
Abstract
Life expectancy is likely to be substantially reduced in patients undergoing chronic hemodialysis (CHD). However, machine learning (ML) may predict the risk factors of mortality in patients with CHD by analyzing the serum laboratory data from regular dialysis routine. This study aimed to establish the mortality prediction model of CHD patients by adopting two-stage ML algorithm-based prediction scheme, combined with importance of risk factors identified by different ML methods. This is a retrospective, observational cohort study. We included 800 patients undergoing CHD between December 2006 and December 2012 in Shin-Kong Wu Ho-Su Memorial Hospital. This study analyzed laboratory data including 44 indicators. We used five ML methods, namely, logistic regression (LGR), decision tree (DT), random forest (RF), gradient boosting (GB), and eXtreme gradient boosting (XGB), to develop a two-stage ML algorithm-based prediction scheme and evaluate the important factors that predict CHD mortality. LGR served as a bench method. Regarding the validation and testing datasets from 1- and 3-year mortality prediction model, the RF had better accuracy and area-under-curve results among the five different ML methods. The stepwise RF model, which incorporates the most important factors of CHD mortality risk based on the average rank from DT, RF, GB, and XGB, exhibited superior predictive performance compared to LGR in predicting mortality among CHD patients over both 1-year and 3-year periods. We had developed a two-stage ML algorithm-based prediction scheme by implementing the stepwise RF that demonstrated satisfactory performance in predicting mortality in patients with CHD over 1- and 3-year periods. The findings of this study can offer valuable information to nephrologists, enhancing patient-centered decision-making and increasing awareness about risky laboratory data, particularly for patients with a high short-term mortality risk.
Similar content being viewed by others

Introduction
Patients on hemodialysis (HD) had a significantly higher mortality rate than the general population1,2,3,4. The life expectancy of patients with chronic hemodialysis (CHD) can be affected by underlying conditions such as aging, anemia, C-reactive protein, hypoalbuminemia, phosphorus, previous cardiovascular event, and dialysis adequacy2,5,6,7,8,9,10. Temporary vascular catheter could also be an independent risk factor of mortality in patients with CHD6,11. Previous studies already reported some clinical factors associated with mortality risks in patients with CHD; however, patients with end-stage kidney disease present considerable heterogeneity in the disease pattern with broad comorbidities12,13. Thus, making a survival outcome prediction model via limited clinical indicators remains challenging.
Various approaches have been attempted to modify the mortality prediction models for patients with CHD. The systematic review of Panupong Hansrivijit et al. demonstrated the precision of factors in predicting mortality in patients with chronic kidney disease, including those undergoing HD and peritoneal dialysis14. Moreover, Chava L. Ramspek et al. conducted a systemic review and further meta-analysis of independent external validation studies to determine the most ideal predictive performance study13. Mikko Haapio et al. performed two developed prognostic models of newly entered mortality prediction for patients with chronic dialysis via logistic regression (LGR) with stepwise variable selection and showed some variables to establish a practical, fine-performing model; however, they may overestimate the mortality risk because of considerably the lower mortality rate observed in the newer cohort10.
Recently, artificial intelligence (AI) has become increasingly popular in the field of patient survival/mortality analysis. Patients with CHD can provide robust serum laboratory data during HD treatments, considering that physicians commonly use them to monitor patients' condition. Machine learning (ML), a branch of AI that imitates human intelligence by incorporating and analyzing available data, is widely utilized in this context15,16,17. It has a unique potential for predicting survival outcomes and identifying mortality risk factors in patients with CHD. Powerful prediction models for patients with CHD have been developed using ML methods such as LGR, random forest (RF), and eXtreme gradient boosting (XGB). The research field encompasses diverse areas, including dialysis adequacy predictions18, survival prognostic prediction19,20,21, and time-dependent adverse event prediction22.
Identifying mortality risk factors in patients with CHD may facilitate early intervention and improve outcomes. Given that various ML techniques are still undergoing development and competition23, relying on a single approach may not consistently outperform others in all conditions. Therefore, the performance and accuracy of these techniques should be evaluated comprehensively. Hence, this study aimed to investigate the importance of risk factors identified using multiple ML methods. We also sought to establish a two-stage ML algorithm-based prediction scheme by comparing the accuracy and consistency of different ML methods to determine the most suitable model and identify common risk factors among patients with CHD who experienced mortality events in different years.
