanets—II. The role of photochemistry. Mon. Not. R. Astron. Soc. 512, 4877–4892 (2022).
Gáspár, A. et al. The quantum efficiency and diffractive image artifacts of Si:As IBC mid-IR detector arrays at 5–10 μm: implications for the JWST/MIRI detectors. Publ. Astron. Soc. Pac. 133, 014504 (2021).
Bell, T. J. et al. A first look at the JWST MIRI/LRS phase curve of WASP-43b. Preprint at https://arxiv.org/abs/2301.06350 (2023).
Bell, T. et al. Eureka!: an end-to-end pipeline for JWST time-series observations. J. Open Source Softw. 7, 4503 (2022).
Bushouse, H. et al. JWST calibration pipeline. GitHub https://github.com/spacetelescope/jwst (2022).
Schlawin, E. et al. JWST noise floor. I. Random error sources in JWST NIRCam time series. Astron. J. 160, 231 (2020).
Kempton, E. M.-R. et al. A reflective, metal-rich atmosphere for GJ 1214b from its JWST phase curve. Nature 620, 67–71 (2023).
Koposov, S. et al. joshspeagle/dynesty: v1.2.3. Zenodo https://doi.org/10.5281/zenodo.6609296 (2022).
Cowan, N. B. & Agol, E. Inverting phase functions to map exoplanets. Astrophys. J. Lett. 678, L129 (2008).
Cowan, N. B., Chayes, V., Bouffard, É., Meynig, M. & Haggard, H. M. Odd harmonics in exoplanet photometry: weather or artifact? Mon. Not. R. Astron. Soc. 467, 747–757 (2017).
Trotta, R. Bayes in the sky: Bayesian inference and model selection in cosmology. Contemp. Phys. 49, 71–104 (2008).
Welbanks, L. & Madhusudhan, N. Aurora: a generalized retrieval framework for exoplanetary transmission spectra. Astrophys. J. 913, 114 (2021).
Luger, R. et al. rodluger/starry: v1.2.0. Zenodo https://doi.org/10.5281/zenodo.5567790 (2021).
Bonomo, A. S. et al. The GAPS programme with HARPS-N at TNG. XIV. Investigating giant planet migration history via improved eccentricity and mass determination for 231 transiting planets. Astron. Astrophys. 602, A107 (2017).
Kipping, D. M. Efficient, uninformative sampling of limb darkening coefficients for two-parameter laws. Mon. Not. R. Astron. Soc. 435, 2152–2160 (2013).
Salvatier, J., Wiecki, T. V. & Fonnesbeck, C. Probabilistic programming in Python using PyMC3. PeerJ Comput. Sci. 2, e55 (2016).
Gelman, A. & Rubin, D. B. Inference from iterative simulation using multiple sequences. Stat. Sci. 7, 457–472 (1992).
Kreidberg, L. batman: basic transit model calculation in Python. Publ. Astron. Soc. Pac. 127, 1161 (2015).
Foreman-Mackey, D., Hogg, D. W., Lang, D. & Goodman, J. emcee: the MCMC hammer. Publ. Astron. Soc. Pac. 125, 306 (2013).
Foreman-Mackey, D. et al. exoplanet: gradient-based probabilistic inference for exoplanet data & other astronomical time series. J. Open Source Softw. 6, 3285 (2021).
Ivshina, E. S. & Winn, J. N. TESS transit timing of hundreds of hot Jupiters. Astrophys. J. Suppl. Ser. 259, 62 (2022).
Gillon, M. et al. The TRAPPIST survey of southern transiting planets. I. Thirty eclipses of the ultra-short period planet WASP-43 b. Astron. Astrophys. 542, A4 (2012).
Turbet, M. et al. Day-night cloud asymmetry prevents early oceans on Venus but not on Earth. Nature 598, 276–280 (2021).
Spiga, A. et al. Global climate modeling of Saturn’s atmosphere. Part II: Multi-annual high-resolution dynamical simulations. Icarus 335, 113377 (2020).
Charnay, B., Forget, F., Tobie, G., Sotin, C. & Wordsworth, R. Titan’s past and future: 3D modeling of a pure nitrogen atmosphere and geological implications. Icarus 241, 269–279 (2014).
Turbet, M. et al. The habitability of Proxima Centauri b: II. possible climates and observability. Astron. Astrophys. 596, A112 (2016).
Charnay, B., Meadows, V., Misra, A., Leconte, J. & Arney, G. 3D modeling of GJ1214b’s atmosphere: formation of inhomogeneous high clouds and observational implications. Astrophys. J. 813, L1 (2015).
Teinturier, L. et al. The radiative and dynamical impact of clouds in the atmosphere of the hot Jupiter WASP-43 b. Astron. Astrophys. 683, A231 (2024).
Blain, D., Charnay, B. & Bézard, B. 1D atmospheric study of the temperate sub-Neptune K2-18b. Astron. Astrophys. 646, A15 (2021).
