
Abstract
Emerging infectious diseases are a critical public health challenge in the twenty-first century. The recent proliferation of such diseases has raised major social and economic concerns. Therefore, early detection of emerging infectious diseases is essential. Subjects from five medical institutions in Beijing, China, which met the spatial-specific requirements, were analyzed. A quality control process was used to select 37,422 medical records of infectious diseases and 56,133 cases of non-infectious diseases. An emerging infectious disease detection model (EIDDM), a two-layer model that divides the problem into two sub-problems, i.e., whether a case is an infectious disease, and if so, whether it is a known infectious disease, was proposed. The first layer model adopts the binary classification model TextCNN-Attention. The second layer is a multi-classification model of LightGBM based on the one-vs-rest strategy. Based on the experimental results, a threshold of 0.5 is selected. The model results were compared with those of other models such as XGBoost and Random Forest using the following evaluation indicators: accuracy, sensitivity, specificity, positive predictive value, and negative predictive value. The prediction performance of the first-layer TextCNN is better than that of other comparison models. Its average specificity for non-infectious diseases is 97.57%, with an average negative predictive value of 82.63%, indicating a low risk of misdiagnosing non-infectious diseases as infectious (i.e., a low false positive rate). Its average positive predictive value for eight selected infectious diseases is 95.07%, demonstrating the model's ability to avoid misdiagnoses. The overall average accuracy of the model is 86.11%. The average prediction accuracy of the second-layer LightGBM model for emerging infectious diseases reaches 90.44%. Furthermore, the response time of a single online reasoning using the LightGBM model is approximately 27 ms, which makes it suitable for analyzing clinical records in real time. Using the Knox method, we found that all the infectious diseases were within 2000 m in our case, and a clustering feature of spatiotemporal interactions (P < 0.05) was observed as well. Performance testing and model comparison results indicated that the EIDDM is fast and accurate and can be used to monitor the onset/outbreak of emerging infectious diseases in real-world hospitals.
Similar content being viewed by others

Introduction
Emerging infectious diseases are defined as “new, emerging, or drug-resistant infectious diseases, the occurrence of which in the population has increased in the past 20 years or for which there are indications that their incidence may increase in the future”1. Emerging infectious diseases mainly include new diseases, existing diseases emerging in a new area or population, reintroduced old diseases, previously clinically mild diseases increasing in severity, and previously preventable or treatable diseases becoming uncontrolled or treatment-resistant2. Emerging pathogens include bacteria, viruses, parasites, chlamydia, rickettsia, spirochetes, and mycoplasma, among which viruses cause the largest number of emerging infectious disease cases. Emerging infectious diseases, which can cause serious regional or international public health concerns, are one of the most critical public health challenges faced by humankind in the twenty-first century. In the past 30 years, at least 40 emerging infectious diseases have been detected worldwide1, and their number is rapidly increasing, posing a considerable threat to human life and health. For example, SARS raged in 2002–2004, the Ebola virus broke out in Africa in 2013–2016, Zika virus cases were detected in 2016, yellow fever was detected in 2016–2018, and so on. Emerging infectious diseases possess the inherent infectivity and prevalence of infectious diseases, they have complex origins, and tracing the sources of these diseases is arduous. Furthermore, they tend to be widespread and difficult to control, making them uniquely uncertain and unpredictable. Owing to these characteristics, these diseases cause extensive harm, as there are no existing guidelines regarding their prevention and control. For example, the coronavirus disease (COVID-19) that occurred in 2019 transmitted rapidly and spread widely, turning into a pandemic, thereby damaging societal and economic stability worldwide3. Accordingly, monitoring and early warning of emerging infectious diseases are critical steps towards preventing their spread. Forecasting of emerging infectious diseases and generating an early warning system to avoid their outbreaks are major challenges.
At present, most emerging infectious diseases are discovered because of abnormalities noticed by clinicians. After observation, laboratory biological testing, clinical treatment, and so on, certain disease symptoms are identified and categorized as symptoms of emerging infectious diseases. For example, COVID-19 was discovered when clinicians, who diagnosed the symptoms, reported that many patients were employees of the Huanan Seafood Wholesale Market, and bioinformatics testing showed that the pathogen was a new type of coronavirus4. Thus, clinical symptom monitoring and access to the complete medical information of a patient can aid in identifying emerging infectious diseases. Medical institutions are the first line of defense for diagnosing and treating such diseases. Unlike public health monitoring to identify known infectious diseases, timely monitoring of abnormal symptoms and phenomena by medical institutions during infectious disease outbreaks is more beneficial for emerging infectious disease management5. Continuous improvements in hospital medical information systems over the years have resulted in the accumulation of a large amount of medical data, including health data, patient information, medical records, inspection records, imaging records, and cost information. In a medical institution with an average daily outpatient volume of 15,000, the medical data volume increases by 50 Gb daily6. In general hospitals in China, daily outpatient visits generally exceed 10,000. Therefore, in addition to seeing patients, doctors in medical institutions are expected to identify clues of emerging infectious diseases from many complex and related medical records, and this task is extremely difficult. Furthermore, clinicians need to follow a specific set of rules and regulations while identifying infectious disease risks, performing active identification and legal reporting, and it is objectively difficult for clinicians to take the initiative to provide early warning in the absence of relevant background information. To address these challenges, a big-data-based effective prediction model that can extract features from a large volume of data, perform data mining, and conduct simultaneous time and space monitoring is urgently required.
In general, medical institutions predict the prevalence and outbreak of infectious diseases. Unlike traditional statistical methods, machine learning and deep learning are data driven. To date, several studies on disease diagnosis, hospitalization, prediction of treatment duration, etc. have been conducted using health data obtained from medical institutions7,8. These reported studies have revealed several significant theoretical and practical results, which have propelled further research in this field. In recent years, early warning generation and prediction of the onset of infectious diseases have come under the spotlight because of the advances in big data and machine learning; for instance, Lee et al., Feng and Jin, and Wang et al. 9,10,11 predicted the onset trend of known infectious diseases. Based on the details, it can be concluded that medical institutions acquire health data during the early stages of the disease as well as are the first points-of-contact for patients infected with various known/unknown infectious diseases. In addition, they have the basic conditions for analyzing the outbreak of emerging infectious diseases. Thus, a combination of machine learning and deep learning will facilitate medical institutions in early detection of the emerging variants of infectious diseases, thereby enabling an effective and timely containment to prevent their outbreak. Thus, this study was designed to construct an emerging infectious disease identification framework based on the real and complete medical records of hospitals, with hierarchical diagnosis model (EIDDM) and the Knox method for spatial cluster as the cores, using machine learning. Considering the accuracy and computational efficiency of data collection in actual medical institutions, a hierarchical diagnosis model, namely the emerging infectious disease detection model (EIDDM), which combines the TextCNN-Attention and LightGBM algorithms, was developed. This proposed framework is suitable for spatial–temporal monitoring of infectious diseases in medical institutions and is anticipated to mitigate the existing key issues related to emerging infectious disease management. The primary objectives and contributions of the present study are as follows:
Analysis of the current research methods on the identification of emerging infectious diseases, and summary of the currently known key issues, including the reported data of symptom events, inadequate reporting of active behavior, and disconnection between non-clinical data (such as online search data) and real medical cases.
Based on the analysis of datasets acquired from multiple medical institutions, structured and unstructured data are applied to various models for separate processing, and a special processing is carried out for different types of features to utilize all the features completely. These processes provide separate datasets for training as well as real-world application of the developed model.
