
Abstract
Direct electron detectors in scanning transmission electron microscopy give unprecedented possibilities for structure analysis at the nanoscale. In electronic and quantum materials, this new capability gives access to, for example, emergent chiral structures and symmetry-breaking distortions that underpin functional properties. Quantifying nanoscale structural features with statistical significance, however, is complicated by the subtleties of dynamic diffraction and coexisting contrast mechanisms, which often results in a low signal-to-noise ratio and the superposition of multiple signals that are challenging to deconvolute. Here we apply scanning electron diffraction to explore local polar distortions in the uniaxial ferroelectric Er(Mn,Ti)O3. Using a custom-designed convolutional autoencoder with bespoke regularization, we demonstrate that subtle variations in the scattering signatures of ferroelectric domains, domain walls, and vortex textures can readily be disentangled with statistical significance and separated from extrinsic contributions due to, e.g., variations in specimen thickness or bending. The work demonstrates a pathway to quantitatively measure symmetry-breaking distortions across large areas, mapping structural changes at interfaces and topological structures with nanoscale spatial resolution.
Similar content being viewed by others

Introduction
High-energy electrons traveling through matter are highly sensitive to the local structure1, collecting a multitude of information about lattice defects and strain2, electric and magnetic properties3, as well as chemical composition and electronic structure4. This sensitivity is utilized in transmission electron microscopy (TEM) to study structure-property relations, and there are continuous efforts to increase resolution, enhance imaging speeds, and enable new imaging modalities5. A real paradigm shift was triggered by the advent of high dynamic-range direct electron detectors (DED), which no longer rely on converting electrons into photons6,7,8. DEDs enable spatially resolved diffraction imaging, providing additional opportunities for high-resolution measurements known as four-dimensional scanning transmission electron microscopy (4D-STEM)8,9,10. A significant advantage of 4D-STEM is the outstanding information density; an image of the dynamically scattered electrons is acquired at every probe position. In turn, advanced analysis tools are required to deconvolute the rich variety of phenomena that contribute to the scattering of the electrons10,11,12,13. Remarkably, low noise levels on DEDs enable the quantification of weak scattering events (e.g., diffuse scattering due to crystallographic defects14,15). The analysis of 4D-STEM data, however, is often challenged by a lack of empirical models that can fully explain the multitude of dynamic scattering processes, as well as varying signal-to-noise ratios. Recently, exponential increases in the deployment of machine learning methods in microscopy have been applied to accelerate a variety of scientific tasks, including real-time data reduction16, segmentation17,18, and automated experiments19,20. Furthermore, they can be used to disentangle features in multimodal nanoscale spectroscopic imaging with improved statistical significance21,22,23,24. Through careful design of machine learning architectures and custom regularization strategies, it is now possible to statistically disentangle and interpret structural properties of functional materials with nanoscale spatial resolution from multimodal imaging25,26,27.
Here, we apply 4D-STEM to investigate domains, domain walls, and vortex structures in a uniaxial ferroelectric oxide, utilizing the scattering of electrons for simultaneous high-resolution imaging and local structure analysis. Using a convolutional autoencoder (CA) with custom regularization, we statistically disentangle features in the diffraction patterns that correlate with the distinct structural distortions in the ferroelectric domains and domain walls, as well as the domain wall charge state. Based on the specific scattering properties, we can readily gain real-space images of ferroelectric domains, domain walls, and their vortex-like meeting points with a resolution limited by the spot size of the focused electron beam (here, 2 nm). Our approach provides a powerful method that combines nanoscale imaging and structural deconvolution—opening a pathway towards improved structure-property correlations, increased fidelity, and automated scientific experiments.
Results and discussion
Domain wall imaging by scanning electron diffraction
4D-STEM experiments are conducted on a model ferroelectric Er(Mn1-x,Tix)O3 (x = 0.002), denoted Er(Mn,Ti)O3 in the following. The high-quality single crystals used in this study are grown by the pressurized floating-zone method, following the same synthesis procedure as outlined by Yan et al.28. Er(Mn,Ti)O3 is a uniaxial ferroelectric and naturally develops 180° domain walls, where the spontaneous electric polarization P inverts29,30,31,32. The ferroelectric domain walls have a width comparable to the size of the unit cell33, and their basic structural34, electric33,35, and magnetic properties36 are well understood, which makes them an ideal model system for exploring local electron scattering events. It is established that the polarization reorientation across the domain walls coincides with a change in the periodic tilt pattern of the MnO5 bipyramids and displacement of Er ions that drive the electric order (i.e., improper ferroelectricity, see Fig. 1a)31. The structural changes at domain walls alter the electron scattering processes from the bulk. In turn, this difference is expected to alter scattering intensities encoded in the local electron diffraction patterns obtained in scanning electron diffraction (SED) measurements. There are, however, no good analytical methods to disentangle structural and extrinsic (e.g., thickness- and orientation-related) scattering mechanisms, particularly in the presence of noise.
