
Abstract
Relative binding free energy calculations have become an integral computational tool for lead optimization in structure-based drug design. Classical alchemical methods, including free energy perturbation or thermodynamic integration, compute relative free energy differences by transforming one molecule into another. However, these methods have high operational costs due to the need to perform many pairwise perturbations independently. To reduce costs and accelerate molecular design workflows, we present a method called λ-dynamics with bias-updated Gibbs sampling. This method uses dynamic biases to continuously sample between multiple ligand analogues collectively within a single simulation. We show that many relative binding free energies can be determined quickly with this approach without compromising accuracy. For five benchmark systems, agreement to experiment is high, with root mean square errors near or below 1.0 kcal mol−1. Free energy results are consistent with other computational approaches and within statistical noise of both methods (0.4 kcal mol−1 or less). Notably, large efficiency gains over thermodynamic integration of 18–66-fold for small perturbations and 100–200-fold for whole aromatic ring substitutions are observed. The rapid determination of relative binding free energies will enable larger chemical spaces to be more readily explored and structure-based drug design to be accelerated.
Similar content being viewed by others

Introduction
Relative binding free energy (RBFE) calculations have emerged as a promising tool for the lead optimization of small molecule pharmaceuticals1,2,3. In an RBFE calculation, a small molecule bound to a protein target is alchemically transformed into a different small molecule, such as an analog formed by modifying one or more functional groups of the lead compound. The relative difference in free energies of binding (ΔΔGbind) between the two molecules can then be calculated using a thermodynamic cycle (Fig. 1)4. Compared to methods such as molecular docking, RBFE calculations have shown significantly improved correlation between computed and experimental binding affinities, with errors of roughly 1 kcal mol−1 or less for state-of-the-art calculations5,6,7,8. Although too high to eliminate the need for experiment entirely, this degree of accuracy is low enough to separate compounds with stronger versus weaker binding affinities and efficiently prioritize molecules for experimental investigation9,10. Using stochastic simulations, Mobley and Klimovich quantified the effect that this computational prioritization can have on a drug discovery project. They estimate that RBFE calculations with an average of 1.0 kcal mol−1 of error to experiment can improve the odds of identifying a tenfold potency boost by a factor of 511. When optimizing lead compounds for other drug-like properties, RBFE calculations can also be used to filter out compound modifications that might negatively affect potency7.

Two ligands (L1 and L2) with different substituents (represented as a methyl group in blue or an iso-propyl group in red) are represented as bound to a protein (in gray) or unbound in solution. Relative binding free energies between L1 and L2 can be computed by alchemically transforming L1 into L2 in bound and unbound states.
While many methods of RBFE calculations exist, the most commonly used methods are free energy perturbation (FEP) or thermodynamic integration (TI) coupled with the multistate Bennett acceptance ratio (MBAR) free energy estimator12,13,14,15. With these methods, an alchemical coupling parameter, called λ, is used to alchemically transform one molecule into another. To ensure sufficient phase space overlap exists between λ states and to achieve convergence in computed free energy differences, many intermediate discrete λ states are also defined (typically 10–20) that span a range of λ values between 0 and 1, the two molecule end states of interest4,7,9. Molecular dynamics (MD) simulations are performed at each of these discrete λ states, λ values held constant for the duration of the simulation, and the MD trajectories are then postprocessed to calculate the final free energy difference. Though effective, FEP and TI calculations require considerable computational resources, are exclusively pairwise, and are inherently unable to evaluate more than one RBFE at a time. For example, in a typical FEP/TI experiment5,7,8,16, 11 discrete λ states may be used to model a single perturbation, requiring 11 MD trajectories of 5–20 ns per λ window to be run, which amounts to a total of 55–220 ns of simulation time for a single RBFE result6,16. Longer simulations or additional windows may be needed for more challenging perturbations, such as ring additions or polar-to-non-polar transformations17. Further compounding computational costs, recommended best practices for investigating large sets of multiple ligands with FEP/TI necessitates the use of redundant calculations to provide improved accuracy around closed perturbation cycles18,19,20. Although the recent adoption of running MD simulations on graphical processing units (GPUs) has accelerated computational throughput and facilitated routine employment of RBFE calculations on large, parallel high-performance computing (HPC) resources for drug discovery21,22,23, costs per RBFE calculation remain high.
Driven by the high cost of pairwise RBFE calculations, many groups have investigated alternative methods to perform RBFE calculations with the aim of achieving comparable accuracy with lower computational costs per computed RBFE. Non-equilibrium switching free energy calculations have seen renewed interest24,25,26,27. Mostly run in a pairwise manner, these calculations require only ca. 20–40 ns per transformation and are highly parallelizable24,27, making them good candidates for HPC or cloud computing. A variety of expanded ensemble methods have also grown in popularity28,29,30,31,32. λ-dynamics (λD)33,34, enveloping distribution sampling35,36,37, and λ-local elevation umbrella sampling methods38,39,40, to name a few, have all sought to calculate free energy differences between multiple thermodynamic states within a single calculation to increase efficiency through improved scalability.
In a conventional λD simulation, λ is treated as a continuous parameter and its value can change dynamically in conjunction with the coordinates of an MD simulation, using extended Lagrangian methods34,41. Sampling of multiple ligand end states or sampling of many substituents at two or more sites of substitution are both feasible with multisite λ-dynamics (MSλD) via holonomic constraints34,42. Hence, multiple RBFEs can be computed from a single λD simulation, lending large efficiency gains over conventional approaches. Recent benchmarks have shown that single-site perturbations can be performed with cost savings in the range of 3–5.4 times better than TI/MBAR6. Advantageously, sampling multiple ligand end states with λD also allows alchemical transitions to occur from one end state to any other end state—forming a connection network termed “strongly connected” in graph theory—without the need for redundant calculations to form cycle closure connections, as commonly performed for FEP/TI (Fig. 2)18,20. Over the past few years, a variety of developments have been introduced to expand the utility of λD for drug discovery, including an Adaptive Landscape Flattening (ALF) algorithm for automated bias determination41,43, a Potts model-based estimator for computing free energy differences and intersite couplings44, an accelerated GPU engine45, and an alternative λ sampling strategy using Gibbs sampling, a Markov chain Monte Carlo algorithm46,47. As discussed in-depth in “Methods”, this work builds upon this latter development of the discrete Gibbs sampler λ-dynamics (d-GSλD) method47.

a λD-based methods sample a strongly connected graph of ligand end states. Efficiency gains obtained with λD-based methods over traditional TI or FEP free energy methods originate from two key sources: (1) all physical and intermediate λ states are sampled within a single simulation (represented as solid lines) and (2) multiple ligands can be sampled simultaneously (represented as different colors). b TI or FEP methods sample a weakly connected graph via pairwise perturbations (commonly referred to as a “star map” when run without redundant calculations for cycle closure) and require many intermediate simulations to be run (represented as dashed lines).
To sample multiple ligands collectively within a single λD simulation, however, free energy barriers between ligand end states in λ-space must first be flattened. This can be accomplished by identifying and incorporating a variety of biasing potentials into a λD simulation41. These biases flatten intermediate free energy barriers and ensure ligand end states have equivalent free energies to facilitate rapid transitioning between end states. Though effective, a non-negligible amount of simulation time must be devoted to determining these biases prior to production sampling, e.g., recent λD simulations have used 20–50 ns for bias determination6,44,48,49. With the advent of d-GSλD, discrete λ states can also be used to propagate alchemical transformations while maintaining the ability to sample all λ states within a single simulation. This approach works by forming two conditional distributions, P(X | λ) and P(λ | X), from the desired joint distribution of atomic coordinates, X, and alchemical states, λ, (P(X, λ)). Sequential sampling of these conditional distributions is then performed with Gibbs sampling to generate new values of X and λ at time t32,47. Molecular dynamics is used to sample X at a fixed λ state, while λ is sampled by calculating the potential energy of every λ state with a fixed set of atomic coordinates and selecting the next λ state proportional to its probability from a probability distribution using a pseudorandom number generator47. In d-GSλD, the use of discrete λ states is advantageous because conventional λD biasing potentials can be simplified from a functional form into a single scalar value per discrete λ state. Biases added to individual λ states flatten energy barriers and facilitate stochastic transitions to different λ states over the course of a d-GSλD simulation. Although this does not remove the need to identify appropriate biases prior to production sampling, this approach reduces the amount of time needed to identify biases to 5–10 ns, on average. Highly accurate d-GSλD free energy estimates can then be obtained with MBAR15,47,50. Nonetheless, the computational cost of identifying biases for d-GSλD or λD reduces the efficiency, throughput, and cost advantages of both methods. Thus, this work was motivated to try to eliminate these costs and accelerate RBFE calculations by removing the need to identify biases prior to production sampling. If such “biasing runs” could be avoided, we estimate that λD-based methods could screen hundreds of compound analogs at a fraction of the cost of FEP/TI methods for drug discovery.