Methods
Study design and population
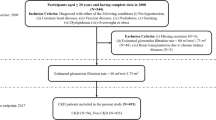
This retrospective observational cohort included 805 patients who received HD at Shin-Kong Wu Ho-Su Memorial Hospital between December 2006 and December 2012. The primary objective of creating this cohort was to assess the impact of reducing intra-dialysis phosphorus on mortality in patients with CHD was evaluated24. This cohort excluded the following criteria: (1) a history of hospitalization for acute events, including cardiovascular, cerebrovascular, and infectious diseases; (2) newly active diseases within 3 months before the data collection; and (3) missing information. After completing the essential data preprocessing steps before applying machine learning (ML) methods in the present study, a total of 800 patients were selected, as they had complete and relevant data required for further analysis. These patients were deemed suitable for inclusion in the study, ensuring a comprehensive dataset for subsequent ML modeling and analysis.
This study conformed to the principles of the Declaration of Helsinki, with approval by the Ethics Committee of the Shin-Kong Wu Ho-Su Memorial Hospital (protocol No.: 20220112R). Given that our study was based on medical records and data review, informed consent was relinquished by the Ethics Committee of the Shin-Kong Wu Ho-Su Memorial Hospital. Furthermore, patient information was anonymized and de-identified before the analysis.
Data collection
This study included 44 variables, such as demographic, biochemical laboratory data, and underlying comorbidities with disease and drugs (e.g., diabetic mellitus, hypertension, cardiovascular disease (CVD), chronic obstructive pulmonary disease, renin–angiotensin–aldosterone system blocker, antiplatelet drug, statin, and beta-blocker). We incorporated all these factors into our analysis because of their critical relevance and strong association to clinical outcomes in CHD patients. Additionally, these parameters were easily obtainable in clinical practice.
In this study, CVD was characterized as a composite of various conditions significantly affecting the mortality of CHD patients. These encompass coronary artery diseases, heart failure, hypertensive heart disease, arrhythmias, valvular heart disease, peripheral artery disease, and thromboembolic disease. Within our clinical practice, routine follow-ups for CHD patients encompassed serum biochemical laboratory assessments, including dialysis quality, electrolyte levels, hemogram, nutritional status, iron profile, lipid profile, and parathyroid function.
The biochemical laboratory data in our study included urea kinetics (Kt/V), urea reduction ratio (URR), blood urea nitrogen (BUN, mg/dL) from pre- and post-HD, creatinine (Cr, mg/dL) from pre- and post-HD, sodium (Na, mEq/L) from pre- and post-HD, potassium (K, mEq/L) from pre- and post-HD, ionized calcium (iCa, mEq/L), phosphate from pre- and post-HD (P, mg/dL), intact parathyroid hormone (iPTH, pg/mL), alkaline phosphatase (IU/L), aspartate aminotransferase (AST, U/L), alanine transaminase (ALT, U/L), total bilirubin (mg/dL), aluminum (ng/mL), uric acid (mg/dL), albumin (g/dL), triglyceride (mg/dL), total cholesterol (mg/dL), high-density lipoprotein (mg/dL), low-density lipoprotein (LDL, mg/dL), hemoglobin (g/dL), hematocrit (%), mean corpuscular volume (MCV, fL), ferritin (μg/L), iron (μg/dL), total iron binding capacity (TIBC) (μg/dL), transferrin saturation (TSAT) (%), ante cibum (AC) blood glucose (mg/dL), post cibum (PC) blood glucose (mg/dL), total protein (g/dL), and cardiothoracic ratio (CTR) (%). Following an 8-h fast for routine biochemical testing, blood samples were collected from patients both before and after their dialysis session. Without using a tourniquet, samples were collected from tunneled catheters, arteriovenous fistulas, or grafts; the initial sample was discarded from heparin-primed catheters.
Statistical analyses
Continuous data were reported as mean ± standard deviation and categorical data were expressed as numbers (%) of patients. To compare the means of continuous variables, analysis of variance (ANOVA) was employed. Additionally, the chi-square test (χ2 test) was utilized to compare categorical variables between different groups.
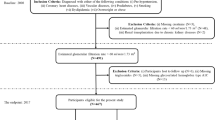
Figure 1 presents the algorithm of data-driven ML methods in CHD patients. We divided the prediction subgroups into 1- and 3-year mortality. Each subgroup utilized ML algorithms to construct prediction models and evaluate the important factors. To establish the fundamentals of model building and validation, we followed a multistage process. First, we divided the patients into validation and testing datasets. The validation dataset comprised 80% of patients with CHD, while the remaining 20% constituted the testing dataset. Next, we employed a tenfold method on the validation dataset. This method involved dividing the dataset into 10 equal parts or folds, ensuring data randomization. Once the folds were established, we proceeded to build five different ML models: LGR, decision tree (DT), RF, gradient boosting (GB), and XGB. Through this approach, the performance of each model can be thoroughly validated and evaluated according to the different folds from the validation dataset. All five ML models were evaluated their respective indicators, including accuracy, sensitivity, specificity, and area under the curve (AUC).