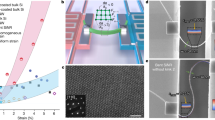
The general working principle of SED measurements is illustrated in Fig. 1b. A focused electron beam is raster-scanned over an electron transparent lamella. The lamella is extracted from an [001]-oriented Er(Mn,Ti)O3 single crystal (P || [001]), using a focused ion beam (FIB) as detailed in Methods. A diffraction pattern is recorded at each probe position of the scanned area, containing information about the local structure. In addition, integrating and selectively filtering the intensities of the collected individual diffraction patterns allows for calculating virtual real-space images. Figure 1c shows such a virtual dark-field (VDF) image. To calculate the VDF, we select and integrate the intensities of the full diffraction patterns as described by Meng and Zuo34. The imaged area contains two ferroelectric 180° domain walls (marked by black dotted lines) that separate +P and −P domains. The polarization direction within the domains was determined before extracting the lamella from the region of interest based on correlated scanning electron microscopy and piezoresponse force microscopy measurements (not shown). A VDF image with a higher resolution is presented in Fig. 1d for one of the domain walls, with visible contrast between the two domains. The data in Fig. 1d is recorded outside the area seen in Fig. 1c to minimize beam exposure (referred to as dataset 1, DS1, in the following).

a Crystallographic structure at room temperature (non-centrosymmetric space group P63cm). The Er atoms show a characteristic down-down-up displacement pattern, which correlates with the direction of the spontaneous polarization as illustrated below (down-down-up: −P, up-up-down: +P). b Schematic of our 4D-STEM approach. The illustration shows how the electron beam (green) is scanned across a selected region of a several micrometers sized Er(Mn,Ti)O3 lamella with a domain wall as indicated by the black dashed line, collecting diffraction patterns at a fixed position of the DED. c Overview VDF image showing two ferroelectric domain walls marked by black dashed lines. The bottom part (light gray) is an amorphous carbon layer with Pt markers that were used to cut a lamella from the region of interest. White arrows indicate the polarization direction of the different domains. Scale bar, 250 nm. d High-resolution VDF image recorded at the right domain wall shown in c. Scale bar, 100 nm.
Domain-dependent center-of-mass shift
We begin our discussion of the SED results with a center-of-mass (COM) analysis applied to the complete stack of diffraction patterns in the area presented in Fig. 1d. The results of the COM analysis are summarized in Fig. 2a, b. In general, the momentum change of the electron probe can be represented by the orientation of a vector in 2D reciprocal space. When interacting with the sample, the direction of the momentum changes, which is used in 4D-STEM COM imaging to determine built-in electric35 or magnetic37 fields. To evaluate the COM distribution over the dataset, we plot the COM position of each diffraction pattern as a single spot in reciprocal space. The result gained from the whole dataset is shown in Fig. 2a, where a substantial redistribution of scattering intensities is observed along the crystallographic [001]-axis. We find that the COM shift is sensitive to the local polarization orientation in Er(Mn,Ti)O3, leading to a split in the dispersion line for +P (red) and −P (blue) domains, as seen in Fig. 2b. Figure 2b presents the spatial origin of the two contributions, which coincides with the ferroelectric domain structure resolved in the VDF image in Fig. 1d.

a The center-of-mass (COM) analysis of every diffraction pattern in DS1 shows a substantial shift with respect to the geometric center in the upwards (downwards) direction along the crystallographic [001]-axis for +P (−P) domains. Scale bar, 0.1 Å−1. b COM analysis of the diffraction patterns associated with +P (red) and −P (blue) domains. Scale bar, 100 nm.
Convolutional autoencoder analysis of SED data
To analyze the domain-dependent scattering in more detail, we deploy a custom CA. The autoencoder consists of different blocks, as illustrated in Fig. 3a–c. The CA takes the input diffraction patterns and learns a low-dimensional statistical representation of the image through a series of convolutional and residual blocks. In each residual block, a max pooling (MaxPool) layer reduces the dimensionality of the image. Once the dimensionality of the image is sufficiently reduced, the two-dimensional image is flattened into a feature vector. This penultimate bottleneck layer is further compressed to a low-dimensional latent space, where statistical characteristics of the structure are disentangled using a scheduled custom regularizer. The learned latent representation is reshaped into a 2D image and decoded in the decoder using a series of upsampling residual blocks until the image is reconstructed to its original resolution. The model is trained on the diffraction patterns from single STEM images, such that there is a model for each experiment or imaging condition, using momentum-based stochastic gradient descent (ADAM)38 to minimize the mean squared reconstruction error of the diffraction images and regularization constraints added to the loss function.

a Main structure, consisting of encoder (from input to flatten layer), embedding, and decoder (from dense layer to reconstruction). The encoder reduces the dimension of each input image by going from 256 × 256 pixels to 8 × 8 pixels and via a dense layer down to the embedding. The embedding controls the number of channels to generate individual domains and domain walls in real space. The decoder recreates the vector from the embedding to the input image size. b Detailed structure of the ResNet MaxPool Block. The block consists of four convolutional layers, two normalization layers, two ReLU activation layers, and one 2D MaxPool layer with shortcut. c Detailed structure of the ResNet UpSample Block. The block contains one 2D upsample layer, four convolutional layers, two normalization layers, and two ReLU activation layers with shortcut. d Averaged diffraction pattern of a +P domain in dataset DS1, corresponding to the left domain (orange) seen in the CA embedding in the inset. e Averaged diffraction pattern of the −P domain (purple) in the CA embedding in the inset to d.