In this report, we implement the use of continuous bias updates in conjunction with discrete Gibbs sampler λ-dynamics to achieve rapid and accurate RBFE estimates. We refer to this method as λ-dynamics with bias-updated Gibbs sampling (LaDyBUGS). In contrast to the static biases used with d-GSλD, which were determined with a Wang–Landau-like algorithm47, LaDyBUGS uses an aggressive dynamic bias that changes and continuously drives the system to sample different λ states. This avoids the need to run separate simulations for bias determination prior to production sampling and continually refocuses sampling towards the least visited λ states to provide exceptionally smooth sampling of all λ states. FastMBAR, a GPU implementation of MBAR, is used for rapid free energy determination and on-the-fly bias refinement50. For five protein–ligand benchmark systems, we observe large efficiency gains of 18–66-fold improvements with LaDyBUGS compared to TI/MBAR without compromising accuracy in the predicted ΔΔGbind results. Larger efficiency gains (100–200-fold) are also observed for two systems involving more challenging perturbations of whole aromatic rings, where enhanced sampling in LaDyBUGS overcomes observed sampling limitations in TI/MBAR. In the following “Results and Discussion”, we evaluate LaDyBUGS’ performance in terms of accuracy compared to the experiment and efficiency compared to TI/MBAR, as implemented in OpenMM51. In “Methods”, we describe the workflow of LaDyBUGS as well as our computational procedure.
Results and discussion
Our goal in evaluating LaDyBUGS was to demonstrate that it provides comparable accuracy to classical methods for RBFE calculation with significant improvements in efficiency and cost savings. To that end, we selected five literature examples to benchmark LaDyBUGS performance: major urinary protein 1 (MUP1)52, DNA ligase53, c-Met kinase (c-Met)54, thrombin55, and 6-phosphofructo-2-kinase/fructose-2,6-biphosphatase 3 (PFKFB3)56. These systems have been featured in previous benchmarking studies of FEP+ and non-equilibrium switching5,16,24,52. In total, binding free energies were calculated for 45 different ligands: 6 for MUP1, 7 for DNA ligase, 11 for c-Met, 11 for thrombin, and 10 for PFKFB3 (Fig. 3). To avoid the complications of charge-changing perturbations5,57,58, only ligands with neutral alchemical substituents were included in this study. We also performed symmetric methyl perturbations to ensure no artificial bias is introduced into LaDyBUGS free energies as a result of using dynamic bias updates.

Five systems with 45 total ligands were used to evaluate and compare LaDyBUGS and TI/MBAR. LaDyBUGS calculations evaluated several ligands within a single simulation, and compounds were grouped in the following panels: a c-Met ligands, b DNA ligase ligands, c thrombin ligands, d PFKFB3 ligands, and e MUP1 ligands. For the TI/MBAR calculations, a star map of pairwise perturbations was utilized (Fig. 2). All relative free energy differences were calculated with respect to a reference compound for each system (highlighted in red). Ligand numbering was kept consistent with original experimental reports (c-Met54, DNA ligase53, thrombin55, and PFKFB356) or a previous benchmark study (MUP152).
Symmetric methyl perturbations
Symmetric perturbations were performed with LaDyBUGS to interconvert between identical but distinct methyl groups on toluene and p-xylene (as shown in Supplementary Fig. 1). This test confirms that correct sampling and accurate free energy estimates could be obtained without introducing artifacts via continuous bias updates in LaDyBUGS. As shown in Table 1, for both systems, the expected result (ΔG = 0.00 kcal mol−1) is reproduced within the computed bootstrapped errors, suggesting that LaDyBUGS is functioning properly for both single-site (toluene) and multisite (p-xylene) systems. These results provide confidence to proceed with benchmark perturbations commonly observed in structure-based drug design.
Structure-based drug design benchmarking
To demonstrate the applicability of LaDyBUGS for structure-based drug design, we assess the accuracy and efficiency of the LaDyBUGS method compared to experiment and a standard alchemical free energy method (TI/MBAR). We also briefly compare LaDyBUGS vs λD, since both methods can examine multiple perturbations simultaneously, albeit λD requires additional sampling time to identify biases prior to production sampling. In total, free energies of binding were calculated for 45 ligands bound to one of five benchmark protein systems: MUP1, DNA ligase, c-Met, thrombin, or PFKFB3. Figure 4 plots the correlation between the experiment and computed binding affinities (ΔGbind) with LaDyBUGS (using 15 ns of sampling per simulation) and TI/MBAR (using 5 ns of sampling per λ window; 55 ns of total sampling per pairwise perturbation); all data points are reported in Supplementary Tables 1 and 2 of the Supplementary Information. Root-mean-square error (RMSE) and Kendall τ scores59 were computed for each test system individually and for the combined dataset60. Using these metrics, we see a uniform improvement in both RMSE and Kendall τ with LaDyBUGS relative to TI/MBAR. For all 45 ligands, the LaDyBUGS RMSE was 0.97 kcal mol−1 and the Kendall τ was 0.65. For every test case, the calculated LaDyBUGS RMSE was near or below 1.0 kcal mol−1, a typical goal and state-of-the-art for predictive accuracy in free energy calculations for drug discovery5,6,7,11,16,17,24. It is important to note that accuracy is dependent on both correct force field representation of a chemical system and thorough configurational sampling with a given free energy method61. The larger RMSE of 1.19 kcal mol−1 and reduced Kendall τ of 0.59 from TI/MBAR (5 ns per window), which used the same force field parameters as LaDyBUGS, suggests LaDyBUGS is providing improved sampling proficiency over TI/MBAR for the same benchmark systems. Notably, LaDyBUGS used 18.3–66.0 times less sampling than TI/MBAR 5 ns per window when comparing the two computational approaches (Fig. 5).

Computed a LaDyBUGS 15 ns and b TI/MBAR 5 ns per window ΔGbind compared to experiment (in kcal mol−1). Data points are colored by the chemical system (MUP1 in cyan, DNA ligase in red, c-Met in blue, thrombin in green, and PFKFB3 in purple), and bootstrapped uncertainties computed over three replicates with FastMBAR are shown as error bars. The center black line represents perfect one-to-one correlation; the shaded gray area represents an error of ± 1 kcal mol−1. Root-mean-square errors and Kendall τ statistics are reported for all data points collectively and each system individually. Source data are provided as a Source Data file.

Correlation between computed LaDyBUGS 15 ns and TI/MBAR 5 ns per window ΔGbind results (in kcal mol−1). Data points are colored by chemical system (MUP1 in cyan, DNA ligase in red, c-Met in blue, thrombin in green, and PFKFB3 in purple), and bootstrapped uncertainties computed over three replicates with FastMBAR are shown as error bars. The center black line represents \(y=x\); the shaded gray area represents an error of ±1 kcal mol−1. Root-mean-square errors, Kendall τ statistics, total amount of sampling, and efficiency gains of LaDyBUGS 15 ns over TI/MBAR 5 ns per window in terms of sampling are reported. Source data are provided as a Source Data file.
Because both LaDyBUGS and TI/MBAR calculations used the same force field parameters, we can also compare the agreement of their ΔGbind predictions (Fig. 5). The two computational methods agree well with each other, with an overall RMSE of 0.44 kcal mol−1. Considering that most protein–ligand ΔGbind calculations have computed uncertainties between 0.3–0.5 kcal mol−1 16,48,49, and that LaDyBUGS bootstrapped errors ranged from 0.1 to 0.4 kcal mol−1 (Supplementary Tables 1 and 2), these results suggest good agreement between these free energy methods exists and that LaDyBUGS results are comparable to the community accepted standard TI/MBAR. To explore the effect of sampling time on the ΔGbind results, we also compared these methods with less sampling per LaDyBUGS simulation (with 5 ns of sampling per simulation) and more sampling per TI/MBAR calculation (with 15 ns of sampling per λ window; 165 ns of total sampling per pairwise perturbation). In Fig. 6, the agreement between LaDyBUGS 5 ns simulations compared to TI/MBAR 5 ns per window remains high with a RMSE of 0.42 kcal mol-1 and a Kendall τ of 0.86. As expected with a reduction in sampling, the mean bootstrapping error for LaDyBUGS increased from 0.17 to 0.30 kcal mol−1, although the RMSE between LaDyBUGS (5 ns) and experiment remains comparable at 1.04 kcal mol−1. This level of agreement is significant considering LaDyBUGS 5 ns used 55.0–198.0 times less sampling than TI/MBAR 5 ns per window. The amount of TI sampling for thrombin and PFKFB3 are noticeably larger than the other systems, by a factor of 2–4, due to the additional calculations performed to sample alternate conformations of larger aromatic ring perturbations. As discussed in the next subsection, LaDyBUGS showed enhanced sampling of dihedral torsions for alchemical aromatic rings, while TI/MBAR did not, requiring additional sampling to be manually performed. Thus, from a total of 120 ns expended to sample all 45 ligands (~2.67 ns per ligand) bound to their respective targets, LaDyBUGS 5 ns can provide ΔGbind predictions with errors near or below 1.0 kcal mol−1 compared to the experiment. Though error bars are slightly larger than observed with 15 ns, running LaDyBUGS for 5 ns could provide a useful way to quickly screen large series of ligand analogs prior to more rigorous evaluations by extending sampling to longer time scales. These results further highlight that significant cost savings are achievable with LaDyBUGS without compromising accuracy in the computed ΔGbind results. In contrast, with 5 ns of sampling per window, TI/MBAR required 12.7 μs of total protein–ligand sampling (165–660 ns per ligand). We note that commonly employed redundant calculations for cycle closure and hysteresis error reduction were not performed here to try to maximize the efficiency of TI/MBAR, although additional calculations were performed to sample 180° rotated ring conformations of the thrombin and PFKFB3 alchemical substituents18,19,20. To test LaDyBUGS convergence, 25 ns simulations were also run. No large deviations were observed and the RMSE between LaDyBUGS 15 ns and LaDyBUGS 25 ns simulations was small (0.12 kcal mol−1), well within statistical noise (Supplementary Tables 1 and 2). The RMSE of 0.30 kcal mol−1 between 5 ns and 25 ns LaDyBUGS results was slightly larger but still within noise, suggesting a high degree of convergence even with a minimal amount of LaDyBUGS sampling. Figure 6 also shows the effects of extending TI/MBAR sampling to 15 ns per window for all systems except MUP1, which was deemed to be satisfactorily converged at 5 ns per window by its low RMSE compared to LaDyBUGS. Large improvements are observed for TI/MBAR 15 ns per window in comparison to TI/MBAR results from 5 ns per window of sampling. The RMSE to experiment improves to 0.93 kcal mol−1 with TI/MBAR 15 ns per window, and the RMSE to LaDyBUGS decreases to 0.27 kcal mol−1. The strong agreement between short 5 ns runs of TI/MBAR and LaDyBUGS, as well as between the longer 15 ns runs of TI/MBAR and LaDyBUGS, suggests LaDyBUGS is able of deliver comparable accuracy as TI/MBAR with significant cost savings in terms of sampling (18–200 times less simulation time required). This is notable considering the spectrum of alchemical substituent sizes involved in these benchmark systems: from 1 to 4 heavy atoms in MUP1 and DNA ligase systems to 6–12 heavy atoms and entire aromatic rings in c-Met, thrombin, and PFKFB3. Improved efficiency with LaDyBUGS directly stems from its ability to investigate several alchemical perturbations collectively within a single simulation, without the need to break up transformations into separate λ windows spread across multiple separate simulations (Fig. 2).