The algorithm of data-driven machine-learning methods in chronic hemodialysis patients.
After the evaluation of these ML models, we compared the results with those of the LGR model and the best modified model from other four. To achieve this, we selected the most significant risk variables from the LGR model alone, while the four remaining models (DT, RF, GB, and XGB) ranked such variables by averaging their rankings. We used these top variables from LGR to modify the rebuilt logistic regression (rebuilt LGR) model and modify the best model among the four remaining models by incorporating the variables with the highest average rank into the most suitable model. Finally, we compared the results with the best remodified model and the rebuilt LGR model through validation and compared the results with the previous training dataset. A two-tailed p value of < 0.05 was considered statistically significant. All statistical data were analyzed using R for MacOS version 4.2.1.
Results
Study population characteristics
We included 800 patients receiving HD, with 718 of them surviving at the 1-year mark and 519 surviving at the 3-year mark. Table 1 summarizes the participants’ basic characteristics, comorbidities, and laboratory data. The overall mean age of the study population was 63.30 ± 13.26 years. In the subgroup with a one-year observation, the mean age of the survival group was 62.73 ± 13.20 years, whereas the mortality group had a mean age of 73.55 ± 11.94 years. For the with a 3-year observation, the survival group had a mean age of 60.92 ± 13.04 years, while the mortality group had a mean age of 71.24 ± 11.43 years.
Comparison of survival prediction performance among different ML methods
Table 2 shows the comparison of survival prediction performance among different ML models, including LGR, DT, RF, GB, and XGB, in terms of accuracy, sensitivity, specificity, and AUC. For the 1-year mortality prediction model, both RF and GB showed high accuracy and AUC in both validation and testing datasets. Specifically, RF had 0.948 accuracy in validation datasets and 0.941 in testing datasets, while GB had 0.949 and 0.941, respectively. Regarding AUC, RF obtained 0.734 in validation datasets and 0.806 in testing datasets, while GB had 0.737 and 0.793, respectively. For the 3-year mortality prediction model, RF had the highest accuracy in both validation and testing datasets (0.794 and 0.804, respectively), and its AUC values were 0.751 and 0.763, respectively, indicating solid performance. Overall, RF outperformed other models in terms of accuracy and AUC for all four study cutoff periods in both validation and testing datasets.
Ranking of CHD mortality risk variables using ML methods
Figure 2 presents the average ranking of variables from four ML models (DT, RF, GB, and XGB) in 1- and 3-year mortality predication. Given that RF had the highest accuracy and AUC results in both the validation and testing datasets, we selected it as the optimal modified model for our study and subsequently put the top average ranking variables. Figure 3 illustrates the RF accuracy trends by the accumulated number of variables for the 1- and 3-year mortality prediction models. The 1- and 3-year accuracy trends of mortality prediction model for RF indicated that only the top 14 and 12 important variables were required to achieve the maximum accuracy, respectively.

The average ranking of variables from four machine-learning models (decision tree, random forest, gradient boosting, and eXtreme gradient boosting ) in (A) 1-year and (B) 3-year mortality prediction. COPD chronic obstructive pulmonary disease, RAAS renin–angiotensin–aldosterone system, Kt/V urea kinetic, URR urea reduction ratio, BUN blood urea nitrogen, AC Ante Cibum (before meals), PC Post Cibum (after meals), Na sodium, K Potassium, iCa ionized calcium, iPTH intact parathyroid hormone, Alk-p alkaline phosphatase, AST aspartate aminotransferase, ALT alanine transaminase, Bil-T total bilirubin, HDL high-density lipoprotein, LDL low-density lipoprotein, Hb hemoglobin, Ht hematocrit, MCV mean corpuscular volume, TIBC total iron binding capacity, TSAT transferrin saturation, Al Aluminum (ng/mL), CTR cardiothoracic ratio.

The random forest accuracy trend by the accumulated number of variables for (A) 1-year mortality and (B) 3-year mortality prediction models.
