
Abstract
Accurate prediction of sea level height is critically important for the government in assessing sea level risk in coastal areas. However, due to the nonlinear, time-varying and highly uncertain characteristics of sea level change data, sea level prediction is challenging. To improve the accuracy of sea level prediction, this paper uses a new swarm intelligence algorithm named the sparrow search algorithm (SSA), which can imitate the foraging behavior and antipredation behavior of sparrows, to determine optimal solutions. To avoid the algorithm falling into a local optimal situation, this paper integrates the sine–cosine algorithm and the Cauchy variation strategy into the SSA to obtain an algorithm named the SCSSA. The SCSSA is used to optimize the parameter values of the CNN-BiLSTM (convolutional neural network combined with bidirectional long short-term memory neural network) model; finally, a combined neural network model (named SCSSA-CNN-BiLSTM) is proposed. In this paper, the time series data of seven tidal stations located in coastal China are used for experimental analysis. First, the SCSSA-CNN-BiLSTM model is compared with the CNN-BiLSTM model to predict the time series data of SHANWEI Station. With respect to the training and test sets of data, the SCSSA-CNN-BiLSTM model outperforms the other models on all the evaluation metrics. In addition, the remaining six tide station datasets and five neural network models, including the SCSSA-CNN-BiLSTM model, are used to further study the performance of the proposed prediction model. Four evaluation indices including the root mean squared error (RMSE), mean absolute error (MAE), mean absolute percentage error (MAPE) and coefficient of determination (R2) are adopted. For six stations, the RMSE, MAE, MAPE and R2 of SCSSA-CNN-BiLSTM model are ranged from 20.9217 ~ 27.8427 mm, 9.4770 ~ 17.8603 mm, 0.1322% ~ 0.2482% and 0.9119 ~ 0.9759, respectively. The experimental analysis results show that the SCSSA-CNN-BiLSTM model makes effective predictions at all stations, and the prediction performance is better than that of the other models. Even though the combination of SCSSA algorithm may increase the complexity of the model, indeed the proposed model is a new prediction method with good accuracy and robustness for predicting sea level change.
Similar content being viewed by others

Introduction
In the context of global warming, sea level rise has become a major global environmental problem, and the study of global and regional sea level changes is a hot topic in marine science at home and abroad. Direct observations of modern climate change show that the global climate system is undoubtedly warming. The sea level continues to rise due to the expansion of ocean heat and the loss of glacier material caused by global warming1. Global sea level rise will increase the vulnerability of low-lying coastal urban populations and ecosystems, which are often affected by natural disasters such as floods, tides and saltwater intrusion.
To actively cope with the social and economic impacts of sea level rise on coastal areas in the context of climate change, countries need the ability to make reasonable predictions of the sea level rise trends. An artificial neural network (ANN) can learn and capture trends in sea level change very effectively. As a data-driven model, an ANN can establish the relationship between inputs and outputs through repeated training. Moreover, the larger the amount of data, the better the training effect will be. Therefore, many scholars apply ANNs to sea level predictions. Röske2 first applied a neural network to sea level prediction for the North Sea coast of Germany, providing a new way of thinking in the sea level prediction field. Since then, neural networks have been widely used by relevant researchers in ocean predictions. For example, O. Mackarynskyy et al.3 have used neural networks to predict hourly sea level changes measured by tide gauges in Boat Harbor, Hillarys, Western Australia; half-day, one-day, 5-day and 10-day mean sea levels were also measured. Huang et al.4 developed a regional water level neural network for predicting water levels at coastal inlets, and successfully predicted water levels at local stations at coastal inlets using a series of water levels at NOAA stations at a certain distance. Karimi et al.5 used the adaptive neuro-fuzzy inference system (ANFIS) model, ANN model and autoregressive moving average (ARMA) model to predict and compare the sea level data series of tidal gauges in Darwin Harbor. The experimental results showed that the prediction effects of the ANFIS model and ANN model were similar and superior to that of the ARMA model. Muslim et al.6 used two neural networks, the ANFIS and multilayer perceptron neural network (MLP-ANN), to explore the effects of different meteorological parameters on sea level rise predictions in different periods and found that the ANFIS model had a better prediction performance than the MLP-ANN model. Guillou et al.7 used multiple regression methods and multilayer perceptrons to predict regional sea levels in western Brittany, France. Makarynska et al.8 used a feedforward neural network to predict the sea level and compared it with the actual value; the authors concluded that the method in the paper could be used for sea level prediction through evaluation indicators. Nieves et al.9 used Gaussian processes and recurrent neural networks to predict coastal sea level changes at regional locations on different time scales. ANNs have also been applied in storm surge forecasting10,11,12. The least squares estimation (LSE) model, multiple linear regression (MLR) model and several single neural networks were used to predict the daily mean sea level height13. Other scholars have used neural network models to construct ocean temperature anomaly predictions14,15.