Correlation in ΔGbind between a LaDyBUGS 5 ns compared to experiment, b LaDyBUGS 5 ns compared to TI/MBAR 5 ns per window, c TI/MBAR 15 ns per window compared to experiment, and d LaDyBUGS 15 ns compared to TI/MBAR 15 ns per window. Data points are colored by chemical system (MUP1 in cyan, DNA ligase in red, c-Met in blue, thrombin in green, and PFKFB3 in purple), and bootstrapped uncertainties computed over three replicates with FastMBAR are shown as error bars. The center black line represents ideal one-to-one agreement; the shaded gray area represents an error of ± 1 kcal mol−1. Root-mean-square errors, Kendall τ statistics, total amount of sampling, and efficiency gains of LaDyBUGS over TI/MBAR in terms of sampling are reported. Source data are provided as a Source Data file.
The performance of LaDyBUGS can also be compared to λD since both methods are able to sample multiple substituent transformations simultaneously. As shown in Supplementary Fig. 2, high correlation is observed between these λD-based techniques; the RMSE is 0.45 kcal mol−1 and the Kendall τ is 0.83. Overall, these results are very similar to what was observed in the above comparisons of LaDyBUGS and TI/MBAR. In contrast to LaDyBUGS, however, λD required 609 ns of sampling for bias identification prior to its 360 ns of production sampling. At this level of sampling, λD is still 13.1 times more efficient than TI/MBAR 5 ns per window, but 2.7 times less efficient than LaDyBUGS 15 ns. The loss of efficiency of λD compared to LaDyBUGS stems directly from the costs associated with bias identification for λD. Each system used a minimum of 48 ns for initial bias identification; however, additional production runs were performed for DNA ligase and thrombin because initial biases were not converged, causing poor λ sampling and free energy convergence in initial production calculations. Though biases can be readily refined with ALF, production sampling that isn’t used for production results ultimately gets incorporated into a system’s overall bias identification costs. For example, in initial DNA ligase production simulations, the reference compound was sampled less than 1% of the time in two out of three duplicates, yielding high uncertainties in computed ΔGbind. Similar trends were observed for some thrombin molecules as well, which were sampled only 2–4% of the time. Meanwhile, other ligands predominated and were sampled 40–50% of the time. These deficiencies were mostly resolved after refining biases and rerunning production simulations, although DNA ligase λD results still show some larger uncertainties (>0.5 kcal mol−1) and may benefit from additional sampling and bias optimization. Thrombin λD results appeared well converged and ligand end states were more equally sampled in the final production runs. As discussed in more detail below, LaDyBUGS avoids these problems of both bias identification and uneven λ sampling via the use of dynamic bias updates. This allows LaDyBUGS to be efficiently and accurately run with less sampling (5–15 ns). In contrast, shortening bias flattening in λD would yield poorer performance because biases may not be fully optimized. As an example, LaDyBUGS 5 ns yields a consistent RMSE of 0.41 kcal mol−1 compared to λD but is now 8.1 times more efficient. In summary, high cost savings are observed with LaDyBUGS even when its performance is compared to other expanded ensemble techniques that can similarly examine multiple perturbations simultaneously.
Enhanced sampling of dihedral torsions with LaDyBUGS
In addition to the efficiency improvements observed with LaDyBUGS, enhanced sampling of dihedral torsions for large substituent perturbations was also observed with LaDyBUGS. In fact, this behavior has long been observed with λD, where intramolecular degrees of freedom in alchemical substituents can be scaled by λ at a user’s discretion. To preserve a functional group’s expected geometric shape, dihedral angles are often scaled by λ, but bonds and angles are not42,43,49. Furthermore, by sampling multiple substituents simultaneously, λD-based methods provide greater flexibility and time in the MD simulation for substituents to sample alternative conformations when their respective λ states are near 0. These attributes are retained in LaDyBUGS, and they provide enhanced sampling for perturbations of larger functional groups, such as the aromatic ring transformations in thrombin and PFKFB3 systems. As shown in Supplementary Fig. 3, LaDyBUGS can equally sample two flipped ring conformations for both thrombin and PFKFB3 ligands within a single calculation, while TI/MBAR is clearly trapped in a single starting conformation. Direct comparison of TI/MBAR results without considering ring flips would, thus, be expected to yield poor agreement to LaDyBUGS, because TI/MBAR fails to sample these important conformational changes. For example, without considering ring flips in the TI/MBAR results, RMSEs of 0.68 and 1.01 kcal mol-1 are observed when comparing LaDyBUGS 15 ns vs TI/MBAR 5 ns per window for thrombin and PFKFB3 systems, respectively. These RMSEs drop significantly to 0.45 and 0.55 kcal mol−1 (Fig. 5), respectively, when additional TI/MBAR calculations with rotated functional groups are performed and weighted together with MBAR to calculate the final ΔGbind results. Hence, LaDyBUGS can provide enhanced sampling of large substituents, without incorporating replica exchange or other additional enhanced sampling techniques, allowing it to retain a high degree of efficiency and speed for examining many kinds of different alchemical perturbations.
Uniformity of λ sampling with LaDyBUGS
One potential issue associated with expanded ensemble free energy methods is a difficulty in achieving sampling smoothness of all λ states, e.g., avoiding becoming stuck primarily sampling one or several states too often and neglecting to sample all other λ states41,62. This problem has been observed in a recent expanded ensemble investigation that used a Wang–Landau algorithm to propagate λ switching28. In conventional λD simulations, including MSλD and d-GSλD, static biases are added to a simulation to reduce free energy barriers in λ space and facilitate transitions between λ states41,47. In most situations, these biases work well, all λ states are evenly sampled, and reliable free energy predictions are obtained. But, as discussed above for λD, burn-in time is required to first identify appropriate biases for these methods, which decreases their overall efficiency. Furthermore, if biases are poorly converged, static biases may be unable to facilitate continuous λ sampling and the simulation could become trapped sampling one or a handful of alchemical end states. Thus, new biases would need to be identified and sampling would have to be restarted. This was observed in the present λD work with DNA ligase and thrombin benchmark systems. However, the dynamic biases used in LaDyBUGS continuously propagate the sampling of many λ states without prior burn-in time for bias identification and allow for conformational plasticity of the chemical system without getting trapped sampling a small number of λ states. Biases from Eq. (4), in “Methods”, rely solely on the number of times each λ state has been sampled and on-the-fly FastMBAR free energy estimates; thus, LaDyBUGS can provide incredibly smooth λ sampling throughout an entire simulation. Figure 7 shows the difference between the minimum and maximum number of times a λ state was sampled as a function of time, referred to as “counts”, averaged across all protein simulations used for benchmarking. On average, the difference between minimum and maximum counts is ~4, even though λ states are sampled more than 500–800 times by the end of each simulation. This level of sampling smoothness ensures that LaDyBUGS does not become trapped sampling particular λ states and provides rapid transitions between multiple ligand end states to facilitate accurate free energy estimation with FastMBAR.

The average difference between the maximum and minimum number of times a λ state was sampled. Counts were computed from all LaDyBUGS benchmark simulations and averaged together as a function of time (plotted in blue). Source data are provided as a Source Data file.