Table 3 summarizes the rankings of variables for CHD mortality risk via all of the five ML methods. The top half of Table 3 displays the average ranking of variables from DT, RF, GB, and XGB before reaching the maximum accuracy for the 1- and 3-year models. For the 1-year model, the top 14 variables included age, post-HD creatinine, AST, total bilirubin, post-HD BUN, pre-HD creatinine, Kt/V, CTR, LDL, albumin, iPTH, alkaline phosphatase, aluminum, and TIBC. For the 3-year model, the top 12 variables included age, AST, CTR, pre-HD creatinine, alkaline phosphatase, AC blood glucose, iPTH, iCa, post-HD creatinine, ferritin, ALT, and hematocrit. At the bottom half of Table 3, we list the significant variables identified by the LGR model before being used in the modified model. The significant variables in the 1-year model were age, CTR, ferritin, and ALT, whereas those in the 3-year model were age, CTR, iPTH, sex, alkaline phosphatase, pre-HD creatinine, post-HD creatinine, and phosphorus.
Survival prediction performance between the RF with stepwise remodeling and the rebuilt LGR
We used the highest average rank variables from DT, RF, GB, and XGB for the RF with stepwise remodeling method. The results were then compared with those of the rebuilt LGR model. Table 4 compares the survival prediction performance between RF stepwise modeling and rebuilt LGR in terms of accuracy, recall, specificity, and AUC. In the 1-year prediction model, the accuracy of RF stepwise modeling was 0.940, whereas that of the rebuilt LGR was 0.937. The specificity was 1.000 in the RF and 0.996 in the LGR, with AUCs of 0.727 and 0.576, respectively. In the 3-year prediction model, the accuracy of RF stepwise modeling was 0.801, whereas that of the rebuilt LGR was 0.767. Regarding specificity, RF and LGR obtained 0.989 and 0.940, with AUCs of 0.805 and 0.806, respectively. Overall, the stepwise RF model demonstrated superior predictive performance compared to the traditional LGR method in predicting the mortality of CHD patients.
Advantage of DT algorithm
DT provided a useful and understandable algorithm. Figure 4A shows the algorithm of DT in the 1-year prediction model. The first cutoff criterion was age below 60 years, which accounted for 41% of the validation dataset. The DT model judged the “age below 60 years” as survival (present as “0”), while the actual survival rate was 92%. The rest of the 59% then moved into the second cutoff criterion, that is, pre-HD creatinine level being greater or equal to 5.5 mg/dL; only 3% of the patients failed to meet the criterion. The DT model judged “age greater or equal to 60 years” and “pre-HD creatinine level less than 5.5 mg/dL” as a mortality result (present as “1”), but the actual survival rate was only 20% in the validation dataset. Further cutoff criteria included AST, TIBC, ALT, iron, MCV, pre-HD BUN, TSAT, triglyceride, AC glucose, and total cholesterol level sequentially. Finally, 13 groups had been categorized and moved into the terminal (leaf) of the DT. Figure 4B shows the algorithm of DT in the 3-year prediction model. The first three cutoff criteria were the same (age below 60 years, pre-HD creatinine level greater or equal to 5.5 mg/dL, and AST below 45 U/L). Further cutoff criteria were TSAT, TIBC, ALT, age below 78 years, MCV, aluminum, alkaline phosphatase, and hemoglobin. Likewise, 13 groups had been categorized and moved into the terminal (leaf) of the DT.

The algorithm of decision tree (DT) in the (A) 1-year prediction model (the 7th fold) and (B) 3-year prediction model (the 1st fold). BUN blood urea nitrogen, AC ante Cibum (before meals), AST aspartate aminotransferase, ALT alanine transaminase, MCV mean corpuscular volume, TIBC total iron binding capacity, TSAT transferrin Saturation.
Discussion
Our study adopted five ML methods to manage the best prediction model from different years of mortality in patients with CHD, then successfully developed a two-stage ML algorithm-based prediction scheme to achieve the stepwise RF model, which incorporates the most important factors of CHD mortality risk based on the average rank from DT, RF, GB, and XGB. The stepwise RF model in our study demonstrated superior predictive performance compared to the traditional LGR method for mortality in CHD patients over both 1-year and 3-year model. Finally, we can integrate our proposed ML scheme into the electronic reporting system to enhance patient care (Fig. 5).

The application of the data-driven machine-learning methods in clinical practice from our study.
All five ML models individually provided solid and consistent performance in predicting the morality of patients with CHD, which were divided into the validation and testing datasets. Regarding the validation and testing datasets from 1- and 3-year mortality prediction model, the RF had better accuracy and area-under-curve results among the five different ML methods. Moreover, the RF only required the top 14 important variables from 1-year accuracy trend and only top 12 variables from the 3-year accuracy trend to reach the maximum accuracy. Interestingly, both the RF stepwise modeling and rebuilt LGR methods needed considerably fewer variables to provide a similar performance from all 44 variables of the 1-year and 3-year models while demonstrating high efficiency in analyzing mortality risk prediction in patients with CHD. Notably, although the DT method did not exhibit the highest accuracy and AUC, it showed a good potential because it provided an algorithm that is very comprehensible and offered some selectable and adjustable variables according to the current clinical trend or physician’s clinical preference.
