
Abstract
Landslides, recognized as a significant global natural disaster, necessitate an exploration of the impact of various resolution types in sampling strategies on Landslide Susceptibility Mapping (LSM) results. This study focuses on the segment from Zigui to Badong within the Three Gorges Reservoir Area, utilizing two resolution types: sampling resolution and spatial resolution, The Support Vector Machine (SVM) is employed to obtain LSM results, which are then analyzed using Receiver Operating Characteristic (ROC) curve, specific category accuracy and statistical methods. Artificial Neural Network (ANN) and Convolutional Neural Network (CNN) were used to verify the reliability of the results. Additionally, five common machine learning models, including Logistic Regression (LR), are used to conduct experiments on four sampling resolutions (10 m,30 m,50 m and 70 m) to further investigate the effect of sampling resolution on LSM results. These are evaluated using a comprehensive quantitative method. The results reveal that increasing spatial resolution improves the prediction accuracy, while increasing sampling resolution produces a contrary effect. Furthermore, the impact of spatial resolution on LSM results is more pronounced than that of sampling resolution. Finally, Fanjiaping landslide and Huangtupo landslide are selected as references for comparative analysis, with the results aligning with engineering reality.
Similar content being viewed by others


Introduction
A landslide is the process in which a hillside body composed of rock, soil, or debris accumulations is subjected to the combined effects of groundwater activity, seismic activity, or artificial slope-cutting, and under the action of gravity, an overall downward slide occurs along a certain soft and weak surface1. As one of the most frequent types of geological hazards, landslides result in significant losses to human life, the economy, and other areas annually. The occurrence of landslides is influenced by numerous factors, including landform, geology, soil composition, weather conditions, and land use2. Due to their wide distribution, high frequent, destructive nature, and rapid development, landslides present unique characteristics. They can also trigger secondary disasters such as river blockages, leading to floods and mudslides, further intensifying the damage3. Consequently, landslides, as significant geological events, have profound implications for human survival and development4.
Advancement in Geographic Information System (GIS) and earth observation technology have made Remote Sensing (RS) and GIS essential in modeling natural disaster susceptibility5. Landslide Susceptibility Mapping (LSM) is a commonly employed approach for predicting the spatial distribution and probability of landslides. LSM outcomes are crucial for reducing landslide disaster risks and for efficient land resource allocation6. In LSM modeling, the sampling strategy significantly affects the results. Several studies have validated this impact. Liu et al. proposed a frequency-ratio based LSM sampling strategy, showing superior performance over conventional methods7. Tekin et al. assessed the effects of two landslide sampling techniques on LSM, finding that selecting landslide-affected pixels from the entire landslide polygon yields higher prediction accuracy than selecting a similar proportion of pixels from any part of the landslide body8. Dagdelenler et al. re-evaluated seed cell sampling strategies, presenting the effects of two different sampling strategies (landslide zones and seed cells) on LSM and comparing the susceptibility maps derived from these strategies9. Hussin et al. summarized four common landslide sample extraction strategies: (1) using the center-of-mass method for individual pixel sampling; (2) extracting all pixels within the entire landslide body; (3) selecting pixel points in and around the landslide crown line using the main scarp upper edge method; (4) the seed-cell approach10. However, these strategies focus solely on various landslide sampling methods, and only a small amount of literature has considered the consistency of non-landslide and landslide sampling methods11,12.
Different resolutions of samples serve as a global sampling strategy, applying the same method for both landslides and non-landslides. Sample resolution includes spatial and sampling resolution. Regarding spatial resolution, the prediction accuracy of landslide susceptibility heavily relies on the quality of input data, primarily derived from Digital Elevation Models (DEM)13. Therefore, selecting the appropriate DEM spatial resolution is a crucial step in LSM research14. Schlögel et al. conducted LSM in the Ubaye Valley of the southern French Alps using three different resolutions (5 m, 10 m, and 25 m) for slope units, with their findings favoring a 10 m resolution15. Meena et al. evaluated LSM in the Kulu Valley of the Himalayan Mountains using three different spatial resolutions (12.5 m, 30 m, and 90 m), highlighting the highest accuracy at a 30 m resolution16. Chen et al. assessed the impact of seven spatial resolutions ranging from 30 to 90 m on LSM prediction and identified the highest accuracy at a 70 m resolution. Their study concluded that a finer resolution did not necessarily yield superior accuracy in LSM prediction14. However, studies regarding the potential impact of sampling resolution on LSM have not been reported in the literature. Based on the available literature, it can be concluded that the effect of spatial resolution on LSM has no obvious regularity in different study areas and spatial resolution. Additionally, there is a notable gap in research concerning the influence of sampling resolution on LSM, so there is no unified standard for the potential effect of different resolutions on LSM.
This article takes focuses on Zigui to Badong section of in the Three Gorges Reservoir Area to investigates the influence of different sampling resolutions (10 m, 16 m, and 30 m) and spatial resolutions (10 m, 16 m, and 30 m) on LSM outcomes. Nine LSM factors, including elevation, slope, aspect, curvature, lithology, distance to faults, Topographic Wetness Index (TWI), Normalized Difference Vegetation Index (NDVI), and multi-year average rainfall. The experiment on sampling resolution selected LSM factors using a 16 m × 16 m and 30 m × 30 m window based on a fixed LSM factor resolution of 10 m. To correspond with the selected sampling resolution, the experiment on spatial resolution used corresponding DEM (10 m, 16 m, and 30 m) and remote sensing images [Sentinel-2 (10 m), GF-1 (16 m), and Landsat-8 (30 m)] to obtain the LSM factors. For the experiment, all the grid points in the study area were used as the whole sample, the grid points in 70% of the landslide surface and an equivalent number of non-landslide grid points were randomly selected to construct the training set, while the grid points in the remaining 30% of the landslide surface serves as a validation set. The support vector machine (SVM) is used to derive LSM results at different sampling and spatial resolutions, evaluated using the Receiver Operating Characteristic (ROC) curve, specific category accuracy and statistical methods. To ensure the reliability of the experimental findings, both artificial neural network (ANN) and convolutional neural network (CNN) are employed, and a comprehensive quantitative scoring method evaluates the LSM results of the three models. In order to further explore the impact of sampling resolution on LSM results, five common machine learning models, including logistic regression (LR), were used to conduct experiments on different sampling resolutions (10 m, 30 m, 50 m, and 70 m), which consistently support the conclusions the previous experiment. Fanjiaping and Huangtupo landslides are selected for comparative analysis and verification, with results aligning with engineering reality. This comprehensive investigation of optimal sampling and spatial resolutions aims to enhance the scientific precision and accuracy of LSM, offering significant theoretical and practical value.
The flow chart of this article is shown in Fig. 1.