LaDyBUGS samples a mixture distribution of λ states
Smooth transitions between states are also facilitated by strong energetic overlap between neighboring λ states. In our benchmark studies, c-Met group 1 consists of different 5-membered heterocycles while group 2 contains a mixture of carbamate and aryl substituents (Fig. 3). As shown in Fig. 8 for two example c-Met group 1 and 2 perturbations, a uniform Δλ schedule provides good energetic overlap between both similar (c-Met Group 1) and dissimilar (c-Met Group 2) transformations. This enables facile transitions to adjacent λ states when sampling the P(λ | X) conditional distribution (described more in “Methods”). As shown in Fig. 8, most transitions occur to +1 or +2 states away, although large jumps (>4 states) are sometimes observed. The degree of overlap between λ states affects the transition distance traveled, with higher overlap facilitating larger jumps (see also Supplementary Table 3). The mean transition distance traveled for c-Met group 1 is 2.47 states, but it is smaller at 1.64 states for c-Met group 2 which has less overlap between adjacent states (Fig. 8). Fortuitously, transitions between energetically similar and adjacent λ states enables the chemical system to quickly relax and equilibrate during the brief 200 fs MD simulation following a sampling transition to a new λ state. Therefore, we assume the MD configuration drawn from P(X | λ) in each Gibbs sampling step represents an equilibrium sample. By constant sampling of different λ states and atomic coordinates, LaDyBUGS can efficiently sample a mixture distribution of λ states within a single simulation. Pairing free energy determination with the MBAR algorithm is natural then, because MBAR pools and reweights samples as if they originated from a mixture distribution15,63. Supplementary Note 1 presents a mathematical proof that demonstrates that samples drawn from the same λ state with different external biases can be treated as coming from the same state. We then use FastMBAR to obtain equilibrium free energy results from a LaDyBUGS simulation, under the stated assumptions of the proof. Furthermore, because sampling of the P(λ | X) conditional distribution requires energies to be calculated for every λ state at every sampled P(X | λ) configuration, no postprocessing of LaDyBUGS trajectories is required to run MBAR; all necessary information is generated on-the-fly and is available at the conclusion of a LaDyBUGS simulation.

Normalized configuration energy distributions between adjacent λ states in two example LaDyBUGS perturbations: a c-Met group 1 cmet_9 → cmet_10 and b c-Met group 2 cmet_5 → cmet_13. Each colored line represents a distribution associated with a unique λ state progressing from λ = 0.0 on the left to λ = 1.0 on the right with Δλ steps of 0.1 (λ = {0.0, 0.1, 0.2, …, 0.9, 1.0}). c Normalized probabilities of transition distances between λ states sampled in all c-Met group 1 and c-Met group 2 LaDyBUGS simulations. The greater the degree of overlap between adjacent λ states, the more probable long-range λ transitions become. Additional transition probabilities can be found in Supplementary Table 3. Source data are provided as a Source Data file.
Software implementation
LaDyBUGS has been implemented in OpenMM51, and all LaDyBUGS scripts are available for download on the Vilseck Lab GitHub page. One advantage of using OpenMM for LaDyBUGS is the ability to use force groups to partition the interactions of different components of an alchemical system and thus enable λ state-dependent energies to be evaluated without recalculating the energy of the entire chemical system. This feature speeds up the sampling of P(λ | X) which requires λ-dependent energies to be calculated for every λ-state at every P(X | λ) configuration. Consequently, we find that sampling a group of 6 ligands collectively with 141 λ states is only marginally slower than performing a standard pairwise perturbation of 11 λ states with LaDyBUGS. For example, on a NVIDIA 2080 TI GPU, 6 duplicate 5 ns LaDyBUGS c-Met group 1 cmet_9 to cmet_10 pairwise perturbations each took ca. 10.85 h to run. Similarly, 6 duplicate 5 ns simulations of all 6 c-Met group-1 ligands sampled collectively took ca. 11.01 h each. Thus, the combined 6-ligand calculation was only ca. 1.5% slower, highlighting the effectiveness and cost savings of sampling multiple ligands simultaneously with LaDyBUGS. With our current implementation of LaDyBUGS in OpenMM and using an assumption of sampling 6 perturbations per LaDyBUGS simulation, we estimate that ca. 4–13 compound perturbations can be investigated per day per 1 GPU with LaDyBUGS using a range of 15 ns to 5 ns of sampling per calculation, respectively. On a modest cluster of 25 GPUs, this readily scales to 100-325 perturbations per day. Hence, rapid high-throughput screening of hundreds of lead compound analogs with highly accurate free energy predictions is obtainable with LaDyBUGS within a day using minimal computational resources.
Work is ongoing to further optimize our implementation of LaDyBUGS in OpenMM as well as incorporate it into other software suites, including CHARMM. To date, LaDyBUGS has been implemented in pyCHARMM, a python API for CHARMM64. In these efforts, if a program lacks the ability to partition energetic interactions via a “force group”-like algorithm, P(λ | X) may be sampled by calculating the energy of the entire chemical system; all non-alchemical environment-to-environment interactions should cancel out when λ state-dependent energies are compared. Though some wall-time slowdown may be expected to occur as a consequence of running a larger energy evaluation, we anticipate that LaDyBUGS would still provide highly efficient results, nonetheless. Incorporating LaDyBUGS into CHARMM, or other programs, could provide additional benefits too. For example, the CustomNonbondedForce class in OpenMM makes it challenging to use particle mesh Ewald (PME) methods with LaDyBUGS. However, a λD-based PME approach is already available in CHARMM and BLaDE for running λD simulations45,65,66,67, and this can be utilized with LaDyBUGS in pyCHARMM to facilitate the inclusion of long-range electrostatic interactions in future calculations.
Multisite sampling
Finally, we emphasize that the efficiency gains for LaDyBUGS reported in this work used only single-site perturbations, where substituent group modifications occurred at only one site off a central ligand core. Multisite perturbations, with functional group substitutions occurring at multiple sites around a ligand core, could also be accomplished as performed previously with d-GSλD47. Such LaDyBUGS simulations may need longer total sampling to obtain converged results due to the increased number of λ states required for multisite sampling, but this has not yet been tested. Instead, this work focused on single-site perturbations to match structure-activity relationship strategies typically pursued experimentally by changing one component of a lead compound at a time16,52,53,54,55,56. In this manner, LaDyBUGS seems especially adept at exploring incremental changes to a lead compound. Future investigations will reveal the applicability of LaDyBUGS to tackle larger or more challenging perturbations or for molecular decoupling to compute absolute free energies of binding directly.
Summary and outlook
Alchemical free energy methods such as FEP and TI have played pivotal roles in the lead optimization phase of drug design1,2,3,5,6,7,8,9,10,11, yet they require large computational costs to explore many tens to hundreds of alchemical perturbations. λD-based methods have shown improved scalability and efficiency in exploring large chemical spaces with reduced costs6,33,34,44,46,47,48,49. Hence, the object of this study was to investigate approaches to further accelerate λD-based free energy methods by eliminating burn-in time commonly expended to identify static biases prior to production sampling. In this work, we have described the λ-dynamics with bias-updated Gibbs sampling method, which is a Gibbs sampler-based λ-dynamics approach. To eliminate time spent for bias identification, LaDyBUGS uses continuous bias updating to rigorously drive the sampling of multiple λ states, and consequently multiple different ligands, simultaneously within a single simulation. This results in very even and complete sampling of all λ states and significant efficiency gains, compared to TI/MBAR. Evaluated against five experimental benchmarks, LaDyBUGS RMSEs of computed ΔGbind compared to the experiment were less than 1 kcal mol−1 on average with only 5–15 ns of sampling per simulation. LaDyBUGS RMSEs were lower than the corresponding error with TI/MBAR in all test cases, notwithstanding the use of only ca. 2–5% of the total amount of TI sampling. From these results, we estimate that highly accurate ΔGbind estimates can be obtained with only ca. 2.5–5 ns of LaDyBUGS sampling per ligand. From timing benchmarks of LaDyBUGS implemented in OpenMM, we estimate that ca. 4–13 perturbations can be examined per day per GPU with LaDyBUGS, depending on the length of sampling. Using a modest amount of GPU resources (with as few as 25 GPUs), this can easily scale to hundreds of compounds examined within a day. We envision that the rapid delivery of ΔGbind predictions via LaDyBUGS could thus be used to screen hundreds of compound analogs with minimal computational costs, accelerating computer-aided drug discovery at an incredible pace.
Methods
λ-Dynamics with bias-updated Gibbs sampling builds upon the framework of the discrete Gibbs sampler λ-dynamics approach47. Therefore, we quickly review d-GSλD before describing the workflow for LaDyBUGS.