The top important variables of CHD identified by the five different ML methods provide consistent results. The average rank from all ML methods concluded that age, creatinine (pre- and post-HD), and CTR were the most frequent top variables in all four cutoff periods. Albumin, aluminum, alkaline phosphatase, AST, and AC blood glucose were also top indicators for mortality prediction. Some of these important variables identified by ML methods agree with previous studies. For example, multiple prospective cohort studies reported that CTR25,26,27, elevated serum alkaline phosphatase28,29,30,31, and lower serum albumin levels32,33,34 are associated with higher mortality risk in patients with CHD. Higher serum aluminum levels also represent as a mortality risk factor35,36,37 and even has some potential associations with CTR, although the cause of the relationship or mechanism is still vague38.
Serum creatinine levels before and after HD were highlighted as the top-ranked variables from the ML models and also frequently measured in clinical practice. Walther et al. also concluded that pre-dialysis and interdialytic change of serum creatinine is highly related to mortality in patients undergoing HD39. However, muscle lean mass40,41,42,43, infection status44,45, severe illness46,47 and poor nutrition status39,45 that affects the metabolism and catabolism may influence the serum creatinine level. Some studies investigated the modified creatinine index (mCI) for better mortality prediction40,43,44,48. However, the baseline characteristic of serum creatinine level in patients with CHD could be more varied in different study periods, making it very difficult to define in clinical practice. Moreover, the mCI incorporated age, sex, and Kt/V (urea kinetics) into the formula, resulting in multifactorial interference and potentially misleading the prediction bias.
URR, one of the most common indicators of HD dose delivery, is generally associated with decreased mortality49,50,51,52. Unexpectedly, the URR in our study did not match the top variable factors, probably because the URR in the survival group (1-year subgroup: 0.73 ± 0.06; 3-year subgroup: 0.73 ± 0.06) and mortality group (0.76 ± 0.07 and 0.74 ± 0.06 respectively) were both in optimized dose (≥ 0.65) without statistically significance. Moreover, URR is higher in patients with sarcopenia or malnutrition, leading to higher mortality risk in those with CHD. McClellan et al. concluded that a URR of 0.70–0.74 has an increasing trend of mortality risk compared with 0.65–0.6953. Considering that the URR is also affected by urea distribution volume changes and urea generation during HD, the 2015 National Kidney Foundation’s Kidney Disease Outcomes Quality Initiative (KDOQI) recommends the targeted single pool Kt/V (spKt/V) for the dialysis adequacy instead of URR52.
Table 5 presents a range of data-driven ML methods employed for identifying risk factors and modifying mortality prediction in patients with CHD. Victoria Garcia-Montemayor et al. concluded that RF is adequate for mortality prediction in patients with CHD, superior to LGR20. According to Kaixiang Sheng et al., XGB can effectively identify high-risk patients within 1 year after HD initiation19. In the study of Covadonga Díez-Sanmartín et al., combining XGBoost method with the corresponding Kaplan–Meier curve presentation to evaluate the risk profile of patients undergoing dialysis demonstrated very high accuracy, specificity, and AUC results16. Oguz Akbilgic et al. also used RF to identify the risk factors of mortality within 1 year after dialysis introduction and inferred that RF also had a strong prediction performance compared with other ML methods, such as artificial neural networks, support vector machines, and k-nearest neighbors algorithm21. Furthermore, Cheng-Hong Yang et al. revealed that whale optimization algorithm with full-adjusted-Cox proportional hazards (WOA-CoxPH) could evaluate risks better than RF and typical Cox proportional hazards (CoxPH) in patients with CHD54. However, these previous studies had a relatively short prediction period, mostly within 2 years. Our study emphasizes the characteristics of patients with CHD and has effectively achieved a robust prediction performance for up to 3 years using the stepwise RF model, modified from two-stage ML algorithm-based prediction scheme. Figure 5 demonstrate our approach of the AI system by incorporating the top numerical risk variables selected by various ML methods, our study model can effectively assist physicians, caregivers, and patients in predicting short-term post-dialysis mortality outcomes. This model allows for enhanced patient-centered decision-making and increased awareness about laboratory data that could be risk factors, especially for patients with a high short-term mortality risk. It also enables individuals to achieve a better quality of life earlier and helps avoid unnecessary healthcare expenditures.