Experimental flow chart.
Study area and data sources
Study area
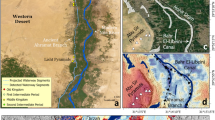
The study area, situated in the Zigui to Badong section, represents the first area of the Three Gorges Reservoir of the Yangtze River, spans 55 km in length and covers an area of 388 square kilometers, situated at 100°18′–110°52′ east longitude and 30°01′–30°56′ north latitude. A schematic diagram of the study area is provided in Fig. 2. Located within the mid-latitude subtropical monsoon climate zone, the area’s climatic elements are influenced by local topography and elevation variations. exhibiting notable spatial and temporal distribution variations significant microclimate characteristics17. Geological hazards primarily include landslides, collapses, and bank collapses, with landslides being particularly frequent, causing substantial human casualties and economic losses. Typical landslides in the area include Fanjiaping, Zhaoshuling, Xintan, Baishuihe, among others18.

(a) Schematic map of the Three Gorges reservoir area. (b) Schematic map of the study area crossing boundaries. (c) Schematic map of the elevation of the study area.
Data
Raw data
The main data used in this article and their applications are detailed in Table 1. The 1:50,000 scale geological map19 and the 1:10,000 scale landslide hazard map20 can meet the precision requirements of 10 m resolution, and can match the highest precision DEM data and remote sensing image data in this article. The landslide hazard database includes information about the occurrence time, type, and impact of some landslides in the study area. The rainfall data, derived from interpolation at each rainfall monitoring station, which only has time resolution but not spatial resolution, so the annual average rainfall for many years is used to eliminate the influence of time factors. It should be noted that, for consistency in resolution and facilitating a comprehensive analysis of the impact of spatial resolution and sampling resolution on LSM results, the 16 m DEM data utilized in this study were obtained by resampling the global 12.5 m DEM data provided by the ALOS satellite.
Factor resolution processing
The factorial resolutions are treated as follows (with ① and ④ being the same experimental data):
-
① 10 m sampling resolution (SA-10): the basic LSM factors resolution is 10 m, achieved by employing a 10 m DEM and Sentinel-2 (10 m) remote sensing images to obtain the LSM factors at the corresponding sampling resolution.
-
② 16 m sampling resolution (SA-16): on the basis of the same LSM factors resolution (10 m), the LSM factors are selected using a 16 m × 16 m window.
-
③ 30 m sampling resolution (SA-30): on the basis of the same LSM factors resolution (10 m), the LSM factors are selected using a 30 m × 30 m window.
-
④ 10 m spatial resolution (SP-10): the basic LSM factors resolution is 10 m, achieved by employing a 10 m DEM and Sentinel-2 (10 m) remote sensing images to obtain the LSM factors at the corresponding spatial resolution.
-
⑤ 16 m spatial resolution (SP-16): the LSM factors are resolved at a spatial resolution of 16 m, obtained through resampling a 12.5 m DEM to a 16 m DEM and GF-1 (16 m) remote sensing images to obtain the LSM factors at the corresponding spatial resolution.
-
⑥ 30 m spatial resolution (SP-30): the LSM factors are resolved at a spatial resolution of 30 m, achieved by employing a 30 m DEM and Landsat-8 (30 m) remote sensing images to obtain the LSM factors at the corresponding spatial resolution.
Factor data
Based on the literature review, nine commonly used base factors are selected for this study: elevation, slope, aspect, curvature, lithology, distance to faults, TWI, NDVI, and multi-year average rainfall6,21,22. To avoid correlation and multicollinearity among these factors, diagnostic methods like Pearson Correlation Coefficient23, Variance Inflation Factor and Tolerance24, and Relief-F algorithms25 are employed. The final diagnosed landslide evaluation factors are shown in Fig. 3, with related information presented in Table 2.

LSM factors in the study area: (a) elevation, (b) aspect, (c) slope, (d) curvature, (e) distance from faults, (f) lithology, (g) TWI, (h) NDVI, (i) rainfall.
Software
The software used in this article includes ArcGIS 10.8, ENVI 5.3, IBM SPSS Statistics 26, IBM SPSS Modeler 18, and PyTorch 1.7.1. The sources and uses are shown in Table 3.
Experimental models and methods
Models
SVM model
SVM, initially proposed by Vapnik26, is a supervised learning method utilized for classification, regression, and anomaly detection27. Known for its high prediction accuracy and performance, SVM is considered a classic nonlinear prediction model for evaluation28. Assuming a linearly separable training vector xi (i = 1, 2, …, n) belonging to two different classes yi = ± 1, SVM can find an n-dimensional hyperplane in the data space using a kernel function, so that the margin \({{\parallel w\parallel } \mathord{\left/ {\vphantom {{\parallel w\parallel } 2}} \right. \kern-0pt} 2}\) between the classification boundary and the nearest data point is the largest, thereby clearly distinguishing between landslide and non-landslide categories29. This hyperplane is represented by formulas (1) and (2).
where \(\parallel w\parallel\) is the normal vector norm of the hyperplane, b is a scalar, xi is a point on the hyperplane, and w is a vector perpendicular to the hyperplane.
Commonly employed kernel functions include linear, polynomial, Radial Basis Function (RBF), and Sigmoid. Among these, RBF demonstrates superior performance with fewer parameters and greater flexibility30. Therefore, this study adopts an RBF kernel-based SVM approach for LSM.
The schematic map of the SVM model is shown in Fig. 4.