Falco, A., Zingales, T., Pluriel, W. & Leconte, J. Toward a multidimensional analysis of transmission spectroscopy: I. Computation of transmission spectra using a 1D, 2D, or 3D atmosphere structure. Astron. Astrophys. 658, A41 (2022).
Adcroft, A., Campin, J.-M., Hill, C. & Marshall, J. Implementation of an atmosphere ocean general circulation model on the expanded spherical cube. Mon. Weather Rev. 132, 2845 (2004).
Marley, M. S., Gelino, C., Stephens, D., Lunine, J. I. & Freedman, R. Reflected spectra and albedos of extrasolar giant planets. I. Clear and cloudy atmospheres. Astrophys. J. 513, 879–893 (1999).
Allard, F. & Hauschildt, P. H. Model atmospheres for M (sub)dwarf stars. I. The base model grid. Astrophys. J. 445, 433 (1995).
Hauschildt, P. H., Allard, F. & Baron, E. The NextGen model atmosphere grid for 3000 ≤ Teff ≤ 10,000 K. Astrophys. J. 512, 377–385 (1999).
Husser, T. O. et al. A new extensive library of PHOENIX stellar atmospheres and synthetic spectra. Astron. Astrophys. 553, A6 (2013).
Freedman, R. S., Marley, M. S. & Lodders, K. Line and mean opacities for ultracool dwarfs and extrasolar planets. Astrophys. J. Suppl. Ser. 174, 504–513 (2008).
Freedman, R. S. et al. Gaseous mean opacities for giant planet and ultracool dwarf atmospheres over a range of metallicities and temperatures. Astrophys. J. Suppl. Ser. 214, 25 (2014).
Marley, M. S. et al. The Sonora brown dwarf atmosphere and evolution models. I. Model description and application to cloudless atmospheres in rainout chemical equilibrium. Astrophys. J. 920, 85 (2021).
Visscher, C., Lodders, K. & Fegley, B. Atmospheric chemistry in giant planets, brown dwarfs, and low-mass dwarf stars. III. Iron, magnesium, and silicon. Astrophys. J. 716, 1060–1075 (2010).
Parmentier, V., Showman, A. P. & Lian, Y. 3D mixing in hot Jupiters atmospheres—I. Application to the day/night cold trap in HD 209458b. Astron. Astrophys. 558, A91 (2013).
Tan, X. & Showman, A. P. Atmospheric circulation of brown dwarfs and directly imaged exoplanets driven by cloud radiative feedback: global and equatorial dynamics. Mon. Not. R. Astron. Soc. 502, 2198–2219 (2021).
Komacek, T. D., Tan, X., Gao, P. & Lee, E. K. H. Patchy nightside clouds on ultra-hot Jupiters: general circulation model simulations with radiatively active cloud tracers. Astrophys. J. 934, 79 (2022).
Ackerman, A. S. & Marley, M. S. Precipitating condensation clouds in substellar atmospheres. Astrophys. J. 556, 872–884 (2001).
Lee, E. K. et al. 3D radiative transfer for exoplanet atmospheres. gCMCRT: a GPU-accelerated mcrt code. Astrophys. J. 929, 180 (2022).
Lee, E. K. et al. Simulating gas giant exoplanet atmospheres with exo-fms: comparing semigrey, picket fence, and correlated-k radiative-transfer schemes. Mon. Not. R. Astron. Soc. 506, 2695–2711 (2021).
Grimm, S. L. et al. Helios-k 2.0 opacity calculator and open-source opacity database for exoplanetary atmospheres. Astrophys. J. Suppl. Ser. 253, 30 (2021).
Gharib-Nezhad, E. et al. Exoplines: molecular absorption cross-section database for brown dwarf and giant exoplanet atmospheres. Astrophys. J. Suppl. Ser. 254, 34 (2021).
Schneider, A. D. et al. Exploring the deep atmospheres of HD 209458b and WASP-43b using a non-gray general circulation model. Astron. Astrophys. 664, A56 (2022).
Mollière, P. et al. petitRADTRANS. a Python radiative transfer package for exoplanet characterization and retrieval. Astron. Astrophys. 627, A67 (2019).
Chubb, K. L. et al. The ExoMolOP database: cross sections and k-tables for molecules of interest in high-temperature exoplanet atmospheres. Astron. Astrophys. 646, A21 (2021).
Polyansky, O. L. et al. ExoMol molecular line lists XXX: a complete high-accuracy line list for water. Mon. Not. R. Astron. Soc. 480, 2597–2608 (2018).
Yurchenko, S. N., Amundsen, D. S., Tennyson, J. & Waldmann, I. P. A hybrid line list for CH4 and hot methane continuum. Astron. Astrophys. 605, A95 (2017).
Yurchenko, S. N., Mellor, T. M., Freedman, R. S. & Tennyson, J. ExoMol line lists—XXXIX. Ro-vibrational molecular line list for CO2. Mon. Not. R. Astron. Soc. 496, 5282–5291 (2020).