Discrete Gibbs sampler λ-dynamics
To investigate alchemical transformations of a chemical system, d-GSλD samples the joint distribution of atomic coordinates, X, and alchemical states, λ, (P(X, λ))47. With Gibbs sampling this is accomplished via indirect sampling of two related conditional distributions, P(X | λ) and P(λ | X), which are formed by freezing a subset of variables, λ and X, respectively. A single Gibbs sampler step thus consists of sequential sampling of P(X | λ) and P(λ | X) to yield X and λ at time t (Xt, λt)32,68,69. To obtain Xt+1, molecular dynamics can be used to sample P(Xt | λt), the coordinate space of the chemical system; λt+1 can then be chosen by using a pseudorandom number generator to sample P(λt | Xt+1) (described in more detail below). While GSλD can utilize both continuous and discrete λ variables, the use of discrete λ states in d-GSλD was advantageous for several reasons. Notably, it allowed for soft-core potentials, or other λ-dependent potentials, to be easily integrated into the direct sampling routines of P(λ | X); in contrast, with the continuous λ variant of GSλD, use of a nonlinear λ-dependent potential creates a complex normalization constant in P(λ | X) which prevents direct sampling46,47. Also, d-GSλD facilitated the exploration of multiple perturbations at many sites around a central ligand core47. Though no unique solution exists for defining discrete λ states between multiple ligand end states, a representation of λ states along connective edges between ligands provides a strongly connected map for sampling multiple ligands simultaneously (Fig. 2), and it has yielded good free energy results in prior benchmark evaluations47. We note that to sample multiple ligands simultaneously with d-GSλD, a single λ state i (λi) consists of a vector of substituent-specific λy,c variables (for substituent c at site y) that scale the interactions of each alchemical functional group individually47. Like most λD-based methods, all λy,c values within a single λi state must sum to 1.0 to prevent more than 1 ligand from interacting with the rest of the chemical system at one time34,41,42. Furthermore, as mentioned earlier, biases are necessary to reduce free energy barriers in λ space and facilitate transitions between λi states at equilibrium. For d-GSλD, these biases are a single scalar energy term added to each λi state47. Prior to production sampling, static biases for each λi state were identified with a Wang–Landau-like algorithm with ca. 5–10 ns of sampling70,71. Production sampling for a preset amount of Gibbs sampling steps then ensued, followed by a FastMBAR50 calculation to compute all final relative free energy differences.
λ-Dynamics with bias-updated Gibbs sampling
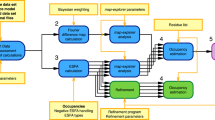
LaDyBUGS builds upon the d-GSλD framework and uses Gibbs sampling with discrete λ states to sample multiple ligand end states collectively within a single simulation. However, in an endeavor to accelerate d-GSλD and achieve rapid free energy results, Gibbs sampling is performed with dynamic biases, rather than static biases, to drive the exploration of many λ states during production sampling without prior bias determination. Figure 9 describes the workflow of LaDyBUGS. Following initialization and minimization of a chemical system, the atomic coordinates and alchemical states of the system are alternatively sampled with Gibbs sampling. As described above, P(X | λ) can be sampled with MD. Like in d-GSλD, in LaDyBUGS the conditional distribution P(λ | X) can be described as a multinomial distribution (Eq. (1)):
where M represents the total number of λi states and Ei is a scalar bias added to each λi state. The single-site VSS and multisite VMS potentials, necessary for investigating multisite perturbations of substituents c and d at sites y and z, are defined by Eqs. (2) and (3), respectively:
where X comprises atomic coordinates for both environment (x0) and alchemical components (xy,c), {x} represents the set of all xy,c coordinates, S represents the number of sites, Ny is the number of substituents on-site y, and λy,c are the site- and substituent-specific λ variables. These equations stem from similar potentials used in conventional MSλD for multisite sampling34,41,42,43,44,45,46,47. However, if systems with only single-site modifications are investigated, VMS equals zero and can be ignored. The conditional distribution P(λ | X) at time t is thus formed by first calculating the potential energy of the system at coordinates Xt for each alchemical state λi and normalizing to form a Boltzmann distribution. A new λi at time t + 1 (\({{{{{{\rm{\lambda }}}}}}}_{t+1}^{i}\)) state can then be chosen by selecting a new state proportional to its probability with a pseudorandom number generator. As shown in Fig. 9, Gibbs sampling is an iterative process that is performed repeatedly for a preset amount time, usually quantified as an amount of cumulative MD sampling. Prior to the end of each Gibbs sampler step, the biases for all λi states are also updated. This update step is described in more detail in the next section. Furthermore, at designated break points, Gibbs sampling is halted and FastMBAR is called to compute relative free energy differences (ΔGi) for each λi state compared to the reference state, λ1. These intermediate MBAR free energy results, collected at various stages of an ongoing simulation, can be used to update and refine the Ei biases for the next set of Gibbs sampler steps. As discussed below, this helps provide uniform sampling of all λ states in a LaDyBUGS simulation. Advantageously, the MBAR input, i.e., equilibrium energies of all λ states at every sampled configuration of the system (X), are calculated and saved on-the-fly when P(λ | X) is sampled, thus no trajectory postprocessing is necessary to combine MBAR with LaDyBUGS. Finally, a concluding MBAR calculation is performed at the termination of a LaDyBUGS free energy calculation to compute the final relative free energy results.

Gibbs sampling is used to sample atomic coordinates and λ states of an alchemical system; a dynamic bias is continually updated to ensure continuous sampling of all λ states. Final free energy estimates and periodic bias refinements are accomplished with FastMBAR.
Choice of the bias function
In LaDyBUGS, the Ei biases are changed at the end of each Gibbs sampler step and intermediate FastMBAR calculations are performed regularly throughout a simulation to provide additional bias refinement. When a LaDyBUGS simulation is initiated, a relatively aggressive biasing scheme is used to ensure every λ state is sampled prior to running FastMBAR for the first time. For example, in this work we used a flat external bias of 100 kcal mol−1, which is added to each λi state every time that state is sampled. While any flat bias value would work, in principle, a large bias (≥ 10 kcal mol−1) ensures rapid sampling of all λ states within a small amount of Gibbs sampling near the onset of a LaDyBUGS simulation. Prior to the first iteration of running FastMBAR, the total bias on λi is \({E}^{i}=100\,{L}_{i}\), where Li is the number of times λi was sampled and 100 is the flat bias employed in this work. At time t = u updates, Gibbs sampling is stopped and a FastMBAR calculation is performed to estimate the free energy differences of each λi state up to that point in time (\(\Delta {G}_{t=u}^{i}\)). At this stage, the Ei biases are replaced with the negative value of the MBAR results (\(-\Delta {G}_{t=u}^{i}\)) and an additional exponential bias39 is used to penalize each λi state based on the number of times λi is sampled compared to the least-sampled state (min[L(λ)]) (Eq. (4), where εb = 1.0 kcal mol−1). After each Gibbs sampler step, the biases are updated with Eq. (4) to reflect the new number of counts per λi state, but the \(-\Delta {G}_{t=u}^{i}\) component remains unchanged until the next FastMBAR calculation. Through this continuous changing of the biases, complete and smooth sampling of all λ states can be achieved (see “Results and discussion” and Fig. 7). Supplementary Note 1 presents a mathematical proof that, assuming the MD simulation used for sampling from P(X | λ) in each Gibbs sampler step reaches equilibrium, the value of the scalar bias used during Gibbs sampling has no effect on the FastMBAR calculation, facilitating the use of unbiased equilibrium energies in FastMBAR for free energy estimation.
Benchmark system details
LaDyBUGS has been implemented in OpenMM and all simulations were run using the CUDA platform51. CHARMM-based force field parameters were used to represent different components of the chemical systems. CHARMM36 was used for all protein atoms72,73,74. Small molecule ligand atoms were parameterized with ParamChem/CGenFF atom types75,76,77 and partial atomic charges from the MATCH atom parameterization tool78. The TIP3P water model was used to represent water79. Initial protein complex coordinates were taken from PDBIDs 1I0680, 4CC553, 4R1Y54, 2ZFF55, and 6HVI56 for MUP1, DNA ligase, c-Met, thrombin, and PFKFB3, respectively. Protonation states of titratable residues at a pH of 7.0 were determined with the assistance of MolProbity81 and ProPKa82. Protein systems were prepared and solvated using the CHARMM-GUI webserver83 and cubic water boxes were constructed with a 10 Å buffer between solute atoms and box edges. Enough ions to neutralize the system and create a 0.1 M NaCl solution were added. Small molecule structure files for MUP1, DNA ligase, thrombin, and PFKFB3 ligands were constructed manually using UCSF Chimera84. Published structure files were used as initial coordinates for the c-Met compounds5. Alchemical functional groups were created as multiple topology models, with explicit atoms for every unique functional group, using the msld-py-prep utility85. Cubic unbound ligand solvent boxes were constructed with the convpdb.pl tool from the MMTSB toolset86, with a 12 Å buffer between solute atoms and box edges. Starting psf topology and pdb coordinate files were generated with the CHARMM molecular simulation package prior to running LaDyBUGS in OpenMM65,66. To track alchemical transformations along connective edges between ligand end states, a series of discrete λ states were created for each system following the procedure used for d-GSλD47. In OpenMM, the CHARMM-generated psf and pdb files were loaded in with the CharmmPsfFile and CharmmParameterSet classes. A nonbonded lookup table was generated to handle CHARMM’s NBFIX nonbonded parameter exceptions, and custom nonbonded forces were written to facilitate λ scaling of all alchemical functional groups. These custom nonbonded forces included CHARMM’s force switching and λD-based soft-core potentials41,87. All LaDyBUGS simulations were performed at 25 °C and 1 atm in the isothermal-isobaric ensemble. In OpenMM, this was accomplished with a Monte Carlo barostat88,89 and a Langevin integrator90 with a friction coefficient of 10 ps−1. An integration time step of 2 fs was used, facilitated by constraining all hydrogen to heavy atom bond lengths with the SHAKE algorithm91. Periodic boundary conditions were employed, and force switching was used to gradually smooth nonbonded forces to zero between 10 and 12 Å87. During a LaDyBUGS simulation, trajectory frames were saved at the end of a Gibbs sampler step, if an alchemical end state was sampled. VMD92 and PyMOL93 were used to visualize and analyze simulation trajectories.