This study has some limitations. First, the top variables modified by ML only provide the relationship of mortality in patients with CHD but not infer the positive or negative associations from these variables. Moreover, not all the top variables agree with previous study results, especially serum creatinine level, which can be affected by various clinical conditions that may mislead the data-driven ML results. In the future implementation of ML-identified variables to an unknown disease, these variables should be clinically investigated further. Second, we initially extended the analysis cutoff period up to 7 years but then only selected within 3 years to avoid data-censoring risk of bias by a high mortality rate after dialysis initiation. A long-term prediction model may need larger data and even longer study period for better qualification and quantification. Third, our dataset only contained a composite parameter for CVD. However, prognoses may vary among different CVD categories in CHD patients. Additional research may be required to examine the effects of subclassifications of CVD on mortality. Fourth, the individuals in our study were chosen from a pool that did not encompass recently hospitalized patients dealing with cardiovascular or infectious concerns. This subset was anticipated to exhibit a greater likelihood of survival compared to those who had recently been hospitalized, a factor that could potentially skew our study results. Therefore, our model may only be applicable to the CHD patients who are relatively stable. Finally, the developed prediction models by ML methods in our study are limited to a single medical center. Hence, the model modified from our study population may not be applicable to other similar at-risk research groups. Future studies on ML such as federated learning that incorporates multiple medical centers and research groups could be helpful for improving predictive performance and strengthening clinical decisions.
Conclusion
The adoption of the stepwise RF model, modified from two-stage ML algorithm-based prediction scheme, enhances patient-centered decision-making, and improves outcomes, particularly for patients with a high short-term mortality risk in both 1-year and 3-year periods. The findings of this study can offer valuable information to nephrologists, increasing awareness about risky laboratory data. However, for longer prediction periods, future studies should consider incorporating larger study populations and diverse groups to further enhance predictive performance.
Data availability
The supporting data can only be accessed by legitimate researchers under a non-disclosure agreement because of confidentiality obligations. Further information on the data and instructions for requesting access can be obtained from the corresponding author.
References
Couser, W. G. et al. The contribution of chronic kidney disease to the global burden of major noncommunicable diseases. Kidney Int. 80(12), 1258–1270 (2011).
Turin, T. C. et al. Chronic kidney disease and life expectancy. Nephrol. Dial. Transplant. 27(8), 3182–3186 (2012).
Neuen, B. L. et al. Chronic kidney disease and the global NCDs agenda. BMJ Glob. Health 2(2), e000380 (2017).
Bello, A. K. et al. Epidemiology of haemodialysis outcomes. Nat. Rev. Nephrol. 18(6), 378–395 (2022).
Wu, B.-S. et al. Mortality rate of end-stage kidney disease patients in Taiwan. J. Formosan Med. Assoc. 121, S12–S19 (2022).
Coric, A. et al. Mortality in hemodialysis patients over 65 years of age. Mater. Sociomed. 27(2), 91–94 (2015).
Gotch, F. A. & Sargent, J. A. A mechanistic analysis of the National Cooperative Dialysis Study (NCDS). Kidney Int. 28(3), 526–534 (1985).
Lowrie, E. G. et al. Effect of the hemodialysis prescription on patient morbidity. N. Engl. J. Med. 305(20), 1176–1181 (1981).
Saeed, F. et al. What are the risk factors for one-year mortality in older patients with chronic kidney disease? An analysis of the cleveland clinic CKD registry. Nephron 141(2), 98–104 (2019).
Haapio, M. et al. One- and 2-year mortality prediction for patients starting chronic dialysis. Kidney Int. Rep. 2(6), 1176–1185 (2017).
do-Samerio-Faria, M. et al. Risk factors for mortality in hemodialysis patients: Two-year follow-up study. Dis. Mark. 35(6), 791–798 (2013).
Goodkin, D. A. et al. Mortality among hemodialysis patients in Europe, Japan, and the United States: Case-mix effects. Am. J. Kidney Dis. 44, 16–21 (2004).
Ramspek, C. L. et al. Prediction models for the mortality risk in chronic dialysis patients: A systematic review and independent external validation study. Clin. Epidemiol. 9, 451–464 (2017).
Hansrivijit, P. et al. Prediction of mortality among patients with chronic kidney disease: A systematic review. World J. Nephrol. 10(4), 59–75 (2021).