All the above studies used a single neural network model to make predictions. However, every single model was not perfect and had its own limitations. With the deepening of related research, many people have combined other methods and neural networks, or a variety of neural networks, to form hybrid models for prediction. In this way, the advantages of various neural networks can be used simultaneously. Fourier transforms and wavelet transforms are the most widely used methods for denoising signal data16. Wang et al.17 proposed a method that combines wavelet decomposition and an adaptive neural fuzzy inference system (ANFIS) to construct a hybrid model capable of predicting multi-hour sea level. In 2007, researchers combined harmonics with BP neural networks to forecast tides18. Han et al.19 predicted SST by combining CNN and gated recurrent units (GRU) together with frequency analyses, and others used a network model that combines the CNN model with the long short-term memory (LSTM) model in ocean prediction20,21. A hybrid model can combine the advantages of several models, so the prediction ability is greatly improved.
However, whether a single model or a mixed model is used, many parameters involved in the model need to be determined by experience or trial and error, which adds subjective factors. Therefore, several researchers have turned their attention to optimization algorithms, which can be used alone or can optimize the parameters of the traditional methods and obtain more reasonable parameter settings, greatly improving the predictive performance of the model. The most widely used optimization algorithms are the genetic algorithm (GA) and particle swarm optimization (PSO). In 2004, Alvarez et al.22 successfully constructed a prediction model for the Ligurian Sea SST and sea level anomalies using the GA algorithm. You et al.23 used a GA to optimize the parameters of a two-dimensional storm surge calculation model, thereby improving the sea level prediction results. Wang et al.24 used a GA to optimize the parameters of a wavelet neural network for non-astronomical tide forecasting. Cheng et al.25 proposed an improved genetic algorithm and applied it to the optimization of reservoir systems with good results. Wang et al.26 proposed a hybrid genetic algorithm that combines chaos and simulated annealing methods, and the experimental results showed that the proposed hybrid algorithm is superior to both genetic algorithms and chaotic genetic algorithms. Some scholars use PSO and support vector machines to find the best value27. Nagappan et al.28 used the PSO algorithm to optimize ANN weights and predict faults in systems. Many other optimization algorithms have been applied in practice. Examples include the artificial bee colony (ABC) algorithm and ant colony optimization (ACO) algorithm29, the cuckoo search (CS) algorithm30 and the imperialist competition algorithm (ICA)31. Alizadeh et al.32 applied GA, ICA, CS and the bee algorithm (BA) to ANN training to optimize its weight and deviation values and compared them with the traditional Levenberg–Marquardt (LM) algorithm. The results show that the CS, ICA and BA algorithms are more effective than the GA and LM algorithms.
The various examples above show that a combination algorithm can improve the prediction accuracy, and the prediction performance can be further enhanced if the parameters are optimized by an optimization algorithm. Therefore, this paper combines the improved sparrow search optimization algorithm (SCSSA) with a CNN model and a BiLSTM model to propose a combination model named SCSSA-CNN-BiLSTM. The prediction ability of the model proposed in this paper is verified by using the data from multiple tide stations and comparing the results with those of four other models. The main innovations and contributions of the paper are as follows:
-
(1)
In this paper, the CNN-BiLSTM combined with a neural network model is applied to sea level time series predictions. A prediction experiment of sea level time series data from multiple tide stations shows that the combined CNN-BiLSTM model outperforms the single models in this field.
-
(2)
In this paper, a new optimization algorithm combining the sparrow search algorithm with sine–cosine and the Cauchy variation (SCSSA) is proposed and used to optimize the learning rate, the number of hidden layer nodes and the parameter values of the regularization coefficient of the CNN-BiLSTM neural network model, which avoids the unsatisfactory parameter settings caused by the artificial selection of parameter values according to experience. By comparing and analyzing the measured time series data of tide stations, it is concluded that the SCSSA-CNN-BiLSTM model is better than the CNN-BiLSTM model for sea level time series predictions.
-
(3)
In prediction analysis cases, this paper takes the measured sea level time series of six tide stations in China as the dataset and uses the single neural network models LSTM, CNN and BiLSTM and the combined models CNN-BiLSTM and SCSSA-CNN-BiLSTM for prediction and comparison. The accuracy and robustness of the SCSSA-CNN-BiLSTM model for sea level prediction are verified, and the results of this study may lead to new ideas for sea surface-related research in coastal areas.
The rest of this paper is organized as follows. The “Theory and methods” section describes the basic principles used in the experiment. The “Results” section contains predictive comparison experiments between the model proposed in this paper and the model before optimization. The proposed model and various prediction models are discussed and compared in the “Discussions” section, and finally, the concluding remarks are provided in the “Conclusions” section.