Schematic map of the SVM model.
ANN model
ANN is a nonlinear computational model that mimics the human nervous system for information acquisition, processing, representation, and calculation31. The ANN model offers several advantages: (a) strong generalization ability, (b) robust self-learning capability and adaptability, (c) excellent nonlinear mapping capability, (d) high fault tolerance and good fitting performance28. Typically, the ANN model consists of three interconnected layer types: input layer, hidden layer, and output layer29, as shown in Fig. 5. In this article, the input layer represents the LSM factors, the hidden layer encompasses the neurons utilized, and the output layer signifies the predicted likehood of landslide occurrence along with the calculation of its probability value.

Schematic map of the ANN model.
CNN model
The deep learning algorithm CNN, introduced by LeCun et al.32, is an enhanced approach based on ANN, where artificial neurons respond to surrounding elements to extract information33. A typical CNN model includes five essential components: the input layer, convolutional layer, pooling layer, fully connected layer, and output layer2, as shown in Fig. 6. The convolutional layer, central to CNN, consists of multiple convolutional kernels that linearly map the input data to extract finer feature information. The adoption of a shared weight strategy in the convolutional layer allows the entire network to be trained with fewer parameters compared to a fully connected network34. The pooling layer crucial in CNN, performs downsampling operations through various nonlinear functions to reduce feature size, retain essential details, and mitigate overfitting with different data35. The fully connected layer acts as a “classifier” within the convolutional neural network, with its input comprising high-dimensional features extracted after the operations of the convolutional and pooling layers36. The parameters of CNN used in this article are shown in Table 4.

Schematic map of the CNN model.
Evaluation methods
ROC curve
ROC curve is widely employed for analyzing LSM results37,38,39. The ROC curve focuses on binary classification model, with four possible outcomes in prediction results: (1) True Positive (TP), (2) False Positive (FP), (3) True Negative (TN), (4) False Negative (FN). These results can be represented by a confusion matrix, as shown in Fig. 7.

Schematic map of the dichotomous model.
Where P is a positive example and N is a negative example40.
The ROC curve begins at the point (0, 0) and ends at (1, 1), plotting the true negative rate (TNR) represented on the horizontal axis and the true positive rate (TPR) depicted on the vertical axis41. This article evaluates LSM results at different sampling and spatial resolutions through ROC curves and AUC values.
Specific category precision analysis
The conventional approach for quantitative analysis in LSM relies on Landslide Susceptibility Zoning (LSZ) results, calculated by the ratio of landslide area in highly susceptible zones to total landslide area. The specific category precision analysis method, however, considers the number of calculation units within classified zones, thus addressing the issue of the model producing favorable results when a large portion of the LSZ falls within the extremely high-risk category. This method provides a more suitable approach for LSM results analysis42. As shown in formula (3).
where i = 1, 2, …, n, n is the number of landslide-prone zoning categories, Ai is the number of grid cells occupied by landslides in the i-th landslide-prone zoning category, Bi is the number of landslides in the i-th landslide-prone area category, and Pi is the specific category precision of the i-th landslide-prone area category.
Statistical methods
Statistical methods employed in this study include Overall accuracy (OA), Precision, Recall, F-measure, and Matthews correlation coefficient (MCC). As shown in formula (4)–(8)43.
where OA measures the ratio of correct predictions to total predictions. Precision and Recall values range between 0 and 1, with values closer to 1 indicating a higher proportion of correct predictions. In cases where Precision and Recall exhibit conflicting behavior, a commonly used approach is to consider their harmonized measure, the F-measure. MCC is essentially the correlation coefficient between actual and predicted binary classifications, yielding values ranging from −1 to + 1, where + 1 means perfect prediction, 0 means no better than random, and −1 means complete inconsistency between prediction and actual44.
Landslide susceptibility mapping
Create a training set and a validation set
The training set was composed of an equal proportion of landslide samples (strain value of 1) and non-landslide samples (strain value of 0)45, Furthermore, several scholars have investigated the impact of different sample ratios in the training dataset on the outcomes of LSM46. Considering various LSM models, this article opted to construct the training set using an equal proportion of landslide and non-landslide samples. Taking the spatial resolution of 10 m as an example, the study area contained 3,829,404 effective grid cells, with 202 landslide occurrences. To construct the training sample set, 70% of the landslide surface were randomly selected, resulting in 141 landslides (164,274 grid cells), along with an equal number of non-landslide data (164,274 grid cells). Consequently, the training set comprised a total of 328,548 grid cells. The remaining 30% of the landslide surface (61 landslides, 68,542 grid cells) were set aside for validation. As shown in Fig. 8.

Spatial distribution of training set and validation set.
LSM results
Landslide susceptibility index (LSI)
The training set constructed in "Create a training set and a validation set" was used for training the SVM model. Then, the entire set is utilized as input for the trained SVM model to generate the landslide susceptibility index (LSI) for the study area, as shown in Fig. 9.

