
Abstract
Chemical probes are an indispensable tool for translating biological discoveries into new therapies, though are increasingly difficult to identify since novel therapeutic targets are often hard-to-drug proteins. We introduce FRASE-based hit-finding robot (FRASE-bot), to expedite drug discovery for unconventional therapeutic targets. FRASE-bot mines available 3D structures of ligand-protein complexes to create a database of FRAgments in Structural Environments (FRASE). The FRASE database can be screened to identify structural environments similar to those in the target protein and seed the target structure with relevant ligand fragments. A neural network model is used to retain fragments with the highest likelihood of being native binders. The seeded fragments then inform ultra-large-scale virtual screening of commercially available compounds. We apply FRASE-bot to identify ligands for Calcium and Integrin Binding protein 1 (CIB1), a promising drug target implicated in triple negative breast cancer. FRASE-based virtual screening identifies a small-molecule CIB1 ligand (with binding confirmed in a TR-FRET assay) showing specific cell-killing activity in CIB1-dependent cancer cells, but not in CIB1-depletion-insensitive cells.
Similar content being viewed by others
Introduction
Recent progress in molecular biology and genome-scale studies constantly increase our understanding of cellular processes and implication of individual proteins in disease1,2,3,4,5 thus extending the landscape of potential drug targets to harder-to-ligand proteins such as transcription factors, signaling or scaffolding proteins6,7,8,9,10. The global drug discovery pipeline is yet to adapt to such a shift. Screening collections used by pharmaceutical companies are mainly composed of ligands targeting historic target families, such as G-protein coupled receptors11 or protein kinases12. Several strategies provide a promising avenue to address the challenge by extending the screenable ligand space. The modern computing prowess enables an ever-increasing scale (up to a billion ligands) of structure-based virtual screening13,14,15. Alternatively, DNA-encoded libraries (DEL) push the boundaries of the accessible chemical space even further by allowing one-pot synthesis and screening of multiple billions of compounds16,17,18,19,20. Finally, generative neural networks21,22,23,24 promise access to virtually limitless chemistries. It is certain, however, that the above strategies come at a cost and bring their own set of problems. For instance, docking and scoring on novel targets are often subject to inacceptable false-positives rates25,26, multi-billion DEL screening requires a long and costly triage and hit confirmation process, and generative approaches may need a prohibitively time- and effort-consuming synthetic effort without necessarily producing a novel chemistry22,27,28. Hence, there is urgent need for both improving the existing strategies and developing new approaches to lead finding.
To further expand the lead finding toolkit, we introduce FRASE-bot, a technology platform for de novo construction of small-molecule ligands to a protein of interest directly in its binding pocket. The only input FRASE-bot needs to initiate the design process is a 3D structure of the protein of interest. It makes use of deep learning to distill 3D information relevant to the protein of interest from 3D structures of tens of thousands of ligand-protein complexes. FRASE-bot exploits the concept of FRAgments in Structural Environments (FRASE)29. FRASEs are structural descriptors blending the chemical and protein structure spaces. A single FRASE includes a chemically sound ligand fragment (e.g., a cycle with adjacent acyclic groups) of a protein-bound ligand and the nearby protein residues (within a distance of 4-5 Å). A comprehensive FRASE database was collected from publicly available sources of experimentally determined 3D structures of protein-ligand complexes29. Conceptually, FRASE-based design of a new ligand for a given protein involves two steps: (i) identification of structural environments, stored in the FRASE database, that match those in the protein of interest (this step results in an automated seeding of ligand fragments from the matching FRASEs into the target protein), and (ii) inspecting the seeded ligand fragments and combining them into synthetically tractable compounds. The concept of FRASE has been successfully applied to develop potent kinase-targeting in vivo antitumor agents29, though it was implemented with one important limitation: it only allowed exploiting information within a given protein family, hence precluding the ligand discovery for the majority of novel targets of interest belonging to understudied families. To overcome that limitation, we developed FRASE-based hit-finding robot (FRASE-bot), a computational platform to exploit the 3D structural and SAR data to identify ligands and their respective binding sites in the protein target. The key components of the platform include a FRASE screening algorithm and a machine learning (ML)-based triage of selected ligand fragments. FRASE-bot might be considered as a step toward a “virtual medicinal chemist” capable of conceiving ligands to novel targets based on an unbiased analysis of structural, chemical and biological data.
FRASE-bot was applied to identify potential agents against Triple Negative Breast Cancer (TNBC) by targeting Calcium- and Integrin-Binding Protein 1 (CIB1)30,31,32. Approximately one million new TNBC cases are diagnosed each year globally and 25% of patients die from this aggressive disease within 5 years of diagnosis33,34,35. Current TNBC treatment options are limited to surgery, radiation and systemic chemotherapy, which often fail due to inherent or acquired resistance. The need for new therapeutic approaches for TNBC is therefore urgent. CIB1 has been found to promote cell survival, growth and proliferation in cancer by regulating at least two prominent growth and oncogenic pathways, PI3K/AKT and MEK/ERK. CIB1, a ubiquitously expressed protein, despite its small size and lack of enzymatic activity, regulates a number of cellular processes including calcium signaling, migration, adhesion, proliferation, and survival36,37,38,39. The functional versatility is mediated by direct interactions with a broad range of binding partners, such as multiple integrin subtypes, serine/threonine kinases, p21-activated kinase 1 (PAK1), apoptosis signal-regulating kinase 1 (ASK1), and polo-like kinase 3 (PLK3)30. The molecular recognition of CIB1 by its binding partners was investigated by NMR, circular dichroism, X-ray crystallography, and sequence analyses. The secondary structure of CIB1 is composed of 10 α-helices, 8 of which form 4 EF-hands. EF-hand is a structural motif found in many proteins including all 4 members of the CIB subfamily (CIB1–CIB4), and closely related homologs, such as calmodulin, calcineurin B (CnB), Kv channel-interacting protein 1 (KChIP1), and Salt Overly Sensitive 3 (SOS3; Arabadopsis thaliana). The EF-hand motif is typically involved in the coordination of divalent cations, such as Ca2+ 40. Ca2+ seem to play an important role in CIB1 folding; apo-CIB1 is a molten globule, while Ca2+-bound CIB1 exhibits a more ordered structure31,41,42. Structural changes triggered by Ca2 open a large hydrophobic cleft on the surface of CIB1 that is be responsible for CIB1 binding to multiple integrin subtypes (as shown by a combination of NMR, mutagenesis, and biophysical assays) and putatively other binding partners43,44,45. Most recently, this same cleft was shown to bind (with a nanomolar affinity) artificial helical peptides identified by phage display46 and their cyclized derivatives47. However, neither endogenous nor exogenous non-peptide small-molecule CIB1 binders were identified yet (despite a significant high-throughput screening effort deployed). Hence, CIB1 is an ideal challenging target for a novel hit finding approach since it does not belong to a well-studied protein family.
In this work, we introduce FRASE-based hit-finding robot (FRASE-bot), to advance ligand identification for challenging therapeutic targets. We employ FRASE-bot to identify ligands for CIB1, a protein implicated in triple negative breast cancer. A small-molecule CIB1 ligand identified by FRASE-bot shows specific cell-killing activity in CIB1-dependent cancer cells, but not in CIB1-depletion-insensitive cells.