Theory and methods
Study area
The study area is the coastal waters of China. To verify the reliability and applicability of the method proposed in this paper, monthly mean sea level data from 7 tide stations located in the coastal waters of China were used. The study area is shown in Fig. 1. The specific information of the data of each tide station is shown in Table 1. The missing data for each station are shown in Table 2. These missing values are supplemented by linear interpolation.

Study area map.
In this paper, we use China's coastal tide station’s MMSL data from the Permanent Service for Mean Sea Level (https://www.psmsl.org/data/obtaining/). The entire prediction process was completed in MATLAB 2021b software using a personal computer configured with an Intel(R) Core(TM) i5-8300H CPU, 8.00 GB of RAM, an NVIDIA GeForce GTX 1050 Ti graphics card and a Windows 10 operating system. The prediction method of this paper is single step prediction, and the lag is selected as 12. The first 12 data points of each station data in Table 1 serve as startup input variables to predict the subsequent sea level data. The first 70% of the remaining data is divided into a training set for training the model, and the last 30% is divided into a test set for testing the prediction effect of the trained model.
Bidirectional long short-term memory neural network (BiLSTM)
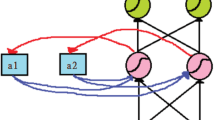
The LSTM model is a variant of a recurrent neural network (RNN) in which information from each time step is no longer passed on to the next time step but rather via an additional “memory” unit. This allows LSTM to better handle long-term dependencies without the problem of disappearing gradients. LSTM introduces three gating mechanisms, namely, an input gate, forget gate and output gate, to choose to forget or retain information33. The BiLSTM model is further improved based on the LSTM model using a forward and reverse bidirectional LSTM so that its output results can not only use past data but can also connect with future data, which is highly suitable for processing time series data. The structure of the BiLSTM model is shown in Fig. 2, where \(h_{t}\) and \(h_{t}^{\prime}\) are the reverse and forward LSTM hidden layers, respectively. \(x_{t}\) is the input value, \(y_{t}\) is the final output value, \(t\) is the \(t\) th time step and \(\sigma\) is the sigmoid function.

BiLSTM model structure.
CNN-BiLSTM
Convolutional neural network (CNN) is a class of feedforward neural networks that include convolutional computations and have deep structures. The essence of the CNN model is to build multiple convolutional filters that can extract data features and use hierarchical convolutional structures to gather input data to extract hidden topological features in the data34. With the increase in the number of network layers, the features extracted by the model will become increasingly abstract, and these abstract features will be integrated through the fully connected layer and then processed by the softmax or sigmoid activation function for classification or regression35.
CNN and BiLSTM are two important deep learning models. The CNN model performs well in extracting local features from the data and combining these features to form advanced features. In contrast, BiLSTM is more suitable for time expansion and has good long-term memory functions36. When the advantages of both methods are fully combined, the processing of the time series will improve. The structure of the CNN-BiLSTM model is shown in Fig. 3.

Structural diagram of the CNN-BiLSTM model.
A sparrow search algorithm combining sine–cosine and the Cauchy variation
The sparrow search algorithm (SSA)37 is an optimization algorithm proposed in 2020 that divides sparrows into three categories, discoverers, followers and observers. The discoverers can preferentially find food for the colony and guide the follower to forage. The position of sparrows can be represented in the following matrix:
where \(n\) is the number of sparrows and \(d\) represents the dimension of the variables of the problems to be optimized. Then, the fitness value of all sparrows can be expressed by the following matrix:
where \(n\) is the number of sparrows , \(d\) represents the dimension of the variables of the problems to be optimized, and the value of each row in \(F_{X}\) represents the fitness value of the individual.
Sparrows with better fitness values have the priority to find food and become discoverers, leading the entire population to find the source of food. The discoverers' position update equation is:
where \(X_{i,j}^{t}\) is the position of the \(i{\text{th}}\) sparrow in dimension \(j\) under the iteration number \(t\), \(\alpha \in {\text{rand}}\left( {0,1} \right]\), \(Iter_{\max }\) is the maximum number of iterations, \(R_{2} \in (0,1)\), it is the warning level, \(ST \in \left[ {0.5,1} \right]\), represents a safe value, \(Q\) is a random number that follows a normal distribution and \(L\) is a matrix with a row of d-dimensional elements that are all one.
The equation for updating the followers' positions is as follows:
where \(X_{Worst}^{t}\) is the overall worst position, \(n\) is the total number of sparrows, and \(i > n/2\) indicates that the ith sparrow has a poor fitness value and needs to fly to other locations to feed. \(X_{p}\) is the optimal location for the discoverers, A is a matrix with a row of d-dimensional elements that are randomly 1 or -1 and \(A^{ + } = A^{T} (AA^{T} )^{ - 1}\).
