
Abstract
Immunoglobulins (IGs), critical components of the human immune system, are composed of heavy and light protein chains encoded at three genomic loci. The IG Kappa (IGK) chain locus consists of two large, inverted segmental duplications. The complexity of the IG loci has hindered use of standard high-throughput methods for characterizing genetic variation within these regions. To overcome these limitations, we use long-read sequencing to create haplotype-resolved IGK assemblies in an ancestrally diverse cohort (n = 36), representing the first comprehensive description of IGK haplotype variation. We identify extensive locus polymorphism, including novel single nucleotide variants (SNVs) and novel structural variants harboring functional IGKV genes. Among 47 functional IGKV genes, we identify 145 alleles, 67 of which were not previously curated. We report inter-population differences in allele frequencies for 10 IGKV genes, including alleles unique to specific populations within this dataset. We identify haplotypes carrying signatures of gene conversion that associate with SNV enrichment in the IGK distal region, and a haplotype with an inversion spanning the proximal and distal regions. These data provide a critical resource of curated genomic reference information from diverse ancestries, laying a foundation for advancing our understanding of population-level genetic variation in the IGK locus.
Similar content being viewed by others

Introduction
Immunoglobulins (IGs) are critical protein components of the immune system with roles in both innate and adaptive immune responses [1]. IGs are produced by B lymphocytes and are either expressed on the cell membrane as B cell receptors (BCRs) or secreted as antibodies. IGs are composed of two pairs of identical ‘heavy’ chains and ‘light’ kappa or lambda chains, encoded by genes located at three loci in the human genome: the IG heavy chain locus (IGH) at 14q32.33, and the IG lambda (IGL) and kappa (IGK) loci, located at 22q11.2 and 2p11.2, respectively [2]. Through the unique mechanism of V(D)J recombination [3], individual variable (V), diversity (D) and joining (J) genes at the IGH locus, and V and J genes at either the IGK or IGL loci, somatically rearrange to generate V-D-J and V-J regions that encode respective antibody variable domains. IG loci are enriched for large structural variants (SVs), including insertions, deletions, and duplications of functional genes, many of which are variable between human populations [4,5,6,7]. The IG loci exhibit extensive haplotype diversity and structural complexity, which contributes to challenges associated with IG haplotype characterization using standard high-throughput approaches [4, 6,7,8,9]. This has limited our understanding of the impact of IG genetic variation in immune function and disease [10,11,12].
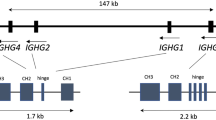
A unique structural characteristic of the IGK locus is that it includes two large inverted segmental duplications (SDs) that contain distinct V genes; these paralogous regions (termed proximal and distal) [13, 14] are separated by an array of 45-Kbp highly identical repeats that encode the 45 S rRNA, totaling 1067285 bp [15]. The proximal region spans 500 Kbp and includes 69 IGKV functional/ORF genes and pseudogenes, downstream of which are 5 functional IGKJ genes and a single functional IGK constant gene. The distal region spans 430 Kbp and includes 62 V genes and pseudogenes (distal V genes are denoted by a ‘D’; for example, IGKV1D-12) [2]. An additional unmapped IGKV gene has also been reported [16] and is cataloged in the International IMmunoGeneTics Information System (IMGT) [17] as IGKV1-NL1 (where the NL indicates “not localized”). The documentation of this gene indicates the presence of SVs in IGK, consistent with observations in IGH and IGL [4, 6, 7, 14]. Evidence for sequence conversion between proximal and distal regions has also been reported [14], highlighting the potential for complex genetic signatures to be observed at the population level.
To date, there are 108 functional/ORF IGKV, IGKJ, and IGKC alleles curated in IMGT. However, only a limited number (n = 4) of fully curated and annotated haplotypes have been characterized at the genomic level [13, 14, 18], and adaptive immune receptor repertoire sequencing (AIRR-seq) has indicated that allelic variation in IGK is likely to be more extensive than what is currently documented [19, 20]. Compared to IGH [4, 6] and IGL [7], our understanding of germline variation at the IGK locus is limited, especially in terms of haplotype structure (including structural variation) as well as coding and non-coding polymorphism. It will be critical to further catalog this genetic variation if we are to clarify the impact of IG germline variants on the antibody response. Diversity in antigen-naïve B cell antibody repertoires is due to combinatorial and junctional diversity and the effective pairing of particular heavy and light chain genes [1]. This partly ensures that the immune system is able to recognize and mount effective immune responses against a broad range of potential antigens. Critically, however, population-level IG haplotype and allelic variation also makes important contributions to antibody diversity and function [6, 11, 21, 22], including in the context of infection and vaccine responsiveness. For example, there have now been clear demonstrations that IGH locus SVs and single nucleotide variants (SNVs) impact usage of IGH genes in expressed antibody repertoires [6]. Antibody light chains also contribute to antigen binding and can limit self-reactivity through the process of light chain receptor editing during B cell development (reviewed in [23]). Consistent with findings related to IGH diversity, usage of specific IGKV genes has been associated with neutralizing antibodies against protein components of influenza A (IGKV4-1, IGKV3-11, IGKV3-15; [24, 25]), HIV-1 (IGKV3-20, IGKV1-33; [26]), Zika virus (IGKV1-5; [27]), as well as auto-reactivity in celiac disease (IGKV1-5; [28]) and systemic lupus erythematosus (IGKV4-1; [29]). Taken together, these findings further motivate a need to develop more robust methods for detecting and genotyping IGK polymorphisms.
To characterize germline IGK sequence variation at population-scale, we extended a technique that employs targeted long-read sequencing to generate haplotype-resolved assemblies of IGK proximal and distal regions [6,7,8]. Here, we characterize IGKC, IGKJ, and IGKV alleles in 36 individuals from the 1000 genomes project (1KGP) [30]. We report 67 novel IGKV alleles and provide evidence of inter-population variation in IGKV allele frequencies. We identify a SV that includes a previously unlocalized IGKV gene (IGKV1-NL1) and provide evidence that this SV is common across populations. In addition, we report a novel large inversion that involves both proximal and distal region genes, and validate a previously described gene conversion event [14], which we also show is associated with haplotype structure in the IGK distal region.
Material and methods
Sample information
Samples used in this study were previously collected as part of the 1KGP [30]. Genomic DNA isolated from lymphoblastoid cell lines (LCLs) were procured for all individuals from the Coriell Institute for Medical Research (https://www.coriell.org/; Camden, NJ). Sample population, subpopulation, and sex are reported in Table S1.
Construction of a custom reference assembly for the IGK locus
The GRCh38 assembly gap between the IGK proximal and distal regions was modified as follows: 10 Kbp of sequence in the GRCh38 assembly upstream of IGKV2-40 and downstream of IGKV2D-40 was replaced with homologous sequence in the T2T assembly [15]; the remaining 190,249 bases in the GRCh38 assembly gap were N-masked. 24,729 bp in a hifiasm-generated assembly for the sample HG02433 were inserted between IGKV1D-8 and IGKV3D-7; 10 Kbp of sequence flanking the insertion in this assembly was swapped with homologous sequence in GRCh38. An example of a haplotype harboring this insertion mapped to GRCh38 is shown in Fig. S1.