Results
FRASE-bot
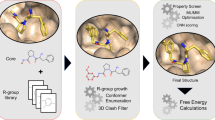
The FRASE-bot workflow includes the following steps: First, the FRASE database is screened to identify FRASEs with structural environments potentially matching those in the target protein. At this step, ligand fragments belonging to hit FRASEs are automatically seeded in the target protein. All potential hit FRASEs (typically thousands) are ranked using a “nativeness” score calculated by a neural network model. The model predicts whether a FRASE’s ligand fragment has a native-like pose within the target’s protein environment. Next, the top-scoring fragments (tens to hundreds) are exploited to obtain drug-like ligands for the target. Currently, two options exist: (i) build one or more pharmacophore models by analyzing densities of pharmacophoric features on the selected ligand fragments and use them to screen databases of commercially available compounds (this option was used in this study); or (ii) apply a generative neural network to enumerate novel ligand structures matching 2D and 3D constraints set by the poses of the seeded fragments. At the final selection step, the pharmacophore screening hits, or generated compounds may be submitted to various filters, such as computational assessment of the binding free-energy, e.g., by MM-PBSA48,49 or by a visual inspection of ligand poses. Eventually, selected ligands are purchased or synthesized and tested in relevant bioassays.
FRASE database screening
Finding whether a target protein has residue arrangements similar to those in the database composed of 184,963 FRASEs (see Methods for the database description) is a combinatorially challenging task. There is a large number of ways in which a set of 5 – 15 residues, could be picked from the target protein and there is a countless number of ways in which an environment picked from the target protein could be aligned with a given environment from the FRASE database. This makes a comprehensive enumeration and alignment of hundreds of environments in a target protein to hundreds of thousands environments stored in the FRASE database computationally prohibitive. To address the combinatorial challenge, all protein environments, both in the database and in the target protein, are encoded into a canonical string notation enabling their ultra-fast comparisons. Due to an oversimplified encoding, the screening step produces a significant number of irrelevant screening hits. However, at the next step of the workflow, all the hits are evaluated by a more thorough scoring method.
In the environment-encoding scheme, for each FRASE, we enumerate triplets of protein residues forming approximately equilateral triangles with sides between 8 Å and 12 Å (Fig. 1). Each residue in a triplet is represented by a many-hot 11-bit string expressing its physical properties—charge, H-bond donor/acceptor, aromaticity, size, and hydrophobicity (e.g., position #1 would be set to 1 if the residue has a positive ionizable group, 0 otherwise). Three positions are reserved for respectively size and hydrophobicity (e.g., all three positions are set to 1 for tryptophane and to 0 for glycine). Bitstrings for individual residues are then concatenated into a single fingerprint for the whole triplet. Six distinct fingerprints are being generated for each triplet to make triplet screening invariant to the order of residues. Typically, 6–15 qualifying triplets are being located in a single FRASE. Although the triplet fingerprint explicitly encodes only 1D information about the triplets, it also contains an implicit 3D information due to geometric constraints on the shape/size of the triangle formed by the triplet residues. Same procedure can be applied to a whole protein structure, i.e., that of the target protein, to typically produce ~350 triplets for a medium-size protein (233 triplets were enumerated for CIB1). The triplets enable a FRASE database screening process as shown in Fig. 1. First, every triplet of the target protein is compared with every triplet in the database. Second, matching triplets are used to align the respective FRASE with the protein of interest. Third, the ligand fragment from the matching FRASE is inserted into the target protein. Fourth, the ligand fragment is scored on its fitness to the target environment using a neural network model (see next section). One advantage of the FRASE screening approach is that it allows bypassing an explicit detection and comparison of ligand-binding sites, a non-trivial task, and an area of continued research50,51,52,53,54.

Finding whether the structural environment in a FRASE from the database matches a structural environment in the target protein occurs in four steps: (i) each residue triplet in the database’s FRASE is compared to each triplet in the target protein; (ii) the matching triplets are used to align the database’s FRASE to the protein; (iii) the ligand fragment is used to define the target’s FRASE; and (iv) the newly identified target’s FRASE is assessed using a machine-learned scoring function on whether it is a proper host for ligand fragment from the database’s FRASE.
FRASE scoring
After thousands FRASE hits were selected from the database using fast-search algorithms and ligand fragments seeded in the target protein, each of them is evaluated on their fitness to their new environments. Since it is impossible to experimentally measure contributions of ligand fragments into the potency of the respective ligands, here, the “fitness” is assessed through learning the distinction between interaction patterns in “true” FRASEs (i.e., FRASEs extracted from high-affinity ligand-protein complexes) and interaction patterns in decoy FRASEs. To this end, we applied a neural network model that learns most informative features from the ligand-protein interaction graph to predict the likelihood of whether a FRASE is “true”. The interaction graph is an extension of the chemical graph in which every pair of nearby (within 5 Å) ligand/protein atoms is connected by an interaction bond defined by the respective atom-centered pharmacophoric features (see Methods for the feature lists). A full set of interaction bonds represents a unique ligand-protein interaction signature. To ensure invariance of the interaction signature with respect to the atom numbering, it is transformed into an interaction fingerprint in which any given position encodes a count of interaction bonds of a particular type (e.g., hydrogen-bond donor – hydrogen-bond acceptor). The dimension of the fingerprint is m*n (377), where m (29) is the number of possible pharmacophoric features on the ligand side and n (13) is the number of features on the protein side. The interaction fingerprint is fed to a fully connected feedforward artificial neural network55 to predict whether an input signature “looks” like a true FRASE or a decoy. The network features two hidden layers (32 and 16 nodes) both employing a Rectified Linear Unit (ReLU) activation function56 and an output layer activated by a sigmoid function57, appropriate for binary classification tasks. It was trained using the backpropagation algorithm57 with a binary cross-entropy loss function58 and the ADAM optimizer59, over 500 epochs and a batch size of 50. The training set for this neural network model consists of a set of 38,791 true FRASEs randomly selected from the database and a set of 77,582 decoys. The decoys were produced by randomly swapping ligand fragments between true FRASEs. The trained models were validated by making predictions for the remaining 146,172 true FRASEs and 509,184 decoys.
Pharmacophore model and screening
To quickly and cost-effectively test the relevance of the fragments seeded in the target protein, we opted for exploiting the fragment-protein complexes in pharmacophore-based virtual screening. To this end, all seeded fragments were converted into pharmacophoric features (Aromatic, Hydrophobic (aliphatic), H-bond Acceptor, H-bond Donor, Positive Ionizable and Negative Ionizable). All features were clustered based on their types and 3D coordinates. Centroids of the most populous and dense clusters were used to compose pharmacophoric queries to search Molport (all in-stock compounds, 2017.2), a database of ~5.1 million commercially available compounds.