Considering the need for safe predation for the entire population, with 10% to 20% of the sparrows in the population acting as observers, the position update equation is:
where \(X_{best}^{t}\) is the overall optimal position, \(\beta\) is the step size correction coefficient following the normal distribution, \(f_{i}\) is the fitness value of the sparrow, and \(f_{\omega }\) and \(f_{g}\) are the worst and best overall fitness, respectively. When \(f_{i} > f_{g}\), it indicates that the sparrows are at the edge of the pack and are prone to danger; when \(f_{i} = f_{g}\), it indicates that the sparrows in the pack feel the danger of the enemy and should immediately move toward the other sparrows. \(k \in [-1,1]\) is a random number, and \(\varepsilon\) is an extremely small constant that prevents the denominator from being zero.
During the process of hunting a sparrow, the food source may be different, as may the location. When the food found by the discoverers is locally optimal, a large number of followers will flock to the location, causing the discoverers and the entire group to stagger and lose positional diversity, thereby increasing the probability of falling into local extremes. Therefore, the sine–cosine algorithm (SCA)38 was introduced into the SSA in this paper, and the oscillating change characteristics of the sine and cosine models were used to determine the location of the discoverers and maintain the individual diversity of the discoverers, thereby improving the global search ability of the SSA to avoid falling into local optima.
The step search factor in the sine–cosine algorithm is as follows:
where \(a\) is a constant, \(t\) is the number of iterations, and \(Iter_{\max }\) is the maximum number of iterations. The step search factor shows a linear decreasing trend, which is not conducive to balancing the global search and local development capabilities of the SSA. Therefore, the step search factor is improved. The new nonlinear decreasing search factor is shown in Eq. (7). In addition, the update of the population individual position of the SSA is often affected by the current position, so a nonlinear weight factor \(\omega\) is added to adjust this situation, and the mathematical equation of \(\omega\) is Eq. (8).
where \(\eta\) is the adjustment factor, \(\eta \ge 1\), and \(a = 1\).
The new discoverers' mathematical equation then becomes:
where \(r_{2} \in \left[ {0,2\pi } \right]\) and \(r_{3} \in \left[ {0,2\pi } \right]\) control the movement distance of the sparrow and the influence of the optimal individual on the next position of the sparrow population, respectively.
To avoid the local optimal solution, this paper also introduces the Cauchy variation strategy into the original follower equation to obtain a new follower equation:
where \(cauchy(0,1)\) is the standard Cauchy distribution function.
The Cauchy distribution is similar to the normal distribution, however, the shape of the whole distribution is flatter, and the speed of approaching the zero value is slower. Therefore, perturbation of the sparrow position update in the population with the Cauchy distribution can expand the search range of the algorithm so that it is not easy for the algorithm to fall into a local optimal situation.
After improvement, the the SCSSA algorithm procedure is as follows:
-
Step 1: Initialize the population.
-
Step 2: Calculate the fitness value of each sparrow to find the best and worst individuals.
-
Step 3: Update the discoverer position with the new discoverers equation.
-
Step 4: Update the followers’ positions with the new followers equation.
-
Step 5: Update the observers’ positions using the original equation.
-
Step 6: Check whether the number of iterations reaches the termination condition. If yes, go to the next step. If not, go back to Step 2.
-
Step 7: The calculation is complete, and the optimal position and fitness value are displayed.
SCSSA-CNN-BiLSTM
Considering that many parameters in the CNN-BiLSTM model are manually and subjectively set, there may be unreasonable parameters. Therefore, this paper optimizes the parameters of the CNN-BiLSTM model via the SCSSA algorithm and proposes the SCSSA-CNN-BiLSTM sea-level time series prediction model. A structural diagram of the SCSSA-CNN-BiLSTM model in this paper is shown in Fig. 4. The optimization and prediction process of the entire model is shown in Fig. 5 and is divided into the following steps:
-
Step 1: Divide the original data into a training set and a test set.
-
Step 2: The training set is input into the model to train the model, the CNN-BiLSTM model is optimized through the SCSSA algorithm, and the optimized SCSSA-CNN-BiLSTM model is built.
-
Step 3: The test set is input into the constructed SCSSA-CNN-BiLSTM model to obtain the predicted values.
-
Step 4: Compare and verify the measured real values with the predicted values to evaluate the prediction effect.

Structural diagram of the SCSSA-CNN-BiLSTM model.

Prediction flow chart of the SCSSA-CNN-BiLSTM model.
Evaluation indices
To evaluate the prediction effect of the monthly mean sea level time series of tide stations, this paper adopts four evaluation indices commonly used in the prediction field, namely, the square root error (RMSE), mean absolute error (MAE), mean absolute percentage error (MAPE) and coefficient of determination (R2). The equations for the four evaluation indices are as follows.
where \(x_{i}\) is the measured value, \(\hat{x}_{i}\) is the predicted value, \(\overline{x}_{i}\) is the mean measurement and \(N\) is the number of samples.