The overarching objective in learning latent representations is to isolate the salient statistical attributes embedded within the data. Traditional β-Variational Autoencoders (VAEs)39,40,41 accomplish this by imposing penalties on non-Gaussian features within the latent space—a very useful characteristic for generative models. This foundational principle has been adapted to allow for the soft disentanglement of geometric transformations, such as rotation, translation, strain, and shear42,43. However, the assumption of a Gaussian-distributed latent space introduces constraints, specifically excluding non-negativity and sparsity—properties that bolster interpretability. Additionally, this Gaussian assumption enforces an unphysical prior when attempting to identify intrinsically non-Gaussian features, like domain walls (Supplementary Fig. 1).
We impose various constraints on the embedding layer to encourage interpretable disentanglement of ferroelectric domains in the latent space. First, we add a rectified linear activation (ReLU) to ensure the activations are non-negative. All neural networks have a loss function based on the mean squared reconstruction error \({MSE}\left(y,\hat{y}\right)=\frac{1}{D}{\sum }_{i=1}^{D}{\left({y}_{i}-{\hat{y}}_{i}\right)}^{2}\), where \(y\) and \(\hat{y}\) denote the \(D\)-dimensional output and input of the neural network (D = 2562 = 65,536), respectively. To impose sparsity (a limited number of activated channels), an additional activity regularization is introduced \({L}_{1}\left(a\right)={\sum }_{i=1}^{d}\left|{a}_{i}\right|\), leading to a total loss function
here, d is the dimensionality of the embedding layer, \({a}_{i}\) are the activations in the embedding layer, and \({\lambda }_{\text{act}}\) is a hyperparameter. This has the effect of trying to drive most activations to zero while only those essential to the learning process are non-zero. As the degree of sparsity required is dataset-dependent, regularization scheduling is used to tune \({\lambda }_{\text{act}}\) to achieve an interpretable degree of disentanglement.
To demonstrate the efficiency of the CA, we analyze 4D-STEM data from the region with two ferroelectric domains seen in Fig. 1d (DS1). The model is trained with an overcomplete embedding layer of size 32. Following training, the number of active channels is reduced to 9 (see Supplementary Note 1 and Supplementary Fig. 2). Most of the embeddings disentangle bias in the imaging mode associated with the scan geometry, varying specimen thickness and orientation variations due to specimen bending; additionally, features associated with the domain wall are disentangled, which we will discuss later. One channel shows a sharp contrast between the 180° domains, indicating a significant contrast mechanism (inset to Fig. 3d). This map represents the activations of one neuron and, hence, is a weighting map for a specific characteristic in the diffraction pattern. To elucidate the nature of the contrast mechanism, we traverse the neural network latent. We show the generated diffraction patterns from the latent space encompassing the +P and −P domains in Fig. 3d, e.
The CA analysis reveals variations between the two domain states in the scanned area for the strongest reflections along the [001]-axis, that is, the \(004\) and \(00\bar{4}\) reflections (note that intensity distributions vary with sample thickness). A substantial advantage of the CA-based approach compared to, e.g., signal decomposition via unsupervised non-negative matrix factorization, is that it does not create artificial components that resemble diffraction patterns. Instead, the CA rates each diffraction pattern according to the scattering features in the embedding channels. Thus, by selecting and averaging diffraction patterns within a specific activation range within a certain channel, one can readily use this approach as a virtual aperture in reciprocal space using multiple areas of the pattern to correlate structural features identified statistically to scattering properties.
To demonstrate that the diffraction patterns in Fig. 3d, e are indeed specific to the local polarization orientation and connect them to the atomic-scale structure of Er(Mn,Ti)O3, we simulate the diffraction patterns expected for +P and −P domains using a Python multislice code44. As one example, Fig. 4a displays the unit cell structure of a +P domain, which is reflected by the up-up-down pattern formed by the Er atoms45. The corresponding simulated diffraction pattern is presented in Fig. 4b, considering a sample thickness of 75 nm. Figure 4b shows an asymmetry in the 004 and \(00\bar{4}\) reflections, consistent with the diffraction data in Fig. 3d. For a more systematic comparison of the experimental and simulated diffraction patterns, we calculate the normalized cross-correlation Δ(+P, −P) between the patterns of the two domains, as shown in Fig. 4c (simulated) and Fig. 4d (experimental data DS1). In both cases, the variational maps show the highest intensities wherever the two compared patterns exhibit the strongest variations. As expected, those arise primarily in the 004 (\(00\bar{4}\)) and, less pronounced, in the 002 (\(00\bar{2}\)) reflections. This observation further corroborates the CA-based analysis of the SED data, linking the changes in the diffraction pattern intensities to the atomic displacements and the resulting polarization direction.

a Illustration of the atomic structure in +P domains, showing the characteristic up-up-down displacement pattern of Er atoms. The crystallographic [001] and [010] axes are indicated by the inserted coordinate systems. b Simulated diffraction pattern for the structure in a. The direct beam and the 004 and \(00\bar{4}\) reflections are marked by white circles. c Normalized cross-correlation between simulated and d experimental (DS1) diffraction patterns of −P and +P domains, Δ(+P, −P), showing that the highest variation occurs for the 004-reflection.