Coordinates of IGK gene features (L-Part1, Intron, V-exon, RSS) were determined using the program ‘Digger’ (https://williamdlees.github.io/digger/_build/html/index.html) and will be made available, along with the custom reference, at https://vdjbase.org/.
IGK sequencing and phased assembly
To enrich for DNA from the IGK locus, we designed a custom Roche HyperCap DNA probe panel (Roche) that includes target sequences from the GRCh38 IGK proximal (chr2:88,758,000-89336429) and distal (chr2:89846189-90,360,400) regions. Genomic DNA samples were prepared and sequenced following previously described methods [6,7,8]. Briefly, genomic DNA was sheared to ~16 Kbp using g-tubes (Covaris, Woburn, MA, USA) and size-selected using the Blue Pippin system (Sage Science, Beverly, MA, USA) using the "high pass" protocol to select fragments greater than 5 Kbp. Size-selected DNA was ligated to universal barcoded adapters and amplified, then individual samples were pooled in groups of six prior to IGK enrichment using the custom Roche HyperCap DNA probes. Targeted fragments were amplified after capture to increase total mass, followed by SMRTBell Express Template Prep (Kit 2.0, Pacific Biosciences) and SMRTBell Enzyme Cleanup (Kit 2.0, Pacific Biosciences), according to the manufacturer’s protocol. Resulting SMRTbell libraries were pooled in 12-plexes and sequenced using one SMRT cell 8 M on the Sequel IIe system (Pacific Biosciences) using 2.0 chemistry and 30 hour movies. Following data generation, circular consensus sequencing analyses were performed, generating high fidelity (“HiFi”, >Q20 or 99.9%) reads for downstream analyses. Reads aligned to our custom reference were input to bamtocov [31] for coverage analysis (Fig. S2).
HiFi reads were processed using IGenotyper [8]; the programs “phase” and “assemble” were run with default parameters to generate phased contigs and Hifi read alignments to the custom IGK reference assembly. HiFi reads were also used to generate haplotype-phased de novo (i.e. reference-agnostic) assemblies using Hifiasm [32] with default parameters. For each sample, Hifiasm assembly contigs were concatenated into a single FASTA file, then redundant contigs (i.e. a contig with 100% sequence identity to a second contig) were filtered out to retain only unique contigs using the program ‘seqkit rmdup --by-seq <hifiasm_contigs.fasta > ’ (seqkit v2.4.0) [33]. Hifiasm assembly contigs were mapped to the custom IGK reference using minimap2 (v2.26) with the ‘-x asm20’ option. For each sample, aligned HiFi reads as well as aligned IGenotyper-generated contigs and Hifiasm-generated contigs were viewed in the Integrative Genomics Viewer (IGV) application [34] for manual selection of phased contigs. Where a Hifiasm and an IGenotyper contig were identical throughout a phased block, the Hifiasm contig was selected (example: Fig. S3). Examples of contig selection are provided in Figs. S3-S7. Contigs were evaluated for read support from mapped HiFi reads (example shown in Fig. S4), and contigs harboring one or more SNVs that lacked read support were not selected during manual curation.
Curated, phased assemblies were aligned to the custom IGK reference using minimap2 [35] with the ‘-x asm20’ option. Phased assembly coverage across IGK (Fig. S8) was computed using ‘bedtools coverage’ (bedtools v2.30.0) [36]. Average IGenotyper and Hifiasm contig lengths across IGK (Fig. S2) were computed by extracting contig lengths using ‘samtools view’.
To assess accuracy of manually curated assemblies, IGK-personalized references were first generated by N-masking the IGK locus of our custom reference (chr2:88837161-90280099) and, for each sample, appending the reference FASTA file with IGK curated assemblies (i.e. all IGK contigs). HiFi reads from each individual were aligned to the corresponding IGK-personalized reference using minimap2 with the ‘-x map-hifi’ preset. Positions in IGK assemblies with > 25% of aligned HiFi reads mismatching the assembly were identified by parsing the output of samtools ‘mpileup’ using a custom bash script; assembly accuracy was determined using the formula [total bases without a mismatch / total (diploid) assembly length (bp)] * 100 = % accuracy (Table S2).
Genotyping and analysis of IGK assemblies
Sample IDs were inserted into the @RG tag of curated assembly BAM files using the ‘samtools addreplacerg’ command (samtools v1.9) [37]. Variants were called from assemblies using the ‘bcftools mpileup’ (bcftools v1.15.1) command with options ‘-f -B -a QS’ and a ‘--regions’ (BED) file corresponding to the IGK locus (proximal: chr2:88866214-89331428, distal: chr2:89851190-90265885), then the ‘bcftools call’ command with the ‘-m’ option. Multiallelic SNVs were split into biallelic SNVs using the ‘bcftools norm’ command with options ‘-a -m-’. A mutli-sample VCF file was generated using ‘bcftools merge’ with the ‘-m both’ option, and the INFO field annotations for V-exon, introns, L-Part1, RSS, and intergenic sequences were added using vcfanno [38]. The VCF file was filtered to include SNVs with an alternate allele count > 1 (MAF ≥ 2.86%) using ‘bcftools view’ with the ‘-v snps -i ‘INFO/AC > 1.0’ options’.
The filtered VCF file was input for principal component analysis (PCA) of SNVs in the IGK distal region (chr2:89852177-90266726) using the SNPRelate package [39] command ‘snpgdsVCF2GDS’ with the option ‘method = “biallelic.only”’ followed by the ‘snpgdsPCA’ command with default parameters. The SNPRelate command ‘snpgdsIBS’ was used to calculate a pairwise dissimilarity matrix from distal region SNVs, followed by hierarchical clustering using the ‘snpgdsHCluster’ function. The outputs of these functions were input to the functions ‘snpgdsCutTree’ and ‘snpgdsDrawTree’ to generate a dendrogram.
A parsable genotype table was generated from the filtered VCF using ‘bcftools query’ and read into R for analysis. SNV densities over genomic intervals were calculated using the formula: SNV density = [sum of alternate alleles over interval / interval length (bp) * 2]. 10 Kbp intervals along the IGK distal region were generated using the ‘bedtools makewindows’ [36] command. dbSNP data were downloaded from the UCSC Table Browser [40] (dbSNP ‘common variants’ release 153). The 1KGP “phase 3” GRCh38 chromosome 2 multi-sample VCF file (https://ftp.1000genomes.ebi.ac.uk/vol1/ftp/data_collections/1000G_2504_high_coverage/working/phase3_liftover_nygc_dir/phase3.chr2.GRCh38.GT.crossmap.vcf.gz) was filtered to include only the IGK locus (chr2:88866214-90265885) excluding the intervening gap region (chr2:89331429-89851189), split into single-sample files, filtered to include only SNVs using bcftools ‘view’, and compared with SNVs from curated assemblies using bedtools ‘intersect’. The downloaded multi-sample VCF file included 33 of 36 samples used in this study. Both dbSNP and 1KGP coordinates were lifted over to our custom reference to account for the SV insertion.