Results
Data analysis
Statistical indicators for seven stations, including the mean and standard deviation (SD), were calculated. The minimum (Min), maximum (Max) and skewness (Skew) are shown in Table 3.
Optimization process
In this section, the SCSSA algorithm is used to optimize the parameters of the CNN-BiLSTM model to obtain reasonable parameter values. The CNN-BiLSTM model contains two convolutional layers and three BiLSTM layers. The training epochs of all the models were set to 300, and the initial learning rate was 0.01. The convolution kernel of the two convolutional layers is 3 times 1, the stride is 1, the activation function of the convolution layer uses the ReLU function, the pooling window size of the pooling layer is 2 times 1, and the stride is 1. The number of nodes in the BiLSTM layer is 10, both the forward and reverse LSTM gate structures in the BiLSTM layer uses sigmoid and tanh activation functions, the dropout rate is 0.2 and the regularization coefficient is set to 0.002. The initial learning rate, regularization coefficient and number of neurons in the BiLSTM hidden layer of the SCSSA-CNN-BiLSTM model are obtained by the optimization algorithm, and the other parameter settings are the same as those of the CNN-BiLSTM model. The population of the SSA is 10, the number of iterations is 6 and the selected data of the tide station are the monthly mean sea level data of the SHANWEI Station. In the optimization process, the minimum RMSE is used as the objective function. When the number of iterations was completed, each parameter value corresponding to the minimum fitness value was saved as the optimized parameter value. The fitness value curve in the optimization is shown in Fig. 6, and the range of each parameter to be optimized and the optimal parameters obtained are shown in Table 4.

SCSSA fitness curve.
Prediction comparison
To reflect the improvement of the prediction accuracy of the optimized CNN-BiLSTM model, the CNN-BiLSTM model and SCSSA-CNN-BiLSTM model were adopted to predict the monthly mean sea level data of the SHANWEI Station. The prediction diagram of the SHANWEI station data is shown in Fig. 7. As shown in the left diagram, both models better predicted the size and trend of the data in the prediction of the training set. However, the data predicted by the SCSSA-CNN-BiLSTM model are more consistent with the data of the original training set than are those predicted by the CNN-BiLSTM model. On the right, both models predict the general trend of the data, however, the data values predicted by the CNN-BiLSTM network model exhibit many obvious deviations from the original data values. The data predicted by the SCSSA-CNN-BiLSTM network model are in good agreement with the original data both in terms of value size and data trend, and the prediction effect is better.

Prediction comparison between the two models at the SHANWEI station. (a) Training set prediction comparison and (b) test set prediction comparison.
Four evaluation indices were used to quantitatively evaluate the prediction effects of the two models, and the specific values are shown in Table 5. All the evaluation indices indicated that the SCSSA-CNN-BiLSTM model achieved the most accurate predictions, and the prediction accuracy was significantly improved by parameter optimization.
Discussions
Comparison of prediction results of various models
In the previous section, the prediction performances of the CNN-BiLSTM model and the SCSSA-CNN-BiLSTM model were compared. To better explore the prediction ability and universality of the SCSSA-CNN-BiLSTM model, a variety of network models are used to forecast the monthly mean sea level time series of six tide stations and compare the predicted results. Considering that SCSSA-CNN-BiLSTM and CNN-BiLSTM are combinations of the CNN model and BiLSTM model, and that the BiLSTM model evolves on the basis of the LSTM model, the models selected for comparison in this section are LSTM, BiLSTM, CNN, CNN-BiLSTM and SCSSA-CNN-BiLSTM. The parameters of the various models have been obtained through multiple tests. The training epochs of all the models were set to 300, and the initial learning rate was 0.01. The LSTM model and BiLSTM model have two hidden layers, and the number of hidden layer nodes is 10. The gate structures in BiLSTM and LSTM uses sigmoid and tanh activation functions. The convolution kernel of the two convolutional layers of the CNN model is 3 times 1, the stride is 1, the activation function of the convolution layer uses the ReLU function, the pooling window size of the pooling layer is 2 times 1 and the stride is 1. The parameter settings of the CNN-BiLSTM model and the SCSSA-CNN-BiLSTM model are the same as those in the previous section.
The test set prediction results for the data from the six tide stations are shown in Fig. 8. The figure shows that the five neural network models used at the six tide stations can all predict the test set of the data to a certain extent. Among them, the SCSSA-CNN-BiLSTM model has the best prediction effect and best fits the data of the test set; this result is more obvious for tide stations with a large amount of data. In addition, the CNN-BiLSTM model has good performance and is similar to the test set in terms of the data trend and value size. The LSTM, BiLSTM and CNN models can predict approximate data trends and values but they all have some deviations. The NANSHA, XISHA and LUSI stations have relatively large prediction deviations; the deviation is particularly prominent at the NANSHA station because this station has less data and because the model has limited data to learn during training. Due to insufficient learning, the prediction accuracy is low.

