
Abstract
The present study aims to assess the treatment outcome of patients with diabetes and tuberculosis (TB-DM) at an early stage using machine learning (ML) based on electronic medical records (EMRs). A total of 429 patients were included at Chongqing Public Health Medical Center. The random-forest-based Boruta algorithm was employed to select the essential variables, and four models with a fivefold cross-validation scheme were used for modeling and model evaluation. Furthermore, we adopted SHapley additive explanations to interpret results from the tree-based model. 9 features out of 69 candidate features were chosen as predictors. Among these predictors, the type of resistance was the most important feature, followed by activated partial throm-boplastic time (APTT), thrombin time (TT), platelet distribution width (PDW), and prothrombin time (PT). All the models we established performed above an AUC 0.7 with good predictive performance. XGBoost, the optimal performing model, predicts the risk of treatment failure in the test set with an AUC 0.9281. This study suggests that machine learning approach (XGBoost) presented in this study identifies patients with TB-DM at higher risk of treatment failure at an early stage based on EMRs. The application of a convenient and economy EMRs based on machine learning provides new insight into TB-DM treatment strategies in low and middle-income countries.
Similar content being viewed by others

Introduction
Tuberculosis (TB) remains a global infectious disease and one of the leading causes of death worldwide. In 2020, The World Health Organization (WHO) estimated the number of people newly diagnosed with TB was 5.8 million1. The End TB Strategy of WHO of 2014 aims for zero mortality and morbidity from TB2. However, high-risk comorbidities, such as HIV, malnutrition, and dysglycemia, are preventing people from achieving this goal. A recent study has reported that persistent dysglycemia was independently associated with unfavorable treatment outcomes (adjusted odds ratio (AOR): 6.1; 95% CI: 1.9–19.6)3. Thus, identifying the patients with TB-DM who are more prone to unfavorable treatment failure from a large amount of miscellaneous EMRs data at an early stage is important.
Previous studies have demonstrated a relationship between diabetes mellitus (DM) and the progression of TB3,4,5,6. A recent systematic review from China showed that the prevalence Of DM among TB patients was 7.8% after screening 7043 articles and 43 eligible studies. The highest prevalence was in Northeast China (21.9%), followed by the East Coast (8.3%), Western China (5.9%), and Central China (5.1%)6. Another previous study reported that dysglycemia influences laboratory, clinical and radiographic manifestations of patients with TB, resulting in unfavorable treatment outcomes and a higher possibility of relapse and death4. Therefore, to improve TB-DM treatment outcomes and ease personal and societal healthcare burdens, clinicians would be better off identifying patients who are more prone to unfavorable treatment outcomes at an early stage. Then, precision treatment strategies can aid them afterward. In sum, it is necessary to establish a stable and reliable clinical prediction model to identify the high risk of treatment failure in patients with TB-DM.
In recent years, machine learning approaches have been applied to diagnosing and treating TB, providing valuable information for clinical decision-making7,8,9. ML approaches are growing fast and have been proven to predict risk factors for various diseases based on large population datasets10. ML algorithms can easily integrate and interpret a vast amount of heterogeneous data, which is beyond the human’s brain power. Previous ML studies, to our knowledge, have not been employed to study the treatment outcome of TB-DM. Hence, in this study, we aimed to apply supervised and unsupervised ML algorithms to a comprehensive set of clinical, demographic, laboratory, and CT (computed tomography) data to construct an interpretable and reliable predictive ML model for the treatment failure of TB among patients with TB-DM in Chongqing Public Health Medical Center (CPHM), an infectious diseases hospital in Chongqing, in the southwest of China.
Methods
Study design and population
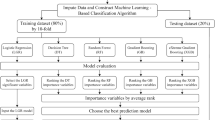
Five hundred and eight patients with TB-DM at CPHM between February 2019 and January 2021 were included in this retrospective study. Seventy-nine patients were excluded because of incomplete electronic medical records or lack of treatment outcome follow-up records. Finally, 429 patients were included in this study (Fig. 1). The main inclusion criteria are similar to our previous study5: age greater than 18 years; antituberculosis therapy for no more than one week before hospitalization in CPHM within five years; the diagnostic criterion of active PTB conforms to at least one of the following laboratory test: sputum or bronchial lavage fluid (BALF) smear positive, sputum or BALF bacterial culture positive, GeneXpert Mycobacterium tuberculosis/ rifampicin resistance in sputum or BALF positive.

The flow chart of the study.