Coles, P. A., Yurchenko, S. N. & Tennyson, J. ExoMol molecular line lists—XXXV. a rotation–vibration line list for hot ammonia. Mon. Not. R. Astron. Soc. 490, 4638–4647 (2019).
Li, G. et al. Rovibrational line lists for nine isotopologues of the CO molecule in the X1Σ+ ground electronic state. Astrophys. J. Suppl. Ser. 216, 15 (2015).
Azzam, A. A. A., Tennyson, J., Yurchenko, S. N. & Naumenko, O. V. ExoMol molecular line lists—XVI. The rotation-vibration spectrum of hot H2S. Mon. Not. R. Astron. Soc. 460, 4063–4074 (2016).
Barber, R. J. et al. ExoMol line lists—III. \n improved hot rotation-vibration line list for HCN and HNC. Mon. Not. R. Astron. Soc. 437, 1828–1835 (2014).
Sousa-Silva, C., Al-Refaie, A. F., Tennyson, J. & Yurchenko, S. N. ExoMol line lists—VII. the rotation–vibration spectrum of phosphine up to 1500 K. Mon. Not. R. Astron. Soc. 446, 2337–2347 (2014).
Wende, S., Reiners, A., Seifahrt, A. & Bernath, P. F. CRIRES spectroscopy and empirical line-by-line identification of FeH molecular absorption in an M dwarf. Astron. Astrophys. 523, A58 (2010).
Piskunov, N. E., Kupka, F., Ryabchikova, T. A., Weiss, W. W. & Jeffery, C. S. VALD: the Vienna Atomic Line Data Base. Astron. Astrophys. Suppl. 112, 525 (1995).
Dalgarno, A. & Williams, D. A. Rayleigh scattering by molecular hydrogen. Astrophys. J. 136, 690–692 (1962).
Chan, Y. M. & Dalgarno, A. The refractive index of helium. Proc. Phys. Soc. 85, 227–230 (1965).
Richard, C. et al. New section of the HITRAN database: collision-induced absorption (CIA). J. Quant. Spectrosc. Radiat. Transf. 113, 1276–1285 (2012).
Hoskins, B. & Simmons, A. A multi-layer spectral model and the semi-implicit method. Q. J. R. Meteorol. Soc. 101, 637–655 (1975).
Menou, K. & Rauscher, E. Atmospheric circulation of hot Jupiters: a shallow three-dimensional model. Astrophys. J. 700, 887–897 (2009).
Rauscher, E. & Menou, K. Three-dimensional modeling of hot jupiter atmospheric flows. Astrophys. J. 714, 1334 (2010).
Rauscher, E. & Menou, K. A general circulation model for gaseous exoplanets with double-gray radiative transfer. Astrophys. J. 750, 96 (2012).
Rauscher, E. & Kempton, E. M. The atmospheric circulation and observable properties of non-synchronously rotating hot Jupiters. Astrophys. J. 790, 79 (2014).
May, E. M. & Rauscher, E. From super-Earths to mini-Neptunes: implications of a surface on atmospheric circulation. Astrophys. J. 893, 161 (2020).
Beltz, H. et al. Magnetic drag and 3D effects in theoretical high-resolution emission spectra of ultrahot Jupiters: the case of WASP-76b. Astron. J. 164, 140 (2022).
Toon, O. B., McKay, C., Ackerman, T. & Santhanam, K. Rapid calculation of radiative heating rates and photodissociation rates in inhomogeneous multiple scattering atmospheres. J. Geophys. Res. Atmos. 94, 16287–16301 (1989).
Gao, P. et al. Aerosol composition of hot giant exoplanets dominated by silicates and hydrocarbon hazes. Nat. Astron. 4, 951–956 (2020).
Zhang, J., Kempton, E. M. R. & Rauscher, E. Constraining hot Jupiter atmospheric structure and dynamics through Doppler-shifted emission spectra. Astrophys. J. 851, 84 (2017).
Malsky, I. et al. Modeling the high-resolution emission spectra of clear and cloudy nontransiting hot Jupiters. Astrophys. J. 923, 62 (2021).
Mendonça, J. M., Grimm, S. L., Grosheintz, L. & Heng, K. THOR: a new and flexible global circulation model to explore planetary atmospheres. Astrophys. J. 829, 115 (2016).
Deitrick, R. et al. THOR 2.0: major improvements to the open-source general circulation model. Astrophys. J. Suppl. Ser. 248, 30 (2020).
Tomita, H. & Satoh, M. A new dynamical framework of nonhydrostatic global model using the icosahedral grid. Fluid Dyn. Res. 34, 357–400 (2004).
Mendonça, J. M. Mass transport in a moist planetary climate model. Astron. Astrophys. 659, A43 (2022).
Mendonça, J. M. & Buchhave, L. A. Modelling the 3D climate of Venus with OASIS. Mon. Not. R. Astron. Soc. 496, 3512–3530 (2020).