LaDyBUGS free energy calculations
Ligands in the five test systems were grouped together as follows: 6 MUP1 ligands were sampled collectively, 7 DNA ligase ligands were sampled collectively, 11 c-Met ligands were grouped into two sets of 6 ligands each, 11 thrombin ligands were grouped into two sets of 6 ligands each, and 10 PFKFB3 ligands were grouped into two sets of 6 and 5 ligands, respectively. For c-Met, thrombin, and PFKFB3 calculations, a common reference compound was featured in each group to connect the two datasets (Fig. 3, red-boxed reference molecules). A symmetric lambda spacing (Δλ) of 0.1 along connective edges was used for all transformations. For LaDyBUGS calculations performing single-site alchemical perturbations only, the number of total λ states (Nλ) scales quadratically with the number of ligands analyzed (Ns), as shown in Eq. (5). As a result, 95 λ states were used in LaDyBUGS calculations analyzing 5 ligands, 141 λ states were used to evaluate 6 ligands, and 196 λ states were used to evaluate 7 ligands collectively. Though this work only investigates single-site perturbations, multisite perturbations are feasible as well, as demonstrated with d-GSλD47.
For each LaDyBUGS calculation, the chemical system was subjected to 1000 steps of energy minimization at a random fixed λ state, followed by 5000 steps of MD equilibration to briefly relax the system. The workflow in Fig. 9 was then followed, with iterative sampling of P(X | λ) and P(λ | X) conditional distributions. MD was run for 100 time steps (200 fs) to sample P(X | λ), and biases were updated after every P(λ | X) sample was taken. After 1000 Gibbs sampler steps (200 ps), a FastMBAR calculation was performed, and the \(\Delta {G}_{t=u}\) results were used to update the biases according to Eq. (4). Gibbs sampling with bias updates then resumed. LaDyBUGS simulations were run for 15 ns each, during which FastMBAR was called 75 times for bias refinement (every 1000 Gibbs sampler steps). Simulations were run in triplicate for a total of 45 ns of simulation time expended per compound group. FastMBAR was used to collate data from all duplicate runs to yield the final free energy results, and bootstrapping was used to provide an estimate of precision. To investigate the effects of running LaDyBUGS for shorter or longer, simulations were also run for 5 ns and 25 ns each, respectively. Computed relative free energy differences (ΔΔGcomp) were converted into absolute free energy differences (ΔGcomp) for comparison to experiment (ΔGexpt) with Eq. (6)16,49.
TI/MBAR free energy calculations
For each chemical system, pairwise perturbations were run between a reference ligand, highlighted with a red box in Fig. 3, and all other ligand analogs for a protein system. This perturbation approach has often been called a “star map” (Fig. 2); redundant calculations for cycle closure were not performed to maximize TI/MBAR efficiency18,19,20. Alchemical transformations were accomplished over 11 λ windows with a Δλ schedule of 0.1. For each λ window, the chemical system was subjected to 1000 steps of energy minimization and 5000 steps of MD equilibration. MD simulations were then run for 5 ns per λ window, and configurations were saved every 100 time steps (200 fs) for a subsequent FastMBAR analysis. Similar to LaDyBUGS, each calculation was run in triplicate for a total of 165 ns of sampling per pairwise perturbation. For systems with larger perturbations, specifically thrombin and PFKFB3 which mutate whole aromatic rings of 6–12 heavy atoms, we observed poor rotational sampling of the perturbed aromatic rings. Therefore, additional sampling of alternative rotational states was performed by manually flipping the aromatic rings by 180° prior to rerunning the TI pairwise calculations. For thrombin, this required twice the total amount of sampling per transformation (330 ns) to perform perturbations from a symmetric reference phenyl ring to two flipped conformations of every other alchemical substituent. For PFKFB3, perturbations were performed between flipped conformations of both the reference and other alchemical substituents, requiring 4 times the total amount of sampling (660 ns) per transformation. For all systems, configurations from all λ windows and duplicates were pooled together and supplied to FastMBAR to estimate a final relative free energy difference and bootstrapped errors. We refer to these results as “TI/MBAR 5 ns per window”. Relative binding free energies were again converted into absolute binding affinities for comparison to LaDyBUGS and experiment. To investigate the effects of running TI/MBAR for longer, λ window simulations were also extended and sampled for 15 ns each, referred to as “TI/MBAR 15 ns per window”. These longer simulations required 495–1980 ns of total sampling for a single pairwise perturbation.
λD free energy calculations
To provide an additional computational dataset for comparison to LaDyBUGS, binding free energies were also calculated with λ-dynamics. Simulation parameters and conditions used for LaDyBUGS were similarly employed for λD to provide a close one-to-one comparison. Therefore, the multiple topology models and ligand groupings used for LaDyBUGS were also used for λD. Calculations were run with the CHARMM molecular simulation package utilizing the domain decomposition (DOMDEC) module or the BLaDE engine for GPU accelerated sampling22,45,65,66. The Adaptive Landscape Flattening algorithm was used to identify appropriate biasing potentials for each system prior to production sampling41. Following conventional λD/ALF protocols, one hundred short 100 ps simulations followed by thirteen longer 1 ns and then five duplicate 5 ns simulations were performed for initial bias identification41,43,44,47,49,50. For each system, this required a minimal amount of 48 ns for bias identification with ALF. For DNA ligase and thrombin systems, initial production runs failed to yield good sampling and converged free energy results; thus, production trajectories were reanalyzed with ALF to yield new, refined biases, and the discarded production sampling was added to the overall amount of time required to identify biases for λD. Additional production runs were then performed until satisfactory convergence was observed in both λ sampling and the final free energy results.
Symmetric perturbations
Finally, to demonstrate that no artificial bias is introduced by using dynamic bias updates during a LaDyBUGS calculation, symmetric perturbations were performed. Because the expected answer of ΔG = 0.00 kcal mol-1 is known, these calculations provide a useful control for evaluating the performance of LaDyBUGS without concern for force field inaccuracies. Utilizing a previous example from d-GSλD47, methyl perturbations in two systems were explored to convert toluene into toluene and p-xylene into p-xylene in water. In each system, 1–2 methyl groups were perturbed into identical but atomically distinct substituents at one (toluene) or two (p-xylene) sites, respectively. Simulations were run in triplicate for 25 ns to ensure full convergence of the calculation, and the final free energy results were calculated with FastMBAR.
Reporting summary
Further information on research design is available in the Nature Portfolio Reporting Summary linked to this article.
Data availability
The data that support the findings of this study are available from the corresponding author upon request. Source data are provided with this paper.
Code availability
Scripts to setup and run LaDyBUGS simulations in OpenMM and pyCHARMM are available at github.com/Vilseck-Lab/LaDyBUGS and Zenodo94.
References
Jorgensen, W. L. The many roles of computation in drug discovery. Science 303, 1813–1818 (2004).
Song, L. F. & Merz, K. M. Evolution of alchemical free energy methods in drug discovery. J. Chem. Inf. Model. 60, 5308–5318 (2020).
Chodera, J. D. et al. Alchemical free energy methods for drug discovery: progress and challenges. Curr. Opin. Struct. Biol. 21, 150–160 (2011).
Peter, K. Free energy calculations: applications to chemical and biochemical phenomena. Chem. Rev. 93, 2395–2417 (1993).
Schindler, C. E. M. et al. Large-scale assessment of binding free energy calculations in active drug discovery projects. J. Chem. Inf. Model. 60, 5457–5474 (2020).
Raman, E. P., Paul, T. J., Hayes, R. L. & Brooks, C. L. III Automated, accurate, and scalable relative protein-ligand binding free-energy calculations using lambda dynamics. J. Chem. Theory Comput. 16, 7895–7914 (2020).
Abel, R., Wang, L., Harder, E. D., Berne, B. J. & Friesner, R. A. Advancing drug discovery through enhanced free energy calculations. Acc. Chem. Res. 50, 1625–1632 (2017).
Lee, T.-S. et al. Alchemical binding free energy calculations in AMBER20: advances and best practices for drug discovery. J. Chem. Inf. Model. 60, 5595–5623 (2020).
Cournia, Z., Allen, B. & Sherman, W. Relative binding free energy calculations in drug discovery: recent advances and practical considerations. J. Chem. Inf. Model. 57, 2911–2937 (2017).
Abel, R., Manas, E. S., Friesner, R. A., Farid, R. S. & Wang, L. Modeling the value of predictive affinity scoring in preclinical drug discovery. Curr. Opin. Struct. Biol. 52, 103–110 (2018).