Identification of IGKC, IGKJ, and IGKV alleles
Allele sequences at V-exons, J-exons, and C-exons were extracted from assembly BAM files and queried against all human immunoglobulin alleles in the IMGT database (downloaded 2023-09-26) using custom python scripts and tools available in the receptor_utils library (https://pypi.org/project/receptor-utils/). Custom python and bash scripts were used to generate metrics of HiFi read support for novel alleles. Briefly, for each sample, IGK assemblies were appended to our custom reference with the IGK locus N-masked to generate an IGK-personalized reference FASTA. All HiFi reads from IG-capture were mapped to the IGK-personalized reference using minimap2 with the option ‘-ax map-hifi’, then the resulting BAM file was input to samtools ‘mpileup’ with iteration over allele coordinates in the IGK-personalized reference. The outputs of this script are in columns 17-26 of Table S3 and include a column for total number of HiFi reads spanning the novel allele (‘Fully_Spanning_Reads’) and a column for the number of HiFi reads spanning the novel allele with 100% sequence identity (‘Fully_Spanning_Reads_100%_Match’). A complete description of HiFi read support metrics for alleles is available at https://vdjbase.org/. Novel alleles were analyzed using IMGT/V-QUEST [41] to determine the presence of synonymous, non-synonymous, and frame-shift substitutions.
Statistical analyses
Statistical tests described in Results and Figure Legends were performed in R (v4.2.1).
Results
Assembly of the IG kappa chain locus
To sequence the IGK locus, we extended our previously described method [6,7,8] such that genomic DNA fragments derived from this locus were enriched using targeted probes and sequenced using single-molecule, real-time (SMRT) long-read sequencing. This methodology was applied to an ancestrally diverse cohort (n = 36; Table S1) to assess genetic variants in IGK across different populations. The cohort represented individuals of African (AFR, n = 8), East Asian (EAS, n = 7), South Asian (SAS, n = 10), European (EUR, n = 10), and Central American (AMR, n = 1) ancestry, spanning 18 subpopulations. Average high quality (>99% accuracy, “HiFi”) read coverage across the custom IGK reference (see Materials and Methods) was > 50X within the proximal and distal IGK regions for all samples (Fig. S2). HiFi reads were assembled into phased contiguous sequences (contigs) using both IGenotyper [6, 8], which uses reference-aligned reads to generate contigs, and Hifiasm [32], which generates a de novo diploid assembly (Fig. S1). The resulting phased contigs were assessed for read support and merged (see Materials and Methods) into manually-curated diploid assemblies (see Materials and Methods and Figs. S3–S7), which on average spanned 99.3% (479.53 Kbp) and 99.7% (413.26 Kbp) of the proximal and distal regions, respectively (Fig. S8). Accuracies of manually-curated diploid assemblies were determined by alignment of HiFi reads to IGK-personalized references (see Materials and Methods) and ranged from 99.84% to 99.97% (mean: 99.95%) (Table S2). Assembly contigs could not be phased between proximal and distal regions due to the extended non-IGK sequence region not covered by our probe panel; additionally, we cannot fully account for the possibility of rare phase-switch errors present in hifiasm assemblies. However, all assemblies were locally phased over each variant position, allowing us to effectively genotype IGK gene loci and locus-wide polymorphisms. For IGK gene and allele annotation, as well as variant calling, curated assemblies were aligned to our in-house reference assembly, which included a novel SV insertion identified in this cohort (see also Materials and Methods).
Characterization of IGKV alleles
Allele sequences were annotated and extracted from haplotype-resolved sequences of all donors for 47 functional/ORF IGKV genes. These alleles were compared against those cataloged in IMGT [17], revealing both known (n = 78) and novel (n = 67) alleles (Fig. 1A, Tables S3 and S4). Of the 67 novel alleles, 23 were observed in >1 individual; 9 of the 67 alleles were also independently supported by alleles curated in VDJbase [42] (Table S3). Novel alleles were assessed for HiFi read support quantitatively, revealing a minimum of 5 HiFi reads supporting each allele with 100% sequence identity (mean: 46.7 supporting reads, range: 5-181 supporting reads; Table S3), and qualitatively by visualization in IGV of HiFi reads mapped to alleles in curated assemblies (Fig. S9).

A Diagram of alleles for the single IGKC gene, 5 IGKJ genes, and 47 IGKV genes. Individuals (rows) are split into two sub-rows, each indicating the allele for a gene (column). Tile colors correspond to allele sequences cataloged in the IMGT database, which have numerical designations. Allele sequences absent from IMGT are considered novel and colored lime-green. Gray tiles represent allele absence due to structural variation (deletion); white tiles represent regions unresolveable due to V(D)J recombination artifacts (see Fig. S8), which we have shown previously to occur in DNA derived from some LCLs [7, 8]. Locally phased assemblies were created for the proximal and distal regions separately; individual sub-rows do not represent locus-wide haplotypes. B Bar plot of the percent of individuals in each population that are heterozygous for 47 IGKV genes. C Stacked bar plot of the number of known and novel alleles for each of 47 IGKV genes; at least one novel allele was identified for 33 of these genes. D Bar plot of the number of individuals that have at least one allele for each of 67 novel alleles. Each novel allele is colored to indicate the presence of a) only synonymous, b) at least one non-synonymous, or c) a frame-shift substitution. E Bar plot of the average number of novel alleles identified per individual for each population. F Venn diagram illustrating the distribution of 67 novel alleles among populations. G Stacked bar plot of the number of individuals (colored by population) with at least one novel allele for each of 33 IGKV genes.
Genes with a single identified allele were determined to be homozygous across all individuals; these genes included IGKV3-11, IGKV1-37, IGKV1D-43, and IGKV3D-7 (Fig. 1A, 1B). IGKV genes that were heterozygous in at least half of all individuals included IGKV5-2, IGKV1-5, IGKV1-8, IGKV1-13, IGKV1-17, IGKV3D-15 and IGKV3D-11 (Fig. 1B). Heterozygosity varied among populations for several genes, including IGKV3-15, IGKV1-27, IGKV2-29, IGKV2-30, IGKV1-39, IGKV2-40, and IGKV2D-40 (Fig. 1B).
Novel alleles were identified for 17 of 24 proximal genes and 18 of 23 distal genes (Fig. 1C) (Table S3). Among the 23 novel alleles identified in >1 individual, 10, 12, and 1 resulted in synonymous, non-synonymous, and frame-shift substitutions, respectively (Fig. 1D). Sixteen of the 67 novel alleles differed from the closest-matching IMGT allele by at least 2 nucleotides (range: 1-8 nucleotides) (Fig. S10). Thirty-three individuals (91.7%) carried at least one novel allele, with individuals of African descent harboring ~10 novel alleles per individual on average (range: 8-14) and individuals from other populations harboring ~2-3 novel alleles on average (ranges; EAS: 1-6, SAS: 0-8, EUR: 0-8) (Fig. 1E). Fifty-three (79%) of the novel alleles were exclusive to a single population, of which, 33 were identified only in AFR individuals (Fig. 1F). Fourteen of the novel alleles were identified in two or more populations (Fig. 1F).