LSI produced by: (a) SA-10, (b) SA-16, (c) SA-30, (d) SP-10, (e) SP-16, (f) SP-30.
Landslide susceptibility zoning (LSZ)
To enhance the comprehensibility of the LSM results and provide a more intuitive representation, a manual threshold method was employed to categorize the landslide susceptibility index (LSI) map shown in Fig. 9 into five distinct levels: Very Low (0–0.5), Low (0.5–0.75), Moderate (0.75–0.85), High (0.85–0.95), and Very High (0.95–1). This classification aimed to obtained LSZ with different sampling and spatial resolutions, as shown in Fig. 10.

LSZ produced by: (a) SA-10, (b) SA-16, (c) SA-30, (d) SP-10, (e) SP-16, (f) SP-30.
Experimental results
ROC curve and AUC value
The AUC corresponds to the region enclosed by the ROC curve and the X-axis. A larger AUC suggests higher precision47. Figure 11 and Table 5 show the ROC curves and AUC values from the SVM model at different sampling and spatial resolutions.

ROC curve.
According to Table 5, it is evident that among the sampling resolutions, the maximum AUC value of 0.871 is obtained for SA-10. Conversely, among the spatial resolutions, the highest AUC value of 0.913 is obtained for SP-30. Additionally, AUC values for spatial resolutions consistently higher than those for sampling resolutions.
Analysis results of specific category precision
Specific category precision based on SVM model’s experimental results at different sampling and spatial resolutions are shown in Table 6.
According to Table 6, the highest specific category precision in the “Very High” category for sampling resolutions was 39.14% for SA-10, while for spatial resolutions, it was 52.51% for SP-30. Additionally, spatial resolutions yielded consistently higher specific category precision in the “Very High” category than sampling resolutions.
Results of statistical methods
The calculation results for five statistical methods, including OA, Precision, Recall, F-measure, and MCC, are presented in Table 7.
According to Table 7, among the sampling resolutions, the 10 m resolution exhibits the highest values for OA (78.68%), Precision (0.1985), Recall (0.8257), F-measure (0.3201), and MCC (0.3767). Conversely, among the spatial resolutions, the 30 m resolution exhibits the highest values for OA (83.00%), Precision (0.2435), Recall (0.8636), F-measure (0.3798), and MCC (0.4286). Additionally, the statistical method values for spatial resolution consistently surpass those for the sampling resolution.
Analysis of results based on SVM for two resolutions
The results from the SVM model in Fig. 11 and Tables 5, 6 and 7 in "Experimental results" reveal that as the sampling resolution increases, the AUC value gradually decreases, the specific category precision for the “Very High” category decreases, and the performance metrics of the statistical methods (OA, Precision, Recall, F-measure, and MCC) also decline. Conversely, as the spatial resolution increases, the AUC value gradually increases, the specific category precision for the “Very High” category improves, and the performance metrics of the statistical methods also enhance. Furthermore, the AUC value, the specific category precision for the “Very High” category, and the performance metrics of the statistical methods are consistently favor spatial resolution over sampling resolution.
Reliability analysis of the conclusions
To ensure the reliability of the impact of different sampling and spatial resolutions on LSM results, both ANN and CNN models were employed for LSM analysis. These models were trained and validated using identical datasets to ensure that any variations in the LSM results were solely attributed to changes in the models. Furthermore, AUC value, specific category precision for the “Very High” category, and statistical methods were used to analyze the experimental results. The results, as shown in Tables 8, 9 and 10 in "Analysis of AUC values for two models", “Analysis of specific category precision for two models” and "Statistical methods analysis of ANN and CNN models".
Analysis of AUC values for two models
According to Table 8, it is evident that both the ANN and CNN models exhibit results that closely resemble those of the SVM model. Among the sampling resolutions, the highest AUC values were achieved at a 10 m resolution, with respective values of 0.880 and 0.857. Moreover, the AUC values obtained by the models gradually decrease as the sampling resolution increases. Concerning spatial resolution, the highest AUC values were achieved at a 30 m resolution, with respective values of 0.921 and 0.890. Furthermore, the AUC values obtained by the models gradually increase as the spatial resolution increases. Additionally, AUC values for spatial resolution consistently surpass those for sampling resolution.
Analysis of specific category precision for two models
According to Table 9, it is evident that both the ANN and CNN models exhibit results that closely resemble those of the SVM model. Among the sampling resolution, the specific category precision for the “Very High” category was achieved at a 10 m resolution, with respective values of values of 49.12% and 44.19%. Moreover, the specific category precision obtained by the models gradually decrease as the sampling resolution increases. Regarding spatial resolution, the specific category precision for the “Very High” category were achieved at a 30 m resolution, with respective values of 56.88% and 46.41%. Furthermore, the specific category precision obtained by the models gradually increase as the spatial resolution increases. Additionally, the specific category precision for the “Very High” category for spatial resolution are surpasses that in sampling resolution.
Statistical methods analysis of ANN and CNN models
According to Table 10, it is evident that both the ANN and CNN models exhibit results that are slightly differ from those of the SVM model. In the validation results of the ANN model, the highest OA (77.93%), Precision (0.1961), F-measure (0.3186), and MCC (0.3754) were achieved at a resolution of 10 m for sampling resolution, with only the Recall (0.8504) being highest at a resolution of 16 m. For spatial resolution, the highest OA (83.80%), Precision (0.2534), F-measure (0.3921), and MCC (0.4392) were achieved at a resolution of 30 m, with only the Recall (0.8678) being highest at a resolution of 16 m. In the validation results of the CNN model, the highest OA (80.33%), Precision (0.2184), Recall (0.8044), and F-measure (0.3101) were achieved at a resolution of 10 m for sampling resolution, only the MCC (0.3662) was highest at a resolution of 16 m. For spatial resolution, the highest OA (80.68%) and Recall (0.8382) were achieved at a resolution of 30 m, the highest Precision (0.2226), F-measure (0.3482), and MCC (0.3998) were achieved at a resolution of 16 m. Additionally, the OA, Precision, Recall, F-measure, and MCC values for spatial resolution exceed those for sampling resolution.
Quantitative analysis of LSM results
Given the inconsistent results among the SVM, ANN, and CNN models using statistical methods, a scoring method was employed to provide a comprehensive evaluation of the impact of different sampling and spatial resolutions on LSM. This method involved evaluating the AUC value of LSM results, the specific category precision for the “Very High” category, and statistical methods. The scoring principle is as follows: the AUC value, the specific category precision for the “Very High” category, and statistical methods obtained from experiments with different sampling and spatial resolutions are ranked from high to low and assigned scores ranging from 3 to 1, with 3 being the highest score and 1 the lowest. In the case of ties, the lower score is assigned. For statistical methods, the score is determined by averaging the scores obtained from the five methods: OA, Precision, Recall, F-measure, and MCC. A higher score in the quantitative analysis indicates a higher level of prediction accuracy24.The score tables are shown in Tables 11 and 12.
According to Tables 11 and 12, it can be observed that for sampling resolution, the highest integrated scores of AUC value, specific category precision for the "Very High" category, and the average value of statistical methods in the comprehensive quantitative evaluation results of the SVM, ANN, and CNN models were obtained at a sampling resolution of 10 m, with scores of 9, 8.6, and 8.6, respectively. Regarding spatial resolution, the highest integrated scores of AUC value, specific category precision for the “Very High” category, and the average value of statistical methods in the comprehensive quantitative evaluation results of the SVM, ANN, and CNN models were obtained at a spatial resolution of 30 m, with scores of 9, 8.8, and 8.2, respectively.
Based on comprehensive quantitative analysis, it has been observed that the prediction accuracy of LSM results decreases with an increase in sampling resolution, while it increases with an increase in spatial resolution. Moreover, the values of AUC, specific category precision for the “Very High” category, and statistical methods at the three different spatial resolutions are higher than those at the sampling resolution, indicating that the impact of spatial resolution on LSM results is greater than that of sampling resolution.
Further experiments on sampling resolution
Given the absence of relevant research on the effect of sampling resolution on LSM results, this study will further investigate the performance results of different sampling resolutions under various machine learning models to verify the impact of sampling resolution on LSM results. This study includes five widely employed machine learning models: SVM, ANN, LR, C5.0, and Bayes, to model different sampling resolutions (10 m, 30 m, 50 m, and 70 m). The LSM results will be evaluated using AUC values, specific category precision, and statistical methods. Furthermore, a comprehensive quantitative assessment will be conducted through the utilization of a scoring method. The results of AUC values and specific category precision are shown in Figs. 12 and 13, while Tables 13 and 14 provide the statistical methods and score tables.