Prediction charts of various models. (a) DALIAN station, (b) KANMEN station, (c) LUSI station, (d) NANSHA station, (e) XISHA station and (f) ZHAPO station.
As shown in Fig. 6, the scatter plot predicted by the five models on the test dataset of the six tide stations clearly reveals that most of the data points predicted by the SCSSA-CNN-BiLSTM model are concentrated near the fitting oblique line, and the best results are obtained, which are followed by those obtained by the CNN-BiLSTM model. Some values predicted by the BiLSTM model, LSTM model and CNN model differ greatly from the real values, and obvious differences are shown for the NANSHA station and XISHA station. In general, the five models are more fully trained and have more accurate prediction results at stations with more data, while the prediction results are more biased at stations with less data, which is consistent with the results shown in Fig. 9.

Scatter plots of the various models. (a) DALIAN station, (b) KANMEN station, (c) LUSI station, (d) NANSHA station, (e) XISHA station and (f) ZHAPO station.
Model prediction performance indicator analysis
The predicted performance indicators of the five models used are shown in Table 6. Specifically, there are relatively small gaps between the CNN model and LSTM model indicators at the DALIAN station, LUSI station, XISHA station and ZHAPO station, however, the accuracy is slightly lower at these stations. The prediction accuracy of the CNN model at the NANSHA station is relatively low. The BiLSTM model is better than the previous two indicators, however, the predicted values of these three models are biased relative to the real values. The prediction performance index of the CNN-BiLSTM model is better than that of the first three models, which shows that the prediction ability of the combined model improved substantially. The SCSSA-CNN-BiLSTM model has the strongest prediction ability among the five models; all the indicators are greatly improved based on the CNN-BiLSTM model, and the prediction error is relatively low.
Conclusions
In this paper, a combined prediction model named SCSSA-CNN-BiLSTM is proposed with the use of the sparrow search algorithm, and it combines sine–cosine and a Cauchy variation to optimize the parameters of the CNN-BiLSTM model. Based on the monthly sea level time series of seven tide stations and five kinds of neural network models, a prediction experiment was constructed for a comparative analysis. By comparing the prediction performance of the SCSSA-CNN-BiLSTM model with that of the other models (LSTM, CNN, BiLSTM and CNN-BiLSTM) through a variety of comparison graphs and error evaluation indicators, the following conclusions can be drawn:
-
(1)
The quantity, regularity and stationarity of data used are crucial for neural network training, and the prediction performance maybe moderate for the stations with less available data, such as LUSI, NANSHA and XISHA stations. The predicted waveform of the DALIAN station is more consistent with the real value than that of the ZHAPO station, due to the more regular and stable data series of DALIAN station.
-
(2)
The BiLSTM model is equipped with a reverse LSTM network, and there is a forward and reverse bidirectional network, which enables the model to better understand and model the contextual information in the series, which is highly helpful for improving the time series prediction capabilities. Therefore, the performance of this model is better than that of the LSTM model. For the DALIAN station, the BiLSTM model improved the RMSE, MAE, MAPE and R2 by 2.42%, 4.64%, 4.37% and 0.74%, respectively, with respect to the LSTM model. Especially for tide stations with less data, the advantages of the BiLSTM model are more prominent because of the use of the reverse LSTM network; for example, at the NANSHA station, the BiLSTM model improved by 4.16%, 11.34%, 11.28% and 16.94% compared to the LSTM model on the four evaluation indices, respectively. Moreover, it is a good method for time series prediction.
-
(3)
The CNN-BiLSTM model is a combination of CNN and BiLSTM that combines the ability to extract features from the CNN model and the strong learning ability of the BiLSTM model. Based on the sea level time series prediction experiments at each tide station, the CNN-BiLSTM model yields a higher prediction accuracy and better evaluation indices. The CNN-BiLSTM model is superior to the CNN model and the BiLSTM model in terms of four evaluation indices at all the stations. Compared with those of the BiLSTM model, for the four evaluation indices of RMSE, MAE, MAPE and R2, the CNN-BiLSTM model can achieve maximum improvements of 45.52%, 62.99%, 63.56% and 84.23%, respectively. This shows that the CNN and BiLSTM combination model has a better prediction performance than their single models.