The proposed EIDDM considers both model recognition and online reasoning efficiency. The average emerging-infectious-disease prediction accuracies of the first- and second layer models were 90.47% and 86.93%, respectively. The prediction time of the online reasoning for a single medical record is only 27 ms, which is remarkably less than that required for one-hot encoding of a single medical record in previous studies (68 ms) and is more suitable for real-time scenarios in real clinical medical institutions.
Cluster analysis was performed using the Knox method, which does not require population migration and total population data. A cluster analysis is an effective supplement to EIDDM, which is a hierarchical diagnosis model, to determine the existence of a spatial cluster after discovering the emerging infectious disease cases. This step reduces the misjudgment rate of individual case samples when the model is applied to the data obtained from real medical institutions.
The rest of the paper is organized as follows: Section "Related work" presents and describes the previous studies reported in this field. Section "Materials and methods" discusses the data processing and modeling approaches employed in this study. Section "Results" elucidates the experimental results and compares them with other state-of-the-art research strengths and limitations. Section "Discussions" discusses the rationale for using the one-vs-rest (OvR) strategy to identify emerging infectious diseases. Section "Conclusion" highlights the major conclusions drawn from the findings of this study.
Related work
Currently, monitoring of emerging infectious diseases is one of the key tasks of public health emergency detection and is accomplished mainly through the collection, analysis, identification, and intervention of the occurrence, spread, and source of infectious diseases in the population. According to Christaki et al. 12, infectious disease monitoring is divided into event-based surveillance, web-based real-time surveillance, social media monitoring, and new technologies in pathogen discovery. Event-based surveillance is primarily organized by health authorities. In China, infectious diseases are divided into categories A, B, and C, and doctors in medical institutions are required to report through the national infectious disease reporting system within a limited time 13. This system enables medical institutions to act as monitoring sentinels to report and review patients with infectious or suspected infectious diseases. The system also aids health departments and disease control systems in rapidly analyzing and judging any epidemic situation. The observations made in the initial stage of the novel coronavirus epidemic revealed that the system is only limited to daily monitoring and reporting of known infectious diseases. These attributes cannot meet the requirements of information acquisition, early warning, and disposal of emerging infectious diseases 14. Furthermore, the elements involved in the surveillance of emerging infectious diseases are diverse and complex, and the fixed indicator combination of traditional disease surveillance is not necessarily applicable to these emerging infectious diseases. Previously, some researchers 15,16 conducted surveillance of influenza, influenza-like illnesses, and severe respiratory illnesses based on the symptom surveillance system, which caused a large analysis bias due to the inevitable gap between the symptoms and the actual diagnosis. However, only considering symptoms without incorporating the time and space information cannot satisfy the prediction accuracy of regional infectious disease incidences.
In online-data-based surveillance, the data are chiefly obtained from non-medical institutions in the form of online search engine data, news data, or social data to monitor diseases with potential epidemic risks as well as infectious diseases with seasonal activities. Ref. 17,18 report the use of results obtained from web search engines as the data sources for infectious disease symptom monitoring. In these two reported studies, correlation analysis was conducted between the frequency of the related search terms and the actual number of people with symptoms to track the spread of regional infectious diseases. According to Ref. 19, Google's prediction of flu trends can be 1 to 2 weeks ahead of that of the Center for Disease Control and Prevention. Juhyeon et al. 20 used Medisys to collect internet articles related to infectious diseases to predict the outbreak of infectious diseases using a support vector machine-based model. However, because search engines and news methods require many search queries, in terms of disease coverage, they only support conventional symptoms that the public can describe, such as fever, vomiting, diarrhea, etc., and cannot monitor abnormalities in inspections. In addition, there is a disconnect between the online data and real medical records of medical institutions, and thus, the online method cannot be truly applied in the monitoring scenarios of medical institutions. From the perspective of spatiotemporal monitoring of infectious diseases, online data monitoring facilitates a general large-scale prediction across the country, which cannot be analyzed from the perspective of a spatial cluster. However, a spatial cluster can be located by analyzing the home and work addresses provided in medical records.
With the development of machine learning and neural networks, several methods for early warning and prediction of infectious diseases have been reported to date. Wilkinson et al. 21 adopted a statistical process control method, because the data should be independent, and the known parameters should follow a normal distribution. However, the actual transmission mechanism of infectious diseases cannot be completely independent; a certain correlation between the cases is expected. Nevertheless, the machine-learning-based prediction methods exhibit some shortcomings. For instance, although a decision tree can be easily interpreted, a single tree is more sensitive to noise data and has a poor generalization ability. However, an integrated model based on the decision tree can overcome the shortcomings of a single tree. Further, the Bayesian method has a simple logic, is easy to implement, and performs well when the features in the correlation are relatively small. However, the algorithm involves independent assumptions of the feature conditions, and performs poorly when there are many features, and the correlation between the features is large22.
Presently, only a few studies on early warning of emerging infectious diseases are available. Li et al. 23 extracted the features from historical medical records of various known diseases and constructed a disease probability map. When the probability of a new patient, becoming infected by each known disease type, is less than the threshold set by each known disease, the case of emerging disease types is evident. Although this method considers different diseases independently, it ignores the complexity of the diseases in real medical scenarios. Currently, thousands of common diseases are known, and the relationships among them are complex. Thus, even if the training covers various known diseases, the complex relationship among them has not yet been effectively accounted for by the existing machine-learning-based prediction models. In our previous study 24, we used 20,620 real infectious disease datapoints obtained from a large hospital from 2012 to 2022, including outpatient and inpatient sample data, to construct a multi-infectious disease diagnosis model (MIDDM) and obtained 740,000-dimensional feature data, and then performed model training after a sparse data densification processing. In addition, a residual network and an attention mechanism were introduced into the MIDDM to improve the model performance. However, due to the large feature dimension of this method (obtained after the one-hot encoding), the dense expression vector needs to be calculated first through the dense network and finally judged by the classification model. Thus, numerous model parameters are involved in this complicated process. Further, the prediction time has a remarkable impact. The prediction time for a single medical record reaches 68 ms, and the average response time is higher than 400 ms when the number of concurrencies is 100.
Therefore, to realize an effective early warning strategy for emerging infectious diseases via data monitoring, it is necessary to develop an automated monitoring approach that overcomes the issues related to manual monitoring, which involves event and statistical analyses and solely relies on manual reporting of symptoms. In this study, we used a hierarchical model to assess the probability of a single sample being an emerging infectious disease case, and combined the proposed model with the Knox method to analyze clusters. The method considers the case attributes as well as rapidly determines the probability of occurrence of infectious diseases. Further, to achieve data source tracking with high fidelity, it is necessary to utilize the complete existing data of hospitals in combination with real cases for monitoring. In this study, all the medical records obtained from multiple medical institutions were used, and the data time information was retained through time sequencing. To solve the problem of low performance caused by dimension explosion after one-hot coding in the early stage, we adopted the word vector model, word2vec, for data pretraining. Combined with the LightGBM model, word2vec can directly read the word vector in the subsequent model training without the need to calculate the dense vector expression of the current input to improve the prediction efficiency.
Materials and methods
This section describes the selection of datasets, data preprocessing, model architecture, classification methods, performance evaluation methods, experimental tools and setup, and validation methods. Figure 1 depicts the artificial intelligence process proposed here for the surveillance of emerging infectious diseases.

Proposed approach.