AUC values.

Specific category precision “Very High”.
In response to the results of Figs. 12 and 13 and Table 13, a comprehensive quantitative assessment will be made using a scoring method, as shown in Table 14.
According to Table 14, the comprehensive quantitative evaluation results of SVM, ANN, LR, C5.0, and Bayes models indicate that, overall, AUC value, specific category precision for the “Very High” category, and statistical methods average, the highest comprehensive score of the three is 10 m sampling resolution, which are 12, 11.8, 11.8, 11.8, and 10.6, respectively, Moreover, the total score decreases as the sampling resolution increases, Based on the above results, it is demonstrated that the prediction accuracy of the LSM results decreases as the sampling resolution increases, consistent with the findings in "Reliability analysis of the conclusions"; thus, validating the effect of sampling resolution on the results of landslide susceptibility assessment.
Discussion
The LSZ map obtained from the SVM model at 30 m spatial resolution is chosen as an example for analysis. It is shown in Fig. 14.

LSZ chart for SA-30.
As can be seen from Fig. 14, there are 21 km2 of high susceptibility areas, accounting for 5.41% of the total area, and 12 km2 of very high susceptibility areas, accounting for 3.09% of the total area. In addition, the medium, high, and very high susceptibility subzones are mainly located along the river, and the low and very low susceptibility subzones are mainly located further away from the water system. Through field surveys, it is evident that landslides are primarily located in the medium, high, and very high susceptibility zones, accounting for 95.05% of the total. Similar conclusions were found in the LSM results at other resolutions, indicating that the experimental results obtained are consistent with the distribution of landslides and engineering experience in the study area.
In order to further validate the conclusions obtained in this article, Fanjiaping landslide and Huangtupo landslide were selected for comparative analysis and validation of the results. Their distribution is shown in Fig. 15.

Distribution of landslides. (The pictures of the Huangtupo landslide and the Fanjiaping landslide on the left are taken at the scene, Remote sensing imagery from publicly available Sentinel-2 satellite imagery; https://sentinel.esa.int/).
Combining the distribution of known landslide surfaces in the study area (Fig. 15) and the results of LSZ (Fig. 10), and selecting the Huangtuopo landslide and the Fanjiaping landslide as a reference to get Fig. 16.