CA-based extraction of domain walls and vortices
After demonstrating that our approach is sensitive to the polar distortions in Er(Mn,Ti)O3, and that it can extract domains, we discuss local variations in the diffraction pattern intensities that originate from finer structural changes. Figure 5a displays the same embedding map as seen in the inset to Fig. 3d, showing two ferroelectric domains with opposite polarization orientation. A second embedding map is shown in Fig. 5b, indicating scattering variations at the position of the domain wall (see also Supplementary Note 1 and Supplementary Fig. 2). The latter reflects the broader applicability of the CA beyond domain-related investigations. To explore the possibility of investigating local structure variations also at domain walls, we conduct additional measurements on a sample with multiple walls that meet in a characteristic six-fold meeting point, leading to a structural vortex pattern30,33,36 as presented in Fig. 5c–f (referred to as DS2). It is established that such vortices promote the stabilization of different types of walls46, which allows for testing the feasibility of our 4D-STEM approach for structure analysis of ferroelectric domain walls with varying physical properties.

a Embedding map showing ferroelectric ±P domains (DS1). Scale bar, 75 nm. Polarization directions are given by white arrows (same as inset to Fig. 2c). b Embedding map revealing the domain wall that separates the domains in a. c Embedding map from a second sample (DS2). Scale bar, 90 nm. d Difference in diffraction patterns between +P and −P domains in (c). e, f Two embedding maps of the CA, separating head-to-head (e) and tail-to-tail (f) domain walls that belong to the vortex in c.
As the statistics of the domain walls are different than within the domains, a uniform sparsity metric cannot disentangle these features well. Thus, to improve the performance of our model, we add two additional regularization parameters to the loss function that encourage sparsity and disentanglement. First, we add a contrastive similarity regularization of the embedding, \({L}_{{\rm{sim}}}\), to the loss function. This regularization term computes the cosine similarity between each of the non-zero vectors \({a}_{i}\) and \({a}_{j}\) within a batch of embedding vectors, where \({N}_{{\rm{batch}}}\) is the batch size, and \({\lambda }_{{\rm{sim}}}\) is a hyperparameter that sets the relative contribution to the loss function:
Since the activations are non-negative, the cosine similarity is bounded between [0,1], where 0 defines orthogonal vectors, and 1 defines parallel vectors. We subtract 1, so that similar and sparse vectors have no contribution to the loss function, whereas dissimilarity of non-sparse vectors decreases the loss and, thus, is encouraged.
Secondly, we add an activation divergence regularization, \({L}_{{\rm{div}}}\), to the loss function, where \({a}_{i,j}\), \({a}_{i,k}\) are components of the ith vector within a batch of latent embeddings. The magnitude of this contribution is regulated using the hyperparameter \({\lambda }_{{\rm{div}}}\):
This term has the effect of enforcing that each embedding vector is sparse, having a dominate component that is easy to interpret. We use the hyperparameter \({\lambda }_{\text{div}}\) to ensure that the magnitude of this contribution is significantly less than the reconstruction error. When applying these custom regularization strategies, the resulting activations disentangle more nuanced features in the domain structure.
The model readily disentangles the +P and −P domain states, as presented in Fig. 5c, revealing a six-fold meeting point of alternating ±P domains. The difference pattern between the two domain states can be determined using the CA as a generator. To do so, we calculate the mean pattern of the upper 5% quantile of the +P (purple) and −P (orange) domains in Fig. 5c, which leads us to Fig. 5d (corresponding color histograms are shown in Supplementary Fig. 3). Consistent with Fig. 4, pronounced intensity variations between +P and −P domains are observed for the 004 (\(00\bar{4}\)) and 002 (\(00\bar{2}\)) reflections. In contrast to the data collected on the first sample (Fig. 4), however, Fig. 5d reveals a stronger variation in the 002 (\(00\bar{2}\)) reflections, which we attribute to a difference in sample thickness.
Interestingly, the neural network produces different embedding maps for the domain walls in Fig. 5c, indicating a difference in their scattering behavior. Specifically, we disentangle statistical features that reveal the existence of two sets of domain walls as shown in Fig. 5e, f, respectively (additional embeddings are shown in Supplementary Fig. 3). Based on the polarization direction in the adjacent domains, we can identify the two sets of domain walls as positively charged head-to-head walls (Fig. 5e) and negatively charged tail-to-tail walls (Fig. 5f). This separation regarding the polarization configuration is remarkable as it reflects that our approach is sensitive to both the crystallographic structure of the domain walls and their electronic charge state as defined by the domain wall bound charge33.