Dataset selection
The data were obtained from five medical institutions in Beijing, China: three in the Haidian District (Headquarters hospital, North hospital, and Party School hospital), one in the Shunyi District, and one in the Daxing District. The location distribution meets the spatial heterogeneityspatial heterogeneity requirement 25. ‘Spatial-specific’ refers to characteristics that distinguish things or phenomena in each spatial location from those in other locations. The medical data of five institutions, including all outpatient, emergency, and inpatient data obtained from January 1, 2012 to December 31, 2021 related to the 59 infectious diseases 26 highlighted by the China Center for Disease Control and Prevention, are considered. By matching the diagnosis name with the ICD-10 code, all the diseases and sub-diseases belonging to the infectious disease category were included in the dataset, and senior medical experts removed some non-infectious sub-diseases such as thyroid tuberculosis and renal tuberculosis. In order to obtain high-quality training data, names such as diseases and symptoms were standardized and the associated data were verified and subjected to an integrity check. Finally, 37,422 and 9,325,680 cases of infectious and non-infectious diseases, respectively, were identified as listed in Table 1. Some infectious diseases, such as pestis, did not occur, and hence, they are not listed in this table.
Owing to the large difference in the number of infectious and non-infectious diseases, stratified sampling was conducted. Most infectious diseases belong to obvious categories (e.g., most of them are respiratory, skin, or digestive diseases), while a few of them are related to orthopedics. Therefore, stratified sampling was carried out based on the departments from which the samples were obtained. For example, if pulmonary tuberculosis belongs to the respiratory department, then the other diseases identified in the data obtained from the respiratory department, such as pneumonia, lung cancer, chronic obstructive pulmonary disease, and bronchiectasis, are randomly selected. In addition to restricting the selection of medical records on non-infectious diseases obtained from the departments where the infectious diseases are evident, we also conducted random down-sampling of the non-infectious diseases. This step enabled the inclusion of a relatively small number of medical records on non-infectious diseases, and the number of non-infectious-disease medical records used as the training samples was 1.5 times that of the infectious cases. After the stratified and random down-sampling, 56,133 cases of non-infectious diseases were finally included. The screening process of the patients’ medical records is illustrated in Fig. 2.

Flowchart of enrollment.
To ensure maximum utilization of the information on important factors related to infectious diseases, the data used in the training model include basic patient information, time information, spatial information, patient medical records, and so on as presented in Table 2. Notably, to prevent information leakage during model training, we eliminated the test items that can clearly indicate the type of infectious disease in the test report, e.g., the new coronavirus nucleic acid test items in the medical records of COVID-19 patients. The diagnosis was used as the label of the sample; the work and home addresses were used as the key information to trace the address of the infectious disease patient; and the remaining extracted fields were used as the input features of the subsequent diagnosis model.
Data preprocessing
Data extraction
Electronic medical records mainly include data in both structured and unstructured (free text) formats. The patient's basic information, diagnosis, outpatient diagnosis, and test report form the structured data of the electronic medical record, while the admission record, outpatient medical record, and examination report become the unstructured data.
Structured data directly extracts the value of the corresponding field from the electronic medical record. Specifically, information such as age, age unit, visit time, home address, and work address are extracted from the front page of the medical record; information such as the patient's diagnosis name and code are extracted from the home page or outpatient diagnosis; inspection time, inspection value, inspection scope, and other information are obtained from the report page. Then, abnormal value processing, number normalization, and standardization are carried out for continuous variables; for example, the abnormal value processing of age will filter out the ones that deviate from the normal age range. Then, according to the different age units (year, month, week, etc.), the age value is uniformly converted into the age unit; each inspection result in the inspection report is classified as “high,” “low,” or “normal” according to their normal value range. In addition, the extracted discrete variables such as diagnosis name and inspection sub-item name are unified into standard names according to the mapped relationship between the aliases and standard names in the knowledge base. Finally, the processed field data are sorted into a text sequence.
For unstructured data, it is first necessary to extract information such as the chief complaint of the admission record, inspection conclusions, and inspection findings in the inspection report 27,28. In this case, we extract various entities (such as time, symptoms, diseases, signs, drugs, inspections, etc.), and then standardize each entity based on the British Medical Journal’s Best Practices 29 knowledge base, and finally obtain a data sequence. Subsequently, all the data sequences extracted from the patient's medical record are spliced according to the order of the document and inspection times to finally form the patient's input sequence for the model. The text merging process is illustrated in Fig. 3.
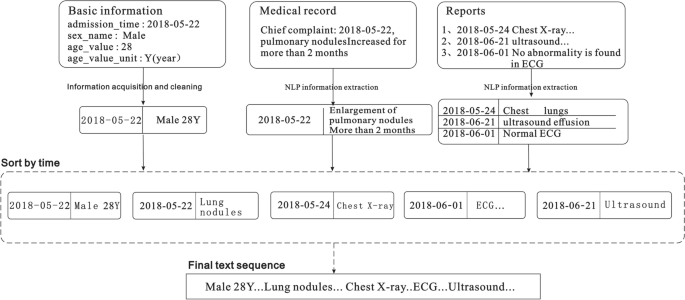
Extraction and serialization of information from electronic medical records.
Data vectorization
To use the above-mentioned serialized data to train the model, it is also necessary to vectorize the sequence text and convert each word in the sequence into a "computable" and "structured" vector before including the data into the model as input. Word2vec, a relatively common tool for training word vectors 30, can transform words into dense, low-dimensional real value vectors, which capture useful syntax and contextual semantics 31. Therefore, we used the Skip gram in word2vec to train the word vector model. Before training the word vector, each word in the input sequence is assigned a unique identifier to identify the word. This identification number is based on the sequence of word frequency in the corpus, and the word is labelled with the highest frequency; for example, the word "male" is assigned a unique identification number < 360 > . In this study, the typical numerical values in the medical records were spliced into a new word by connecting the names, values, and units, and then a unique identifier was assigned to the spliced output; for example, "alkaline phosphatase 102 U/L" is assigned a unique identifier 891. Therefore, the Chinese word sequence is converted into a word index sequence. Then, the word vector model is trained based on the obtained word index sequence. When training the word vector model, we set the word vector dimension to 100, and a window size of 5 is adopted. In addition, considering that the time complexity of the Skip gram is expressed as window size × thesaurus size, a large number of words in the training set increase the computation time. Therefore, we set min_ count = 2 in the model, and ignore the low-frequency words that only appear once or twice.
When vectorizing sequence data, we first calculate the length of all the input sequences and denote the length L of its 98% quantile as the final length of each sequence data. Then, each input sequence is truncated and filled with 0. Next, the unique identifier corresponding to each word in the sequence is converted into a word vector representation according to the trained word vector object. Finally, all the word vectors are spliced together to form an input vector of length L × 100. The process of converting medical records into a vector is depicted in Fig. 4.

Word vector conversion.
Unbalanced dataset processing
To alleviate the impact of data imbalance on the model results, down sampling was performed in the first layer model in this study. The number of medical records on non-infectious diseases is 1.5 times of that on infectious diseases. In the training of the two-layer model, we added category weight processing to provide categories with fewer samples a higher calculation weight, expressed by formula (1), and use them extensively for model training:
where \({w}_{k}\) represents the weight of the \(k\) class, \({N}_{all}\) represents the total number of samples in the dataset, \(C\) denotes the total number of categories (\(C\) = 8), and \({N}_{k}\) represents the number of samples of the \(k\) class. When the weight is not changed, the weight for each category is represented by the average attention degree (\(1/C\)), and the weight calculation formula satisfies:
Category weight × proportion of the number of category samples in the total dataset = Average attention.
Proposed EIDDM architecture
In this study, we mainly used the EIDDM (TextCNN-Attention + LightGBM), a regional clustering analysis, and symptom association of medical staff to predict the outbreak of emerging infectious diseases. Although no current case of emerging infectious diseases such as SARS, COVID-19, monkeypox, etc., was analyzed in this study, their performance is similar to that of the known infectious diseases; further, their characteristics are similar to those of regional clusters of infectious diseases. Therefore, we used a two-layer model to predict the number of people infected with suspected emerging infectious diseases, and then used their contact addresses to evaluate the possibility of existence of regional clusters. The EIDDM flow is shown in Fig. 5. Finally, through the symptom association analysis of medical staff, we assessed the probability of "human-to-human transmission.". The results of the analysis of interpersonal association transmission 32,33,34 are expected to promote further follow-up epidemiological studies on transmission routes, gene sequencing, and prevention and control programs.