FRASE database screening and converting hit fragments into pharmacophore queries
Fast screening of the FRASE database was performed against a recent x-ray structure of CIB1 (PDB: 6OCX). This particular structure was chosen because it features a Ca2+-bound CIB1 in complex with an exogenous peptide46 and, hence, the protein is more likely to be pre-formed for ligand binding. The screening enabled identification of 5,362 fragments seeded in the structure’s multiple regions (Fig. 2A). Next, a filter passing only those fragments that do not “collide” with the protein (that is, whose atoms are at least 1 Å away from protein atoms) and that are sufficiently “buried” within the protein (that is, each ligand atom has an average of 5 protein atoms within 5 Å) reduced the number of fragments to 726. Finally, the fitness score threshold of 0.4 was applied to further reduce the number of fragments to 151 (Fig. 2B). Each of the 151 hit fragments were then converted into a set of pharmacophoric features (H-bond donor/acceptor (HBD/HBA), Ionizable positive/negative (Pos/Neg), Aromatic (Ar), and Hydrophobic aliphatic (Hyd)), resulting in a total of 398 features (Fig. 2D). All features were clustered using k-means algorithm (see Methods) by type and 3D coordinates into 76 clusters (with a maximum distance between cluster members of 3 Å). Centroids of the ten largest clusters (Fig. 2D) were considered as potential features for the pharmacophore model. Visual inspection of the protein structure suggested that centroids forming two groups (1–2 and 5-8) occupy two distinct nearby pockets that are close enough for a hypothetic ligand combining features from both groups to be a drug-like molecule. Eventually, centroids 1, 2, 6, and 8 were retained to compose a pharmacophore query consisting of two HBA and two Ar features (Fig. 2D). The centroids 9 and 10 were rejected because they are screened from the remaining clusters by a protein helix and hence no ligands would be able to simultaneously match features on 9/10 and features on any other centroid. We also dismissed centroids 4 and 7 since they are less buried than other centroids. Finally, the features on centroids 1, 2, 6, and 8 were retained to result in a spatially and compositionally balanced pharmacophore query for subsequent virtual screening.

A 5362 fragments (rendered in magenta sticks) were seeded into the CIB1 structure (rendered a cyan cartoon) by the initial triplet-based FRASE database screen; (B). Application of filters including collision count, buried’ness, and the fitness score further reduced the number of fragments to 151; (C). The 151 selected fragments were converted into 398 pharmacophoric features that were clustered into 76 feature clusters (rendered as colored spheres; HBA, red; HBD, light blue; Pos, blue; Ar, orange; Hyd, green). The 10 largest clusters (shown as larger spheres) were considered as potential components of the pharmacophore model. The final model used for screening consisted of 2 HBA and 2 Ar (clusters 1, 2, 6, and 8).
Virtual screening
The pharmacophoric query was used to screen the MolPort database. Schrodinger’s Phase algorithm60 was used to perform the pharmacophoric search, which yielded 190,320 hits. All pharmacophore hits were docked to the x-ray structure of CIB1 (PDB: 6OCX) using Glide method61 with standard precision. The docking grid was defined to comprise the four features of the pharmacophore query with a 5 Å margin. The Glide gscore values were distributed in a range from −1.4– −10.3 kcal/mol with a median of 5.6 kcal/mol. About 10,000 ligands (i.e., ~ 5% of the docked set) having gscore below − 7kcal/mol were selected for further triage. These docking hits were clustered to reduce the set of ligands for visual inspection throughout the triage process to top-scored cluster representatives (i.e., marking of a cluster representative for removal meant the removal of the whole cluster). K-means clustering on FCFP4 fingerprints with a maximum Tanimoto distance between cluster members of 0.60 resulted in 567 clusters. The triage process included visual inspection of 2D ligand structures and 3D ligand-protein complexes. First, 567 structures of cluster representatives were scrutinized computationally and visually for the presence of unwanted reactive groups, suitability for docking (e.g., ligands containing long aliphatic linkers were removed), and their lead potential (113 clusters were removed at this step). Second, the 3D poses were browsed for a visual assessment of the binding entropy (e.g., flexible ligands whose binding relies on solvent-exposed hydrogen bonds were removed) and ensuring that the docking pose aligns well with the pharmacophore query (~ 350 clusters were removed at this step). Next, up to 3 cluster representatives (depending on the cluster size) were selected from the clusters that survived the first two triage steps resulting in a set of ~ 200 candidates for purchase. The final triage step involved the refinement of the purchase list based on prices, shipping fees and available budget. Eventually, 56 compounds were purchased for experimental confirmation.
Experimental confirmation in a CIB1 TR-FRET displacement assay
Binding of the 56 purchased compounds was experimentally assessed in a time-resolved fluorescence energy transfer (TR-FRET) assay (see Fig. 3A and Supplementary data 1). Briefly, it serves as a displacement assay using an AlexaFluor-labeled cyclic CIB1-binding peptide and a Europium (Eu)-labeled Streptavidin donor for attachment to the AviTag biotinylated CIB1 protein (described previously in Puhl et al. and Haberman et al.47,62). Dose-response studies (in a 0.005–100 μM concentration range) identified 29 compounds with a dose-dependent response (that is, 52% of virtual hits selected for experimental testing), three of which had IC50 values below 10 μM (Fig. 3B). The three most promising compounds were retested in the dose-response TR-FRET assay numerous times (n = 8) as biological replicates and the averaged curves are shown in Fig. 3B. Several compounds showed rather high Hill slopes (>3), which is a potential indication of promiscuous or aggregating artifact activity, whereas UNC10245380 typically yielded Hill slopes within the acceptable range of 1.5–2.5. We compared the putative binding pose of UNC10245380 (obtained by Glide docking) with the x-ray structure of CIB1-bound linear peptide UNC10245109 (FWYGAMKALY) (Fig. 3C). UNC10245380 mostly overlaps with the dodecapeptide but occupies a significantly smaller volume. Such an overlap circumstantially supports the hypothetic docking pose, since otherwise the compound would not outcompete the peptide. The respective binding modes feature two similar interactions, hydrogen bonds with respectively Asn67 and Ser160 (though in the interaction with Ser160, the peptide is the hydrogen bond donor, while the small molecule is the hydrogen bond acceptor). On the other hand, UNC10245380 has an unmatched aromatic-aromatic stacking interaction with Phe98. Overall, the common features in binding modes of the peptide and non-peptide ligands suggest that the docking pose is plausible and might be used as a starting point for structure-based lead optimization (until proven wrong).

A CIB1 TR-FRET assay uses an AlexaFluor-labeled cyclic CIB1-binding peptide and a Europium (Eu)-labeled Streptavidin donor for attachment to the AviTag biotinylated CIB1 protein. B Three virtual hits showed IC50 below 10 µM in CIB1 TR-FRET assays (the IC50 values shown are means over the number of replicates ± standard deviation). C The x-ray structure of the peptide ligand UNC10245109 (magenta sticks) in complex with CIB1 (cyan sticks and ribbon) (6OCX [https://doi.org/10.2210/pdb6OCX/pdb]), superposed docking pose of UNC10245380 (green sticks) and the pharmacophore query. D A panel of CIB1 depletion-sensitive (MDA468, MDA436, BT549) and -insensitive (MDA231 and MDA453) TNBC cells treated with respectively DMSO vehicle or 30 µM UNC10245380 (UNC5380) for 24 h. Cell death was assessed by trypan blue exclusion. UNC5380 selectively kills CIB1 depletion-sensitive TNBC cells. Results are expressed as the mean % of dead cells from adherent and floating cell populations in 3 independent experiments. Error bars correspond to standard errors of the mean (SEM). Source data are provided as a Source Data file.
Additionally, 24 analogs of UNC10245380 were purchased from commercial sources and tested in this TR-FRET assay (see Supplementary data 1). Ten of 24 compounds showed robust dose-dependent response in low-micromolar range (three showed IC50 < 10 µM), but none yielded dramatic improvement of potency, and therefore a diverse set of 15 compounds from the initial hit list with strong dose-dependent response in TR-FRET was advanced to cellular assays.