Detailed map of the Huangtupo landslide and Fanjiaping landslide (satellite images from Google Earth Pro 7.3; https://www.google.com/intl/en/earth/).
In the case of the Huangtupo landslide, the northwest corner of SA-30 exhibits the highest prediction accuracy, and the degree of agreement of its prediction results gradually increases as the sampling resolution decreases. Regarding SP-30, it displays the highest agreement in prediction results, while the north and northwest corners of SP-16 have higher prediction accuracies, with the agreement of their prediction results gradually decreasing as the spatial resolution decreases. For the Fanjiaping landslide, higher prediction accuracies are observed in the northern, central, and northwestern corners of SA-30, with the degree of agreement of its prediction results increasing as the sampling resolution decreases. In the case of SP-30, it includes almost the entire landslide surface, and the degree of agreement gradually decreases with the decrease in spatial resolution. Moreover, the predictions at spatial resolutions tend to match more closely than those at their corresponding sampling resolutions.
The analysis of the experimental results in "Experimental results" and "Reliability analysis of the conclusions" has led to the conclusion that the highest prediction accuracy is achieved with a 10 m sampling resolution. Since there is no relevant study on the effect of sampling resolution on LSM results to corroborate these findings, this study further explores the impact of sampling resolution in "Further experiments on sampling resolution", which yields experimental results that align with the previous conclusions. This further validates the influence that sampling resolution has on LSM results. This influence may be attributed to the influence of the number of training sample points with 10 m sampling resolution is sufficiently large compared to the sampling resolutions of 16 m, 30 m, 50 m and 70 m, and a sufficient number of training sample points can construct a model that is more relevant to the actual situation. However, it is important to note that the difference in sampling resolution also affects the spatial correlation between sample points. When conducting statistical analyses of data with spatial attributes, it is necessary to consider the interdependence of training samples, and the spatial correlation between the samples should be reduced as much as possible48. Therefore, in future studies, it is important to explore a suitable sampling resolution that can reduce the spatial correlation between sample points while ensuring a sufficient number of training sample points for the analysis of LSM results.
The analysis of experimental results in "Experimental results" and "Reliability analysis of the conclusions" indicates that a 30 m spatial resolution yields the highest prediction accuracy. This finding diverges from several existing studies, possibly due to the influence of spatial resolution on landslides being contingent on the scale of landslides within the study area. Utilizing identical resolutions for both landslides and geo-environmental information may introduce potential biases49. For example, small grid cells adeptly capture morphological details of shallow landslides but are less effective for large, deep-seated landslides, whose features are more discernible at coarser resolutions50,51. The study also acknowledges certain limitations: (1) Landslides, as complex natural hazards, are influenced by various geological and environmental factors, complicating accurate modeling; (2) The quality of the DEM data; (3) The limited number of landslide references in the database. Consequently, further research on the optimal spatial resolution for predictive LSM modeling is warranted.
Conclusion
This article focuses on the section from Zigui to Badong in the Three Gorges Reservoir Area as the study area. The SVM model is employed to generate LSM results under various sampling and spatial resolutions. The obtained results are then evaluated and analyzed using ROC curves, specific category accuracy, and statistical methods. To ensure the reliability of the experimental findings, ANN and CNN models were also used for verification. Subsequently, a comprehensive quantitative scoring method is employed to assess the LSM results from obtained the three models. To verify the reliability of the sampling resolution results, five models of SVM, ANN, LR, C5.0 and Bayes were selected to model and discuss four different sampling resolutions (10 m, 30 m, 50 m and 70 m). The total score results indicate that the highest sampling resolution of 10 m yields the best prediction accuracy for LSM results. As the sampling resolution increases, the prediction accuracy of LSM results decreases, consistent with the experimental results obtained in "Reliability analysis of the conclusions". The results show that: firstly, the results of 10 m sampling resolution in SVM, ANN, and CNN models outperform those at 16 m and 30 m. As the sampling resolution increases, the accuracy of LSM result predictions decreases. Conversely, the results of 30 m spatial resolution in SVM, ANN, and CNN models are superior to those at 10 m and 16 m. Moreover, as the spatial resolution increases, the accuracy of LSM result predictions increases. Secondly, AUC values, specific category precision for the “Very High” category, and statistical methods results derived from the spatial resolution are superior to those obtained from the sampling resolution. This indicates that spatial resolution has a greater impact on the LSM results than sampling resolution. Finally, Fanjiaping landslide and Huangtupo landslide are selected as references for comparative analysis and verification of the results, and the results obtained are in line with the engineering reality.
This article provides systematic research on different sampling and spatial resolutions, which can provide a certain degree of reference for the selection of sampling resolution and spatial resolution of LSM factors when researchers carry out LSM. These findings contribute to improving the scientific accuracy and precision of LSM, holding significant theoretical and practical value for engineering applications.