Mobley, D. L. & Klimovich, P. V. Perspective: alchemical free energy calculations for drug discovery. J. Chem. Phys. 137, 230901 (2012).
Zwanzig, R. W. High‐temperature equation of state by a perturbation method. I. nonpolar gases. J. Chem. Phys. 22, 1420–1426 (1954).
Wang, L., Berne, B. J. & Friesner, R. A. On achieving high accuracy and reliability in the calculation of relative protein–ligand binding affinities. Proc. Natl. Acad. Sci. USA 109, 1937–1942 (2012).
Kirkwood, J. G. Statistical mechanics of fluid mixtures. J. Chem. Phys. 3, 300–313 (1935).
Shirts, M. R. & Chodera, J. D. Statistically optimal analysis of samples from multiple equilibrium states. J. Chem. Phys. 129, 124105–124105 (2008).
Wang, L. et al. Accurate and reliable prediction of relative ligand binding potency in prospective drug discovery by way of a modern free-energy calculation protocol and force field. J. Am. Chem. Soc. 137, 2695–2703 (2015).
Kuhn, M. et al. Assessment of binding affinity via alchemical free-energy calculations. J. Chem. Inf. Model. 60, 3120–3130 (2020).
Liu, S. et al. Lead optimization mapper: automating free energy calculations for lead optimization. J. Comput. Aided Mol. Des. 27, 755–770 (2013).
Yang, Q. et al. Optimal designs for pairwise calculation: an application to free energy perturbation in minimizing prediction variability. J. Comp. Chem. 41, 247–257 (2020).
Wang, L. et al. Modeling local structural rearrangements using FEP/REST: application to relative binding affinity predictions of CDK2 inhibitors. J. Chem. Theory Comput. 9, 1282–1293 (2013).
Chen, H. et al. Boosting free-energy perturbation calculations with GPU-accelerated NAMD. J. Chem. Inf. Model. 60, 5301–5307 (2020).
Hynninen, A. P. & Crowley, M. F. New faster CHARMM molecular dynamics engine. J. Comput. Chem. 35, 406–413 (2014).
Kutzner, C. et al. More bang for your buck: improved use of GPU nodes for GROMACS 2018. J. Comp. Chem. 40, 2418–2431 (2019).
Gapsys, V. et al. Large scale relative protein ligand binding affinities using non-equilibrium alchemy. Chem. Sci. 11, 1140–1152 (2020).
Khalak, Y., Tresadern, G., de Groot, B. L. & Gapsys, V. Non-equilibrium approach for binding free energies in cyclodextrins in SAMPL7: force fields and software. J. Comput. Aided Mol. Des. 35, 49–61 (2021).
Baumann, H. M., Gapsys, V., de Groot, B. L. & Mobley, D. L. Challenges encountered applying equilibrium and nonequilibrium binding free energy calculations. J. Phys. Chem. B 125, 4241–4261 (2021).
Gapsys, V. et al. Pre-exascale computing of protein-ligand binding free energies with open source software for drug design. J. Chem. Inf. Model. 62, 1172–1177 (2022).
Zhang, S., Hahn, D. F., Shirts, M. R. & Voelz, V. A. Expanded ensemble methods can be used to accurately predict protein-ligand relative binding free energies. J. Chem. Theory Comput. 17, 6536–6547 (2021).
Lyubartsev, A., Martsinovski, A., Shevkunov, S. & Vorontsov-Velyaminov, P. New approach to Monte Carlo calculation of the free energy: method of expanded ensembles. J. Chem. Phys. 96, 1776–1783 (1992).
Tan, Z. Optimally adjusted mixture sampling and locally weighted histogram analysis. J. Comput. Graph. Stat. 26, 54–65 (2017).
Lindahl, V., Lidmar, J. & Hess, B. Accelerated weight histogram method for exploring free energy landscapes. J. Chem. Phys. 141, 044110 (2014).
Chodera, J. D. & Shirts, M. R. Replica exchange and expanded ensemble simulations as Gibbs sampling: simple improvements for enhanced mixing. J. Chem. Phys. 135, 194110 (2011).
Kong, X. & Brooks, C. L. III λ‐dynamics: a new approach to free energy calculations. J. Chem. Phys. 105, 2414–2423 (1996).
Knight, J. L. & Brooks, C. L. III Multisite λ dynamics for simulated structure–activity relationship studies. J. Chem. Theory Comput. 7, 2728–2739 (2011).
Christ, C. D. & van Gunsteren, W. F. Enveloping distribution sampling: a method to calculate free energy differences from a single simulation. J. Chem. Phys. 126, 184110 (2007).
Christ, C. D. & van Gunsteren, W. F. Simple, efficient, and reliable computation of multiple free energy differences from a single simulation: a reference hamiltonian parameter update scheme for enveloping distribution sampling (EDS). J. Chem. Theory Comput. 5, 276–286 (2009).
Perthold, J. W. & Oostenbrink, C. Accelerated enveloping distribution sampling: enabling sampling of multiple end states while preserving local energy minima. J. Phys. Chem. B 122, 5030–5037 (2018).
Bieler, N. S. & Hünenberger, P. H. Communication: estimating the initial biasing potential for λ-local-elevation umbrella-sampling (λ-LEUS) simulations via slow growth. J. Chem. Phys. 141, 201101 (2014).
Bieler, N. S., Häuselmann, R. & Hünenberger, P. H. Local elevation umbrella sampling applied to the calculation of alchemical free-energy changes via λ-dynamics: the λ-LEUS scheme. J. Chem. Theory Comput. 10, 3006–3022 (2014).
Bieler, N. S., Tschopp, J. P. & Hünenberger, P. H. Multistate λ-local-elevation umbrella-sampling (MS-λ-LEUS): method and application to the complexation of cations by crown ethers. J. Chem. Theory Comput. 11, 2575–2588 (2015).
Hayes, R. L., Armacost, K. A., Vilseck, J. Z. & Brooks, C. L. III Adaptive landscape flattening accelerates sampling of alchemical space in multisite λ dynamics. J. Phys. Chem. B 121, 3626–3635 (2017).
Knight, J. L. & Brooks, C. L. III Applying efficient implicit constraints in alchemical free energy simulations. J. Comput. Chem. 32, 3423–3432 (2011).
Hayes, R. L., Vilseck, J. Z. & Brooks, C. L. III Approaching protein design with multisite λ dynamics: accurate and scalable mutational folding free energies in T4 lysozyme. Prot. Sci. 27, 1910–1922 (2018).
Hayes, R. L., Vilseck, J. Z. & Brooks, C. L. III Addressing intersite coupling unlocks large combinatorial chemical spaces for alchemical free energy methods. J. Chem. Theory Comput https://doi.org/10.1021/acs.jctc.1c00948 (2022).
Hayes, R. L., Buckner, J. & Brooks, C. L. III BLaDE: a basic lambda dynamics engine for GPU-accelerated molecular dynamics free energy calculations. J. Chem. Theory Comput. 17, 6799–6807 (2021).
Ding, X., Vilseck, J. Z., Hayes, R. L. & Brooks, C. L. III Gibbs sampler-based λ-dynamics and Rao–Blackwell estimator for alchemical free energy calculation. J. Chem. Theory Comput. 13, 2501–2510 (2017).
Vilseck, J. Z., Ding, X., Hayes, R. L. & Brooks, C. L. III Generalizing the discrete Gibbs sampler-based λ-dynamics approach for multisite sampling of many ligands. J. Chem. Theory Comput. 17, 3895–3907 (2021).
Vilseck, J. Z., Armacost, K. A., Hayes, R. L., Goh, G. B. & Brooks, C. L. III Predicting binding free energies in a large combinatorial chemical space using multisite. λ Dyn. J. Phys. Chem. Lett. 9, 3328–3332 (2018).
Vilseck, J. Z., Sohail, N., Hayes, R. L. & Brooks, C. L. III Overcoming challenging substituent perturbations with multisite λ-dynamics: a case study targeting β-secretase. 1. J. Phys. Chem. Lett. 10, 4875–4880 (2019).
Ding, X., Vilseck, J. Z. & Brooks, C. L. III Fast solver for large scale multistate Bennett acceptance ratio equations. J. Chem. Theory Comput. 15, 799–799 (2019).
Eastman, P. et al. OpenMM 7: rapid development of high performance algorithms for molecular dynamics. PLOS Comput. Biol. 13, e1005659 (2017).
Steinbrecher, T. B. et al. Accurate binding free energy predictions in fragment optimization. J. Chem. Inf. Model. 55, 2411–2420 (2015).
Howard, S. et al. Fragment-based discovery of 6-azaindazoles as inhibitors of bacterial DNA ligase. ACS Med. Chem. Lett. 4, 1208–1212 (2013).
Dorsch, D. et al. Identification and optimization of pyridazinones as potent and selective c-Met kinase inhibitors. Bioorg. Med. Chem. Lett. 25, 1597–1602 (2015).
Baum, B. et al. More than a simple lipophilic contact: a detailed thermodynamic analysis of nonbasic residues in the s1 pocket of thrombin. J. Mol. Biol. 390, 56–69 (2009).
Boutard, N. et al. Discovery and structure-activity relationships of N-Aryl 6-aminoquinoxalines as potent PFKFB3 kinase inhibitors. ChemMedChem 14, 169–181 (2019).
