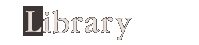Figure 2: Frameshift
Figure 2: Frameshift












« Prev Next »
Once scientists determined that messenger RNA (mRNA) served as a copy of each gene's DNA and specified the sequence of amino acids in proteins, they immediately had many more questions about the process of protein formation. Specifically, these researchers knew that proteins are made from 20 different amino acids. Moreover, they also knew that there were only four nucleotides in mRNA: adenine (A), cytosine (C), guanine (G), and uracil (U). But how exactly could these four nucleotides code for all 20 amino acids? The answer to this question turned out to be simpler than one might expect.
Determining the Number of Nucleotides Per Amino Acid
Right away, researchers knew that the genetic code was more complex than one nucleotide per amino acid. After all, if this was the case, a person's DNA could only code for four different amino acids. In fact, even two nucleotides per amino acid (i.e., a doublet code) could not account for 20 amino acids, because such a code provides only 16 permutations (four bases at each of two positions = 4 × 4 = 16 amino acids).

Figure 1: Distinct possibilities: Overlapping or non-overlapping genetic code?
Early researchers studying the genetic code had to determine if the mRNA encoding amino acids was non-overlapping. Was it each sequential set of three nucleotides encoding one amino acid? Or was it overlapping, with each three-nucleotide code beginning on sequential single nucleotides?
© 2008 Nature Education All rights reserved. 

Table 1: Did the code have commas or not?
A non-overlapping code provided scientists with predictions they could test.
© 2008 Nature Education All rights reserved.
Ruling Out Overlaps
In their investigation of the exact nature of the genetic code, scientists first turned to the question of possible overlaps. Specifically, researchers Akira Tsugita and Heinz Fraenkel-Conrat (1960) proposed that if the code were overlapping, a mutation (or change) in one nucleotide would cause changes in more than one amino acid in the resulting protein. Fortunately, recent technological advancements had made it possible for Tsugita and Fraenkel-Conrat to determine the amino acid sequence in short proteins. Thus, by comparing protein sequences made from both nonmutated and mutated DNA, they were able to resolve this issue. First, the research team treated tobacco mosaic virus DNA with nitrous acid, leading to a point mutation in the DNA sequence. Then, they compared the protein produced by the mutated DNA with that produced by the "normal" viral DNA. Strikingly, the amino acid sequence of the "mutant" protein contained a change in only one amino acid, strongly suggesting use of a non-overlapping code.
Determining Codon Length

© 1961 Nature Publishing Group Crick, F. H. et al. General Nature of the Genetic Code for Proteins. Nature 192, 1229 (1961). All rights reserved.
However, Tsugita and Fraenkel-Conrat's findings alone did not resolve whether the genetic code was read in sets of three nucleotides or perhaps more. This issue was addressed by a separate research team consisting of Francis Crick, Leslie Barnett, Sydney Brenner, and Richard Watts-Tobin. In 1961, this group provided the first evidence for a triplet code by way of experiments using the T4 bacteriophage (a bacteria-specific virus).
In particular, these researchers devised a clever assay that enabled them to deduce the properties of the genetic code following introduction of a special kind of mutation, known as a frameshift mutation. A frameshift mutation is caused by either the addition or the deletion of a base in the original DNA sequence, which in turn causes the protein-forming machinery to shift positions (or reading frames) on the RNA. Such a frameshift alters codon groupings, and thus the corresponding protein is made with incorrect amino acids from the point of the mutation onward (Figure 2).
In their work, the research team first introduced a single frameshift mutation into a viral protein involved in the infection of E. coli bacteria. (Bacterial infection was the readout in this experiment.) This addition of a lone frameshift mutation rendered the resulting protein ineffective. The researchers then introduced additional frameshift mutations in the hope that doing so would restore the correct reading frame (and, in turn, allow the protein to once again play a role in the infection of E. coli). The experiment worked! For example, when the first mutation added a base (+), a later suppressor mutation (-), which deleted a base, was able to put the code back on track.
Interestingly, the team noted that the introduction of three separate frameshift mutations that each added a base (+ + +) to the same DNA were also sometimes (when they were close together) able put the code back on track. Similarly, three mutations that deleted a base (- - -) could also rescue protein function and infectivity. Therefore, the code was only thrown off by nontriplet changes. This finding strongly supported the existence of a triplet code, or at least a code written in multiples of three bases. Thus, when Crick and his colleagues analyzed their results, they were the first people to see that the genetic code was based on multiples of three bases!
References and Recommended Reading
Crick, F. H. C., et al. General nature of the genetic code for proteins. Nature
192, 1227–1232 (1961). doi:10.1038/1921227a0 (link to article)
Tsugita, A., & Fraenkel-Conrat, H. The amino acid composition and C-terminal sequence of a chemically evoked mutant of TMV. Proceedings of the National Academy of Sciences 46, 636–642 (1960)