CIB1 hit selectively target CIB1-dependent cancer cells
Previous studies showed that CIB1 depletion induces cell death and inhibition of CIB1-dependent signaling in 8 of 11 of triple-negative breast cancer cell lines32. The remaining three cell lines were insensitive to CIB1 depletion and thus serve as important controls for compound off-target effects. We selected two CIB1-depletion sensitive and one CIB1-depeltion insensitive TNBC cell lines to screen compounds for cell death activity. The three compounds having TR-FRET IC50 values below 10 µM were selected for evaluation in TNBC cell lines (see Supplementary data 1). One of the CIB1-sensitive cell lines (MDA-MB-461) was used for primary screening. Two of the selected compounds did not show promising cell killing activity in the MDA-MB-461 cell line and were not advanced to testing in MDA-MB-468 and MDA-MB-231 cell lines. However, one of the tested compounds, UNC10245380, showed significant cell killing activity in both CIB1-depletion-sensitive (MDA-MB-461, and MDA-MB-468) cell lines (Fig. 3D). Importantly, UNC10245380 showed no activity in the CIB1-depletion-insensitive (MDA-MB-231) cell line (Fig. 3D), strongly suggesting a lack of non-specific cellular toxicity. UNC10245380 also showed >90% dose-dependent cell death of MDA-468 TNBC cells over 48 h, indicating a more robust and rapid cell death than CIB1 shRNA depletion by 72 h. We next examined the effects of UNC10245380 on CIB1-dependent signaling events. Western blot analysis showed that UNC10245380 inhibited AKT and ERK phosphorylation in CIB1 depletion-sensitive, but not insensitive cell lines (see Supplementary Fig. 1). UNC10245380 also upregulates death receptor TRAIL-R1/D5 expression specifically in the three CIB1 depletion-sensitive cell lines that recapitulate our previous findings63 (Supplementary Fig. 1). Taken together, our data indicate that UNC10245380 closely parallels the CIB1 depletion cell death and signaling phenotypes in TNBC cells32,39,63, and thus provides an appropriate starting point for the future CIB1-targeted anticancer drug development.
Discussion
In our previous work29, the concept of fragments in structural environments was introduced and tested in a “model system”, that is, on protein targets with multiple known ligands and belonging to a well-established superfamily of protein kinases. Moreover, FRASE-based ligand design was performed stepwise, by visually assessing the choice of the next fragment and its attachment site. In this study, the FRASE-based ligand finding strategy was applied to Calcium and Integrin Binding protein 1 (CIB1), a target belonging to a small family of four proteins with the closest family member, Calcium and Integrin Binding protein 4 (CIB4), showing only 45% of sequence identity to CIB1. Furthermore, no known non-peptide small-molecule ligands have been reported to any of the CIB family members and their only function appears to be signaling through association with a number of other proteins43,45,64,65,66. Putatively, CIB1 does not interact with any endogenous small-molecule binder and does not have a pocket sculpted by nature for such an interaction. Previously, several unsuccessful attempts have been made by our groups to identify small-molecule CIB1 binders, including high-throughput screening of several collections of ~ 110 K commercially available compounds67. However, the only currently known CIB1 inhibitors are peptides identified from phage display screens44,46,47. This study demonstrates the high potential of the FRASE-based strategy in the intended setting, that is, applied to a difficult non-conventional target. We also made use of FRASE-bot in a recent Critical Assessment of Computational Hit-finding Experiments (CACHE) Challenge #168,69. In this competition, the participants were invited to apply their original toolkits to identify hits for LRRK2 WD40 repeat (WDR), a promising Parkinson’s target70,71,72. The mechanism by which LRRK2 WDR is implicated in disease, as well as whether and how it can bind a small-molecule ligand, is unknown, thus making it a particularly challenging, high-impact target. Only 7 participating workflows, out of 23, were able to identify any hits. In two rounds of the challenge, we identified 8 experimentally confirmed hits (of 85 submitted compounds, thus showing 9% success rate) with Kd ranging from 3 µM to 44 µM as determined by Surface Plasmon Resonance73.
On the technology side, FRASE-bot is a formalized semi-automated workflow enabling faster hit finding and leaving less room for a subjective human decision making. The quantum lip from the previously published system29, in which fragments were only exchanged between the aligned members of the same protein superfamily, has become possible due a triplet-based FRASE screening. Next, the ML-based scoring function enabled fragment ranking by inferring the latent similarity of their 3D poses to those of FRASEs in the FRASE database. Finally, cluster analysis of the fragments’ pharmacophoric features made possible a formal algorithm for a transition from a large set of top-scoring ligand fragments to 3D pharmacophore-based screening of millions of commercially available compounds. A possible future alternative to virtual screening might be through using the seeded fragments, along with respective 3D geometric constraints, as an input to ligand generators thus biasing them toward generating binders to the target protein.
Like any empirical method, FRASE-bot has its limitations and caveats. In particular, intrinsic to the approach are hypothetic assumptions throughout the workflow (e.g., that a ligand fragment would necessarily “like” a similar protein environment or that it is possible to learn the difference between true FRASEs and decoys). Because of these assumptions, FRASE-bot can only be used as an enrichment technique (i.e., the generated hit list is expected to show a significantly higher hit rate than a random selection from the same database) rather than a deterministic predictor. Nevertheless, this is a type of enrichment approach that is particularly useful to prescreen billion-scale screening collections, such as Enamine REAL74, for ligands containing seeded fragments, since substructure search is fast and computationally undemanding. It is also possible that the available protein structure is not in a ligand “friendly” conformation, in which case FRASE-bot would fail to identify hit compounds irrespectively of how efficient the method is.
Conceptually, FRASE-bot builds on the legacy of multiple earlier developments. For over a century, medicinal chemists dealt with finding optimal substituents for a given scaffold, a paradigm quantified through an additive approach by Free and Wilson in 1970 s75,76. In 1990 s, the advent of high-throughput x-ray and NMR technologies enabled structure-guided fragment-based discovery that explicitly exploited the concept of fragments “liking” specific protein environments77,78,79,80. In 2000 s, a broad family of approaches collectively termed chemogenomics or proteochemometrics experimented with various ways of using the protein sequence or structure to share SAR information between targets81,82,83,84,85. Finally, during the last decade, deep machine learning has shown potential to combine protein and ligand data for a fast prediction of protein-ligand binding affinity86,87,88,89.
Beyond FRASE-bot, its components may have a broader use in hit finding and drug design. For instance, the ligand fragments identified by FRASE screening can be used as an input to a conventional structure-based design through an incremental fragment growing or plugged as a structural constraint to a generative neural network. Furthermore, the module translating a large number of seeded ligand fragments into pharmacophoric queries for a large-scale screening of commercially available compounds can be applied to experimentally identified fragments, e.g., from the Diamond Light Source90. And the neural scoring function distinguishing between true FRASEs and decoys could be used to rank poses in structure-based virtual screening. Another important outcome of this study is a small-molecule CIB1 ligand with a demonstrated cellular effect. We expect it be a helpful probe to further exploit and validate CIB1 as a promising anti-cancer target. Later, UNC10245380 may be a source of inspiration for developing a CIB1-targeting drug or an in vivo probe.