Treatment outcome
According to WHO guidelines, TB treatment outcome was defined as failure or cure11 (Supplementary Tables 1–2). In this study, both cured and completed treatment were identified as successful TB treatment.
Laboratory tests
The obtained variables in this study were as follows: white blood cell count (WBC), neutrophil count (NEUT), lymphocyte count (LYMPH), monocyte count (MONO), platelet count (PLT), red blood cell count (RBC), hemoglobin (HGB), hematocrit (HCT), mean platelet volume (MPV), plateletcrit (PCT), platelet distribution width (PDW), erythrocyte sedimentation rate (ESR), C-reactive protein (CRP), total protein (TP), albumin (ALB), total cholesterol (T_CHOL), high density lipoprotein (HDL), Low Density Lipoprotein (LDL), triglyceride (TG), Alanine transaminase (ALT), Aspartate Aminotransferase (AST), total bilirubin (TBil), calcium (Ca), chlorine (Cl), kalium (K), natrium (Na), activated partial throm-boplastic time (APTT), fibrinogen (FIB), prothrombin time (PT), thrombin time (TT), urea nitrogen, creatinine, Uric Acid, fasting blood-glucose (FBG), CD4, and CD8.
Basic feature
Age, sex, body mass index (BMI), systolic blood pressure (SBP), diastolic blood pressure (DBP), type of resistance, comorbidity ≥ 2, cough, expectoration, hemoptysis, fever, night sweats, asymptomatic, history of TB, antidiabetic (metformin, sulfonylureas, insulin), smoking, drinking history, family history of DM.
CT feature
In this study, two experienced radiologists who were blinded to the related clinical data examined the CT images, and a senior TB expert made the final decision if the explanations of imaging results from the two radiologists were different. The number of pulmonary lobes involved, small patchy shadow, small nodules, air bronchial sign, large segmented leafy shadow, thick-walled cavity, single cavity, multiple cavities, calcification, fibrosis, lymph node enlargement, and Pleural effusion. This detail information was shown in Supplementary Table 3.
Definition of some variables
Comorbidities ≥ 2
Some patients included in this study have more than 2 comorbidities, such as hypertension, dyslipidemia, pneumonia, chronic obstructive pulmonary disease, coronary heart disease, bronchiectasis, hypoproteinemia, renal failure, and so on.
Smoking history
Smoking status was defined as having smoked at least 100 cigarettes in life: Yes (smoker) or No (non-smoker).
Drinking history
It was defined as having ever consumed 1 drink of any alcoholic beverages, including liquor, beer, wine, wine coolers, and any other type of alcoholic beverage in thier entire life, not counting small tastes or sips.
Type of resistance
Sensitive: Drug-susceptible TB; Mono-R: mono-resistant tuberculosis; Poly-R: Poly—resistant tuberculosis; MDR: Multi-drug resistant tuberculosis; XDR: Extensively drug-resistant tuberculosis.
Supervised ML approach
Given the high dimensionality of EMR data and the possible overfit, the Boruta algorithm12 was applied to select the best predictors of treatment failure of TB-DM in the feature selection stage. The Boruta algorism is a random forest-based feature selection method performing multiple random forest runs to compare shuffled random variables to the original variables. Then, scores standing for importance are assigned to each feature. All selected features were split into rejected, tentative, and confirmed ones according to their importance scores. In brief, confirmed features that may contribute positively to the predictive model has a performance that is better than the best random feature, indicated as ‘‘shadowMax’’. Finally, those confirmed features are considered into the ML model. Then, we split the data 70%/30% temporally and adopted a fivefold Cross-Validation on the training set to estimate the skill of the model. The remain data (test set) was used to assess the models (Fig. 2).

Modeling step of machine learning method (five-fold cross validation based on the data).
Four models, including XGBoost algorithm, random forest (RF), support vector machine (SVM), and logistic regression (LR), were established by ML approach using the R package ‘caret’, ‘xgboost’, and ‘e1071’. Meanwhile, model performance metrics contained accuracy score, receiver operating characteristic curve (ROC), kappa value, sensitivity, specificity, precision, recall, and F1 were also evaluated. We used a grid search to configure the best combination of hyperparameters to tune the model parameters (Supplementary Table 4).
Popular feature attribution methods may be inconsistent, which means they may reduce a feature’s assigned significance when its real impact is raised13,14. To address this problem, we adopted SHAP (Shapley Additive exPlanation) values based on game theory, which quantifies the contribution of each feature to the models.