Data availability
The data processing platform can be downloaded directly through the link provided in Table 3. However, basic geographic data, basic geological data, and landslide distribution data are all confidential data in China. According to the requirements of relevant laws, these confidential data have been decrypted when we use them. Any researchers in related fields that need these decrypted data can contact the corresponding author to obtain them.
References
Ado, M. et al. Landslide susceptibility mapping using machine learning: A literature survey. Remote Sens. https://doi.org/10.3390/rs14133029 (2022).
Yi, Y., Zhang, W., Xu, X., Zhang, Z. & Wu, X. Evaluation of neural network models for landslide susceptibility assessment. Int. J. Digit. Earth 15, 934–953. https://doi.org/10.1080/17538947.2022.2062467 (2022).
Sun, D. Mapping Landslide Susceptibility Based on Machine Learning and Forecast Warning of Landslide Induced by Rainfall (East China Normal University, 2019).
Zhuang, J. et al. Distribution and characteristics of landslide in Loess Plateau: A case study in Shaanxi province. Eng. Geol. 236, 89–96 (2018).
Thi Ngo, P. T. et al. Evaluation of deep learning algorithms for national scale landslide susceptibility mapping of Iran. Geosci. Front. 12, 505–519. https://doi.org/10.1016/j.gsf.2020.06.013 (2021).
Yong, C. et al. Review of landslide susceptibility assessment based on knowledge mapping. Stochastic Environ. Res. Risk Assess. 36, 2399–2417. https://doi.org/10.1007/s00477-021-02165-z (2022).
Liu, L.-L., Zhang, Y.-L., Xiao, T. & Yang, C. A frequency ratio-based sampling strategy for landslide susceptibility assessment. Bull. Eng. Geol. Environ. https://doi.org/10.1007/s10064-022-02836-3 (2022).
Tekin, S. & Çan, T. Effects of landslide sampling strategies on the prediction skill of landslide susceptibility modelings. J. Indian Soc. Remote Sens. 46, 1273–1283 (2018).
Dagdelenler, G., Nefeslioglu, H. A. & Gokceoglu, C. Modification of seed cell sampling strategy for landslide susceptibility mapping: An application from the Eastern part of the Gallipoli Peninsula (Canakkale, Turkey). Bull. Eng. Geol. Environ. 75, 575–590 (2016).
Hussin, H. Y. et al. Different landslide sampling strategies in a grid-based bi-variate statistical susceptibility model. Geomorphology 253, 508–523 (2016).
Zhu, A.-X. et al. A similarity-based approach to sampling absence data for landslide susceptibility mapping using data-driven methods. Catena 183, 104188 (2019).
Hong, H., Wang, D., Zhu, A.-X. & Wang, Y. Landslide susceptibility mapping based on the reliability of landslide and non-landslide data. Expert Syst. Appl. 3, 122933 (2023).
Dou, J. et al. Different sampling strategies for predicting landslide susceptibilities are deemed less consequential with deep learning. Sci. Total Environ. 720, 137320 (2020).
Chen, Z., Ye, F., Fu, W., Ke, Y. & Hong, H. The influence of DEM spatial resolution on landslide susceptibility mapping in the Baxie River basin, NW China. Nat. Hazards 101, 853–877. https://doi.org/10.1007/s11069-020-03899-9 (2020).
Schlögel, R. et al. Optimizing landslide susceptibility zonation: Effects of DEM spatial resolution and slope unit delineation on logistic regression models. Geomorphology 301, 10–20. https://doi.org/10.1016/j.geomorph.2017.10.018 (2018).
Meena, S. R. & GudiyangadaNachappa, T. Impact of spatial resolution of digital elevation model on landslide susceptibility mapping: A case study in Kullu Valley, Himalayas. Geosciences 9, 360 (2019).
Cheng, J. et al. Landslide susceptibility assessment model construction using typical machine learning for the Three Gorges Reservoir Area in China. Remote Sens. https://doi.org/10.3390/rs14092257 (2022).
Yu, X., Wang, Y., Niu, R. & Hu, Y. A combination of geographically weighted regression, particle swarm optimization and support vector machine for landslide susceptibility mapping: A case study at Wanzhou in the Three Gorges Area, China. Int. J. Environ. Res. Public Health 13, 487 (2016).
Survey, H. P. G (Hubei Province Geological Survey Press, 1997).
Reservoir HoPaCoG-HiAoTG, cartographer1:10,000 geological hazard mapping database. (2011).
Fan, H. et al. A landslide susceptibility evaluation of highway disasters based on the frequency ratio coupling model. Sustainability 14, 7740 (2022).
Ke, C., He, S. & Qin, Y. Comparison of natural breaks method and frequency ratio dividing attribute intervals for landslide susceptibility mapping. Bull. Eng. Geol. Environ. 82, 384 (2023).
Mao, Z., Shi, S., Li, H., Zhong, J. & Sun, J. Landslide susceptibility assessment using triangular fuzzy number-analytic hierarchy processing (TFN-AHP), contributing weight (CW) and random forest weighted frequency ratio (RF weighted FR) at the Pengyang county, Northwest China. Environ. Earth Sci. 81, 86 (2022).
Yu, X., Xia, Y., Zhou, J. & Jiang, W. Landslide susceptibility mapping based on multitemporal remote sensing image change detection and multiexponential band math. Sustainability 15, 2226 (2023).
Achour, Y. et al. Assessing landslide susceptibility using a machine learning-based approach to achieving land degradation neutrality. Environ. Earth Sci. 80, 1–20 (2021).
Cortes, C. & Vapnik, V. Support-vector networks. Mach. Learn. 20, 273–297 (1995).
Ullah, I. et al. An integrated approach of machine learning, remote sensing, and GIS data for the landslide susceptibility mapping. Land 11, 1265 (2022).
Li, Y. et al. Collapse susceptibility assessment using a support vector machine compared with back-propagation and radial basis function neural networks. Geomat. Nat. Hazards Risk 11, 510–534. https://doi.org/10.1080/19475705.2020.1734101 (2020).
Zhao, P., Masoumi, Z., Kalantari, M., Aflaki, M. & Mansourian, A. A GIS-based landslide susceptibility mapping and variable importance analysis using artificial intelligent training-based methods. Remote Sens. 14, 211 (2022).
Zhou, X., Wu, W., Qin, Y. & Fu, X. Geoinformation-based landslide susceptibility mapping in subtropical area. Sci. Rep. 11, 24325. https://doi.org/10.1038/s41598-021-03743-5 (2021).
Jacinth Jennifer, J. & Saravanan, S. Artificial neural network and sensitivity analysis in the landslide susceptibility mapping of Idukki district, India. Geocarto Int. 37, 5693–5715. https://doi.org/10.1080/10106049.2021.1923831 (2021).