In summary, our work demonstrates a powerful pathway for imaging and characterizing ferroelectric materials at the nanoscale. By applying a custom-designed CA to SED data gained on the model system Er(Mn,Ti)O3, we have shown that different scattering signatures can be separated within the same experiment. The latter includes ferroelectric domains, domain walls, and emergent vortex structures, as well as extrinsic features (e.g., bending and thickness variations), giving access to both the local structure and electrostatics. Analogous to the training specifically performed for the Er(Mn,Ti)O3 datasets, the model can be trained and specifically tailored to other systems. The core elements of the model—including its architecture, regularization techniques, and hyperparameters tuning methods—are broadly applicable to high-dimensional imaging modalities, not only in ferroelectrics. Thus, the findings can readily be expanded to other systems to localize, identify, and correlate weak scattering signatures to structural variations based on SED. By building a CA with custom regularization to promote disentanglement, subtle spectroscopic signatures of structural distortions can be statistically unraveled with nanoscale spatial precision. This approach is promising to automate and accelerate the unbiased discovery of defects, secondary phases, boundaries, and other structural distortions that underpin functional materials. Furthermore, it opens the possibility to expand the design of experiments to larger imaging sizes, higher frame rates, and more broadly into automated experimentation and, eventually, controls.
Methods
Specimen preparation
The lamellas used in this work are extracted from an Er(Mn,Ti)O3 single crystal using a FIB. For this purpose, the crystal is first oriented by Laue diffraction and cut perpendicular to the polar axis (P || [001]), to achieve a sample with out-of-plane polarization (thickness ~1 mm). To confirm that the crystal exhibits the characteristic domain structure of the hexagonal manganites, it is chemo-mechanically polished with silica slurry, which gives a root-mean-square roughness of about 1 nm and allows for domain imaging by, e.g., piezoresponse force microscopy and scanning electron microscopy (SEM) (not shown, for an example, see Evans et al.47). From the pre-characterized sample, a smaller piece is cut with a lateral dimension of about 2 × 2 mm2 for the FIB preparation48. This sample is then mounted on an SEM specimen holder with carbon tape and loaded into a Thermo Fisher Scientific G4 UX DualBeam FIB. This system combines a SEM and a gallium (Ga) ion beam column. The region of interest (ROI) is located by SEM imaging and platinum markers, and a carbon protection layer is deposited by the electron beam. This step is critical as it ensures that the ROI is marked and shielded from any potential ion beam irradiation damage. Subsequently, another carbon protection layer is deposited by the ion beam. Following the deposition steps, a Ga ion beam is used to mill trenches on each side of the ROI, after which the lamella is extracted and transferred to a copper TEM grid. The lamella is then progressively thinned down towards the pre-marked target position with the ion beam, with the current gradually decreasing from 9 nA to 90 pA. This thinning process ends with a lamella where the ROI is located in the upper middle of the lamella, with the ROI thinner than the surrounding areas to ensure optimal flatness. The process is stopped as the ROI becomes electron transparent49. For the final polishing step, a low-energy electron beam (2 kV, 0.11 nA) is used to remove the damage layer50 and improve the surface quality.
Diffraction data acquisition and STEM imaging
The diffraction experiments were conducted on a Jeol 2100 F TEM at 200 kV and the scans were controlled via the Nanomegas P1000 scan engine. For acquiring the diffraction patterns, we used a Merlin 1S DED from Quantum Detectors operated with a lower threshold of 40 kV and with no limit on the upper threshold. The electron beam is focused on a probe with a diameter of 2 nm and a convergence angle of 9 mrad. The total scan grid consisted of 256 × 256 probe positions (with a step size of 1.4 nm) with a probe dwell time of 50 ms at each beam position. STEM imaging was performed using the nanobeam diffraction mode and a 10 µm aperture. The probe current was measured to be 4.6 pA.
Convolutional autoencoder (CA)
Data from 4D-STEM was analyzed using a CA built in Pytorch51. Prior to training, the log of the raw 4D-STEM data was used to obtain less non-linear images. The number of learnable parameters is 4,700,770. The CA consists of three parts: an encoder, an embedding layer, and a decoder. The encoder consists of three ResNet Blocks with different feature sizes, a convolutional layer with one filter, and a flattened layer. Each ResNet Block consists of a Residual Convolutional Block and an Identity Block. Each Residual Convolutional Block has three sequence convolutional layers with 128 filters, connected with a normalization layer and a Rectified Linear Unit (ReLU) activation layer. There is a skip connection between the input and output of the block, which can maintain the information of the input image after image processing. Each Identity Block has a convolutional layer with 128 filters, connected with a normalization layer and a ReLU activation layer. There is a 2D Max Pooling layer after each Resnet Block for image size dimensionality reduction. The image sizes to each ResNet Block in the encoder are (256 × 256), (64 × 64), (16 × 16). The embedding consists of a linear layer and a ReLU activation layer. The decoder consists of a linear layer, a convolutional layer with 128 filters, three ResNet Blocks, and a convolutional layer with 1 filter. There is an upsampling layer before each ResNet Block to recreate the input image. A loss function based on the mean square reconstruction error (MSE) between the input and generated image is used. The image sizes to each ResNet Block in the decoder are (8 × 8), (16 × 16), (64 × 64). The loss function has additional L1 activity regularization of the embedding. When generating domain walls in Fig. 5e, f, we also include contrastive similarity regularization and activate divergence regularization to make the output embedding sparse and unique.