Comparison of the performance of the conventional statistic, ML model using all features, and ML model plus CT features with the optimal ML model.
To validate the performance of the optimal ML model, we constructed a conventional measure, logistical regression, for comparison and the ML model using all features (69 features) from the dataset. For the conventional method, based on the previous studies3,15,16,17 and the relevance of clinical practice, we selected the sex, age, BMI, smoking, alcoholism, fasting glucose, HbA1C, type of resistance, and multiple cavities as potential confounding factors to construct a multiple analysis logistic regression model. For the ML model plus CT features, the optimal ML model combined with all CT features, including the number of pulmonary lobes involved, small patchy shadow, small nodules, air bronchial sign, large segmented leafy shadow, thick-walled cavity, single cavity, multiple cavities, calcification, fibrosis, lymph node enlargement, and Pleural effusion.
Statistical analysis
Continuous variables were represented as mean ± standard or Median, Interquartile Range (IQR; 25–75%). Normally distributed continuous variables were compared using Student’s t-test, while non-normally distributed continuous variables were compared using the Mann–Whitney U test. Categorical variables were expressed as percentages (%). Comparison between groups was performed using the Χ2 test or Fisher exact test as appropriate. The clinical application was investigated by decision curve analysis (DCA).
RStudio (version 1.4.1717) was adopted to analyze all data in this study. For all analyses, differences with p < 0.05 were statistically significant.
Ethics approval and consent to participate
This study was approved after agreement from the Ethics Committee of Chongqing Public Health Medical Center (no. 2021-023-02-KY). Due to the retrospective nature of the study, the Ethics Committee of Chongqing Public Health Medical Center waived the requirement for patient informed consents. The patients were anonymized and their information was nonidentifiable. In general, all data in this study was obtained in accordance with the Helsinki declaration.
Results
Baseline characteristics according to treatment outcome of TB-DM
A total of 429 patients were included in this study (age: 56.2 ± 11.2 (mean ± median)); male: 17.2%). Treatment failure of TB-DM occurred in around one-third of the case. The baseline characteristics are summarized in Table 1.
Clustering of laboratory tests patterns between two treatment outcomes
In terms of utility and convenience, the combination of the multiple blood biomarkers may outperform single in evaluating the treatment outcome of TB-DM. Thus, we assessed the prediction of treatment outcome of the combination of different blood biomarkers by the unsupervised ML approach.
Feature selection
9 features were selected from the 69 features in this study based on the random forest-based Boruta algorithm (Fig. 3): drug-susceptible type of resistance, APTT, TT, HDL, PDW, PT, HbA1c, TP, and history of TB. In addition, other variables (rejected or tentative) with an importance score lower than shadowMax were all identified as unimportant and excluded.

Boruta screening features results.
Predictive performance comparison of different classifiers
After selecting the optimal features through the Boruta algorism, we plugged them into four classifiers for further modeling, respectively. The primary confusion matrix performance and ROC scores of all ML classifiers were summarized in Table 2 and (Fig. 4). The four models have good performance as a whole (all ROC scores of models ≥ 0.7). The most promising model that predicts treatment failure of TB-DM is XGBoost, which obtained better model evaluation scores than any other ML classifiers (Table 2). Based on the decision curve analysis (DCA), the XGBoost classifier demonstrated the best net benefit along with the threshold probability than other classifiers, suggesting that XGBoost classifier was the optimal model with helpful clinical utility (Fig. 5).

ROC curves of the four models on the testing set.

Decision curve analyses of the four models. The horizontal line here shows patients with favorable of treatment outcome, and the gray oblique line indicates patients with unfavorable of treatment outcome.
The conventional method showed AUC 0.8632 and 83.7% accuracy, XGBoost using all features demonstrated 0.8858 and 0.81%, respectively. XGBoost plus.
CT features showed 0.9048 and 80.5%. While, the machine learning model, XGBoost, showed AUC 0.9281 and 84.4% accuracy. Considering the sensitivity and specificity, the conventional method showed 0.7333 and 0.8844, respectively. classifiers using all features showed 0.6222 and 0.9157, respectively. XGBoost plus CT features produced 0.6667 and 0.8795. ML model produced 0.7111 and 0.9167, respectively (Table 3).