Methods
FRASE database
The FRASE database was collected using data-processing protocols implemented in Pipeline Pilot91 X-ray structures of high-affinity ligand-protein complexes were imported from the Protein Data Bank (PDB)92. The PDB codes for high affinity complexes for drug-like ligands were obtained from BindingDB93 (retrieved in 05/2018). “High affinity” was defined as KD, Ki, IC50 or EC50 < 100 nM. Drug-likeness of the ligands was warranted by filters including Lipinski94, REOS95 and structural queries to remove peptides, inorganic and phosphorous compounds, as well as those containing highly reactive groups. This selection process resulted in 10,464 complexes involving 4724 unique ligands and 3,068 unique proteins. This dataset allowed us to generate a database 184,963 FRASES involving 51,060 unique ligand fragments. A FRASE was defined as a ligand fragment with all nearby protein residues (i.e., residues having at least one atom within 4.5 Å from the closest ligand’s atom). Ligands were fragmented using the “Enumerate Fragments” Pipeline Pilot component, allowing only single, non-cyclic bonds to be broken and keeping α-atoms attached to the cyclic fragments. Only fragments weighing between 50 and 300 Da were retained. All FRASEs, that is, ligand fragments with nearby protein residues, were saved to an SD file.
FRASE database screening
The screening protocols used in this study were implemented in Pipeline Pilot91 as a combination of standard components and custom Pilot scripts. The four key steps of the screening process include (i) enumerating triplets of protein residues and representing them as fingerprints, (ii) similarity search in the FRASE database for triplets similar to those in the target protein, (iii) alignment of the FRASEs containing hit triplets to the protein structure by the Cα atoms of the triplet’s residues, and (iv) making a target-based FRASE for further scoring. The “Align Molecules using Substructure” component is used for the alignment. After the hit FRASE from the database is aligned to the target protein, its ligand fragment can be used to create a new, target -based FRASE by cutting out the nearby residues of the target protein (i.e., residues having at least one atom within 4.5 Å from the closest ligand’s atom) and merging them with the ligand fragment.
All triplets of protein residues satisfying the geometric condition were enumerated in all FRASEs from the database and in the target protein. The geometric condition for a set of three residue to qualify as a triplet was for its respective Cα atoms to form an approximately equilateral triangle with edge lengths between 8 Å and 12 Å. Each residue in a triplet is represented by a many-hot 11-bit string expressing its physical properties—charge, H-bond donor/acceptor, aromaticity, size, and hydrophobicity. First 3 positions are reserved for size, next 3 for hydrophobicity, 1 for hydrogen bond acceptors, 1 for hydrogen bond donors, 1 for positive ionizable, 1 for negative ionizable, and 1 for aromatic. Bit strings for all 20 side chains are shown in Table 1.
FRASE scoring
FRASE scores were calculated using a neural network model for binary classification. The model is trained to learn the difference between true FRASEs and decoys. The decoys were generated by randomly shuffling ligand fragments between true FRASEs. FRASEs and decoys were represented by fixed-length feature vectors. Each feature corresponds to a distance-weighted pair of atom types centered, respectively, on a ligand and a protein atoms. The 29 ligand atom types are “Aromatic”, “Hetero”, “Halogen”, “Negative Ionizable”, “Positive Ionizable”, “H-bond Donor”, “H-bond Acceptor”, “Amide Nitrogen”, “Amine Nitrogen”, “Vinyl”, “Carboxylate Oxygen”, “Alcohol Oxygen”, “Nitro Oxygen”, “Nitro Nitrogen”, “Phosphate Oxygen”, “Sulfone Sulfur”, “Sulfoxide Sulfur”, “Enol Oxygen”, “Imine Nitrogen”, “Enamine Nitrogen”, “Aromatic Nitrogen”, “Aromatic Oxygen”, “Aromatic Sulfur”, “Aromatic Carbon”, “Aliphatic Carbon”, “F”, “Cl”, “Br”, and “I”. The 13 protein atom types are “Aromatic”, “NegativeIonizable”, “Positive Ionizable”, “H-bond Donor”, “H-bond Acceptor”, “Amide Nitrogen”, “Amine Nitrogen”, “Carboxylate Oxygen”, “Alcohol Oxygen”, “Imine Nitrogen”, “Aromatic Nitrogen”, “Aromatic Carbon”, and “Aliphatic Carbon”. Hence, the dimension of this interaction feature vector is 377. The value on a feature is calculated as follows:
where \({f}_{{mn}}^{l}\) is the \(l\)-th element of the feature vector corresponding to the pair of the ligand atom type \(m\) and the protein atom type \(n\), \({\delta }_{{mi}}\) is the Kronecker delta equal to 1 if the \(i\)-th atom is of type \(m\) (otherwise, 0), and \(w({d}_{{ij}})\) is the distance weighting factor equal to
where \({d}_{{ij}}\) is distance between the ligand atom \(i\) and the protein atom \(j\).
Pharmacophore queries and screening
The 3D pharmacophore queries for database screening were created using the Phase software96 with Maestro graphics interface. Individual pharmacophore features were created and manually placed at the centers of feature clusters (see “Pharmacophore model and screening” in the main text for context). The created features were merged into pharmacophore queries for screening in the “Merged hypotheses” mode. The ligand input file was in maegz format. Prior to screening, the Molport ligand collection (all in-stock compounds, 2017.2) was filtered through a modified Lipinski94 and REOS95 filters (the modified Lipinski rule allowed ligands of up 600 Da). The 3D ligand structures for 5,142,498 ligands from the MolPort database were generated by the Pipeline Pilot software91. The “Generate conformers during search” (up to 50) was applied to the input ligands. “PhaseScreenScore” was used to rank the screening hits.
Docking
Ligands were docked to CIB1 using the Glide program61 in standard docking precision (Glide SP). The binding region was defined by a 20 Å × 20 Å × 20 Å box centered on the geometric center of the pharmacophore model. A scaling factor of 0.8 was applied to the van der Waals radii. Default settings were used for all the remaining parameters. One pose per ligand was generated.
Virtual screening triage
Virtual hits ranked and selected based on the Phase Fitness score and Glide gscore were submitted to a hit triage process. First, the hit redundancy was reduced through retaining the best-scoring hits from clusters of similar compounds. Clustering was performed by a k-means method as implemented in the Pipeline Pilot software91. The inclusion criterion was 45% of Tanimoto similarity on ECFP4 fingerprints to the current cluster center. Second, binding poses of top-ranked non-redundant hits were visually inspected to remove poses whose scores putatively underestimate the entropic penalty on binding. Finally, a fraction of hits from the final list was eliminated based on pricing and availability criteria.