Shao, W. D., Zhang, X., Mendonça, J. & Encrenaz, T. Local-time dependence of chemical species in the Venusian mesosphere. Planet. Sci. J. 3, 3 (2022).
Deitrick, R. et al. The THOR + HELIOS general circulation model: multiwavelength radiative transfer with accurate scattering by clouds/hazes. Mon. Not. R. Astron. Soc. 512, 3759–3787 (2022).
Tsai, S.-M. et al. Toward consistent modeling of atmospheric chemistry and dynamics in exoplanets: validation and generalization of the chemical relaxation method. Astrophys. J. 862, 31 (2018).
Malik, M. et al. HELIOS: an open-source, GPU-accelerated radiative transfer code for self-consistent exoplanetary atmospheres. Astron. J. 153, 56 (2017).
Charnay, B. et al. A survey of exoplanet phase curves with Ariel. Exp. Astron. 53, 417–446 (2022).
Mendonça, J. M., Read, P. L., Wilson, C. F. & Lee, C. A new, fast and flexible radiative transfer method for Venus general circulation models. Planet. Space Sci. 105, 80–93 (2015).
Yurchenko, S. N. & Tennyson, J. ExoMol line lists—IV. The rotation–vibration spectrum of methane up to 1500 K. Mon. Not. R. Astron. Soc. 440, 1649–1661 (2014).
Yurchenko, S. N., Barber, R. J. & Tennyson, J. A variationally computed line list for hot NH3. Mon. Not. R. Astron. Soc. 413, 1828–1834 (2011).
Harris, G. J., Tennyson, J., Kaminsky, B. M., Pavlenko, Y. V. & Jones, H. R. A. Improved HCN/HNC linelist, model atmospheres and synthetic spectra for WZ Cas. Mon. Not. R. Astron. Soc. 367, 400–406 (2006).
Rothman, L. S. et al. HITEMP, the high-temperature molecular spectroscopic database. J. Quant. Spectrosc. Radiat. Transf. 111, 2139–2150 (2010).
Rothman, L. S. et al. The HITRAN2012 molecular spectroscopic database. J. Quant. Spectrosc. Radiat. Transf. 130, 4–50 (2013).
Draine, B. T. Physics of the Interstellar and Intergalactic Medium (Princeton Univ. Press, 2011).
Stock, J. W., Kitzmann, D., Patzer, A. B. C. & Sedlmayr, E. FastChem: a computer program for efficient complex chemical equilibrium calculations in the neutral/ionized gas phase with applications to stellar and planetary atmospheres. Mon. Not. R. Astron. Soc. 479, 865–874 (2018).
Gandhi, S. & Madhusudhan, N. Retrieval of exoplanet emission spectra with HyDRA. Mon. Not. R. Astron. Soc. 474, 271–288 (2018).
Feroz, F., Hobson, M. P. & Bridges, M. MULTINEST: an efficient and robust Bayesian inference tool for cosmology and particle physics. Mon. Not. R. Astron. Soc. 398, 1601–1614 (2009).
Buchner, J. et al. X-ray spectral modelling of the AGN obscuring region in the CDFS: Bayesian model selection and catalogue. Astron. Astrophys. 564, A125 (2014).
Skilling, J. Nested sampling for general Bayesian computation. Bayesian Anal. 1, 833–859 (2006).
Gandhi, S., Madhusudhan, N. & Mandell, A. H- and dissociation in ultra-hot Jupiters: a retrieval case study of WASP-18b. Astron. J. 159, 232 (2020).
Piette, A. A. A. & Madhusudhan, N. Considerations for atmospheric retrieval of high-precision brown dwarf spectra. Mon. Not. R. Astron. Soc. 497, 5136–5154 (2020).
Piette, A. A. A., Madhusudhan, N. & Mandell, A. M. HyDRo: atmospheric retrieval of rocky exoplanets in thermal emission. Mon. Not. R. Astron. Soc. 511, 2565–2584 (2022).
Gandhi, S., Madhusudhan, N., Hawker, G. & Piette, A. HyDRA-H: simultaneous hybrid retrieval of exoplanetary emission spectra. Astron. J. 158, 228 (2019).
Gandhi, S. et al. Spatially resolving the terminator: variation of Fe, temperature, and winds in WASP-76 b across planetary limbs and orbital phase. Mon. Not. R. Astron. Soc. 515, 749–766 (2022).
Madhusudhan, N. & Seager, S. A temperature and abundance retrieval method for exoplanet atmospheres. Astrophys. J. 707, 24–39 (2009).
Taylor, J. et al. Understanding and mitigating biases when studying inhomogeneous emission spectra with JWST. Mon. Not. R. Astron. Soc. 493, 4342–4354 (2020).
Yurchenko, S. N., Tennyson, J., Barber, R. J. & Thiel, W. Vibrational transition moments of CH4 from first principles. Journal of Molecular Spectroscopy 291, 69–76 (2013).