Sarker, I. H. AI-based modeling: Techniques, applications and research issues towards automation, intelligent and smart systems. SN Comput. Sci. 3(2), 158 (2022).
Díez-Sanmartín, C., Cabezuelo, A. S. & Belmonte, A. A. A new approach to predicting mortality in dialysis patients using sociodemographic features based on artificial intelligence. Artif. Intell. Med. 136, 102478 (2023).
Chaudhuri, S. et al. Artificial intelligence enabled applications in kidney disease. Semin. Dial. 34, 5–16 (2023).
Kim, H. W. et al. Dialysis adequacy predictions using a machine learning method. Sci. Rep. 11(1), 15417 (2021).
Sheng, K. et al. Prognostic machine learning models for first-year mortality in incident hemodialysis patients: Development and validation study. JMIR Med. Inform. 8(10), e20578 (2020).
Garcia-Montemayor, V. et al. Predicting mortality in hemodialysis patients using machine learning analysis. Clin. Kidney J. 14(5), 1388–1395 (2020).
Akbilgic, O. et al. Machine learning to identify dialysis patients at high death risk. Kidney Int. Rep. 4(9), 1219–1229 (2019).
Liu, Y.-S. et al. Machine learning analysis of time-dependent features for predicting adverse events during hemodialysis therapy: Model development and validation study. J. Med. Internet Res. 23(9), e27098 (2021).
Pugliese, R., Regondi, S. & Marini, R. Machine learning-based approach: Global trends, research directions, and regulatory standpoints. Data Sci. Manag. 4, 19–29 (2021).
Fang, Y. W. et al. Higher intra-dialysis serum phosphorus reduction ratio as a predictor of mortality in patients on long-term hemodialysis. Med. Sci. Monit. 25, 691–699 (2019).
de Mutsert, R. et al. Association between serum albumin and mortality in dialysis patients is partly explained by inflammation, and not by malnutrition. J. Renal Nutr. 19(2), 127–135 (2009).
Tang, J. et al. Early albumin level and mortality in hemodialysis patients: A retrospective study. Ann. Palliat. Med. 10(10), 10697–10705 (2021).
Iseki, K., Kawazoe, N. & Fukiyama, K. Serum albumin is a strong predictor of death in chronic dialysis patients. Kidney Int. 44(1), 115–119 (1993).
Fan, Y. et al. Elevated serum alkaline phosphatase and cardiovascular or all-cause mortality risk in dialysis patients: A meta-analysis. Sci. Rep. 7(1), 13224 (2017).
Regidor, D. L. et al. Serum alkaline phosphatase predicts mortality among maintenance hemodialysis patients. J. Am. Soc. Nephrol. 19(11), 2193–2203 (2008).
Blayney, M. J. et al. High alkaline phosphatase levels in hemodialysis patients are associated with higher risk of hospitalization and death. Kidney Int. 74(5), 655–663 (2008).
Sumida, K. et al. Prognostic significance of pre-end-stage renal disease serum alkaline phosphatase for post-end-stage renal disease mortality in late-stage chronic kidney disease patients transitioning to dialysis. Nephrol. Dial. Transplant. 33(2), 264–273 (2017).
Yotsueda, R. et al. Cardiothoracic ratio and all-cause mortality and cardiovascular disease events in hemodialysis patients: The Q-cohort study. Am. J. Kidney Dis. 70(1), 84–92 (2017).
Chou, C.-Y. et al. Cardiothoracic ratio values and trajectories are associated with risk of requiring dialysis and mortality in chronic kidney disease. Commun. Med. 3(1), 19 (2023).
Bashardoust, B. et al. Mortality and nutritional status in patients undergoing hemodialysis. Shiraz E-Med. J. 16(2), e20076 (2015).
Tsai, M. H. et al. Association of serum aluminum levels with mortality in patients on chronic hemodialysis. Sci. Rep. 8(1), 16729 (2018).
Hsu, C. W. et al. Association of low serum aluminum level with mortality in hemodialysis patients. Ther. Clin. Risk Manag. 12, 1417–1424 (2016).
Salahudeen, A. K. et al. Race-dependent survival disparity on hemodialysis: Higher serum aluminum as an independent risk factor for higher mortality in whites. Am. J. Kidney Dis. 36(6), 1147–1154 (2000).
Chuang, P.-H. et al. Blood aluminum levels in patients with hemodialysis and peritoneal dialysis. Int. J. Environ. Res. Public Health 19(7), 3885 (2022).
Walther, C. P. et al. Interdialytic creatinine change versus predialysis creatinine as indicators of nutritional status in maintenance hemodialysis. Nephrol. Dial. Transplant. 27(2), 771–776 (2012).