EIDDM flow.
First layer of model with TextCNN-attention
Because of the large amount of medical record data and high-dimensional feature sequence text data in the first layer model used in this study, the model selects the text-based convolutional neural network TextCNN for classification. This network considers both convolution extraction and timing. The word embedding features of the long text sequences are composed of admission records, and thus, the inspection and testing documents have different effects on the classification results. The features that have a greater impact on the model decision are given a greater weight of attention via the Multi-Head Attention mechanism, and then the key and interference features of the text can be distinguished. Therefore, the introduction of the Attention mechanism in TextCNN can effectively enhance the feature extraction capability of the model.
First, zero-padding is used for the filling to ensure that the length of the input feature sequence is consistent in the model. The final maximum sequence length is L (L = 5061), indicating that the input sequence size is 5061 (after the operation: word vector layer × 100). After the word embedding layer, a word embedding matrix with a size of 5061 × 100 is formed. The parameters of the word embedding layer are initialized using the Skip-gram method. Notably, one-dimensional convolution is used in this convolutional neural network. We consider the number of samples, hardware equipment performance, model complexity, case data characteristics, and other factors, and use the grid search 35 method to set multiple values for the same parameter in different value domains and magnitude ranges in descending order. By comparing the accuracy of the trained model using the test set, five filters with dimensions of 1 × 100, 2 × 100, 3 × 100, 4 × 100, and 5 × 100 are set. After the convolution layer, five convolution expressions, L × 100, (L-1) × 100, (L-2) × 100, (L-3) × 100, and (L-4) × 100 are obtained, respectively. Then, we add the max pooling layer to reduce the dimensions of the filter-layer features and splice the pooled vectors; the spliced dimensions are 500. The reduced-dimension spliced pooled vectors are input into the Muti-Head Attention layer with multi-head parameter = 8 and head_dim parameter = 16. Then, we connect a residual (size: 500) with the normalization layer. Finally, the vector is expanded, and in order to prevent overfitting, the dropout loss mechanism is used as the input of the sigmoid layer. The structure of the first layer of the EIDDM is shown in Fig. 6.

First layer of the EIDDM-TextCNN-Attention model.
Second layer of EIDDM with LightGBM
Should the first layer of evaluation indicate the presence of an infectious disease, the medical record text sequence is then transformed into Term Frequency-Inverse Document Frequency (TF-IDF) values, which are subsequently inputted into a secondary model for assessing whether the sequence constitutes an emerging infectious disease. TF-IDF serves as a textual vectorization representation method. Term Frequency (TF) computes the frequency of occurrence of a specific term within the current medical record and normalization. Inverse Document Frequency (IDF) is used to ascertain whether a term is prevalent across multiple medical records. If a term appears frequently in numerous medical records, it is likely to be a common term with lower discriminatory power across the entire corpus of medical records. TF-IDF is the product of multiplying TF and IDF. It combines the importance of each term within the current medical record with its significance in the overall corpus of medical records. For terms that appear frequently in the current medical record but infrequently in the entire corpus, the TF-IDF value is higher, emphasizing their significance within the current medical record. Through TF-IDF transformation, the input text sequence is represented as a vector.
Multi-classification algorithms such as random forest, XGBoost, and LightGBM are decision tree-based ensemble classifiers, and as a result, their prediction accuracies are higher than that of a single decision tree model. The efficiency and scalability of XGBoost and random forest are not ideal for data with a large sample size and high feature latitude, because during the splitting of the tree nodes, they need to scan the eigenvalues of each feature to locate the optimal cut points, which is a time-consuming process. To solve the above problems, LightGBM proposed gradient-based one side sampling and exclusive feature bundling (EFB) to sample and reduce the feature dimensions, respectively. LightGBM can focus on the "not fully trained" sample data during the model training. Simultaneously, a histogram algorithm is used to accelerate the search for segmentation points, and large-scale data are input into the histogram; this step reduces the feature memory size and accelerates the model training.
In addition, for category features, on-hot coding is employed by gradient boosting decision tree GBDT, XGBoost, and random forest. However, one-hot coding is easy to overfit, and the tree is relatively deep to achieve better results. LightGBM uses the EFB algorithm to optimize the support of the category features. Through the combination of sparse features and binding of mutually exclusive features, the category features can be directly input without any additional 0/1 expansion, and this process further optimizes the training speed of the model. Therefore, considering the time, memory, accuracy, and other aspects, LightGBM with a fast iteration speed and strong interpretability is selected as the second layer of the classification model used in this study, and the prediction performances of random forest and XGBoost are compared.
The objective of this study is to identify emerging infectious diseases, where "emerging" indicates that the disease category was not present in the current training dataset. In order to perform this identification, the study employs the One vs. Rest strategy 36. For the N categories present in the training dataset, N LightGBM models are trained, with each model undertaking a binary classification task. During the prediction phase, an initial threshold is established. Novel test samples undergo probability calculations through individual binary classifiers. If the computed probability surpasses the threshold, it indicates membership in a singular category; conversely, probabilities below the threshold suggest membership in the remaining categories. In cases where the predictive probabilities from all classifiers are below the threshold, indicating that all N models collectively classify the test sample into non-target categories—meaning the sample is dissimilar to any of the infectious disease categories currently included in the models—it is inferred that the sample pertains to an emerging infectious disease. We substantiate the validity of the One vs. Rest approach for recognizing novel categories by using a spatial ensemble methodology. Specifically, assume that the current training set contains three categories, A/B/C, and the test sample X. Then, three dichotomous OvR experiments are conducted: (1) A / R(BC), (2) B / R(AC), (3) C / R(AB). Finally, three models, viz. Model-1 (M1), Model-2 (M2), and Model-3 (M3), are obtained through the training. For the test sample X, the probability P (A | M1) that X belongs to category A, the probability P (B | M2) that X belongs to category B, and the probability P (C | M3) that X belongs to category C are obtained using the model. Finally, X is judged based on the set threshold and results of the three models.
For the above-mentioned process, the following condition is assumed:
where \({(\mathrm{BC})}_{\mathrm{M}1}\) represents the space area of category R(BC) divided by the decision boundary of M1 in the current feature space. The division methods of \({(\mathrm{AC})}_{\mathrm{M}2}\) and \({(\mathrm{AB})}_{\mathrm{M}3}\) follow a similar process. Figure 7 (a), (b), and (c) represent the test results of the three models (shown in a two-dimensional space), respectively. The red line represents the decision boundary obtained from the model training, and the yellow point represents the feature space of the test sample X. When X is predicted as category R (BC), R (AC), and R (AB) by each model, it is judged as a new category. As shown in Fig. 7 (d), when sample X is located in the intersection area of the three R categories, it represents a new category that does not belong to A/B/C. However, when the decision boundary of each model completely cuts the feature space (i.e., there is no intersection area in the R category space of each model, as shown in Fig. 7 (e)), the sample X must belong to one of the A/B/C categories, and thus, it cannot be labeled as a new category.

OvR strategy-based identification of test results for new categories (illustrated in a two-dimensional space).
In summary, the identification of new categories using the OvR strategy depends on the condition that an intersection exists between the R category regions of each model; that is, formula (2) must be satisfied. In the current experiment, the TF-IDF data feature is a high-dimensional space of 84,411 dimensions, and the probability that the decision boundaries of each model partially overlap or are perfectly cut is extremely small. Therefore, these experimental results satisfy the assumption of formula (2), and the OvR strategy-based new category identification method can be implemented in this model.