Among all functional/ORF IGKV genes, the number of individuals harboring at least one novel allele was highest for IGKV1-13 (24 individuals), IGKV2D-26 (18 individuals), IGKV2D-40, IGKV2D-28 and IGKV3D-15 (11 individuals each), followed by IGKV1-6, IGKV2-40, IGKV1-27, and IGKV1D-42 ( > 3 individuals each) (Fig. 1G).
Single nucleotide polymorphism in the IGKV proximal and distal loci
In addition to variants within IGKV V-exon regions, we also characterized SNVs across the whole of the IGK locus. We enumerated 3,396 SNVs for which we observed >1 individual carrying an alternate allele relative to our reference (equivalent to a MAF ≥ 2.86%). Of these, 42% and 57.8% were absent from the dbSNP ‘common variants’ dataset in the proximal and distal regions, respectively (Fig. 2A). Sample-level comparison of SNV positions identified in this study with those from short read-derived (1KGP) data revealed that, on average, 58% of SNV positions were uniquely identified in our curated assemblies and 37.9% were identified in both datasets (Fig. 2B, Table S5), consistent with known limitations of short reads for genotyping genomic regions enriched with duplicated sequence [8, 10, 43,44,45]. SNV positions were more numerous in individuals of non-EUR ancestry, most notably among individuals of AFR ancestry (Fig. 2B).

A Stacked bar plot of the number of SNVs (MAF ≥ 2.86%) in the IGK proximal and distal regions. Bar colors indicate SNV inclusion in dbSNP. B Stacked bar plot of IGK locus SNV positions found uniquely in the 1KGP “phase 3” release, uniquely in curated assemblies generated in this study (long read-based assemblies), or in both, for 33 individuals. Total SNV positions are indicated above bars. C Pie charts of SNV distribution among genic (functional IGKV genes) and intergenic regions in proximal and distal regions of IGK. D Boxplots of SNV densities in IGK proximal and distal regions for each individual (data point). Gray dashed lines indicate paired SNV density values for individuals. Gray shading of data points indicates data point overlap. P-values: paired Wilcoxon tests.
We categorized the 3,396 SNVs as overlapping either intergenic sequence or an IGKV gene feature, including the leader part 1 (L-Part1), intron, V-exon, or recombination signal sequence (RSS). While the majority of SNVs were intergenic (Fig. 2C), SNV density was greater in V-exons, L-Part1 regions, and introns relative to intergenic and overall SNV densities (Fig. S11). Partitioning of SNVs into proximal and distal also revealed that, for each feature except V-exons, there was increased SNV density in the distal relative to proximal region for the majority of (but not all) individuals (Fig. 2D).
Characterization of structural variants, a gene conversion haplotype and associated SNV signatures
We analyzed our curated assemblies for evidence of large structural events. This revealed the presence of a ~ 24.7 Kbp insertion between IGKV1D-8 and IGKV3D-7 in a large fraction of haplotypes in our cohort (Fig. S1); this insertion is not present in GRCh38. The insertion sequence was queried against alleles from the IMGT database using BLAT [46], revealing the presence of a single functional IGKV gene, IGKV1-NL1 (IGKV1-“not localized 1”); this sequence was integrated into the reference assembly used for all analyses in this study (see Materials and Methods) and its absence was codified as a deletion (Fig. 3A, Table S1). The frequency of the deletion was 50% in AFR as compared to 78.6%, 90%, and 85% in EAS, SAS, and EUR populations, respectively (Fig. 3B). The distribution of this SV allele in AFR versus non-AFR groups was significantly different (Fisher’s exact test, P < 0.01) (Table S6). Among 35 individuals, one EAS and two AFR samples were identified as homozygous for the IGKV1-NL1 allele (Fig. 1A).

A Diagram of structural polymorphisms in the IGK locus, including a gene conversion event in which ~16 Kbp of sequence containing IGKV1-12 and IGKV1-13 replaced paralogous sequence in the distal region, described previously [14]. Also shown is an inversion spanning the proximal and distal regions from IGKV1-27 to IGKV1D-27 with a length of ~ 1.301 Mbp (see Fig. S12), and a 24.7 Kbp deletion SV that includes the gene IGKV1-NL1. B Stacked bar plot indicating the SV genotype frequencies for each population, with “1” corresponding to deletion. C Stacked bar plot indicating the gene conversion haplotype frequency for each population, with “1” corresponding to the conversion haplotype. D Boxplot of the SNV density difference between distal and proximal regions with samples grouped according to their genotype for the gene conversion (left) as well as population (right). SNV densities were computed for 10 Kbp windows along the proximal and distal regions from alignments of IGK proximal assemblies to the proximal region of our custom reference and, likewise, alignments of IGK distal assemblies to the distal region of our custom reference (see Materials and Methods). For each sample, the mean SNV density for the distal region was subtracted from the mean SNV density value for the proximal region. E (Top) SNV densities in 10 Kbp windows along the IGK distal region (chr2:89859172-90266726). IGKV genes in this interval are labeled along the x-axis. Each line represents a sample. Samples are grouped according to their genotype for the gene conversion. (Bottom) Genotypes (colors) at each variant position for the corresponding coordinates above. The “.” symbol represents deletion. Hierarchical clustering of samples (rows) resulted in the 3 indicated clusters. F Principal component analysis of samples based on SNVs (MAF ≥ 2.86%) in the IGK distal region. Samples are colored by population (left) or gene conversion genotype (right). EV1: eigenvector 1, EV2: eigenvector 2.
During assembly curation, we noted an unusual pattern of SNVs in one sample (HG02433, AFR) over the genes IGKV1-27 and IGKV1D-27 wherein half of each read was enriched with mismatches (Fig. S12). The portion of each read that was enriched with mismatches mapped to the paralogous region when aligned by BLAT against GRCh38, but in the opposite orientation, suggesting that such reads span the breakpoints of an inversion involving the proximal and distal regions (Figs. 3A, S12). Hifiasm generated contigs in agreement with these reads (Fig. S12). Analysis of additional haplotypes will be needed to determine the frequency and population distribution of this putative SV.