LeCun, Y., Bottou, L., Bengio, Y. & Haffner, P. Gradient-based learning applied to document recognition. Proc. IEEE 86, 2278–2324 (1998).
Lin, Q. et al. National-scale data-driven rainfall induced landslide susceptibility mapping for China by accounting for incomplete landslide data. Geosci. Front. 12, 101248 (2021).
Hacıefendioğlu, K., Demir, G. & Başağa, H. B. Landslide detection using visualization techniques for deep convolutional neural network models. Nat. Hazards 109, 329–350 (2021).
Mohammadifar, A., Gholami, H. & Golzari, S. Assessment of the uncertainty and interpretability of deep learning models for mapping soil salinity using DeepQuantreg and game theory. Sci. Rep. 12, 15167. https://doi.org/10.1038/s41598-022-19357-4 (2022).
Yang, Z., Xu, C., Shao, X., Ma, S. & Li, L. Landslide susceptibility mapping based on CNN-3D algorithm with attention module embedded. Bull. Eng. Geol. Environ. 81, 412 (2022).
Feng, H., Miao, Z. & Hu, Q. Study on the uncertainty of machine learning model for earthquake-induced landslide susceptibility assessment. Remote Sens. 14, 2968 (2022).
Kulsoom, I. et al. SBAS-InSAR based validated landslide susceptibility mapping along the Karakoram Highway: A case study of Gilgit-Baltistan, Pakistan. Sci. Rep. 13, 3344. https://doi.org/10.1038/s41598-023-30009-z (2023).
Rabby, Y. W., Li, Y. & Hilafu, H. An objective absence data sampling method for landslide susceptibility mapping. Sci. Rep. 13, 1740. https://doi.org/10.1038/s41598-023-28991-5 (2023).
Vakhshoori, V. & Zare, M. Is the ROC curve a reliable tool to compare the validity of landslide susceptibility maps?. Geomat. Nat. Hazards Risk 9, 249–266 (2018).
Cantarino, I., Carrion, M. A., Goerlich, F. & Martinez Ibañez, V. A ROC analysis-based classification method for landslide susceptibility maps. Landslides 16, 265–282 (2019).
Yu, X., Zhang, K., Song, Y., Jiang, W. & Zhou, J. Study on landslide susceptibility mapping based on rock-soil characteristic factors. Sci. Rep. 11, 15476. https://doi.org/10.1038/s41598-021-94936-5 (2021).
Chen, W. et al. Spatial prediction of landslide susceptibility using data mining-based kernel logistic regression, naive Bayes and RBFNetwork models for the Long County area (China). Bull. Eng. Geol. Environ. 78, 247–266 (2019).
Yu, X., Xiong, T., Jiang, W. & Zhou, J. Comparative assessment of the efficacy of the five kinds of models in landslide susceptibility map for factor screening: A case study at Zigui-Badong in the Three Gorges Reservoir Area, China. Sustainability https://doi.org/10.3390/su15010800 (2023).
Dai, F. C. & Lee, C. F. Landslide characteristics and slope instability modeling using GIS, Lantau Island, Hong Kong. Geomorphology 42, 1–228 (2002).
Tang, L., Yu, X., Jiang, W. & Zhou, J. Comparative study on landslide susceptibility mapping based on unbalanced sample ratio. Sci. Rep. 13, 5823. https://doi.org/10.1038/s41598-023-33186-z (2023).
Bui, D. T., Tsangaratos, P., Nguyen, V.-T., Van Liem, N. & Trinh, P. T. Comparing the prediction performance of a Deep Learning Neural Network model with conventional machine learning models in landslide susceptibility assessment. Catena 188, 104426 (2020).
Cheng, W., Peng, L. & Niu, R. Landslide susceptibility assessment based on rough set theory: Taking Zigui County territory in Three Gorges Reservoir for example. J. Central South Univ. Nat. Sci. Ed. 8, 11 (2013).
Reichenbach, P., Rossi, M., Malamud, B. D., Mihir, M. & Guzzetti, F. A review of statistically-based landslide susceptibility models. Earth-Sci. Rev. 180, 60–91. https://doi.org/10.1016/j.earscirev.2018.03.001 (2018).
Passalacqua, P., Tarolli, P. & Foufoula-Georgiou, E. Testing space-scale methodologies for automatic geomorphic feature extraction from lidar in a complex mountainous landscape. Water Resour. Res. 46, 22 (2010).
Pike, R. J. The geometric signature: Quantifying landslide-terrain types from digital elevation models. Math. Geol. 20, 491–511 (1988).
Acknowledgements
We are grateful to the National Natural Science Foundation of China and Innovation Demonstration Base of Ecological Environment Geotechnical and Ecological Restoration of Rivers and Lakes. We are also grateful to the Headquarters of Prevention and Control of Geo-Hazards in the Area of the Tree Gorges Reservoir for providing data and material. We thank the anonymous reviewers for their constructive comments and suggestions on the manuscript. We also thank editorial employees for editing the manuscript.
Funding
This study was supported by the National Natural Science Foundation of China (No. 41807297) and Innovation Demonstration Base of Ecological Environment Geotechnical and Ecological Restoration of Rivers and Lakes (No. 2020EJB004).
Author information
Authors and Affiliations
Contributions
Writing—original draft preparation, X.Y., H.C.; writing—review and editing, X.Y. and H.C.; visualization, X.Y. and H.C.; conceptualization, X.Y. and H.C.; software, X.Y. and H.C.; validation, X.Y. and H.C.; formal analysis, X.Y. and H.C.; investigation, X.Y. and H.C.; resources, X.Y.; data curation, X.Y.; methodology, X.Y. and H.C.; supervision, X.Y.; project administration, X.Y.; funding acquisition, X.Y. All authors have read and agreed to the published version of the manuscript.
Corresponding author
Ethics declarations
Competing interests
The authors declare no competing interests.
Additional information
Publisher's note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Yu, X., Chen, H. Research on the influence of different sampling resolution and spatial resolution in sampling strategy on landslide susceptibility mapping results. Sci Rep 14, 1549 (2024). https://doi.org/10.1038/s41598-024-52145-w
Received:
Accepted:
Published:
DOI: https://doi.org/10.1038/s41598-024-52145-w
This article is cited by
-
Game-theoretic optimization of landslide susceptibility mapping: a comparative study between Bayesian-optimized basic neural network and new generation neural network models
Environmental Science and Pollution Research (2024)
Comments
By submitting a comment you agree to abide by our Terms and Community Guidelines. If you find something abusive or that does not comply with our terms or guidelines please flag it as inappropriate.