Regional cluster analysis
Using the EIDDM, we can determine the probability of a single case sample being an emerging infectious disease. The time series data obtained from the simultaneous spatiotemporal monitoring of infectious diseases are integrated into the complete patient record in the two-layer model, which meets the requirements of time monitoring. We also need to consider the spatial cluster analysis of the family and work addresses in the patient record to reduce the occurrences of positive false results for single case prediction in real applications of this model in medical institutions. In epidemiology, clustering of infectious diseases is a common phenomenon. Presently, statistical methods, including flexible spatial scanning statistical analysis 37, Rogerson spatial pattern-based analysis method 38, Knox method that uses only the spatiotemporal information of the cases 39, and so on, are widely employed for the detection of spatial clusters of infectious diseases. The flexible, Rogerson, and Turnbull methods first divide the whole research area into multiple sub-regions for the analyses and require population data of each sub-region, including the total population and migration data. In practice, it is difficult to select the most appropriate sub-region division method for the study area; therefore, the above three methods are not applicable in this study. The Knox method does not need to divide the whole region into molecular regions; moreover, it does not require demographic data of sub-regions as input parameters. Instead, this method only requires the case information and spatiotemporal data without control group and susceptible population data 40. The Knox method is a global test method for evaluating spatiotemporal aggregation and analyzes the location and time of the disease onset. The test statistic \(X\) is the number of case pairs that are close in space and time and is represented by formula (3); its expected formula is expressed as formula (4).
where N is the number of cases; \({a}_{ij}^{s}\)= 1 if the cases i and j are similar in space, and \({a}_{ij}^{s}\) = 0 if the cases are dissimilar; \({a}_{ij}^{t}\) = 1 if the cases i and j are similar in time, and \({a}_{ij}^{t}\) = 0 if the cases are dissimilar; and s and t represent the prespecified space and time distances, respectively. If the difference between X and its expected E is statistically significant, then there exists a spatiotemporal clustering feature. We calculate the onset date and case space distances of the case pair. If these distances are less than the prespecified time and space threshold, then a "near" case is obtained. The prespecified time threshold is the incubation time of each infectious disease, and the prespecified space threshold is 200, 500, 1000, 2000 m, and other different intervals. We count the number of cases with "near" statistical time \({N}_{t}\) as well as those with "near" distance \({N}_{s}\).
When acquiring the spatial data, we first collect the detailed contact address, home address, work address, and other information of the people suspected to be infected with emerging infectious diseases from the patient's personal information. Second, we the longitude and latitude of each address of the patient as the coordinate datapoint of the patient from the China Gaode Map Service 41; for example, the longitude and latitude of the contact the address "Peking University, No. 5, Yiheyuan Road, Haidian District, Beijing" is (116.310905,39.992806), which was obtained from the map of Gaode.
Most early studies on the statistical Knox method were focused on extracting approximate values using methods such as Poisson distribution, Barton–David method, Monte Carlo method, and so on. However, in this study, the Monte Carlo method was used for analyzing the test statistics \(X\) 42. We performed several random simulations, and in each simulation, the \(X\) cases are randomly marked as N occurrences. Further, the reference distribution is obtained by calculating the test statistics of each random number. The specific steps of this method are as follows:
Calculate the actual statistics \(X\) of the original dataset;
The spatial distance between case pairs is fixed, whereas the time distance is rearranged to generate a new random dataset;
Recalculate the statistics for randomly rearranged datasets;
The calculation was repeated 999 times for each infectious disease, and 999 new statistics were obtained;
Count the number of each new statistic and arrange it in ascending order according to the size of the new statistic;
Estimate of \(P\)-value as shown in formula (5).
where \(k\) ≥ \(X\) in the new statistics, and \(N\) is the total number of new statistics.
Finally, the \(P\)-value is compared with the threshold of 0.05. If \(X\) > \(E\), then we obtain \(P\)-value < 0.05, which indicates that the case has spatiotemporal aggregation.
Early warning of doctor, nurse, and patient association symptoms
For the case when the classification model predicts the onset of an emerging infectious disease, an algorithm for symptom related monitoring of medical personnel is proposed to aid in hospital infection management and epidemic prevention and control. First, we use formula (6) to identify the occurrence of an infection among the medical staff, and then use formula (7) to determine whether the infection value exceeds the expected infection value. If it exceeds the expected infection value, then we focus on monitoring the current target patients and medical staff receiving treatment, so that public health experts can intervene to assess the possibility of "human-to-human" transmission of emerging infectious diseases. According to the initial time point, contact times, and contact status of the target patients and their medical staff, the occurrence of the same symptoms in doctors and nurses is deduced within seven days after receiving the treatment to enable an epidemiological analysis.
Initially, the symptom sets of patients with Emerging Infectious Diseases predicted by the hierarchical diagnostic model, were categorized as H = {\({h}_{1},{h}_{2}\)…\({h}_{j}\)}. For the primary care physicians of the target patients, a symptom vector V and a set of symptom vector values {\({v}_{1}\),\({v}_{2}\dots {v}_{j}\)}were created using data from the patients' medical records at the time of first contact. For the secondary contact connection between the initial contact medical staff and the remainder of the medical staff in the same department, the symptom vector U and symptom value vector set {\({u}_{1}\),\({u}_{2}\dots {u}_{j}\)}were built. We calculated the highest frequency symptom using term frequency–inverse document frequency (TF-IDF) for the sets H, V and U, and recorded it as \({a}_{1}.\) The symptoms with the highest frequency \({r}_{i}\) were recorded as prominent symptoms, and other symptoms were recorded as concomitant symptoms. The reference symptom vector K and the corresponding symptom value vector set{\({k}_{1},{k}_{2}\dots {k}_{\mathrm{j}}\)} of the emerging infectious diseases are set according to the clinical observations. Zhu et al. 43 used the Pearson correlation coefficient to measure the correlation between the symptoms and calculate the difference relationship between the target patient H and the medical staff (\(U\cup V\)) as well as preset the reference symptom K. In this case, the Pearson correlation coefficient \(1-|p|\) is the difference factor \(\partial\). If this is not the case, then the difference factor \(\partial\) is 1, indicating that the symptoms are not similar. If all the difference factors \(\partial\) satisfy the condition \(1>\ge 0\), then the symptoms are similar (\({n}_{1}\) represents the total number of similar symptoms; \({n}_{2}\) represents the total number of non-similar symptoms of the target patient \({h}_{i}\); and \({n}_{3}\) represents the total number of non-similar symptoms of the corresponding medical staff).
Formula (6) is used to calculate the infection value \(Y\), which includes the calculations of both similar and dissimilar symptoms. Experts can determine whether to include the dissimilar symptoms in the calculation of the infection value to set the evaluation parameters \(\varepsilon \). If the dissimilar symptoms are included, then the value is 1; otherwise, 0.
where \(s_{i0}\) represents the vector value of the \({i}_{th}\) similar symptom based on the target patient; \(s_{i1}\) represents the vector value of the \({i}_{th}\) similar symptom based on the medical staff; \(s_{j0}\) represents the vector value of the symptom based on the \({j}_{th}\) dissimilar symptom index of the target patient; \(\varepsilon_{j0}\) represents the evaluation coefficient based on whether the \({j}_{th}\) dissimilar symptom index of the target patient has a reference value; \(s_{j1}\) represents the vector value of the symptom based on the \({j}_{th}\) dissimilar symptom index of the medical staff; \(\varepsilon_{j1}\) represents the evaluation coefficient based on whether the \({j}_{th}\) dissimilar symptom index of the medical staff has a reference value; and \(\sum \partial\) represents the cumulative sum of the difference factors corresponding to each prominent symptom.