Watson et al. [14] previously reported a gene conversion event wherein a ~ 16 Kbp region that includes IGKV1-13 was swapped into the paralogous distal region (Fig. 3A). Relative to a reference sequence that does not contain this sequence exchange, a haplotype with the gene conversion is marked by high SNV density within a ~ 16 Kbp window that spans IGKV1D-12 and IGKV1D-13 (Fig. S5). Genotyping of this gene conversion event revealed that it is a common haplotype structure in the population, with a frequency ≥ 70% in EUR, SAS, and EAS populations, and a frequency of 37.5% in AFR populations (Fig. 3C, Table S1). The distribution of the gene conversion haplotype in AFR versus non-AFR groups was significantly different (Fisher’s exact test, P < 0.01) (Table S6). In this cohort, the four individuals homozygous for the reference (non-conversion) haplotype (HG01887; AFR, HG02107; AFR, HG02284; AFR, HG00136; EUR) were also the only four individuals homozygous for IGKV1D-13*02, IGKV1D-12*02, and IGKV3D-11*02 (Fig. 1A), which may indicate that the gene conversion haplotype structure extends beyond the previously identified ~16 Kbp region.
Based on the observation that most, but not all, individuals exhibit increased SNV density in the distal region relative to proximal region (Fig. 2D), we computed the within-individual difference between distal and proximal SNV densities and then partitioned individuals by genotype for the gene conversion event (Fig. 3D). This analysis revealed that the gene conversion haplotype was associated with increased SNV density in the distal region (Fig. 3D). Accordingly, SNV density in the region spanning IGKV1D-12 and IGKV1D-13 increases with dosage of the gene conversion haplotype (Fig. 3E). We noted increased SNV density throughout an ~70 Kbp region downstream of IGKV1D-13 extending to IGKV1D-17, and also throughout an ~30 Kbp region from IGKV3D-11 to downstream of IGKV1D-43 (Fig. 3E), further suggesting that the gene conversion haplotype structure is extended beyond the ~16 Kbp region containing IGKV1D-12 and IGKV1D-13. Hierarchical clustering (Fig. 3E, Fig. S13) and PCA (Fig. 3F) based on these distal region SNVs revealed separation of individuals based on their genotype for the gene conversion haplotype. In this cohort, we observed differences between AFR and non-AFR individuals with respect to the combinations of the gene conversion genotype and SV genotype; AFR individuals were neither i) homozygous for the gene conversion and homozygous for the SV deletion, or ii) heterozygous for the gene conversion and homozygous for the SV deletion, whereas 19 of 27 ( ~ 70%) individuals of non-AFR ancestry possessed these combinations of genotypes (Fig. S14).
To determine associations between the gene conversion and IGKV alleles, we tested for IGKV allele frequency distribution differences between individuals of each gene conversion genotype group. This analysis revealed significant associations for 13 IGKV genes (Fig. S15; chi-square P < 0.05). The strongest associations were for genes within the gene conversion region (IGKV1D-13, IGKV1D-12), three genes within ~50 Kbp of this region (IGKV3D-15, IGKV1D-42, and IGKV1D-8), and three genes ~160-200 Kbp away from this region (IGKV2D-29, IGKV2D-28, IGKV2D-26). Homozygotes for the gene conversion harbored only the *01 allele for IGKV1D-13 and IGKV1D-12, whereas homozygotes for the non-conversion haplotype harbored only *02 alleles for these genes (Fig. S15). These data suggest that the gene conversion haplotype associates with variation in IGKV allele frequencies in the distal region.
Inter-population IGKV allelic variation
Coding sequences in the human IGH and IGL loci have been shown to exhibit population-level allelic diversity [6, 7, 11, 23]. Although our cohort is relatively small in number, we observed that functional/ORF IGKV genes also exhibited inter-population differences in allele frequency (Fig. 4A, Table S8). In total, 10 of the 47 IGKV genes demonstrated significant skewing in allele frequencies (Fig. 4B; chi-square, FDR < 0.05). For example, the alleles IGKV1-5*04 and IGKV1-8*02 were not identified in AFR or SAS individuals, but each had an allele frequency of 0.43 and 0.1 in EAS and EUR individuals, respectively (Fig. 4A). The alleles IGKV6-21*02, IGKV2-24*02, and IGKV1-27*02 were similarly enriched in EAS individuals (Fig. 4A). These inter-population differences in allele frequency appeared to correlate with overall SNV density as six of seven EAS individuals showed SNV density patterns between IGKV6-21 and IGKV1-27 that were highly similar and, on average, distinct from AFR, EUR, and SAS populations (Fig. S16). Seven alleles were identified only in AFR individuals and also had an intra-population allele frequency of 0.25 or greater, including IGKV2-29*03, IGKV1-39*02, IGKV3-15*02, and the novel alleles IGKV2D-28_N1, IGKV1-27_N1, IGKV1D-42_N1, and IGKV2D-40_N1 (Fig. 4A, Table S7). We noted that SNV density was uniquely elevated in 75% (6/8) of AFR individuals in a region including IGKV1-39 and IGKV2-40 (Fig. S16), suggesting a relationship between haplotype structure and gene alleles in this region. The frequencies of the novel alleles IGKV2D-26_N1 and IGKV2D-29*02 were > 4-fold higher in AFR relative to each other population (Fig. 4A–B). In contrast, the frequency of IGKV2D-29*01 was 0.19 in AFR and ~0.9 in EUR, SAS, and EAS populations. As noted above (Fig. 1A, Fig. S15), the *02 alleles for IGKV1D-13, IGKV1D-12, and IGKV3D-11 were homozygous in three AFR individuals and one EUR individual; there was a trend of increased frequency of these *02 alleles in AFR individuals (Fig. 4A).

A Stacked bar plot of allele frequencies for each of 47 functional IGKV genes for AFR, EAS, SAS, and EUR populations. For each gene, a color corresponds to a unique allele (detailed in Table S7). Gray color indicates allele absence due to structural variation (deletion). B Differences in allele frequency distributions among populations were determined using a chi-square test (Table S8); Benjamini-Hochberg adjusted (False Discovery Rate) P-values (Padj) are plotted as -log10(Padj) for each gene. Red points indicate Padj < 0.05.
Among non-AFR populations, only two genes showed significant inter-population variation in allele frequency, with enrichment of IGKV6-21*02 and IGKV1-27*02 in EAS relative to EUR and SAS (Figs. S17, 4A), suggesting that AFR haplotypes significantly contribute to observed variation in inter-population allele frequency distributions among IGKV genes.
Discussion
Genomic loci enriched with SDs, including the IGK locus [14, 23], lack complete and accurate information on population-level variation due to shortcomings of short-read sequencing [10, 47, 48]. Here, we used a SMRT long-read sequencing and analysis framework to characterize diploid IGK assemblies from 36 individuals of African, East Asian, South Asian, European, and Central American ancestry. These assemblies represent a significant advance, increasing the number of available curated assemblies 18-fold, from 4 [13,14,15, 18] to 72 haplotypes. We identified a common SV ~ 24.7 Kbp in length that includes a functional IGKV gene observed more frequently in AFR individuals relative to three other populations. One AFR haplotype in this cohort had evidence of an inversion spanning ~1.301 Mbp ~, with breakpoint-spanning reads covering IGKV1-27 and IGKV1D-27. Analysis of 47 functional IGKV genes revealed at least one novel allele for 35 of these genes, with 67 novel alleles identified in total. Ten IGKV genes showed evidence of inter-population allelic variation, including alleles unique to specific populations within this dataset. Finally, we observed a common gene conversion event that associates with a distinct IGK distal haplotype structure. This gene conversion haplotype may be a significant driver of genetic variation in the IGK distal region.