The models were trained on a server with 4x A100 GPUs. To generate the domain in Fig. 5a and the domain wall in Fig. 5b, we set the coefficient \({\lambda }_{\text{act}}=1\times {10}^{-5}\) and trained the model using optimization ADAM52 (learning rate of 3 × 10−5) for 377 epochs. To generate the vortex-like domain pattern (Fig. 5c), we set the coefficient \({\lambda }_{\text{act}}=1\times {10}^{-5}\) and trained the model for 225 epochs using optimization ADAM (learning rate of 3 \(\times {10}^{-5}\)), then raised \({\lambda }_{\text{act}}\) to \(5\times {10}^{-4}\) and trained the model for another 60 epochs using learning rate cycling (increasing from 3\(\times {10}^{-5}\) to 5\(\times {10}^{-5}\) in 15 epochs, then decreasing from 5\(\times {10}^{-5}\) to 3\(\times {10}^{-5}\) in the next 15 epochs). To generate the corresponding domain walls in Fig. 5e, f, besides L1 regularization with coefficient \({\lambda }_{\text{act}}=5\times {10}^{-3}\) in the loss function, we also included contrastive similarity regularization with coefficient \({\lambda }_{\text{sim}}=5\times {10}^{-5}\) and activity divergence regularization with coefficient \({\lambda }_{\text{div}}=2\times {10}^{-4}\) to make the output embedding sparse and unique. We trained the model for 18 epochs using optimization ADAM (learning rate of 3\(\times {10}^{-5}\)). Following training, the output from the embedding layer was extracted. This represents a compact representation of the important features in the sample domain. To visualize the change in the diffraction pattern that is encoded by a single channel, the difference between the mean pattern of all diffraction pattern with 5% highest and lowest activation at the channel of interest was calculated. This was used to create the projections in Figs. 3d, e, 4d, 5d and the third row of Supplementary Fig. 3. Full details are available in the reproducible source code38.
Data availability
Data and reproducible code are made openly available under the BSD-2 License. 4D-STEM raw data is published on Zenodo53.
References
Ehrhardt, K. M., Radomsky, R. C. & Warren, S. C. Quantifying the local structure of nanocrystals, glasses, and interfaces using TEM-based diffraction. Chem. Mater. 33, 8990–9011 (2021).
Goris, B. et al. Measuring lattice strain in three dimensions through electron microscopy. Nano Lett. 15, 6996–7001 (2015).
Möller, M., Gaida, J. H., Schäfer, S. & Ropers, C. Few-nm tracking of current-driven magnetic vortex orbits using ultrafast lorentz microscopy. Commun. Phys. 3, 36 (2020).
Mundy, J. A., Mao, Q., Brooks, C. M., Schlom, D. G. & Muller, D. A. Atomic-resolution chemical imaging of oxygen local bonding environments by electron energy loss spectroscopy. Appl. Phys. Lett. 101, 042907 (2012).
Crozier, P. et al. Enabling Transformative Advances in Energy and Quantum Materials through Development of Novel Approaches to Electron Microscopy. Available at: https://www.temfrontiers.com/ (2021).
Pennycook, T. J. et al. Efficient Phase Contrast Imaging in STEM Using A Pixelated Detector. Part 1: experimental demonstration at atomic resolution. Ultramicroscopy 151, 160–167 (2015).
Yang, H., Pennycook, T. J. & Nellis, P. D. Efficient phase contrast imaging in STEM using a pixelated detector. Part II: optimisation of imaging conditions. Ultramicroscopy 151, 232–239 (2015).
Zeltmann, S. E. et al. Patterned probes for high precision 4D-STEM bragg measurements. Ultramicroscopy 209, 112890 (2020).
Ophus, C. Four-dimensional scanning transmission electron microscopy (4D-STEM): from scanning nanodiffraction to ptychography and beyond. Microsc. Microanal. 25, 563–582 (2019).
Bustillo, K. C. et al. 4D-STEM of beam-sensitive materials. Acc. Chem. Res 54, 2543–2551 (2021).
LeBeau, J. M., Findlay, S. D., Allen, L. J. & Stemmer, S. Position averaged convergent beam electron diffraction: theory and applications. Ultramicroscopy 110, 118–125 (2010).
Yu, C.-P., Friedrich, T., Jannis, D., Van Aert, S. & Verbeeck, J. Real-time integration center of mass (riCOM) reconstruction for 4D STEM. Microsc. Microanal. 28, 1526–1537 (2022).
Pollock, J. A., Weyland, M., Taplin, D. J., Allen, L. J. & Findlay, S. D. Accuracy and precision of thickness determination from position-averaged convergent beam electron diffraction patterns using a single-parameter metric. Ultramicroscopy 181, 86–96 (2017).
Wehmeyer, G., Bustillo, K. C., Minor, A. M. & Dames, C. Measuring temperature-dependent thermal diffuse scattering using scanning transmission electron microscopy. Appl. Phys. Lett. 113, 253101 (2018).
Shao, Y. T. et al. Cepstral scanning transmission electron microscopy imaging of severe lattice distortions. Ultramicroscopy 231, 113252 (2021).