The determined infected value indicates the possibility of an associated infection risk between the patient and the medical staff. Further, calculating the deterioration probability P metric of the corresponding medical staff according to certain prominent symptoms of the staff is essential to assess the current risk, reduce the large amount of interference monitoring caused by more common symptoms, and focus on the medical and nursing population beyond the research and judgment of public health experts. The calculation formula of deterioration probability \(P\) is expressed as (7):
where \(Y_{0}\) represents the left boundary value of the infection level corresponding to \(Y\); \(Y_{1}\) represents the right boundary value of the infection level corresponding to Y and \(Y_{0}\) is less than \(Y_{1}\). The boundary values \(Y_{0}\) and \(Y_{1}\) are determined by experts according to historical conditions. The parameter \(\sum R\) is the total influence factor of all the corresponding prominent symptoms that deteriorate the health of the patient, and the value is determined based on the prominent symptoms \({r}_{i}\) determined by the experts; typically, the value is in the range of (\(\mathrm{0,1})\). Further, in formula (7), \(m1\) represents the total number of corresponding prominent symptoms; and \(\Im\) indicates the adjustment parameter when \(\left| {Y - Y_{0} } \right| \le \left| {Y - Y_{1} } \right|\) (\(\Im = 0.2\) for \(\left| {Y - Y_{0} } \right| \le \left| {Y - Y_{1} } \right|\); otherwise, \(\Im\) = \(\{\mathrm{0,1}\}\)). We compare the results of hierarchical monitoring according to the deterioration probability \(P\) and preset probability \({P}_{0}\). Evidently, if P > P0, then we should focus on monitoring the corresponding medical staff. In the opposite case, we should conduct a routine monitoring of the corresponding medical staff.
Performance evaluation
Given the absence of authentic test medical records for emerging infectious diseases in practical settings, this study hypothetically designated various known infectious diseases as emerging infectious diseases and excluded them from the training dataset during model construction. Subsequently, these hypothetical medical records for the designated infectious diseases were used as test cases for emerging infectious diseases in the well-trained model in order to evaluate the model's predictive capabilities. The prediction process of the EIDDM model comprises two stages: first, the first layer model is employed to determine if the case is an infectious disease; if it is, then the secondary layer model is invoked to determine whether it is an emerging infectious disease or not. As a result, it is essential to assess the accuracy of the first layer model in predicting infectious diseases and the accuracy of the secondary layer model in predicting emerging infectious diseases separately. The evaluation method of the first layer model is presented in Table 3.
In Table 3, \(k\) indicates that the Kth infectious disease is predicted as an emerging infectious disease; \(T{P}_{1k}\) indicates that the real medical record is an infectious disease, and the model correctly predicts the number of samples for the infectious disease; \(F{P}_{1k}\) indicates that the real medical record is a non-infectious disease, and the model incorrectly predicts the number of samples for the infectious diseases; \(F{N}_{1k}\) indicates that the real medical record is an infectious disease, and the model incorrectly predicts the number of samples as non-infectious disease; and \(T{N}_{1k}\) indicates that the real medical record is a non-infectious disease, and the model correctly predicts the number of samples for the non-infectious diseases. The accuracy, sensitivity (\(T{PR}_{1k})\), and \({FNR}_{1k}\) of the first layer model prediction are evaluated using formulae (8)–(10), respectively:
The proportion of non-infectious diseases in the medical records correctly predicted as non-infectious diseases is referred to as specificity (\({Specificity}_{1k}\)) or true negative rate (\(T{NR}_{1k}\)). Conversely, the rate at which non-infectious diseases are erroneously predicted as infectious is known as the false positive rate. The formulae for calculating specificity and false positive rate are as follows:
Furthermore, it is necessary to assess how many of the diseases identified by the model as infectious diseases are truly infectious diseases, which is known as the positive predictive value (\({PPV}_{1k}\)). Its calculation formula is as follows:
Here, "\(T{P}_{1k}+F{P}_{1k}\)" represents the total number of medical cases predicted as infectious diseases in the first layer.
In the set of model predictions for non-infectious diseases, it is essential to determine how many are truly non-infectious diseases, referred to as the negative predictive value (\({NPV}_{1k}\)). Its calculation formula is as follows:
Here, "\(T{N}_{1k}+F{N}_{1k}\)" represents the total number of medical cases predicted as non-infectious diseases in the first layer.
Among the subset of cases predicted as infectious diseases by the first layer (\({TP}_{1K}\) and \({FP}_{1K}\)), the second layer model is subsequently employed to predict whether they are emerging infectious diseases. Assume that for true medical records classified as emerging infectious diseases, the second layer model correctly predicts \(T{UK}_{2k}\) samples as emerging infectious diseases and incorrectly predicts \(F{K}_{2k}\) samples as non-emerging infectious diseases. For true medical records classified as non-infectious diseases, the secondary layer model incorrectly predicts \(F{UK}_{2k}\) samples as emerging infectious diseases.
The sensitivity of the second layer model for the Kth emerging infectious disease, denoted as Sensitivity2k (also referred to as True Positive Rate), represents the proportion of correctly predicted emerging infectious disease cases in the medical records of this emerging infectious disease. Conversely, the false negative rate (\(F{NR}_{2k}\)) represents the proportion of cases from this infectious disease category that was incorrectly predicted as non-emerging infectious diseases. The formulas for calculating sensitivity and \(F{NR}_{2k}\) are as follows:
Here, \({TUK}_{2k}\) + \({FK}_{2k}\) = \({TP}_{1k}\) represents the total number of medical records for the \({K}_{th}\) emerging infectious disease that were correctly predicted as infectious diseases by the first layer.
In the second layer model, true medical records categorized as non-infectious diseases are incorrectly predicted as infectious diseases. Hence, the specificity is 0, and \({NPV}_{2k}\) is also 0. The false positive rate is divided into two components, with one being predicted as emerging infectious diseases and the other as non-emerging infectious diseases. The false positive rate for being predicted as emerging infectious diseases is calculated as given in Formula (17).
Here, \({FUK}_{2k}\) + \({FK}_{2k}\) = \({FP}_{1k}\), representing the total number of medical records for non-infectious diseases that were incorrectly predicted as infectious diseases by the first layer.
EIDDM combines the overall accuracy of the two layers, denoted as \({A\mathrm{ccuracy}}_{k}\), which represents the ratio of correctly predicted medical records for emerging infectious diseases and non-infectious diseases to the total number of test medical records. Specifically, the number of correctly predicted medical records for emerging infectious diseases is \({TUK}_{2k}\), while the number of correctly predicted medical records for non-infectious diseases is \({TN}_{1k}\), which is the count of cases correctly predicted as non-infectious diseases by the first layer. Therefore, the formula for calculating the overall model accuracy is as follows.
By considering the first layer as well as secondary prediction models, we can derive \({Sensitivity}_{k}\), also known as true positive rate (\({TPR}_{k}\)), for the Kth infectious disease. TPR represents the proportion of correctly predicted emerging infectious disease cases within the medical records of that specific infectious disease. Conversely, the false negative rate (\({FNR}_{k}\)), which is the rate of cases from the emerging infectious disease category being incorrectly predicted as non-infectious diseases or known infectious diseases, is calculated as given below:
As non-infectious diseases are predicted as non-infectious diseases only in the first layer model, whereas they may be predicted as either emerging infectious diseases or non-emerging infectious diseases in the secondary layer, the proportion of correctly predicted non-infectious disease cases within all non-infectious disease medical records, referred to as \({Specificity}_{k}\) (also known as true negative rate, \({TNR}_{k}\)), remains identical to the Specificity of the first layer, denoted as \({Specificity}_{1k}\).