Databases of germline IG alleles are foundational for the analysis and interpretation of AIRR-seq data [48, 49] and, more fundamentally, genotyping is required to determine the impact of IG germline variation on IG gene usage in antibody repertoires [6]. To our knowledge, the data presented here represent the first survey of human IGK haplotypes in an ancestrally diverse cohort. Novel IGKV allele sequences described in this study represent a ~ 64% increase in IGKV alleles available in IMGT. These alleles and their associated haplotype data have been made available in VDJbase and the Open Germline Receptor Database (OGRDB) as part of an ongoing effort to build population-representative germline allele databases [42, 50, 51] that can be leveraged for applications such as AIRR-seq analysis [52]. The high prevalence of novel alleles in AFR individuals relative to the other populations in this study reflects the ongoing need to generate genomic resources that are representative of the global population [45].
Deficits in existing resources for other forms of genetic variation were also observed in this dataset. For example, of the >3,000 common SNVs identified, 49.7% were not found in dbSNP. This is likely a reflection of the fact that locus complexity has hindered the use of high-throughput genotyping methods for cataloging IGK variants. We demonstrated that for most individuals in our cohort, over half of the SNVs called using our approach were missing from the 1KGP phase 3 genotype sets. This result alone implies that genetic disease association studies in the IGK locus have likely not effectively surveyed genetic diversity in this region.
Structural variation is common in the IG loci [4, 6, 7, 14]; here, we identified a haplotype harboring an inversion spanning 15 functional/ORF genes across the IGK proximal and distal regions, as well as a ~ 24.7 Kbp insertion in the IGK distal region that includes the functional gene IGKV1-NL1. To our knowledge, this is the first inversion characterized in the IG loci. Higher frequency of the insertion sequence in AFR individuals is consistent with the observation that AFR populations harbor increased amounts of sequence in SD regions genome-wide [53, 54]. Inclusion of this SV in future human genome references will be important for not only describing IGKV1-NL1 alleles, but also for genotyping all SNVs in this SV that can be tested for association with immune-related phenotypes. It is notable that these were the only two SVs identified in this cohort, indicating that SVs may be less characteristic of the IGK locus relative to IGH.
It is documented that SDs provide substrates for more frequent gene conversion, in some cases leading to enrichments of SNVs [47]. We previously reported the existence of two distinct haplotype structures within ~16 Kbp of the IGK distal region; one of these haplotypes harbored a gene conversion involving sequence exchange between IGKV1D-13 and IGKV1-13 [14]. Here, we demonstrated that haplotypes harboring the gene conversion are common in the population and associate with increased SNV density (relative to the remainder of the IGK distal region) throughout ~100 Kbp ranging from IGKV1D-17 to IGKV1D-43. The frequency of both the gene conversion haplotype and the IGKV1-NL1 SV were similar in EAS, SAS, and EUR populations but distinct among AFR individuals. Whereas most individuals from other populations were grouped into clusters by the PCA based on variants in the distal region (Fig. 3F), individuals of AFR ancestry were more dispersed, suggesting the potential for greater haplotype diversity in these populations. However, given the smaller sized cohort analyzed here, analysis of additional haplotypes will be needed to determine the extent of inter-population variation in IGK proximal and distal regions.
Considering that IGH germline variants are associated with usage of IGH genes in expressed antibody repertoires [6], we hypothesize that the usage of IGK genes will also likely be associated with SNVs and SVs identified here. AIRR-seq studies focused on IGL and IGK have shown inter-individual variation in germline gene usage and alternative splicing in expressed light chain repertoires [55]. The data and analytical framework presented here lay a foundation for testing the impact of IGK locus-wide (coding and non-coding) germline variants on variation in the expressed antibody repertoire in diverse human populations. This will expand our understanding of the collective roles of IG germline variation across the IGH, IGL and IGK loci in antibody diversity and function, including potential genetic interactions between these complex gene regions and their coevolution [21, 23]. This will ultimately be critical for identifying coding alleles and haplotype variation as determinants of disease susceptibility and clinical phenotypes, including autoimmunity, cancer, infection, and vaccine efficacy [9, 11, 21, 24, 56,57,58,59,60,61,62,63,64,65,66,67,68].
Data availability
Novel alleles are provided in Table S3. Mapped sequence data and assemblies will be made available at https://vdjbase.org/ with sample metadata. Raw data are undergoing submission to BioProject PRJNA555323.
References
Weaver C, Murphy K Janeway’s immunobiology. Garland Sci. 2016. https://hero.epa.gov/hero/index.cfm/reference/details/reference_id/7124292
Lefranc M-P, Lefranc G The Immunoglobulin FactsBook. Academic Press; (2001).
Tonegawa S. Somatic generation of antibody diversity. Nature. 1983;302:575–81.
Watson CT, Steinberg KM, Huddleston J, Warren RL, Malig M, Schein J, et al. Complete haplotype sequence of the human immunoglobulin heavy-chain variable, diversity, and joining genes and characterization of allelic and copy-number variation. Am J Hum Genet. 2013;92:530–46.
Kidd MJ, Chen Z, Wang Y, Jackson KJ, Zhang L, Boyd SD, et al. The inference of phased haplotypes for the immunoglobulin H chain V region gene loci by analysis of VDJ gene rearrangements. J Immunol. 2012;188:1333–40.
Rodriguez OL, Safonova Y, Silver CA, Shields K, Gibson WS, Kos JT, et al. Genetic variation in the immunoglobulin heavy chain locus shapes the human antibody repertoire. Nat Commun. 2023;14:4419.
Gibson WS, Rodriguez OL, Shields K, Silver CA, Dorgham A, Emery M, et al. Characterization of the immunoglobulin lambda chain locus from diverse populations reveals extensive genetic variation. Genes Immun. 2023;24:21–31.
Rodriguez OL, Gibson WS, Parks T, Emery M, Powell J, Strahl M, et al. A Novel Framework for Characterizing Genomic Haplotype Diversity in the Human Immunoglobulin Heavy Chain Locus. Front Immunol. 2020;11:2136.
Watson CT, Breden F. The immunoglobulin heavy chain locus: genetic variation, missing data, and implications for human disease. Genes Immun. 2012;13:363–73.
Watson CT, Matsen FA 4th, Jackson KJL, Bashir A, Smith ML, Glanville J, et al. Comment on “A Database of Human Immune Receptor Alleles Recovered from Population Sequencing Data.”. J Immunol. 2017;198:3371–3.
Watson CT, Glanville J, Marasco WA. The Individual and Population Genetics of Antibody Immunity. Trends Immunol. 2017;38:459–70.
Collins AM, Yaari G, Shepherd AJ, Lees W, Watson CT. Germline immunoglobulin genes: disease susceptibility genes hidden in plain sight? Curr Opin Syst Biol. 2020;24:100–8.