TR-FRET assay
For the TR-FRET tracer molecule, UNC10245204 (a cyclic peptide -S-Ac-YTTPIWNIRFC-NH2 described in ref. 47) was synthesized with an N-terminal cysteine to facilitate conjugation with maleimide AlexaFluor 647 (Thermo Fisher Scientific; Alexa647-CIB1-peptide). Compounds were dispensed into 384-well plates using a Mosquito HTS nanoliter instrument (TTP LABTech) as 3-fold serial dilutions (100x in DMSO, 0.1 μL) for final concentrations ranging from 100 μM to 0.5 nM. Biotinylated CIB1 was diluted to a final concentration of 3 nM in assay buffer (20 mM) TRIS pH 7.5, 150 mM NaCl, 1 mM CaCl, 1 mM CHAPS, and 1 mM DTT (added fresh each time), and 5 μL of diluted protein was added to the wells of the assay plate using a Multidrop Combi Reagent Dispenser (Thermo Scientific) and incubated at room temperature for 20 min. 5 μL detection solution containing 2 nM Lance Eu-Streptavidin (Perkin Elmer) and 30 nM Alexa647-CIB1-phage peptide diluted in assay buffer was added to the wells and incubated 30–60 min at room temperature protected from light. TR-FRET signals were measured using an Envision Multilabel Plate Reader (PerkinElmer; Eu excitation 320 nm, Eu emission 615 nm, Alexa dye emission 665 nm). TR-FRET signal is measured as the ratio 665 nm/615 nm, and percent inhibition was calculated using two sets of control wells; biotinylated CIB1 and detection solution in the presence (100% inhibition, positive control) or absence (0% inhibition, negative control) of CIB1 inhibitor. Inhibition curves were analyzed using a four-parameter non-linear curve fit using ScreenAble software, and the mean and standard deviation were calculated. Publication curves were averaged and fit with a four-parameter non-liner curve fit using GraphPad Prism.
Cellular assay
Human triple-negative cell lines MDA-MB-468, MDA-MB-436, MDA-MB-231, and BT-549 were cultured in Dulbecco’s modified eagle medium (DMEM, Gibco) supplemented with 10% fetal bovine serum and 1% non-essential amino acids (Gibco) at 5% CO2 and 37 °C. BT549 and MDA-436 media was also supplemented with 10 µg/ml insulin (Gibco). For cell death studies, each cell line was plated at a density of 1.5 × 105 cells/well. After 24 h, the media was replaced with 1.5 mL of media containing 30 μM of compound or 1% DMSO vehicle and incubated and additional 24–48 h. Floating and adherent cell populations were harvested and cell death quantified by Trypan blue exclusion and expressed as the mean percentage of dead cells (i.e., trypan blue positive) from both floating and adherent total cell populations. Statistical analysis from 2 separate experiments was performed using GraphPad Prism software.
Reporting summary
Further information on research design is available in the Nature Portfolio Reporting Summary linked to this article.
Data availability
The input/output files generated by the Pipeline Pilot workflow are shared as a Mendeley data set (https://doi.org/10.17632/9yn47cy5jv.1). A spreadsheet with TR-FRET data for 56 compounds selected by virtual screening, as well as for 24 compounds resulting from the SAR-by-catalog study is shared as a Supplementary data 1. Source data for the figures are provided with this paper. Source data are provided with this paper.
Code availability
The source code used to perform the current study is shared as a Supplementary archive file and through the GitHub repository https://github.com/kireevlab/FRASE-bot-Pipeline-Pilot97. The latest version of FRASE-bot implemented as Python code is available at https://github.com/kireevlab/FRASE-bot-RDKit98.
References
Gaudet, P. et al. neXtProt: organizing protein knowledge in the context of human proteome projects. J. Proteome Res. 12, 293–298 (2013).
Omenn, G. S. et al. Progress on identifying and characterizing the human proteome: 2019 metrics from the HUPO human proteome project. J. Proteome Res. 18, 4098–4107 (2019).
Uhlén, M. et al. Tissue-based map of the human proteome. Science (1979) 347, 6220 (2015).
Cafarelli, T. M. et al. Mapping, modeling, and characterization of protein–protein interactions on a proteomic scale. Curr. Opin. Struct. Biol. 44, 201–210 (2017).
Carter, A. J. et al. Target 2035: probing the human proteome. Drug Discov. Today 24, 2111–2115 (2019).
Bushweller, J. H. Targeting transcription factors in cancer—from undruggable to reality. Nat. Rev. Cancer 19, 611–624 (2019).
Lu, H. et al. Recent advances in the development of protein–protein interactions modulators: mechanisms and clinical trials. Signal Transduct. Target Ther. 5, 1–23 (2020).
Enz, R. Metabotropic glutamate receptors and interacting proteins: evolving drug targets. Curr. Drug Targets 13, 145–156 (2012).
Cui, T., Zhang, L., Wang, X. & He, Z.-G. Uncovering new signaling proteins and potential drug targets through the interactome analysis of Mycobacterium tuberculosis. BMC Genom. 10, 118 (2009).
Neubig, R. R. & Siderovski, D. P. Regulators of G-protein signalling as new central nervous system drug targets. Nat. Rev. Drug Discov. 1, 187–197 (2002).
Hauser, A. S., Attwood, M. M., Rask-Andersen, M., Schiöth, H. B. & Gloriam, D. E. Trends in GPCR drug discovery: new agents, targets and indications. Nat. Rev. Drug Discov. 16, 829–842 (2017).
Attwood, M. M., Fabbro, D., Sokolov, A. V., Knapp, S. & Schiöth, H. B. Trends in kinase drug discovery: targets, indications and inhibitor design. Nat. Rev. Drug Discov. 20, 839–861 (2021).
Gorgulla, C. et al. An open-source drug discovery platform enables ultra-large virtual screens. Nature 580, 663–668 (2020).
Lyu, J. et al. Ultra-large library docking for discovering new chemotypes. Nature 566, 224–229 (2019).
Gentile, F. et al. Deep docking: a deep learning platform for augmentation of structure based drug discovery. ACS Cent. Sci. 6, 939–949 (2020).
Neri, D. & Lerner, R. A. DNA-encoded chemical libraries: a selection system based on endowing organic compounds with amplifiable information. Annu Rev. Biochem. 87, 479–502 (2018).
Decurtins, W. et al. Automated screening for small organic ligands using DNA-encoded chemical libraries. Nat. Protoc. 11, 764–780 (2016).
Franzini, R. M. & Randolph, C. Chemical space of DNA-encoded libraries. J. Med. Chem. 59, 6629–6644 (2016).
Yuen, L. H. et al. A focused DNA-encoded chemical library for the discovery of inhibitors of NAD + -dependent enzymes. J. Am. Chem. Soc. 141, 5169–5181 (2019).
Satz, A. L. What do you get from DNA-encoded libraries? ACS Med. Chem. Lett. 9, 408–410 (2018).
Schneider, P. et al. Rethinking drug design in the artificial intelligence era. Nat. Rev. Drug Discov. 19, 353–364 (2019).
Gupta, A. et al. Generative recurrent networks for de novo drug design. Mol. Inf. 37, 1700111 (2018).
Zhavoronkov, A. et al. Deep learning enables rapid identification of potent DDR1 kinase inhibitors. Nat. Biotechnol. 37, 1038–1040 (2019).
Popova, M., Isayev, O. & Tropsha, A. Deep reinforcement learning for de novo drug design. Sci. Adv. 4, eaap7885 (2018).
Zev, S. et al. Benchmarking the ability of common docking programs to correctly reproduce and score binding modes in SARS-CoV-2 protease Mpro. J. Chem. Inf. Model 61, 2957–2966 (2021).
Walters, W. P., Stahl, M. T. & Murcko, M. A. Virtual screening–an overview. Drug Discov. Today 3, 160–178 (1998).
Meyers, J., Fabian, B. & Brown, N. De novo molecular design and generative models. Drug Discov. Today 26, 2707–2715 (2021).
Grebner, C., Matter, H., Plowright, A. T. & Hessler, G. Automated de novo design in medicinal chemistry: which types of chemistry does a generative neural network learn? J. Med. Chem. 63, 8809–8823 (2020).
Da, C. et al. Data-driven construction of antitumor agents with controlled polypharmacology. J. Am. Chem. Soc. 141, 15700–15709 (2019).