After the above analysis, we calculated SHAP values of XGBoost model. Figure 6 showed the distribution of feature contributions to predictions of treatment failure of TB-DM using SHAP values of each feature for every observation. Each dot is an individual prediction. For instance, the type of resistance is associated with low and positive values on the target. Where low comes from the color and positive from the x value. In other words, people who are less drug resistant may be more likely to be cured. When APTT is high (or true) then SHAP value is high. Patients with high APTT may result in treatment failure. In addition, the high value dots of HbA1c mainly concentrates on the right side of x-axis, which means high HbA1c increases the risk of treatment failure.

Shapley Additive exPlanations (SHAP) values for each selected feature. The higher the predictor is on the left list, the bigger the impact on model output. Each patient is represented by a dot. The x-axis represents the extent of the impact on prediction, they accumulate to represent density. The color of the dot shows the feature value (e.g., the purple color implies higher values, while yellow lower values).
Discussion
In this study, we have shown the feasibility and stability of applying ML approaches to a comprehensive set of demographic, clinical, laboratory tests, and radiology features acquired for evaluating the treatment outcome of patients with TB-DM upon admission. Moreover, all four models we established predicted treatment failure of TB-DM with an AUC above 0.7. XGBoost is the optimal model for predicting the risk of treatment failure in TB-DM, with a high sensitivity of 71.1%, specificity of 91.7%, and an AUC of 0.9218 on the cross-validated test set. In addition, nine features were selected as predictors of treatment failure in TB-DM and certain laboratory tests were identified as critical potential predictors.
In our study, seven routine blood parameters, such as PDW, PT, TT, APTT, TP, HDL, and HbA1c, are particularly important in our models after feature selection. It is challenging to accurately interpret predictions from tree-based ML models, such as tree gradient boosting machines and random forests. Feature attribution for trees is often heuristic and not personalized for each prediction. SHAP can address the above problems. Thus, we found higher APTT, HbA1c, and PDW and lower TT, HDL and PT may increase the risk of treatment failure of TB-DM by using SHAP values to analyze the results from the XGboost model. Verma et al. have reported a significant correlation between platelet abnormalities and stroke in patients with tuberculous meningitis (TBM)18. In their study, they found platelet distribution width (PDW) (p < 0.001) was significantly associated with infarction in patients with TBM. In 2018, Dong et al. found hemostasis and dyslipidemia were related to exacerbated lung damage in TB, especially in patients with TB-DM, by comparing inflammatory biomarkers and hematologic and biochemical parameters between the two groups of patients, one with TB-DM and the other with TB19. Of note, other studies have reported the similar results20,21.
In our study, we demonstrated that each selected feature contributed positively or negatively to the probability of treatment failure of TB-DM, as indicated SHAP values. The resistance type is the strongest predictor of treatment outcome, and lower-level drug resistance has a more apparent negative relationship with treatment failure, as expected. Not surprisingly, patients who have a history of TB are at an increased risk of unfavorable treatment outcome. Although none of radiology features were selected into the ML models, some of their manifestations, such as multiple cavities, thick-walled cavity, the number of pulmonary lobes involved, and nodules, have been shown to be potential factors to predict the treatment outcome of TB-DM to some extent in previous studies5,22,23. In addition, Yang. et al. reported that radiological features, which are obtained using a single experienced radiologist reading per image, can be used for predicting drug-resistant TB (DR-TB), and that automatic discrimination between DR-TB and drug-sensitive TB (DS-TB) is possible24. Another study has also demonstrated that the ML model they constructed showed that radiologist observations of CT are a promising predictive method for the treatment outcome of TB25. Deep learning and artificial intelligence (AI) are extensively being utilized in medical image processing to assign labels and annotations to features with the aim of aiding diagnosis and prognosis. Recently, AI methods have shown superior performance compared to radiologists in distinguishing TB from non-TB using chest radiographs. However, it is important to note that radiologist evaluations of medical images are still considered the definitive benchmark for supporting the advancement of AI26. Clinically, distinguishing the treatment outcome of patients with TB based solely on CT images using an ML model is challenging, because CT images of TB are complicated. For instance, TB patients with different conditions exhibit multiple nodules, funicular foci, patchy dense shadows, cavities, and buds. So far, there has been no research reporting the prediction of deep learning based on CT images analysis model for the treatment outcome of pulmonary tuberculosis. Most radiomics studies based on CT with ML in TB focus on differentiating between TB and lung cancer, identifying active TB, or predicting multidrug resistance. Moreover, these studies share a common characteristic in that they typically model one feature of tuberculosis imaging, such as nodules or lung cavitation, without incorporating multiple features of tuberculosis imaging into the model. To strength our results, we applied all the full set of CT features into our optimal model, and comparison the optimal ML model and ML model plus the full set of CT features27,28,29,30,31.