Kawasaki K, Minoshima S, Nakato E, Shibuya K, Shintani A, Asakawa S, et al. Evolutionary dynamics of the human immunoglobulin kappa locus and the germline repertoire of the Vkappa genes. Eur J Immunol. 2001;31:1017–28.
Watson CT, Steinberg KM, Graves TA, Warren RL, Malig M, Schein J, et al. Sequencing of the human IG light chain loci from a hydatidiform mole BAC library reveals locus-specific signatures of genetic diversity. Genes Immun. 2015;16:24–34.
Nurk S, Koren S, Rhie A, Rautiainen M, Bzikadze AV, Mikheenko A, et al. The complete sequence of a human genome. Science. 2022;376:44–53.
Juul L, Hougs L, Barington T. A new apparently functional IGVK gene (VkLa) present in some individuals only. Immunogenetics. 1998;48:40–46.
Giudicelli V, Chaume D, Lefranc M-P. IMGT/GENE-DB: a comprehensive database for human and mouse immunoglobulin and T cell receptor genes. Nucleic Acids Res. 2005;33:D256–61.
Zhang J-Y, Roberts H, Flores DSC, Cutler AJ, Brown AC, Whalley JP, et al. Using de novo assembly to identify structural variation of eight complex immune system gene regions. PLoS Comput Biol. 2021;17:e1009254.
Gadala-Maria D, Gidoni M, Marquez S, Vander Heiden JA, Kos JT, Watson CT, et al. Identification of Subject-Specific Immunoglobulin Alleles From Expressed Repertoire Sequencing Data. Front Immunol. 2019;10:129.
Peres A, Lees WD, Rodriguez OL, Lee NY, Polak P, Hope R, et al. IGHV allele similarity clustering improves genotype inference from adaptive immune receptor repertoire sequencing data. Nucleic Acids Res. 2023;51:e86.
Pennell M, Rodriguez OL, Watson CT, Greiff V. The evolutionary and functional significance of germline immunoglobulin gene variation. Trends Immunol. 2023;44:7–21.
Gidoni M, Snir O, Peres A, Polak P, Lindeman I, Mikocziova I, et al. Mosaic deletion patterns of the human antibody heavy chain gene locus shown by Bayesian haplotyping. Nat Commun. 2019;10:628.
Collins AM, Watson CT. Immunoglobulin Light Chain Gene Rearrangements, Receptor Editing and the Development of a Self-Tolerant Antibody Repertoire. Front Immunol. 2018;9:2249.
Shrock EL, Timms RT, Kula T, Mena EL, West AP Jr, Guo R, et al. Germline-encoded amino acid-binding motifs drive immunodominant public antibody responses. Science 2023;380:eadc9498.
Guthmiller JJ, Han J, Utset HA, Li L, Lan LY-L, Henry C, et al. Broadly neutralizing antibodies target a haemagglutinin anchor epitope. Nature. 2022;602:314–20.
Havenar-Daughton C, Sarkar A, Kulp DW, Toy L, Hu X, Deresa I, et al. The human naive B cell repertoire contains distinct subclasses for a germline-targeting HIV-1 vaccine immunogen. Sci Transl Med. 10. https://doi.org/10.1126/scitranslmed.aat0381 (2018).
Robbiani DF, Bozzacco L, Keeffe JR, Khouri R, Olsen PC, Gazumyan A, et al. Recurrent Potent Human Neutralizing Antibodies to Zika Virus in Brazil and Mexico. Cell. 2017;169:597–609.e11.
Roy B, Neumann RS, Snir O, Iversen R, Sandve GK, Lundin KEA, et al. High-Throughput Single-Cell Analysis of B Cell Receptor Usage among Autoantigen-Specific Plasma Cells in Celiac Disease. J Immunol. 2017;199:782–91.
Hehle V, Fraser LD, Tahir R, Kipling D, Wu Y-C, Lutalo PMK, et al. Immunoglobulin kappa variable region gene selection during early human B cell development in health and systemic lupus erythematosus. Mol Immunol. 2015;65:215–23.
1000 Genomes Project Consortium, Auton A, Brooks LD, Durbin RM, Garrison EP, Kang HM, et al. A global reference for human genetic variation. Nature. 2015;526:68–74.
Birolo G, Telatin A. BamToCov: an efficient toolkit for sequence coverage calculations. Bioinformatics. 2022;38:2617–8.
Cheng H, Concepcion GT, Feng X, Zhang H, Li H. Haplotype-resolved de novo assembly using phased assembly graphs with hifiasm. Nat Methods. 2021;18:170–5.
Shen W, Le S, Li Y, Hu F. SeqKit: A Cross-Platform and Ultrafast Toolkit for FASTA/Q File Manipulation. PLoS One. 2016;11:e0163962.
Robinson JT, Thorvaldsdóttir H, Winckler W, Guttman M, Lander ES, Getz G, et al. Integrative genomics viewer. Nat Biotechnol. 2011;29:24–26.
Li H. Minimap2: pairwise alignment for nucleotide sequences. Bioinformatics. 2018;34:3094–3100.
Quinlan AR, Hall IM. BEDTools: a flexible suite of utilities for comparing genomic features. Bioinformatics. 2010;26:841–2.
Danecek P, Bonfield JK, Liddle J, Marshall J, Ohan V, Pollard MO, et al. Twelve years of SAMtools and BCFtools. Gigascience. 10. https://doi.org/10.1093/gigascience/giab008 (2021).
Pedersen BS, Layer RM, Quinlan AR. Vcfanno: fast, flexible annotation of genetic variants. Genome Biol. 2016;17:118.
Zheng X, Levine D, Shen J, Gogarten SM, Laurie C, Weir BS. A high-performance computing toolset for relatedness and principal component analysis of SNP data. Bioinformatics. 2012;28:3326–8.
Karolchik D, Hinrichs AS, Furey TS, Roskin KM, Sugnet CW, Haussler D, et al. The UCSC Table Browser data retrieval tool. Nucleic Acids Res. 2004;32:D493–6.
Giudicelli V, Brochet X, Lefranc M-P. IMGT/V-QUEST: IMGT standardized analysis of the immunoglobulin (IG) and T cell receptor (TR) nucleotide sequences. Cold Spring Harb Protoc. 2011;2011:695–715.
Omer A, Shemesh O, Peres A, Polak P, Shepherd AJ, Watson CT, et al. VDJbase: an adaptive immune receptor genotype and haplotype database. Nucleic Acids Res. 2020;48:D1051–D1056.
Ebbert MTW, Jensen TD, Jansen-West K, Sens JP, Reddy JS, Ridge PG, et al. Systematic analysis of dark and camouflaged genes reveals disease-relevant genes hiding in plain sight. Genome Biol. 2019;20:97.
Barbitoff YA, Polev DE, Glotov AS, Serebryakova EA, Shcherbakova IV, Kiselev AM, et al. Systematic dissection of biases in whole-exome and whole-genome sequencing reveals major determinants of coding sequence coverage. Sci Rep. 2020;10:2057.