Conversely, within the set of cases predicted as non-infectious diseases, the true rate of non-infectious diseases, known as negative predictive value (\({NPV}_{k}\)), is also equivalent to the NPV of the first layer model, denoted as \({NPV}_{1k}\).
For the EIDDM model's predictions of emerging infectious diseases, the positive predictive value for true emerging infectious disease cases, denoted as \({PPV}_{k}\), is used as the result for the secondary layer, which is also equivalent to \({PPV}_{2k}\). The false positive rate is divided into two components, with one being predicted as emerging infectious diseases while the other as non-emerging infectious diseases. The false positive rate for cases being predicted as emerging infectious diseases is calculated as below:
Ethical approval
The study was approved by the Medical Science Research Ethics Committee of Peking University Third Hospital (serial number: IRB00006761-M2022287). All methods were performed under the relevant guidelines and regulations. The informed consent was waived by Peking University Third Hospital.
Results
Model parameter setting
The super parameter setting has a great impact on the accuracy of the model. Therefore, the grid search method was adopted in this study. The parameter search method uses a large step size for a rough search. After the parameters are preliminarily determined, a small step size is used for a fine search near the parameters. The optimal parameters are searched from the value range of each parameter by iteration. In this study, 520 batches were used for training, and the learning rate was set as 0.001. We set early_stopping_rounds to prevent overfitting by the model, and the corresponding optimal parameters are shown in Table 4.
The second layer model uses LightGBM and compares the prediction performances of the XGBoost and random forest models. Each algorithm performs a grid search to optimize the model parameters. The main adjusted parameters and their optimal results are listed in Table 5.
Model results
The testing process first inputs the case into the first layer model to identify whether it is an infectious disease. If it is an infectious disease, then the input is sent to the second layer model to identify whether it is an emerging infectious disease. Finally, we calculate the accuracy of predicting emerging infectious diseases and non-communicable diseases, the sensitivity of emerging infectious diseases being correctly predicted, as well as the false positive rate and false negative rate. The results of the first layer model (TextCNN-Attention) are shown in Table 6.
Based on the experimental results of the first-layer model, it can be observed that the sensitivity for predicting infectious diseases such as scarlet fever and infectious gastroenteritis exceeds 90%, while other infectious diseases can be predicted with a sensitivity of over 60%. The average specificity for non-infectious diseases is 97.57%, with an average negative predictive value (\({NPV}_{1k}\)) of 82.63%, indicating a low risk of misdiagnosing non-infectious diseases as infectious (false positive rate). The average positive predictive value for the eight infectious diseases (\({PPV}_{1k}\)) is 95.07%, demonstrating the model's ability to avoid "misdiagnoses." The overall average accuracy of the model is 86.11%. Thus, the first-layer model proves effective in predicting infectious as well as non-infectious diseases.
The cases denoted as infectious diseases by the first layer model are sent to the second layer model, which identifies whether they are non-emerging or emerging infectious diseases. The second layer model was tested using the LightGBM, XGBoost, and Random Forest algorithms, and the corresponding test results are presented in Table 7.
A comparison between the emerging-infectious-disease-prediction accuracies of the three algorithms shows that the performance of LightGBM is better than that of XGBoost, except for viral hepatitis and COVID-19. Furthermore, the infectious-disease-prediction accuracy of LightGBM surpasses that of the Random Forest algorithm, except for tuberculosis. The average prediction sensitivities of LightGBM, XGBoost, and Random Forest are 90.44%, 87.43%, and 86.90%, respectively, indicating that LightGBM is the best algorithm for the proposed model. According to the LightGBM test results listed in Table 7, the accuracy rate of predicting infectious diseases as emerging infectious diseases is substantially higher than the misjudgment rate of non-emerging infectious diseases. Therefore, the second-layer model can reliably distinguish between non-emerging infectious diseases and emerging infectious diseases. The misjudgment rates for predicting hand-foot-and-mouth disease, infectious diarrhea, and scarlet fever as known infectious diseases are relatively high at 24.8%, 22.78%, and 25.86% respectively, but they are also much lower than the rates for correctly predicting emerging infectious diseases, so the model is still capable of providing early warnings for these emerging infectious diseases. The accuracy of EIDDM is listed in Table 8.
In summary, the overall false positive rate is relatively low owing to the first layer model already excluding a large number of non-infectious cases. Consequently, the second layer decision-making process avoids the misclassification of non-infectious diseases as emerging infectious diseases. The mean value of the overall accuracy is 83.47%. In conclusion, the first layer model TextCNN-Attention and the second layer model LightGBM demonstrate strong discriminative capabilities for distinguishing between infectious and non-infectious diseases, as well as between non-emerging infectious diseases and emerging infectious diseases.
Model classification threshold
The model prediction threshold (set to 0.5 in this study) significantly influences the prediction results, and thus, different thresholds are set to evaluate the prediction performance. We increase the threshold of the one-to-many LightGBM model to 0.4 and 0.6, and compare the resulting prediction performance with that observed at a threshold of 0.5. The corresponding results are shown in Table 9.
Tables 7 and 9 suggest that when the threshold is 0.5, the average sensitivity, average false negative rate, and average false positive rate of emerging infectious diseases are 90.44%, 9.56%, and 50.26% respectively. When the threshold is 0.4, the average sensitivity, average false negative rate, and average false positive rate are 87.64%, 12.36%, and 45.60% respectively. We can see that when the threshold is lowered, the sensitivity as well as the false positive rate will decrease. When the sensitivity and the false positive rate decrease concurrently, this study chooses to retain the model with higher sensitivity; when the threshold is equal to 0.6, the average sensitivity is 91.16%, the average false negative rate is 8.84%, and the average false positive rate is 54.74%. We can see that the average sensitivity has increased by less than 1 percentage point, but the average false positive rate has increased by more than 4 percentage points. Therefore, the final threshold in this study was set at 0.5.
Results of spatial cluster analysis by Knox method
As indicated before, the EIDDM can effectively distinguish between infectious and emerging infectious diseases. However, the monitoring and early warning of infectious diseases also require spatiotemporal information. In the simple time-aggregation detection method, the time lags when the aggregation is discovered. In contrast, the time–space aggregation analysis uses the complete spatiotemporal data, and its prediction results are more accurate and are obtained in less time. Therefore, among the suspicious people who have been screened for carrying emerging infectious diseases by the EIDDM, it is necessary to identify the existence of a spatial cluster of the suspected emerging infectious diseases based on information such as time of detection of the infectious disease, home address, and work address.
Latent infected individuals play a greater role in transmission in the saturation stage of an epidemic 44. The incubation periods of each infectious disease analyzed in this study are shown in Table 10. The calculated test statistics \(X\) and expectation \(E\) at different intervals of D (200, 500, 1000, and 2000 m) are represented in Table 11, which shows many case pairs of influenza, viral hepatitis, and tuberculosis. Therefore, cluster analysis is conducted on 1000 cases of partial viral hepatitis that occurred in 2019, 500 cases of partial influenza that occurred in 2019, and 737 cases of tuberculosis that occurred in 2019.
When \(X\) = 0, there is no statistical significance, and the corresponding P-values are replaced by "-" in Table 12.