Gordon, I. E. et al. The HITRAN2016 molecular spectroscopic database. J. Quant. Spectrosc. Radiat. Transf. 203, 3–69 (2017).
Underwood, D. S. et al. ExoMol molecular line lists—XIV. The rotation–vibration spectrum of hot SO2. Mon. Not. R. Astron. Soc. 459, 3890–3899 (2016).
Chubb, K. L. et al. Marvel analysis of the measured high-resolution rovibrational spectra of H232S. J. Quant. Spectrosc. Radiat. Transf. 218, 178–186 (2018).
Pinhas, A. & Madhusudhan, N. On signatures of clouds in exoplanetary transit spectra. Mon. Not. R. Astron. Soc. 471, 4355–4373 (2017).
Cubillos, P. E. & Blecic, J. The PyratBay framework for exoplanet atmospheric modeling: a population study of Hubble/WFC3 transmission spectra. Mon. Not. R. Astron. Soc. 505, 2675–2702 (2021).
Burrows, A., Marley, M. S. & Sharp, C. M. The near-infrared and optical spectra of methane dwarfs and brown dwarfs. Astrophys. J. 531, 438–446 (2000).
Kurucz, R. L. ATLAS: A Computer Program for Calculating Model Stellar Atmospheres SAO Special Report 309 (SAO, 1970).
Lecavelier Des Etangs, A., Pont, F., Vidal-Madjar, A. & Sing, D. Rayleigh scattering in the transit spectrum of HD 189733b. Astron. Astrophys. 481, L83–L86 (2008).
Tennyson, J. et al. The ExoMol database: molecular line lists for exoplanet and other hot atmospheres. J. Mol. Spectrosc. 327, 73–94 (2016).
Cubillos, P. E. An algorithm to compress line-transition data for radiative-transfer calculations. Astrophys. J. 850, 32 (2017).
Borysow, A., Jorgensen, U. G. & Fu, Y. High-temperature (1000–7000 K) collision-induced absorption of H2 pairs computed from the first principles, with application to cool and dense stellar atmospheres. J. Quant. Spectrosc. Radiat. Transf. 68, 235–255 (2001).
Parmentier, V. & Guillot, T. A non-grey analytical model for irradiated atmospheres. I. Derivation. Astron. Astrophys. 562, A133 (2014).
Blecic, J., Harrington, J. & Bowman, M. O. TEA: a code calculating thermochemical equilibrium abundances. Astrophys. J. Suppl. Ser. 225, 4 (2016).
Line, M. R. & Parmentier, V. The influence of nonuniform cloud cover on transit transmission spectra. Astrophys. J. 820, 78 (2016).
Benneke, B. Strict upper limits on the carbon-to-oxygen ratios of eight hot Jupiters from self-consistent atmospheric retrieval. Preprint at https://arxiv.org/abs/1504.07655 (2015).
Benneke, B. & Seager, S. How to distinguish between cloudy mini-Neptunes and water/volatile-dominated super-Earths. Astrophys. J. 778, 153 (2013).
Morley, C. V. et al. Neglected clouds in T and Y dwarf atmospheres. Astrophys. J. 756, 172 (2012).
ter Braak, C. J. F. & Vrugt, J. A. Differential evolution Markov chain with snooker updater and fewer chains. Stat. Comput. 18, 435–446 (2008).
Cubillos, P. et al. On correlated-noise analyses applied to exoplanet light curves. Astron. J. 153, 3 (2017).
Irwin, P. G. J. et al. The NEMESIS planetary atmosphere radiative transfer and retrieval tool. J. Quant. Spectrosc. Radiat. Transf. 109, 1136–1150 (2008).
Krissansen-Totton, J., Garland, R., Irwin, P. & Catling, D. C. Detectability of biosignatures in anoxic atmospheres with the James Webb Space Telescope: a TRAPPIST-1e case study. Astron. J. 156, 114 (2018).
Lacis, A. A. & Oinas, V. A description of the correlated-k distribution method for modelling nongray gaseous absorption, thermal emission, and multiple scattering in vertically inhomogeneous atmospheres. J. Geophys. Res. 96, 9027–9064 (1991).
Barstow, J. K. Unveiling cloudy exoplanets: the influence of cloud model choices on retrieval solutions. Mon. Not. R. Astron. Soc. 497, 4183–4195 (2020).
Irwin, P. G. J. et al. 2.5D retrieval of atmospheric properties from exoplanet phase curves: application to WASP-43b observations. Mon. Not. R. Astron. Soc. 493, 106–125 (2020).
Borysow, A. Collision-induced absorption coefficients of H2 pairs at temperatures from 60 K to 1000 K. Astron. Astrophys. 390, 779–782 (2002).
Benneke, B. et al. Water vapor and clouds on the habitable-zone sub-Neptune exoplanet K2-18b. Astrophys. J. Lett. 887, L14 (2019).