Deiana, A. M. et al. Applications and techniques for fast machine learning in science. Front. Big Data 5, 787421 (2022).
Groschner, C. K., Choi, C. & Scott, M. C. Machine learning pipeline for segmentation and defect identification from high-resolution transmission electron microscopy data. Microsc. Microanal. 27, 549–556 (2021).
Lu, S., Montz, B., Emrick, T. & Jayaraman, A. Semi-supervised machine learning workflow for analysis of nanowire morphologies from transmission electron microscopy images. Digit. Discov. 1, 816–833 (2022).
Liu, Y. et al. Automated experiments of local non-linear behavior in ferroelectric materials. Small 18, 2204130 (2022).
Kalinin, S. V. et al. Machine learning for automated experimentation in scanning transmission electron microscopy. npj Comput. Mater. 9, 227 (2023).
Kalinin, S. V. et al. Unsupervised machine learning discovery of structural units and transformation pathways from imaging data. APL Mach. Learn. 1, 026117 (2023).
Holstad, T. S. et al. Application of a long short-term memory for deconvoluting conductance contributions at charged ferroelectric domain walls. npj Comput. Mater. 6, 163 (2020).
Agar, J. C. et al. Revealing ferroelectric switching character using deep recurrent neural networks. Nat. Commun. 10, 4809 (2019).
Agar, J. C. et al. Machine detection of enhanced electromechanical energy conversion in PbZr0.2Ti0.8O3 thin films. Adv. Mater. 30, 1800701 (2018).
De La Mata, M. & Molina, S. I. STEM tools for semiconductor characterization: beyond high-resolution imaging. Nanomaterials 12, 337 (2022).
Munshi, J. et al. Disentangling multiple scattering with deep learning: application to strain mapping from electron diffraction patterns. npj Comput. Mater. 8, 254 (2022).
Kalinin, S. V. et al. Deep learning for electron and scanning probe microscopy: from materials design to atomic fabrication. MRS Bull. 47, 931–939 (2022).
Yan, Z. et al. Growth of high-quality hexagonal ErMnO3 single crystals by the pressurized floating-zone method. J. Cryst. Growth 409, 75–79 (2015).
Holstad, T. S. et al. Electronic bulk and domain wall properties in ErMnO3. Phys. Rev. B 97, 085143 (2018).
Jungk, T., Hoffmann, Á., Fiebig, M. & Soergel, E. Electrostatic topology of ferroelectric domains in YMnO3. Appl. Phys. Lett. 97, 012904 (2010).
Van Aken, B. B., Palstra, T. T. M., Filippetti, A. & Spaldin, N. A. The origin of ferroelectricity in magnetoelectric YMnO3. Nat. Mater. 3, 164–170 (2004).
Choi, T. et al. Insulating interlocked ferroelectric and structural antiphase domain walls in multiferroic YMnO3. Nat. Mater. 9, 253–258 (2010).
Holtz, M. E. et al. Topological defects in hexagonal manganites: inner structure and emergent electrostatics. Nano Lett. 17, 5883–5890 (2017).
Meng, Y. & Zuo, J.-M. Three-dimensional nanostructure determination from a large diffraction data set recorded using scanning electron nanodiffraction. Int. Union Crystallogr. 3, 300–308 (2016).
Beyer, A. et al. Quantitative characterization of nanometer-scale electric fields via momentum-resolved STEM. Nano Lett. 21, 2018–2025 (2021).
Geng, Y., Lee, N., Choi, Y. J., Cheong, S.-W. & Wu, W. Collective magnetism at multiferroic vortex domain walls. Nano Lett. 12, 6055–6059 (2012).
Yücelen, E., Lazić, I. & Bosch, E. G. T. Phase contrast scanning transmission electron microscopy imaging of light and heavy atoms at the limit of contrast and resolution. Sci. Rep. 8, 2676 (2018).
Ludacka, U. et al. Imaging and structure analysis of ferroelectric domains, domain walls, and vortices by scanning electron diffraction. Available at: https://research.coe.drexel.edu/mem/m3-learning/tutorials/papers/2023_Imaging_ferroelectric_domains_by_scanning_electron_diffraction/STEM_Domains.html (2022).
Burgess, C. P. et al. Understanding disentangling in β-VAE. Preprint at http://arXiv.org/abs/1804.03599 (2018).
Qin, S., Guo, Y., Kaliyev, A. T. & Agar, J. C. Why it is unfortunate that linear machine learning “works” so well in electromechanical switching of ferroelectric thin films. Adv. Mater. 34, 2202814 (2022).
Kalinin, S. V., Steffes, J. J., Liu, Y., Huey, B. D. & Ziatdinov, M. Disentangling ferroelectric domain wall geometries and pathways in dynamic piezoresponse force microscopy via unsupervised machine learning. Nanotechnology 33, 055707 (2022).
Valleti, M., Vasudevan, R. K., Ziatdinov, M. A. & Kalinin, S. V. Deep kernel methods learn better: from cards to process optimization. Mach. Learn.: Sci. Technol. 5, 015012 (2024).
Oxley, M. P. et al. Probing atomic-scale symmetry breaking by rotationally invariant machine learning of multidimensional electron scattering. npj Comput. Mater. 7, 65 (2021).