-
(4)
Compared with the traditional empirical method and trial and error method used to determine model parameters, the CNN-BiLSTM model, optimized by the SCSSA algorithm, can obtain more reasonable parameter values, which greatly improves the ability of the model to predict time series. With respect to the data prediction at each site, the SCSSA-CNN-BiLSTM model is far better than the other models in terms of both sequence fit and performance evaluation indicators, which effectively indicates the powerful prediction performance and high robustness of the SCSSA-CNN-BiLSTM model and provides a new way of thinking about time series prediction research.
Although the SCSSA-CNN-BiLSTM model proposed in this paper achieves excellent prediction performances in experiments, it still has limitations. For example, the combination of the SCSSA algorithm maybe more time-consuming due to the increasing model complexity. Many factors affect sea level rise, such as the sea water temperature, salinity and glacial ablation. An artificial neural network model is more effective for large-scale data and systems with complex structures; the larger the amount of data and the more types of data there are, the more accurate the prediction will be. However, in this paper, only a single time series is used for prediction, and the amount of data is small. Moreover, the article does not cover predictions of the future part of the time series; and the optimization effect of the SCSSA optimization algorithm can be compared with that of other optimization algorithms. These aspects also need further research in the future.
Data availability
The tide gauge datasets used in this research are freely available at https://www.psmsl.org/data/obtaining/.
References
Church, J. A. et al. Revisiting the Earth's sea‐level and energy budgets from 1961 to 2008. Geophysical Research Letters 38 (2011).
Röske, F. Sea level forecasts using neural networks. Dtsch. Hydrograph. Z. 49, 71–99 (1997).
Makarynskyy, O., Makarynska, D., Kuhn, M. & Featherstone, W. Predicting sea level variations with artificial neural networks at Hillarys Boat Harbour, Western Australia. Estuar. Coast. Shelf Sci. 61, 351–360 (2004).
Huang, W., Murray, C., Kraus, N. & Rosati, J. Development of a regional neural network for coastal water level predictions. Ocean Eng. 30, 2275–2295 (2003).
Karimi, S., Kisi, O., Shiri, J. & Makarynskyy, O. Neuro-fuzzy and neural network techniques for forecasting sea level in Darwin Harbor, Australia. Comput. Geosci. 52, 50–59 (2013).
Muslim, T. O. et al. Investigating the influence of meteorological parameters on the accuracy of sea-level prediction models in Sabah, Malaysia. Sustainability 12, 1193 (2020).
Guillou, N. & Chapalain, G. Machine learning methods applied to sea level predictions in the upper part of a tidal estuary. Oceanologia 63, 531–544 (2021).
Makarynska, D. & Makarynskyy, O. Predicting sea-level variations at the Cocos (Keeling) Islands with artificial neural networks. Comput. Geosci. 34, 1910–1917 (2008).
Nieves, V., Radin, C. & Camps-Valls, G. Predicting regional coastal sea level changes with machine learning. Sci. Rep. 11, 7650 (2021).
De Oliveira, M. M. et al. Neural network model to predict a storm surge. J. Appl. Meteorol. Climatol. 48, 143–155 (2009).
Lee, T.-L. Neural network prediction of a storm surge. Ocean Eng. 33, 483–494 (2006).
Sztobryn, M. Forecast of storm surge by means of artificial neural network. J. Sea Res. 49, 317–322 (2003).
Sertel, E., Cigizoglu, H. & Sanli, D. Estimating daily mean sea level heights using artificial neural networks. J. Coast. Res. 24, 727–734 (2008).
Aguilar-Martinez, S. & Hsieh, W. W. Forecasts of tropical Pacific sea surface temperatures by neural networks and support vector regression. Int. J. Oceanogr., 2009 (2009).
Wu, A., Hsieh, W. W. & Tang, B. Neural network forecasts of the tropical Pacific sea surface temperatures. Neural Netw. 19, 145–154 (2006).
Sithara, S., Pramada, S. & Thampi, S. G. Sea level prediction using climatic variables: A comparative study of SVM and hybrid wavelet SVM approaches. Acta Geophys. 68, 1779–1790 (2020).
Wang, B., Wang, B., Wu, W., Xi, C. & Wang, J. Sea-water-level prediction via combined wavelet decomposition, neuro-fuzzy and neural networks using SLA and wind information. Acta Oceanol. Sin. 39, 157–167 (2020).
Lee, T.-L., Makarynskyy, O. & Shao, C.-C. A combined harmonic analysis–artificial neural network methodology for tidal predictions. J. Coast. Res. 23, 764–770 (2007).
Han, Y., Sun, K., Yan, J. & Dong, C. The CNN-GRU model with frequency analysis module for sea surface temperature prediction. Soft Comput. 27, 8711–8720 (2023).
Qiao, B., Wu, Z., Tang, Z. & Wu, G. In 2022 24th International Conference on Advanced Communication Technology (ICACT). 342–347 (IEEE).
Wang, B. et al. Multi-step ahead short-term predictions of storm surge level using CNN and LSTM network. Acta Oceanol. Sin. 40, 104–118 (2021).