Several limitations in our studies should be mentioned. Firstly, this study is a retrospective and single-center study, which is not a nationally representative. Therefore, the differences in other ethnic groups should be considered when applying our model to other populations. Secondly, there is no external validation of our models, which may restrict their applicability. Thus, further research in the future should be conducted to verify the generalizability of our findings. Thirdly, bacillary load in sputum is not routinely measured in our lab, which might influence treatment outcome. Fourth, compared to the conventional method, the ML model, XGBoost, showed the marginal improvement in AUC-ROC and lower sensitivity. The sample size in the current study was relatively small from a ML perspective, which might be partially responsible for the poor sensitivity of the prediction model.
Despite the above limitations, ML models have several advantages such as handling non-linearity and capturing complex interactions among features, which may not be effectively captured by the conventional model. The use of ML does not inherently imply automatic superiority over traditional methods, despite literature that has demonstrated so32,33. The effectiveness of predictive models in ML hinges on both the quality of the data utilized and the meticulous execution of the analysis. Furthermore, the results of this present study do not necessarily indicate that machine learning is completely superior to conventional statistics, but rather it highlights an inherent advantage of ML.
Conclusions
In our study, four ML approaches for treatment failure of TB-DM yielded high predictions with functional and actionable interpretations based on ERM data. Our model is thus valuable for treating and managing TB-DM in developing countries and provides new insights for the WHO End TB Strategy.
Data availability
The datasets used and/or analyzed during the current study are not publicly available due to its proprietary nature, supporting data cannot be made openly available. But are available from the corresponding author on reasonable request.
References
WHO. WHO (2022). Global Tuberculosis Report. 2022. https://www.who.int/publications/i/item/9789240061729.
WHO. The end TB strategy. World Health Organization; 2015;2015.
Calderon, R. I. et al. Persistent dysglycemia is associated with unfavorable treatment outcomes in patients with pulmonary tuberculosis from Peru. Int. J. Infect. Dis. 116, 293–301 (2022).
Arriaga, M. B. et al. The effect of diabetes and prediabetes on Mycobacterium tuberculosis transmission to close contacts. J. Infect. Dis. 224(12), 2064–2072 (2021).
Chen, Y. et al. Association of TyG index with CT features in patients with tuberculosis and diabetes mellitus. Infect. Drug Resist. 15, 111–125 (2022).
Du, Q., Wang, L., Long, Q., Zhao, Y. & Abdullah, A. S. Systematic review and meta-analysis: Prevalence of diabetes among patients with tuberculosis in China. Trop. Med. Int. Health 26(12), 1553–1559 (2021).
Li, Z. et al. Computer-aided diagnosis of spinal tuberculosis from CT images based on deep learning with multimodal feature fusion. Front. Microbiol. 13, 823324 (2022).
Sauer, C. M. et al. Feature selection and prediction of treatment failure in tuberculosis. PLoS ONE 13(11), e0207491 (2018).
Asad, M., Mahmood, A. & Usman, M. A machine learning-based framework for Predicting Treatment Failure in tuberculosis: A case study of six countries. Tuberculosis 123, 101944 (2020).
Schwalbe, N. & Wahl, B. Artificial intelligence and the future of global health. Lancet. 395(10236), 1579–1586 (2020).
WHO. WHO revised definitions and reporting framework for tuberculosis. Euro Surveill. 18(16), 20455 (2013).
Kursa, M. B. J. A. & Rudnicki, W. R. Boruta—A system for feature selection. Fundam. Inform. 45, 5–32 (2010).
Lundberg, S. M. et al. From local explanations to global understanding with explainable AI for trees. Nat. Mach. Intell. 2(1), 56–67 (2020).
Lundberg, S. M., Erion, G. G., & Lee, S.-I. Consistent individualized feature attribution for tree ensembles. arXiv preprint arXiv:180203888. 2018.
Alemu, A., Bitew, Z. W. & Worku, T. Poor treatment outcome and its predictors among drug-resistant tuberculosis patients in Ethiopia: A systematic review and meta-analysis. Int. J. Infect. Dis. 98, 420–439 (2020).
Leung, C. C. et al. Smoking adversely affects treatment response, outcome and relapse in tuberculosis. Eur. Respirat. J. 45(3), 738–745 (2015).
Duraisamy, K. et al. Does Alcohol consumption during multidrug-resistant tuberculosis treatment affect outcome? A population-based study in Kerala, India. Ann. Am. Thorac. Soc. 11, 712–718 (2014).