Liao W-W, Asri M, Ebler J, Doerr D, Haukness M, Hickey G, et al. A draft human pangenome reference. Nature. 2023;617:312–24.
Kent WJ. BLAT-the BLAST-like alignment tool. Genome Res. 2002;12:656–64.
Vollger MR, Dishuck PC, Harvey WT, DeWitt WS, Guitart X, Goldberg ME, et al. Increased mutation and gene conversion within human segmental duplications. Nature. 2023;617:325–34.
Collins AM, Peres A, Corcoran MM, Watson CT, Yaari G, Lees WD, et al. Commentary on Population matched (pm) germline allelic variants of immunoglobulin (IG) loci: relevance in infectious diseases and vaccination studies in human populations. Genes Immun. 2021;22:335–8.
Yaari G, Kleinstein SH. Practical guidelines for B-cell receptor repertoire sequencing analysis. Genome Med. 2015;7:121.
Collins AM, Ohlin M, Corcoran M, Heather JM, Ralph D, Law M, et al. AIRR-C Human IG Reference Sets: curated sets of immunoglobulin heavy and light chain germline genes. bioRxiv. p. 2023.09.01.555348. https://doi.org/10.1101/2023.09.01.555348 (2023).
Lees W, Busse CE, Corcoran M, Ohlin M, Scheepers C, Matsen FA, et al. OGRDB: a reference database of inferred immune receptor genes. Nucleic Acids Res. 2020;48:D964–D970.
Collins AM, Ohlin M, Corcoran M, Heather JM, Ralph D, Law M, et al. AIRR-C IG Reference Sets: curated sets of immunoglobulin heavy and light chain germline genes. Front Immunol. 2023;14:1330153.
Vollger MR, Guitart X, Dishuck PC, Mercuri L, Harvey WT, Gershman A, et al. Segmental duplications and their variation in a complete human genome. Science. 2022;376:eabj6965.
Porubsky D, Vollger MR, Harvey WT, Rozanski AN, Ebert P, Hickey G, et al. Gaps and complex structurally variant loci in phased genome assemblies. Genome Res. 2023;33:496–510.
Mikocziova I, Peres A, Gidoni M, Greiff V, Yaari G, Sollid LM. Germline polymorphisms and alternative splicing of human immunoglobulin light chain genes. iScience. 2021;24:103192.
Stamatatos L, Pancera M, McGuire AT. Germline-targeting immunogens. Immunol Rev. 2017;275:203–16.
Lee JH, Toy L, Kos JT, Safonova Y, Schief WR, Havenar-Daughton C, et al. Vaccine genetics of IGHV1-2 VRC01-class broadly neutralizing antibody precursor naïve human B cells. NPJ Vaccines. 2021;6:113.
Haynes BF, Wiehe K, Borrow P, Saunders KO, Korber B, Wagh K, et al. Strategies for HIV-1 vaccines that induce broadly neutralizing antibodies. Nat Rev Immunol. 2023;23:142–58.
Avnir Y, Watson CT, Glanville J, Peterson EC, Tallarico AS, Bennett AS, et al. IGHV1-69 polymorphism modulates anti-influenza antibody repertoires, correlates with IGHV utilization shifts and varies by ethnicity. Sci Rep. 2016;6:20842.
Kirik U, Persson H, Levander F, Greiff L, Ohlin M. Antibody Heavy Chain Variable Domains of Different Germline Gene Origins Diversify through Different Paths. Front Immunol. 2017;8:1433.
Azevedo Reis Teixeira A, Erasmus MF, D’Angelo S, Naranjo L, Ferrara F, Leal-Lopes C, et al. Drug-like antibodies with high affinity, diversity and developability directly from next-generation antibody libraries. MAbs. 2021;13:1980942.
Parks T, Mirabel MM, Kado J, Auckland K, Nowak J, Rautanen A, et al. Association between a common immunoglobulin heavy chain allele and rheumatic heart disease risk in Oceania. Nat Commun. 2017;8:14946.
Wheatley AK, Whittle JRR, Lingwood D, Kanekiyo M, Yassine HM, Ma SS, et al. H5N1 Vaccine-Elicited Memory B Cells Are Genetically Constrained by the IGHV Locus in the Recognition of a Neutralizing Epitope in the Hemagglutinin Stem. J Immunol. 2015;195:602–10.
Liu L, Lucas AH. IGH V3-23*01 and its allele V3-23*03 differ in their capacity to form the canonical human antibody combining site specific for the capsular polysaccharide of Haemophilus influenzae type b. Immunogenetics. 2003;55:336–8.
Feeney AJ, Atkinson MJ, Cowan MJ, Escuro G, Lugo G. A defective Vkappa A2 allele in Navajos which may play a role in increased susceptibility to haemophilus influenzae type b disease. J Clin Invest. 1996;97:2277–82.
Sasso EH, Buckner JH, Suzuki LA. Ethnic differences of polymorphism of an immunoglobulin VH3 gene. J Clin Invest. 1995;96:1591–1600.
deCamp AC, Corcoran MM, Fulp WJ, Willis JR, Cottrell CA, Bader DLV, et al. Human immunoglobulin gene allelic variation impacts germline-targeting vaccine priming. medRxiv. https://doi.org/10.1101/2023.03.10.23287126 (2023).
Altomare CG, Adelsberg DC, Carreno JM, Sapse IA, Amanat F, Ellebedy AH, et al. Structure of a Vaccine-Induced, Germline-Encoded Human Antibody Defines a Neutralizing Epitope on the SARS-CoV-2 Spike N-Terminal Domain. MBio. 2022;13:e0358021.
Acknowledgements
We acknowledge and thank William Gibson for productive insights regarding IG light chain genetic variation, and we also acknowledge Zachary VanWinkle for assistance with manuscript preparation.
Funding
This work was supported by an award made to C.T.W. and M.L.S. by the National Institute of Allergy and Infectious Disease (R24 AI138963).
Author information
Authors and Affiliations
Contributions
EE, OLR, MLS, CTW conceived and planned the study. MLS directed wet lab/bench and sequencing experiments. KS and SS prepared sequencing libraries. EE, OLR, DT, UJ, GY, WL, and CTW interpreted results. CTW, MLS supervised the experiments, analysis, and data interpretation. EE wrote the manuscript with contributions from CTW, MLS, and OLR. EE, CTW, MLS, OLR, GY, WL reviewed and edited the manuscript. All authors read and approved the final manuscript.
Corresponding authors
Ethics declarations
Competing interests
CTW, MLS, GY, and WL are co-founders of Clareo Biosciences, Inc.
Additional information
Publisher’s note Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Supplementary information
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Engelbrecht, E., Rodriguez, O.L., Shields, K. et al. Resolving haplotype variation and complex genetic architecture in the human immunoglobulin kappa chain locus in individuals of diverse ancestry. Genes Immun (2024). https://doi.org/10.1038/s41435-024-00279-2
Received:
Revised:
Accepted:
Published:
DOI: https://doi.org/10.1038/s41435-024-00279-2