Leisner, T. M., Freeman, T. C., Black, J. L. & Parise, L. V. CIB1: a small protein with big ambitions. FASEB J. 30, 2640–2650 (2016).
Gentry, H. R. et al. Structural and biochemical characterization of CIB1 delineates a new family of EF-hand-containing proteins. J. Biol. Chem. 280, 8407–8415 (2005).
Black, J. L. et al. CIB1 depletion impairs cell survival and tumor growth in triple-negative breast cancer. Breast Cancer Res. Treat. 152, 337–346 (2015).
Stovgaard, E. S., Nielsen, D., Hogdall, E. & Balslev, E. Triple negative breast cancer–prognostic role of immune-related factors: a systematic review. Acta Oncol. (Madr.) 57, 74–82 (2018).
Yao, H. et al. Triple-negative breast cancer: is there a treatment on the horizon? Oncotarget 8, 1913 (2017).
Collignon, J., Lousberg, L., Schroeder, H. & Jerusalem, G. Triple-negative breast cancer: treatment challenges and solutions. Breast Cancer.: Targets Ther. 8, 93 (2016).
Yuan, W. et al. CIB1 is an endogenous inhibitor of agonist-induced integrin αIIbβ3 activation. J. Cell Biol. 172, 169–175 (2006).
Naik, M. U. & Naik, U. P. Contra‐regulation of calcium‐ and integrin‐binding protein 1‐induced cell migration on fibronectin by PAK1 and MAP kinase signaling. J. Cell Biochem. 112, 3289–3299 (2011).
NAIK, M. U. et al. CIB1 deficiency results in impaired thrombosis: the potential role of CIB1 in outside‐in signaling through integrin αIIbβ3. J. Thromb.Haemost. 7, 1906–1914 (2009).
Leisner, T. M., Moran, C., Holly, S. P. & Parise, L. V. CIB1 prevents nuclear GAPDH accumulation and non-apoptotic tumor cell death via AKT and ERK signaling. Oncogene 32, 4017–4027 (2013).
Grabarek, Z. Insights into modulation of calcium signaling by magnesium in calmodulin, troponin C and related EF-hand proteins. Biochim. Biophys. Acta 1813, 913–921 (2011).
Huang, H., Ishida, H., Yamniuk, A. P. & Vogel, H. J. Solution structures of Ca2 + -CIB1 and Mg2 + -CIB1 and their interactions with the platelet integrin αIIb cytoplasmic domain. J. Biol. Chem. 286, 17181–17192 (2011).
Yamniuk, A. P., Nguyen, L. T., Hoang, T. T. & Vogel, H. J. Metal ion binding properties and conformational states of calcium- and integrin-binding protein. Biochemistry 43, 2558–2568 (2004).
SHOCK, D. D. et al. Calcium-dependent properties of CIB binding to the integrin αIIb cytoplasmic domain and translocation to the platelet cytoskeleton. Biochem. J. 342, 729–735 (1999).
Freeman, T. C. et al. Identification of novel integrin binding partners for calcium and integrin binding protein 1 (CIB1): structural and thermodynamic basis of CIB1 promiscuity. Biochemistry 52, 7082–7090 (2013).
Barry, W. T. et al. Molecular basis of CIB binding to the integrin αIIb cytoplasmic domain. J. Biol. Chem. 277, 28877–28883 (2002).
Puhl, A. C. et al. Discovery and characterization of peptide inhibitors for calcium and integrin Binding Protein 1. ACS Chem. Biol. 15, 1505–1516 (2020).
Haberman, V. A. et al. Discovery and development of cyclic peptide inhibitors of CIB1. ACS Med. Chem. Lett. 12, 1832–1839 (2021).
Massova, I. & Kollman, P. Combined molecular mechanical and continuum solvent approach (MM-PBSA/GBSA) to predict ligand binding. Perspect. Drug Discov. Des. 18, 113–135 (2000).
Kuhn, B., Gerber, P., Schulz-Gasch, T. & Stahl, M. Validation and use of the MM-PBSA approach for drug discovery. J. Med. Chem. 48, 4040–4048 (2005).
An, J., Totrov, M. & Abagyan, R. Comprehensive identification of “druggable” protein ligand binding sites. Genome Inform. 15, 31–41 (2004).
Weisel, M., Proschak, E. & Schneider, G. PocketPicker: analysis of ligand binding-sites with shape descriptors. Chem. Cent. J. 1, 1–17 (2007).
Pu, L., Govindaraj, R. G., Lemoine, J. M., Wu, H.-C. & Brylinski, M. DeepDrug3D: Classification of ligand-binding pockets in proteins with a convolutional neural network. PLoS Comput. Biol. 15, e1006718 (2019).
Eguida, M. & Rognan, D. A computer vision approach to align and compare protein cavities: application to fragment-based drug design. J. Med Chem. 63, 7127–7142 (2020).
Naderi, M. et al. Binding site matching in rational drug design: algorithms and applications. Brief. Bioinform. 20, 2167–2184 (2019).
Rumelhart, D. E., McClelland, J. L. & PDP Research Group, C. Parallel Distributed Processing: Explorations in the Microstructure of Cognition. Vol. 1: Foundations 567 (MIT press, 1986).
Nair, V. & Hinton, G. E. Rectified linear units improve restricted Boltzmann machines. In Proc. 27th International Conference on Machine Learning (ICML-10) 807–814 (IEEE, 2010).
Rumelhart, D. E., Hinton, G. E. & Williams, R. J. Learning representations by back-propagating errors. Nature 323, 533–536 (1986).
Mao, A., Mohri, M. & Zhong, Y. Cross-entropy loss functions: theoretical analysis and applications. arXiv https://doi.org/10.48550/arXiv.2304.07288 (2023).
Kingma, D. P. & Ba, J. Adam: A method for stochastic optimization. arXiv https://doi.org/10.48550/arXiv.1412.6980 (2014).
Maestro Suite. Schrodinger LLC https://www.schrodinger.com/ (2021).
Friesner, R. A. et al. Glide: a new approach for rapid, accurate docking and scoring. 1. Method and assessment of docking accuracy. J. Med. Chem. 47, 1739–1749 (2004).
Puhl-Rubio, A. C. et al. Use of protein kinase–focused compound libraries for the discovery of new inositol phosphate kinase inhibitors. SLAS Discov. 23, 9 (2018).
Chung, A. H. et al. CIB1 depletion with docetaxel or TRAIL enhances triple-negative breast cancer cell death. Cancer Cell Int. 19, 26 (2019).
Haataja, L., Kaartinen, V., Groffen, J. & Heisterkamp, N. The Small GTPase Rac3 interacts with the integrin-binding protein CIB and promotes integrin αIIbβ3-mediated adhesion and spreading. J. Biol. Chem. 277, 8321–8328 (2002).
Fang, X.-D., Chen, C., Wang, Q., Gu, J.-X. & Chi, C.-W. The interaction of the calcium- and integrin-binding protein (CIBP) with the coagulation factor VIII. Thromb. Res. 102, 177–185 (2001).
Stabler, S. M., Ostrowski, L. L., Janicki, S. M. & Monteiro, M. J. A myristoylated calcium-binding protein that preferentially interacts with the alzheimer’s disease presenilin 2 protein. J. Cell Biol. 145, 1277–1292 (1999).