Verma, R. et al. Platelet dysfunction and coagulation assessment in patients of tuberculous meningitis. Neurol. Sci. 41(8), 2103–2110 (2020).
Dong, Z. et al. Hemostasis and Lipoprotein Indices Signify Exacerbated Lung Injury in TB With Diabetes Comorbidity. Chest. 153(5), 1187–1200 (2018).
Deniz, O. et al. Serum total cholesterol, HDL-C and LDL-C concentrations significantly correlate with the radiological extent of disease and the degree of smear positivity in patients with pulmonary tuberculosis. Clin Biochem. 40(3–4), 162–166 (2007).
Vinnard, C. & Blumberg, E. A. Endocrine and Metabolic aspects of tuberculosis. Microbiol. Spectr. 5, 1 (2017).
Xia, L. L. et al. The correlation between CT features and glycosylated hemoglobin level in patients with T2DM complicated with primary pulmonary tuberculosis. Infect. Drug Resist. 11, 187–193 (2018).
Yang, W. B. et al. The correlation between CT features and insulin resistance levels in patients with T2DM complicated with primary pulmonary tuberculosis. J. Cell Physiol. 235(12), 9370–9377 (2020).
Yang, F. et al. Differentiating between drug-sensitive and drug-resistant tuberculosis with machine learning for clinical and radiological features. Quant. Imaging Med. Surg. 12(1), 675–687 (2022).
Rosenfeld, G. et al. Radiologist observations of computed tomography (CT) images predict treatment outcome in TB Portals, a real-world database of tuberculosis (TB) cases. PLoS ONE 16(3), e0247906 (2021).
Rubin, D. L. Artificial Intelligence in Imaging: The Radiologist’s Role. J. Am. Coll. Radiol. 16(9 Pt B), 1309–1317 (2019).
Li, Y. et al. Radiomics analysis of lung CT for multidrug resistance prediction in active tuberculosis: A multicentre study. Eur. Radiol. 33(9), 6308–6317 (2023).
Zhang, X. et al. Deep learning PET/CT-based radiomics integrates clinical data: A feasibility study to distinguish between tuberculosis nodules and lung cancer. Thorac. Cancer. 14(19), 1802–1811 (2023).
Nijiati, M. et al. Deep learning based CT images automatic analysis model for active/non-active pulmonary tuberculosis differential diagnosis. Front. Mol. Biosci. 9, 1086047 (2022).
Zhang, W. et al. New diagnostic model for the differentiation of diabetic nephropathy from non-diabetic nephropathy in Chinese patients. Front. Endocrinol. 13, 913021 (2022).
Li, Y. et al. Machine learning and radiomics for the prediction of multidrug resistance in cavitary pulmonary tuberculosis: A multicentre study. Eur. Radiol. 33(1), 391–400 (2023).
Raita, Y. et al. Emergency department triage prediction of clinical outcomes using machine learning models. Crit. Care 23, 1–13 (2019).
Ley, C.A.-O. et al. Machine learning and conventional statistics: Making sense of the differences. Knee Surg. Sports Traumatol. Arthrosc. 30(3), 753–757 (2022).
Funding
This study was funded by Youth Doctoral Program of Xinqiao Hospital, Third Military Medical University, Chongqing, No. 2023YQB064.
Author information
Authors and Affiliations
Contributions
Y.C., A.Z.-P., and Q.Z. conceived and designed the study. X.H.-K., S.T.-L., H.F.-Z., L.L.-X., and L.J.-M. participated in data collection. Y.C. and Q.Z. finished data analysis. Y.C. wrote this manuscript and prepared Figs. 1, 2, 3, 4, 5, 6. Y.C., A.Z.-P., and Q.Z. reviewed the manuscript. All authors read and approved the final manuscript.
Corresponding authors
Ethics declarations
Competing interests
The authors declare no competing interests.
Additional information
Publisher's note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Supplementary Information
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Peng, Az., Kong, XH., Liu, St. et al. Explainable machine learning for early predicting treatment failure risk among patients with TB-diabetes comorbidity. Sci Rep 14, 6814 (2024). https://doi.org/10.1038/s41598-024-57446-8
Received:
Accepted:
Published:
DOI: https://doi.org/10.1038/s41598-024-57446-8
Comments
By submitting a comment you agree to abide by our Terms and Community Guidelines. If you find something abusive or that does not comply with our terms or guidelines please flag it as inappropriate.