Tian, R. et al. Association of the modified creatinine index with muscle strength and mortality in patients undergoing hemodialysis. Renal Fail. 44(1), 1732–1742 (2022).
Kalantar-Zadeh, K. et al. The obesity paradox and mortality associated with surrogates of body size and muscle mass in patients receiving hemodialysis. Mayo Clin. Proc. 85(11), 991–1001 (2010).
Canaud, B. et al. Creatinine index as a surrogate of lean body mass derived from urea Kt/V, pre-dialysis serum levels and anthropometric characteristics of haemodialysis patients. PLoS ONE 9(3), e93286 (2014).
Yamamoto, S. et al. Modified creatinine index and clinical outcomes of hemodialysis patients: An indicator of sarcopenia?. J. Renal Nutr. 31(4), 370–379 (2021).
Arase, H. et al. Modified creatinine index and risk for long-term infection-related mortality in hemodialysis patients: Ten-year outcomes of the Q-Cohort Study. Sci. Rep. 10(1), 1241 (2020).
Noori, N. et al. Racial and ethnic differences in mortality of hemodialysis patients: Role of dietary and nutritional status and inflammation. Am. J. Nephrol. 33(2), 157–167 (2011).
Clermont, G. et al. Renal failure in the ICU: Comparison of the impact of acute renal failure and end-stage renal disease on ICU outcomes. Kidney Int. 62(3), 986–996 (2002).
Viallet, N. et al. Daily urinary creatinine predicts the weaning of renal replacement therapy in ICU acute kidney injury patients. Ann. Intensive Care 6(1), 71 (2016).
Suzuki, Y. et al. Trajectory of lean body mass assessed using the modified creatinine index and mortality in hemodialysis patients. Am. J. Kidney Dis. 75(2), 195–203 (2020).
Owen, W. F. et al. The urea reduction ratio and serum albumin concentration as predictors of mortality in patients undergoing hemodialysis. N. Engl. J. Med. 329(14), 1001–1006 (1993).
Held, P. J. et al. The dose of hemodialysis and patient mortality. Kidney Int. 50(2), 550–556 (1996).
Wolfe, R. A. et al. Improvements in dialysis patient mortality are associated with improvements in urea reduction ratio and hematocrit, 1999 to 2002. Am. J. Kidney Dis. 45(1), 127–135 (2005).
Daugirdas, J. T. et al. KDOQI clinical practice guideline for hemodialysis adequacy: 2015 update. Am. J. Kidney Dis. 66(5), 884–930 (2015).
McClellan, W. M., Soucie, J. M. & Flanders, W. D. Mortality in end-stage renal disease is associated with facility-to-facility differences in adequacy of hemodialysis. J. Am. Soc. Nephrol. 9(10), 1940–1947 (1998).
Yang, C.-H. et al. Machine learning approaches for the mortality risk assessment of patients undergoing hemodialysis. Ther. Adv. Chronic Dis. 13, 20406223221119616 (2022).
Funding
The artificial intelligence center of Shin Kong Wu Ho-Su Memorial Hospital sponsored this study (2021SKHADE034). The authors report no conflicts of interest.
Author information
Authors and Affiliations
Contributions
Conceptualization: L.-W.T., F.-Y.W., C.-M. and T.-M.H.; Methodology: S.-B.C., C-M., S.-B.C., and T.-M.H.; Data analysis and interpretation: L.-W.T., F.-Y.W., C.-W.S., H.-K.Y., S.-B.C. and C.-M. and T.-M.H.: Writing: L.-W.T. and T.-M.H.; Review & Editing: F.-Y.W., C.-M., and T.-M.H.; Visualization: L.-W.T., C.-W.S., and H.-K.Y.; Supervision: C.-M. and T.-M.H.; Funding acquisition: C.-M. and T.-M.H.; Approved the manuscript: all authors.
Corresponding authors
Ethics declarations
Competing interests
The authors declare no competing interests.
Additional information
Publisher's note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Lee, WT., Fang, YW., Chang, WS. et al. Data-driven, two-stage machine learning algorithm-based prediction scheme for assessing 1-year and 3-year mortality risk in chronic hemodialysis patients. Sci Rep 13, 21453 (2023). https://doi.org/10.1038/s41598-023-48905-9
Received:
Accepted:
Published:
DOI: https://doi.org/10.1038/s41598-023-48905-9
Comments
By submitting a comment you agree to abide by our Terms and Community Guidelines. If you find something abusive or that does not comply with our terms or guidelines please flag it as inappropriate.