Alvarez, A., Orfila, A. & Tintoré, J. Real-time forecasting at weekly timescales of the SST and SLA of the Ligurian Sea with a satellite-based ocean forecasting (SOFT) system. J. Geophys. Res. Oceans https://doi.org/10.1029/2003JC001929 (2004).
You, S. H., Lee, Y. H. & Lee, W. J. Parameterization and application of storm surge/tide modeling using a genetic algorithm for typhoon periods. Adv. Atmos. Sci. 28, 1067–1076 (2011).
Wang, H., Yin, J. & Wang, X. In 2020 Chinese Control And Decision Conference (CCDC). 4862–4867 (IEEE).
Cheng, C.-T., Wang, W.-C., Xu, D.-M. & Chau, K. W. Optimizing hydropower reservoir operation using hybrid genetic algorithm and chaos. Water Resour. Manag. 22, 895–909 (2008).
Wang, W.-C., Cheng, C.-T., Chau, K.-W. & Xu, D.-M. Calibration of Xinanjiang model parameters using hybrid genetic algorithm based fuzzy optimal model. J. Hydroinform. 14, 784–799 (2012).
das Chagas Moura, M., Lins, I. D., Veleda, D., Droguett, E. L. & Araújo, M. In 10th International Probabilistic Safety Assessment & Management Conference.
Kayarvizhy, N., Kanmani, S. & Uthariaraj, R. Improving Fault prediction using ANN-PSO in object oriented systems. Int. J. Comput. Appl. 73, 0975–8887 (2013).
Chen, X., Chau, K.-W. & Busari, A. A comparative study of population-based optimization algorithms for downstream river flow forecasting by a hybrid neural network model. Eng. Appl. Artif. Intell. 46, 258–268 (2015).
Gandomi, A. H., Yang, X.-S. & Alavi, A. H. Cuckoo search algorithm: A metaheuristic approach to solve structural optimization problems. Eng. Comput. 29, 17–35 (2013).
Kaveh, A. & Talatahari, S. Optimum design of skeletal structures using imperialist competitive algorithm. Comput. Struct. 88, 1220–1229 (2010).
Alizadeh, M., Shabani, A. & Kavianpour, M. Predicting longitudinal dispersion coefficient using ANN with metaheuristic training algorithms. Int. J. Environ. Sci. Technol. 14, 2399–2410 (2017).
Chen, Y. et al. Stock price forecast based on CNN-BiLSTM-ECA Model. Sci. Program. 2021, 1–20 (2021).
Choi, Y. R. & Kil, R. M. Face video retrieval based on the deep CNN with RBF loss. IEEE Trans. Image Process. 30, 1015–1029 (2020).
Cheng, N., Chen, D., Lou, B., Fu, J. & Wang, H. A biosensing method for the direct serological detection of liver diseases by integrating a SERS-based sensor and a CNN classifier. Biosens. Bioelectron. 186, 113246 (2021).
Lin, Z., Ji, Y. & Sun, X. Landslide displacement prediction based on CEEMDAN method and CNN–BiLSTM model. Sustainability 15, 10071 (2023).
Xue, J. & Shen, B. A novel swarm intelligence optimization approach: Sparrow search algorithm. Syst. Sci. Control Eng. 8, 22–34 (2020).
Mirjalili, S. SCA: A sine cosine algorithm for solving optimization problems. Knowl. Based Syst. 96, 120–133 (2016).
Acknowledgements
We are grateful to the Permanent Service for Mean Sea Level (PSMSL) for providing tide gauge datasets. We are grateful for the helpful corrections and suggestions of the reviewers.
Funding
This research was funded by the National Natural Science Foundation of China (42064001, 42374017) and the Nanchang Key Laboratory (2021-NCZDSY-007).
Author information
Authors and Affiliations
Contributions
X.L.: Methodology, Investigation, Validation, Writing-original draft. S.Z.: Conceptualization, Methodology, Supervision, Writing-review & editing. F.W.: Formal analysis, Writing-review & editing. L.F.: Formal analysis, Writing-review. All the authors contributed to the article and approved the submitted version.
Corresponding author
Ethics declarations
Competing interests
The authors declare no competing interests.
Additional information
Publisher's note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Li, X., Zhou, S., Wang, F. et al. An improved sparrow search algorithm and CNN-BiLSTM neural network for predicting sea level height. Sci Rep 14, 4560 (2024). https://doi.org/10.1038/s41598-024-55266-4
Received:
Accepted:
Published:
DOI: https://doi.org/10.1038/s41598-024-55266-4
Comments
By submitting a comment you agree to abide by our Terms and Community Guidelines. If you find something abusive or that does not comply with our terms or guidelines please flag it as inappropriate.