Chen, W. et al. Accurate calculation of relative binding free energies between ligands with different net charges. J. Chem. Theory Comput. 14, 6346–6358 (2018).
Rocklin, G. J., Mobley, D. L., Dill, K. A. & Hünenberger, P. H. Calculating the binding free energies of charged species based on explicit-solvent simulations employing lattice-sum methods: an accurate correction scheme for electrostatic finite-size effects. J. Chem. Phys. 139, 184103 (2013).
Kendall, M. G. A new measure of rank correlation. Biometrika 30, 81–93 (1938).
The MathWorks, Inc. (MATLAB version 9.14.0 (R2023a), Natick, Massachusetts, USA, 2023).
Mobley, D. L. Let’s get honest about sampling. J. Comput. Aided Mol. Des. 26, 93–95 (2012).
König, G., Ries, B., Hünenberger, P. H. & Riniker, S. Efficient alchemical intermediate states in free energy calculations using λ-enveloping distribution sampling. J. Chem. Theory Comput. 17, 58–5-5815 (2021).
Shirts, M. R. Reweighting from the mixture distribution as a better way to describe the multistate Bennett acceptance ratio. Preprint at https://arxiv.org/abs/1704.00891 (2017).
Buckner, J. et al. pyCHARMM: embedding CHARMM functionality in a Python framework. J. Chem. Theory Comput. 19, 3752–3762 (2023).
Brooks, B. R. et al. CHARMM: the biomolecular simulation program. J. Comput. Chem. 30, 1545–1614 (2009).
Brooks, B. R. et al. CHARMM: a program for macromolecular energy, minimization, and dynamics calculations. J. Comput. Chem. 4, 187–217 (1983).
Huang, Y., Chen, W., Wallace, J. A. & Shen, J. All-atom continuous constant pH molecular dynamics with particle mesh Ewald and titratable water. J. Chem. Theory Comput. 12, 5411–5421 (2016).
Geman, S. & Geman, D. Stochastic relaxation, Gibbs distributions, and the Bayesian restoration of images. IEEE Trans. Pattern Anal. Mach. Intell. PAMI-6, 721–741 (1984).
Smith, A. F. & Roberts, G. O. Bayesian computation via the Gibbs sampler and related Markov chain Monte Carlo methods. J. R. Stat. Soc. B 55, 3–23 (1993).
Wang, F. & Landau, D. P. Efficient, multiple-range random walk algorithm to calculate the density of states. Phys. Rev. Lett. 86, 2050–2053 (2001).
Belardinelli, R. E. & Pereyra, V. D. Wang-Landau algorithm: a theoretical analysis of the saturation of the error. J. Chem. Phys. 127, 184105 (2007).
Best, R. B., Mittal, J., Feig, M. & MacKerell, A. D. Inclusion of many-body effects in the additive CHARMM protein CMAP potential results in enhanced cooperativity of α-helix and β-hairpin formation. Biophys. J. 103, 1045–1051 (2012).
Best, R. B. et al. Optimization of the additive CHARMM all-atom protein force field targeting improved sampling of the backbone φ, ψ and side-chain χ1 and χ2 dihedral angles. J. Chem. Theory Comput. 9, 3257–3273 (2012).
Huang, J. et al. CHARMM36m: an improved force field for folded and intrinsically disordered proteins. Nat. Methods 14, 71–73 (2017).
Vanommeslaeghe, K. et al. CHARMM general force field: a force field for drug-like molecules compatible with the CHARMM all-atom additive biological force fields. J. Comput. Chem. 31, NA–NA (2009).
Vanommeslaeghe, K. & MacKerell, A. D. Automation of the CHARMM general force field (CGenFF) I: bond perception and atom typing. J. Chem. Inf. Model. 52, 3144–3154 (2012).
Vanommeslaeghe, K., Raman, E. P. & MacKerell, A. D. Automation of the CHARMM general force field (CGenFF) II: assignment of bonded parameters and partial atomic charges. J. Chem. Inf. Model. 52, 3155–3168 (2012).
Yesselman, J. D., Price, D. J., Knight, J. L. & Brooks, C. L. III MATCH: an atom-typing toolset for molecular mechanics force fields. J. Comput. Chem. 33, 189–202 (2012).
Jorgensen, W. L., Chandrasekhar, J., Madura, J. D., Impey, R. W. & Klein, M. L. Comparison of simple potential functions for simulating liquid water. J. Chem. Phys. 79, 926–935 (1983).
Timm, D. E. et al. Structural basis of pheromone binding to mouse major urinary protein (MUP-I). Prot. Sci. 10, 997–1004 (2001).
Williams, C. J. et al. MolProbity: more and better reference data for improved all-atom structure validation. Protein Sci. 27, 293–315 (2018).
Søndergaard, C. R., Olsson, M. H. M., Rostkowski, M. & Jensen, J. H. Improved treatment of ligands and coupling effects in empirical calculation and rationalization of pKa values. J. Chem. Theory Comput. 7, 2284–2295 (2011).
Jo, S., Kim, T., Iyer, V. G. & Im, W. CHARMM-GUI: a web-based graphical user interface for CHARMM. J. Comput. Chem. 29, 1859–1865 (2008).
Pettersen, E. F. et al. UCSF Chimera—a visualization system for exploratory research and analysis. J. Comput. Chem. 25, 1605–1612 (2004).
Vilseck, J. Z., Cervantes, L. F., Hayes, R. L. & Brooks, C. L. III Optimizing multisite λ-dynamics throughput with charge renormalization. J. Chem. Inf. Model. 62, 1479–1488 (2022).
Feig, M., Karanicolas, J. & Brooks, C. L. III MMTSB Tool Set: enhanced sampling and multiscale modeling methods for applications in structural biology. Conform. Sampl. 22, 377–395 (2004).
Steinbach, P. J. & Brooks, B. R. New spherical-cutoff methods for long-range forces in macromolecular simulation. J. Comput. Chem. 15, 667–683 (1994).
Chow, K.-H. & Ferguson, D. M. Isothermal-isobaric molecular dynamics simulations with Monte Carlo volume sampling. Comput. Phys. Commun. 91, 283–289 (1995).
Åqvist, J., Wennerström, P., Nervall, M., Bjelic, S. & Brandsdal, B. O. Molecular dynamics simulations of water and biomolecules with a Monte Carlo constant pressure algorithm. Chem. Phys. Lett. 384, 288–294 (2004).
Feller, S. E., Zhang, Y., Pastor, R. W. & Brooks, B. R. Constant pressure molecular dynamics simulation: the Langevin piston method. J. Chem. Phys. 103, 4613–4621 (1995).
Ryckaert, J.-P., Ciccotti, G. & Berendsen, H. J. C. Numerical integration of the cartesian equations of motion of a system with constraints: molecular dynamics of n-alkanes. J. Comput. Phys. 23, 327–341 (1977).
Humphrey, W., Dalke, A. & Schulten, K. VMD: visual molecular dynamics. J. Mol. Graph. 14, 33–38 (1996).
Schrödinger, L. L. C. (The PyMOL Molecular Graphics System, Version 1.8., 2015).
Vilseck, J. Z. & Robo, M. T. Vilseck-Lab/LaDyBUGS. Zenodo https://doi.org/10.5281/zenodo.10238489 (2023).
Acknowledgements
The authors gratefully acknowledge the National Institutes of Health (NIH) for financial support through grant R35GM146888 (to J.Z.V.). This work was also supported by an award from the Ralph W. and Grace M. Showalter Research Trust (award 077151-00002B to J.Z.V.) and start-up funds provided to J.Z.V. by Indiana University School of Medicine. The content of this work is solely the responsibility of the authors and does not necessarily represent the official views of the NIH, Showalter Research Trust, or the Indiana University School of Medicine. The authors acknowledge the Indiana University Pervasive Technology Institute for providing supercomputing and storage resources that have contributed to the research results reported within this paper. We further thank Charles L. Brooks III for helpful discussions about this work.
Author information
Authors and Affiliations
Contributions
J.Z.V. conceived the presented idea and supervised the project. J.Z.V., R.L.H., X.D., and M.T.R. developed the theoretical formalism and developed the code. M.T.R., B.P., and J.Z.V. performed the experiments and analysis. M.T.R. and J.Z.V. wrote the manuscript with input from all authors.
Corresponding author
Ethics declarations
Competing interests
The authors declare no competing interests.
Peer review
Peer review information
Nature Communications thanks the anonymous reviewer(s) for their contribution to the peer review of this work.
Additional information
Publisher’s note Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Supplementary information
Source data
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons license, and indicate if changes were made. The images or other third party material in this article are included in the article’s Creative Commons license, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons license and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this license, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Robo, M.T., Hayes, R.L., Ding, X. et al. Fast free energy estimates from λ-dynamics with bias-updated Gibbs sampling. Nat Commun 14, 8515 (2023). https://doi.org/10.1038/s41467-023-44208-9
Received:
Accepted:
Published:
DOI: https://doi.org/10.1038/s41467-023-44208-9
Comments
By submitting a comment you agree to abide by our Terms and Community Guidelines. If you find something abusive or that does not comply with our terms or guidelines please flag it as inappropriate.