Pelletier, S. et al. Where is the water? Jupiter-like C/H ratio but strong H2O depletion found on τ Boötis b using SPIRou. Astron. J. 162, 73 (2021).
Stock, J. W., Kitzmann, D. & Patzer, A. B. C. FASTCHEM 2: an improved computer program to determine the gas-phase chemical equilibrium composition for arbitrary element distributions. Mon. Not. R. Astron. Soc. 517, 4070–4080 (2022).
Bell, K. L. & Berrington, K. A. Free-free absorption coefficient of the negative hydrogen ion. J. Phys. B 20, 801–806 (1987).
John, T. L. Continuous absorption by the negative hydrogen ion reconsidered. Astron. Astrophys. 193, 189–192 (1988).
Chubb, K. L., Tennyson, J. & Yurchenko, S. N. ExoMol molecular line lists—XXXVII. spectra of acetylene. Mon. Not. R. Astron. Soc. 493, 1531–1545 (2020).
McKemmish, L. K. et al. ExoMol molecular line lists—XXXIII. The spectrum of titanium oxide. Mon. Not. R. Astron. Soc. 488, 2836–2854 (2019).
McKemmish, L. K., Yurchenko, S. N. & Tennyson, J. ExoMol line lists—XVIII. The high-temperature spectrum of VO. Mon. Not. R. Astron. Soc. 463, 771–793 (2016).
Zhang, M., Chachan, Y., Kempton, E. M. R., Knutson, H. A. & Chang, W. H. PLATON II: new capabilities and a comprehensive retrieval on HD 189733b transit and eclipse data. Astrophys. J. 899, 27 (2020).
Line, M. R. & Yung, Y. L. A systematic retrieval analysis of secondary eclipse spectra. III. Diagnosing chemical disequilibrium in planetary atmospheres. Astrophys. J. 779, 3 (2013).
Ormel, C. W. & Min, M. ARCiS framework for exoplanet atmospheres—the cloud transport model. Astron. Astrophys. 622, A121 (2019).
Min, M., Ormel, C. W., Chubb, K., Helling, C. & Kawashima, Y. The ARCiS framework for exoplanet atmospheres: modelling philosophy and retrieval. Astron. Astrophys. 642, A28 (2020).
Chubb, K. L., Min, M., Kawashima, Y., Helling, C. & Waldmann, I. Aluminium oxide in the atmosphere of hot Jupiter WASP-43b. Astron. Astrophys. 639, A3 (2020).
Kreidberg, L. et al. A Precise water abundance measurement for the hot Jupiter WASP-43b. Astrophys. J. Lett. 793, L27 (2014).
Chubb, K. L. & Min, M. Exoplanet atmosphere retrievals in 3D using phase curve data with ARCiS: application to WASP-43b. Astron. Astrophys. 665, A2 (2022).
Blecic, J. et al. Spitzer observations of the thermal emission from WASP-43b. Astrophys. J. 781, 116 (2014).
Patrascu, A. T., Tennyson, J. & Yurchenko, S. N. ExoMol molecular linelists: VII: the spectrum of AlO. Mon. Not. R. Astron. Soc. 449, 3613–3619 (2015).
Tennyson, J. et al. The 2020 release of the ExoMol database: molecular line lists for exoplanet and other hot atmospheres. J. Quant. Spectrosc. Radiat. Transf. 255, 107228 (2020).
Barton, E. J., Yurchenko, S. N. & Tennyson, J. ExoMol molecular linelists—II. The ro-vibrational spectrum of SiO. Mon. Not. R. Astron. Soc. 434, 1469–1475 (2013).
Line, M. R., Teske, J., Burningham, B., Fortney, J. J. & Marley, M. S. Uniform atmospheric retrieval analysis of ultracool dwarfs. I. Characterizing benchmarks, GI570D and HD3651b. Astrophys. J. 807, 183 (2015).
Guillot, T. On the radiative equilibrium of irradiated planetary atmospheres. Astron. Astrophys. 520, A27 (2010).
Bell, T. J. et al. Products and models for "Nightside clouds and disequilibrium chemistry on the hot Jupiter WASP-43b". Zenodo https://doi.org/10.5281/zenodo.10525170 (2024).
Malik, M. et al. Self-luminous and irradiated exoplanetary atmospheres explored with HELIOS. Astron. J. 157, 170 (2019).
Harris, C. R. et al. Array programming with NumPy. Nature 585, 357–362 (2020).
Astropy Collaboration. Astropy: a community Python package for astronomy. Astron. Astrophys. 558, A33 (2013).
Astropy Collaboration. The Astropy Project: building an open-science project and status of the v2.0 core package. Astron. J. 156, 123 (2018).
Hunter, J. D. Matplotlib: a 2D graphics environment. Comput. Sci. Eng. 9, 90–95 (2007).