CICBDD. Chemical Compound Collection. https://cicbdd.web.unc.edu/resources/ (2023).
Ackloo, S. et al. CACHE (Critical assessment of computational hit-finding experiments): a public–private partnership benchmarking initiative to enable the development of computational methods for hit-finding. Nat. Rev. Chem. 6, 287–295 (2022).
Critical Assessment of Computational Hit-finding Experiments. Results of CACHE Challenge #1. https://cache-challenge.org/results-cache-challenge-1 (2024).
Zhang, P. et al. Crystal structure of the WD40 domain dimer of LRRK2. Proc. Natl Acad. Sci. USA 116, 1579–1584 (2019).
Galper, J., Kim, W. S. & Dzamko, N. LRRK2 and lipid pathways: implications for Parkinson’s disease. Biomolecules 12, 1597 (2022).
Taymans, J.-M. et al. Perspective on the current state of the LRRK2 field. NPJ Parkinsons Dis. 9, 104 (2023).
Schasfoort, R. B. M. Introduction to surface plasmon resonance. in Handbook of Surface Plasmon Resonance (eds Schasfoort, R. B. M.) 1–26 (The Royal Society of Chemistry, 2017).
Enamine REAL library.
Free, S. M. & Wilson, J. W. A mathematical contribution to structure-activity studies. J. Med. Chem. 7, 395–399 (1964).
Kubinyi, H. Free wilson analysis. Theory, applications and its relationship to Hansch analysis. Quant. Struct.‐Act. Relatsh. 7, 121–133 (1988).
Shuker, S. B., Hajduk, P. J., Meadows, R. P. & Fesik, S. W. Discovering high-affinity ligands for proteins: SAR by NMR. Science (1979) 274, 1531–1534 (1996).
Erlanson, D. A., Fesik, S. W., Hubbard, R. E., Jahnke, W. & Jhoti, H. Twenty years on: the impact of fragments on drug discovery. Nat. Rev. Drug Discov. 15, 605–619 (2016).
Lu, W. et al. Fragment-based covalent ligand discovery. RSC Chem. Biol. 21, 9230 (2021).
Talamas, F. X. et al. De novo fragment design: a medicinal chemistry approach to fragment-based lead generation. J. Med. Chem. 56, 3115–3119 (2013).
Sheinerman, F. B., Giraud, E. & Laoui, A. High affinity targets of protein kinase inhibitors have similar residues at the positions energetically important for binding. J. Mol. Biol. 352, 1134–1156 (2005).
Vieth, M. et al. Kinomics-structural biology and chemogenomics of kinase inhibitors and targets. Biochim. Biophys. Acta 243–257, 2004 (1697).
Kubinyi, H. Chemogenomics in drug discovery. In Chemical Genomics. Ernst Schering Research Foundation Workshop (eds. Jaroch, S., Weinmann, H.) 1–19 (Springer, Berlin, Heidelberg, 2006).
Vulpetti, A., Kalliokoski, T. & Milletti, F. Chemogenomics in drug discovery: computational methods based on the comparison of binding sites. Future Med. Chem. 4, 1971–1979 (2012).
van Westen, G. J. P., Wegner, J. K., Ijzerman, A. P., van Vlijmen, H. W. T. & Bender, A. Proteochemometric modeling as a tool to design selective compounds and for extrapolating to novel targets. Medchemcomm 2, 16–30 (2011).
Ragoza, M., Hochuli, J., Idrobo, E., Sunseri, J. & Koes, D. R. Protein–ligand scoring with convolutional neural networks. J. Chem. Inf. Model 57, 942–957 (2017).
Gomes, J., Ramsundar, B., Feinberg, E. N. & Pande, V. S. Atomic convolutional networks for predicting protein-ligand binding affinity. arXiv https://doi.org/10.48550/arXiv.1703.10603 (2017).
Feinberg, E. N. et al. PotentialNet for molecular property prediction. ACS Cent. Sci. 4, 1520–1530 (2018).
Wallach, I., Dzamba, M. & Heifets, A. AtomNet: A deep convolutional neural network for bioactivity prediction in structure-based drug discovery. arXiv https://doi.org/10.48550/arXiv.1510.02855 (2015).
Diamond Light Source. Diamond Light Source https://www.diamond.ac.uk/Home.html (2023).
Pipeline. Pilot: A Data Processing Software. https://www.geeksforgeeks.org/pilot-testing-in-software-testing/ (2020).
Deshpande, N. et al. The RCSB protein data bank: a redesigned query system and relational database based on the mmCIF schema. Nucleic Acids Res. 33, D233–D237 (2005).
Liu, T., Lin, Y., Wen, X., Jorissen, R. N. & Gilson, M. K. BindingDB: a web-accessible database of experimentally determined protein-ligand binding affinities. Nucleic Acids Res. 35, D198–D201 (2007).
Lipinski, C. A., Lombardo, F., Dominy, B. W. & Feeney, P. J. Experimental and computational approaches to estimate solubility and permeability in drug discovery and development settings. Adv. Drug Deliv. Rev. 23, 3–25 (1997).
Walters, W. P. & Murcko, M. A. Prediction of ‘drug-likeness’. Adv. Drug Deliv. Rev. 54, 255–271 (2002).
Dixon, S. L. et al. PHASE: a new engine for pharmacophore perception, 3D QSAR model development, and 3D database screening: 1. Methodology and preliminary results. J. Comput. Aided Mol. Des. 20, 647–671 (2006).
Kireev, D. & Glavatskikh, M. kireevlab/FRASE-bot-Pipeline-Pilot: In silico fragment-based discovery of CIB1-directed anti-tumor agents by FRASE-bot. Zenodo https://doi.org/10.5281/zenodo.11372285 (2021).
Wang, X. & Kireev, D. kireevlab/FRASE-bot-RDKit: In silico fragment-based discovery of CIB1-directed anti-tumor agents by FRASE-bot. Zenodo https://doi.org/10.5281/zenodo.11372361 (2023).
Acknowledgements
We thank all the members within the Center for Integrative Chemical Biology and Drug Discovery for advice and technical support. This work was supported by grant 5R01GM132299 from NIH, National Institute of General Medical Sciences (NIGMS) to D.K. We acknowledge the University of Missouri, Division of IT, Research Computing Support Services for the use of the computing resources.
Author information
Authors and Affiliations
Contributions
Methodology, Investigation, Analyses, Writing, & Editing: Y.A., M.G., J.L., X.W., J.N-D, B.H., T.M.L., K.H.P., and D.K.; Conceptualization, Writing, Review, Supervision, Resources, Project Administration: K.H.P. and D.K.
Corresponding authors
Ethics declarations
Competing interests
The authors declare no competing interests.
Peer review
Peer review information
Nature Communications thanks Gokul Das and the other, anonymous, reviewer(s) for their contribution to the peer review of this work. A peer review file is available.
Additional information
Publisher’s note Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Source data
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
An, Y., Lim, J., Glavatskikh, M. et al. In silico fragment-based discovery of CIB1-directed anti-tumor agents by FRASE-bot. Nat Commun 15, 5564 (2024). https://doi.org/10.1038/s41467-024-49892-9
Received:
Accepted:
Published:
DOI: https://doi.org/10.1038/s41467-024-49892-9
Comments
By submitting a comment you agree to abide by our Terms and Community Guidelines. If you find something abusive or that does not comply with our terms or guidelines please flag it as inappropriate.