Brown, H., Pelz, P., Ophus, C. & Ciston, J. A Python Based Open-source Multislice Package for Transmission Electron Microscopy. Microsc. Microanal. 26, 2954–2956 (2020).
van Aken, B. B. et al. Hexagonal YMnO3. Acta Crystallogr. Sect. C. Cryst. Struct. Commun. 57, 230–232 (2001).
Kumagai, Y. & Spaldin, N. A. Structural Domain Walls in Polar Hexagonal Manganites. Nat. Commun. 4, 1540 (2013).
Evans, D. M. et al. Conductivity control via minimally invasive anti-Frenkel defects in a functional oxide. Nat. Mater. 19, 1195–1200 (2020).
Schaffer, M., Schaffer, B. & Ramasse, Q. Sample preparation for atomic-resolution STEM at low voltages by FIB. Ultramicroscopy 114, 62–71 (2012).
Minenkov, A. et al. Advanced preparation of plan-view specimens on a MEMS chip for in situ TEM heating experiments. MRS Bull. 47, 359–370 (2022).
Kelley, R. D., Song, K., Van Leer, B., Wall, D. & Kwakman, L. Xe+ FIB milling and measurement of amorphous silicon damage. Microsc. Microanal. 19, 862–863 (2013).
Paszke, A. et al. PyTorch: an imperative style, high-performance deep learning library. In: Proceedings of the 33rd International Conference on Neural Information Processing Systems, Curran Associates Inc., Red Hook, USA (2019).
Kingma, D. P. and Adam, J. B.: A Method for Stochastic Optimization. in: International Conference on Learning Representations (ICLR), San Diego, USA (2015).
Ludacka, U. et al. Data from Imaging and structure analysis of ferroelectric domains, domain walls, and vortices by scanning electron diffraction [Data set]. Zenodo. https://doi.org/10.5281/zenodo.7837986 (2023).
M3_learning at main · m3-learning/m3_learning. (Github). Available at: https://github.com/m3-learning/m3_learning (2023).
Joshua C. Agar. m3-learning/m3_learning: STEM-AE (Version V0). Zenodo. https://doi.org/10.5281/zenodo.7844268 (2023).
Acknowledgements
U.L. thanks Muhammad Z. Khalid for help with the visualization of the crystal structure. D.M., U.L., and J.H. acknowledge funding from the European Research Council (ERC) under the European Union’s Horizon 2020 Research and Innovation Program (Grant Agreement No. 863691). D.M. thanks NTNU for support through the Onsager Fellowship Program and the Outstanding Academic Fellow Program. The Research Council of Norway is acknowledged for the support of the Norwegian Micro- and Nano-Fabrication Facility, Nor-Fab, project number 295864, and the Norwegian Center for Transmission Electron Microscopy, NORTEM (197405). S.Q. acknowledges support from the National Science Foundation under grant TRIPODS + X:RES-1839234 and DOE Data Reduction for Science award Real-Time Data Reduction Codesign at the Extreme Edge for Science. J.C.A. and X.Z. acknowledge support from the Army/ARL via the Collaborative for Hierarchical Agile and Responsive Materials (CHARM) under cooperative agreement W911NF-19-2-0119, and National Science Foundation under grant OAC:DMR:CSSI - 2246463. We acknowledge computational resources provided by NSF grant 2320600 and National Science Foundation (NSF) awards CNS-1730158, ACI-1540112, ACI-1541349, OAC-1826967, OAC-2112167, CNS-2100237, CNS-2120019, the University of California Office of the President, and the University of California San Diego’s California Institute for Telecommunications and Information Technology/Qualcomm Institute. Thanks to CENIC for the 100 Gbps networks. M.Z. acknowledges funding from the Studienstiftung des Deutschen Volkes via a Doctoral Grant and the State of Bavaria via a Marianne-Plehn scholarship.
Funding
Open access funding provided by Norwegian University of Science and Technology.
Author information
Authors and Affiliations
Contributions
U.L. performed the 4D-STEM measurements supervised by D.M. and with support from E.F.C. and A.T.v.H; J.H. conducted SPM and SEM measurements and prepared the lamellas for the SED experiments under supervision of D.M. S.Q. designed, trained, and analyzed the convolutional autoencoder under supervision by J.C.A., with support from U.L. and M.Z. (supervised by D.M. and I.K.). K.A.H. simulated the diffraction pattern assisted by U.L., Z.Y., and E.B., provided the single crystals used in this work. D.M. initiated and coordinated the project. U.L., M.Z., J.C.A., and D.M. wrote the manuscript. All authors discussed the results and contributed to the final version of the manuscript.
Corresponding authors
Ethics declarations
Competing interests
The authors declare no competing interests.
Additional information
Publisher’s note Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Supplementary information
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Ludacka, U., He, J., Qin, S. et al. Imaging and structure analysis of ferroelectric domains, domain walls, and vortices by scanning electron diffraction. npj Comput Mater 10, 106 (2024). https://doi.org/10.1038/s41524-024-01265-y
Received:
Accepted:
Published:
DOI: https://doi.org/10.1038/s41524-024-01265-y