Acknowledgements
T.J.B. acknowledges funding support from the NASA Next Generation Space Telescope Flight Investigations program (now JWST) via WBS 411672.07.05.05.03.02. J.K.B. is supported by a UKRI/STFC Ernest Rutherford Fellowship (grant ST/T004479/1). J.B. acknowledges the support received in part from the NYUAD IT High Performance Computing resources, services, and staff expertise. E.D. acknowledges funding as a Paris Region Fellow through the Marie Sklodowska-Curie Action. M.Z. and B.V.R. acknowledge funding from the 51 Pegasi b Fellowship. A.D.F. acknowledges support from the NSF Graduate Research Fellowship Program. M.M., D.P. and L.W. acknowledge funding from the NHFP Sagan Fellowship Program. P.E.C. is funded by the Austrian Science Fund (FWF) Erwin Schroedinger Fellowship program J4595-N. K.L.C. acknowledges funding from STFC, under project number ST/V000861/1. L.D. acknowledges funding from the KU Leuven Interdisciplinary Grant (IDN/19/028), the European Union H2020-MSCA-ITN-2019 under grant no. 860470 (CHAMELEON) and the FWO research grant G086217N. O.V. acknowledges funding from the ANR project ‘EXACT’ (ANR-21-CE49-0008-01) and from the Centre National d’Études Spatiales (CNES). L.T. and B.C. acknowledge access to the HPC resources of MesoPSL financed by the Region Ile de France and the project Equip@Meso (reference ANR-10-EQPX-29-01) of the programme Investissements d’Avenir supervised by the Agence Nationale pour la Recherche.
Author information
Authors and Affiliations
Contributions
All authors played an appreciable role in one or more of the following: development of the original proposal, management of the project, definition of the target list and observation plan, analysis of the data, theoretical modelling, and preparation of this paper. Some specific contributions are listed as follows. N.M.B., J.L.B. and K.B.S. provided overall programme leadership and management. L.K. and N.C. coordinated the MIRI working group. L.K., V.P., K.B.S., D.K.S., E.M.-R.K., O.V. and P.E.C. made substantial contributions to the design of the programme and the observing proposal. K.B.S. generated the observing plan with input from the team. A.D., P.-O.L., R.C.C., A.L.C., G.M. and M.M. led or co-led working groups and/or contributed to important strategic planning efforts like the design and implementation of the pre-launch data challenges. P.E.C., D.K.S., R.C.C., P.-O.L. and J.B. generated simulated data for pre-launch testing of methods. L.K., T.J.B., M.T.R., N.C., V.P., A.A.A.P. and J.I.M. contributed substantially to the writing of this paper. T.J.B., N.C., M.Z. and E.D. contributed to the development of data analysis pipelines and/or provided the data analysis products used in this analysis that is, reduced the data, modelled the light curves, and/or produced the planetary spectrum. A.A.A.P. coordinated the atmospheric retrieval analysis with contributions from J.K.B., J.B., L.-P.C., M.Z., and K.L.C. M.T.R. coordinated the GCM results and interpretation with contributions from X.T., L.T., L.C., J.M.M. and I.M. T.J.B., N.C., P.E.C., J.B., L.-P.C. and M.H. generated figures for this paper. M.C.N., X.Z., B.V.R., J.K., M.L.-M., B.C., S.L.C. and R.H. provided substantial feedback to the paper, and G.M. and K.L.C. coordinated comments from all authors.
Corresponding author
Ethics declarations
Competing interests
The authors declare no competing interests.
Peer review
Peer review information
Nature Astronomy thanks the anonymous reviewer(s) for their contribution to the peer review of this work
Additional information
Publisher’s note Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Extended data
Extended Data Fig. 1 The underestimation of uncertainties as a function of spectral binning for the L168-9b commissioning observations.
a, The observed L168-9b transmission spectrum with 1σ error bars for spectrally unbinned data (grey circles), 0.15 μm bins (black squares), 0.5 μm bins (large red circles), and a 5-12 μm broadband bin (horizontal blue shaded region). The spectrum for wavelength pairs is not shown to avoid excessive clutter. b, The median of the transit depth uncertainties are shown with blue squares, while the observed scatter in the transmission spectrum is shown with orange circles. For unbinned data, the transmission spectrum shows about 2.5 × the scatter predicted by the fits to the individual light curves. Binning pairs of wavelengths reduces the level of underestimation of the scatter in the transmission spectrum, but considerable excess noise remains. Coarser binning schemes like the constant 0.15 μm bins used in the MIRI time-series observation commissioning paper29 or the 0.5 μm bins we use in this work further reduce the level of uncertainty underestimation.
Extended Data Fig. 2 A model-independent demonstration of the initial changes in flux for the WASP-43b observations.
a, The first 120 minutes of three of our spectroscopically binned light curves of WASP-43b (with 1σ uncertainties) showing the initial settling behaviour as a function of wavelength. A teal dashed line shows the amplitude of a -0.25% change in flux compared to the values around 120 minutes, and a magenta dotted line shows a +0.25% change. b, A summary of the ramp amplitudes, signs, and timescales for each of our wavelength bins (with 1σ uncertainties). The teal and magenta horizontal lines are the same as those in panel a to aid in translating between the two figures. At short wavelengths, the flux sharply drops by about 0.5% within the first 30 minutes and then largely settles but does continue to decrease with time. With increasing wavelength, the strength of this initial ramp decreases and eventually changes sign, becoming an upwards ramp. Within the ‘shadowed region’ (marked in red), the light curves show a very strong upwards ramp that takes much longer (greater than about 60 minutes) to appreciably decay. It is important to note that the data in this figure also includes a small amount of astrophysical phase variations which should result in a small increase in flux of less than 0.05% per hour.
Extended Data Fig. 3 Retrieved spectra from the six retrievals.
a, Median retrieved nightside spectra for the HyDRA (dark blue line), NEMESIS (dash-dotted gold line), and PyratBay (dashed magenta line) and their 1σ contour. The regions of higher water opacity are indicated by the purple shading at the top of the panel, with the observed rise in flux at 6.3 μm being caused by a drop in opacity. b, c, and d, Same as panel a for the evening terminator, dayside, and morning terminator respectively. e, f, g, and h, Same as panels a, b, c, and d, for the SCARLET (dashed red line), PLATON (blue line), and ARCiS (dash-dotted green line) retrievals.
Extended Data Fig. 4 Chemically-consistent atmospheric retrievals.
Same as Figure 4 but for retrievals assuming thermochemical-equilibrium abundances consistent with the pressure-temperature profiles. a, 1σ credible interval contours of the temperature profiles. The black curves show the predicted temperature profile from a 2D radiative-transport model46. The vertical bars show the range of pressures probed by the observations. b and c, probability posterior distributions for H2O and CH4 abundances, respectively. The shaded area for each curve denotes the 1σ credible interval of each posterior. The green and blue bars denote the abundances predicted by equilibrium and disequilibrium-chemistry models with solar abundances, respectively, at the pressures probed by the observations. Compared to the free-chemistry retrievals, the thermochemical-equilibrium retrievals on the nightside spectra produced worse fits, this is driven particularly by the higher amount of methane expected under equilibrium chemistry.
Extended Data Fig. 5 Retrieval contribution functions.
Contribution functions integrated over the data point spectral bins, at each phase (a-d), and for each retrieval framework. These curves show the range of pressures probed by the observation according to the atmospheric models. The enhanced opacity from the water band around 7-9 μm makes these wavelengths probe lower pressures and hence colder temperatures, whereas the rest of the observing window probes higher pressures and higher temperatures.
Extended Data Fig. 6 PyratBay clouds exploration.
a, Cloud species that condense in the temperature regime expected for the WASP-43b nightside. Dashed lines represent vapour pressure curves162 for each species assuming solar composition, while the coloured ranges denote the corresponding extent of the vapour pressure curves assuming 100 × sub- and super-solar atmospheric composition. The extent of the retrieved nightside contribution functions is shown in grey, and the extent of the retrieved temperature uncertainties is shown in light purple. The intersection between the contribution function and temperature ranges indicates the pressures at which we could observe cloud condensation and potentially detect their spectral features, if present in the observations. b, Panels display the retrieved posterior density plots for the explored cloud parameters of the TSC model (cloud number density, q*; effective particle size, reff; and the standard deviation of the log-normal distribution, \({\sigma }_{\log }\)) for the MnS clouds. The black vertical line denotes the parameter’s median value, while the extent of the purple region denotes the 1σ uncertainties, both given at the top left corner of the panel. Similar, fully non-constrained posteriors are retrieved for other explored cloud species, MgSiO3, ZnS, and KCl, suggesting the lack of observable spectral characteristics from clouds in the observed data.
Extended Data Fig. 7 A comparison of the retrieved temperature-pressure profiles to the GCM simulations.
Each of a-d shows the temperature profile retrieved by HyDRA, compared to the GCM simulations highlighted in Figure 3 and listed in Extended Data Table 1. The GCM temperature profiles are calculated at phases 0.0, 0.25, 0.5, and 0.75 by averaging over the visible hemisphere by viewing angle, to produce a one-dimensional profile that is comparable to the retrieved profile. The GCM simulations are generally warmer on the nightside than the retrieved temperatures; cloudy simulations emit from lower pressures and so match the observed lower brightness temperatures better (see the contribution functions in Extended Data Fig. 5).
Supplementary information
Supplementary Information
Supplementary Table 1 and Figs. 1 and 2.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Bell, T.J., Crouzet, N., Cubillos, P.E. et al. Nightside clouds and disequilibrium chemistry on the hot Jupiter WASP-43b. Nat Astron (2024). https://doi.org/10.1038/s41550-024-02230-x
Received:
Accepted:
Published:
DOI: https://doi.org/10.1038/s41550-024-02230-x