The null hypothesis is that there is no spatiotemporal cluster of emerging infectious diseases. Table 10 shows that the test statistics X are greater than their expected E, and the significance level of the usual hypothesis is 0.05. According to Table 12, except for scarlet fever, the P-values of all the emerging infectious diseases are less than 0.05. Accordingly, the null hypothesis is rejected; that is, except scarlet fever, the other emerging infectious diseases are likely to accumulate in time and space 45. By comparing the P -values with the calibration level of 0.05, it can be concluded that the spatial clusters of influenza occurs at 500 and 1000 m, those of the hand-foot-mouth disease occurs at 200 and 1000 m, and that of the viral hepatitis occurs within 500 m. In the case of COVIS-19, the spatial cluster occurred at 2000 m, indicating that although the new coronavirus has a strong infectious ability, the distance of 2000 m obtained in this study is a result of the controlled epidemic prevention policy of China. High-frequency nucleic acid screenings and a timely sealing and control prevent large-scale infections 46,47. Scarlet fever is within the range of 200, 500, 1000, and 2000 m, and its P-value is greater than 0.05, which may be caused by the deviation in the distance selection. The test statistic X and expectation E at the interval of 700 m are recalculated as 3 and 0.87, respectively. The P-value is 0.047, which is less than the inspection level by 0.05. These results reveal that all infectious diseases accumulate in time and space within 2 km.
Test results of the model’s response speed
In the performance test, all the infectious diseases and 1.5 times more non-infectious diseases are used as the training set, and a two-layer model is trained. The test results show that although the training process is computationally intensive, the model requires approximately 27 ms to analyze the case of a new patient . These results were obtained by using an Intel Xeon Gold 5117 CPU 14 core with a 64 Gb memory server under the Keras framework, which can aid in achieving a good response speed. Table 13 shows the performance test results of the model service. The test results of this study are compared with those of our previous MIDDM study 24, in which we used the one-hot coding method to classify the infectious diseases.
Discussions
Comparison and discussion of methods
The method proposed in this study, utilizing the TextCNN deep learning model, differs from the decision tree and naive Bayes single models employed by Prilutsky et al.48. The TextCNN model incorporates various convolutional layers to extract text features, enabling it to capture semantic characteristics at multiple levels. Furthermore, the model includes a multi-head self-attention mechanism, which assigns specific attention weights to features, resulting in more precise classification. To compare various models, we conducted a replacement experiment in the first layer model, where we used LSTM. The results are presented in Table 14. Based on the experimental comparison between the first layer TextCNN-Attention model and the LSTM model, we can observe that the LSTM model exhibits, on average, approximately 4% lower sensitivity and accuracy compared to the TextCNN-Attention model. In other words, the TextCNN-Attention model demonstrates better performance.
The second layer model, LightGBM, is an ensemble framework implementing the Boosting algorithm idea, combining multiple learners to achieve better generalization compared to individual learners. In contrast to disease probability graphs23 used for predicting emerging contagious diseases, the knowledge-graph-based approach heavily relies on prior knowledge and domain experts' experiences rather than direct learning from complete patient medical record data. This approach may be limited by data quality and completeness, leading to less comprehensive and accurate predictions. Furthermore, constructing knowledge graphs typically requires manual curation and annotation by domain experts, demanding substantial human resources and time for data collection, labeling, and validation. In contrast, machine learning models based on medical records utilize large-scale real-world healthcare data, enabling automatic learning of patterns and correlations without the need for extensive human intervention. We are currently testing integrated models such as LightGBM and XGBoost based on the Boosting strategy and Random Forest based on the Bagging strategy. In the future, we will consider further validating our experiments on linear and nonlinear models such as SVM49 as well as similarity-based models such as KNN50.
In recent years, major achievements have been made in Natural Language Processing (NLP) tasks through the use of large language models, such as the GPT model series introduced by OpenAI (e.g., GPT-2 and GPT-3) 51,52, and Google's BERT model53. These models often exhibit remarkable performance owing to their vast number of parameters, reaching billions, bestowing them with powerful language representation capabilities. However, these achievements also come with certain challenges and limitations. BERT and large language models require substantial computational resources and storage space for training and inference and also necessitate substantial investments in time and computational power for pre-training or fine-tuning. In contrast, TextCNN, combined with Attention, typically possesses a smaller model size and computational complexity, enabling model training under less resource-intensive conditions, while also providing faster response times during prediction.
In this study, the Knox method was employed because of its relatively simple principles, fast computation, and ease of result interpretation and explanation. Furthermore, Knox is a non-parametric method that does not assume data adherence to specific distributions, making it effective even when data distribution is unknown or does not follow specific distribution assumptions. Knox is also less sensitive to irregularly shaped geographic regions, ensuring that the analysis is not influenced by arbitrary geographical boundaries. Therefore, Knox can serve as an exploratory tool to detect potential spatial and temporal clusters in infectious disease data. Its convenience allows for quick and preliminary assessments, aiding researchers in deciding whether further investigation is warranted. The Knox method used in this study enables rapid monitoring of clustering within a 2-km range, providing more specific information compared to nationwide large-scale monitoring, and can identify areas of high priority for further investigation.
Unbalanced dataset processing
In this study, we first extracted all outpatient, emergency, and hospitalization data for ten years from January 1, 2012 to December 31, 2021. Therefore, the number of samples of non-communicable diseases was quite large. Considering the running time and storage issues, we first use the down-sampling method and select 1.5 times the total number of known infectious diseases as the initial enrollment samples of non-communicable diseases. However, owing to the large difference in the number of samples of various known infectious diseases, the issue of data imbalance for the first- and second-layer training samples in the experiment persists. In order to further improve this characteristic of the content, we can consider optimizing the following aspects in the future:
For minority samples, oversampling methods could be used to increase the sample size of minority categories, such as SMOTE54, ADASYN55, or Borderline-SMOTE56.
For most samples, over-sampling methods could be used to reduce the number of samples in most categories, such as Random Under sampling, Cluster Centroids, or Tomek Links.
Limitations
In this study, we developed a suitable model and used it to predict emerging infectious diseases by using medical records, time information, and spatial information as well as through a correlation analysis of the symptoms shown by doctors and patients. However, the proposed model exhibits several limitations as well: (1) The data sources used in this study were primarily sourced from several medical institutions, which can cover the epidemic situation in some areas of Beijing, China; however, it is still necessary to obtain information from cross-provincial medical institutions and further optimize the model. (2) The quality of medical records is affected by the writing style of the doctors, and some symptom results are expected to be missing from the medical records; these two factors affect the accuracy of the model. (3) The developed model, EIDDM, performed poorly when tuberculosis, syphilis, and such type of infectious diseases were used as the test data (medical records); therefore, because of misjudgment of non-infectious diseases or poor quality of medical records, the extracted characteristics are not accurate; this shortcoming needs to be mitigated via further optimizations in the future. (4) Owing to its primary reliance on convolutional operations to capture local features in text, TextCNN may exhibit insensitivity to certain text tasks that involve explicit word order and long-range dependencies. In contrast, BERT and large language models excel in modeling global semantics and capturing semantic relationships within the text through self-attention mechanisms. Therefore, in the future, when computational resources and storage space permit, further experimentation should be conducted to explore the feasibility of employing large language models and fine-tuning BERT for the task of infectious disease prediction. This approach is likely to enhance the modeling of complex textual patterns and semantic relationships, potentially leading to improved predictive performance in such tasks. (5) The association analysis of infection symptoms of medical personnel, proposed in this study, cannot be verified, because the original data that were clinically reviewed and determined as the transmission chain did not contain real medical data. Future studies should be designed to incorporate data from multiple medical institutions and to focus on the transmission chain data of infection symptoms by further verifying and optimizing the model attributes.
Conclusion
The emerging-infectious-disease-prediction framework proposed here is the first ever reported method based on the analysis of real and complete medical records. In this study, we used a hierarchical model and the Knox method to experimentally realize early warning and monitoring of emerging infectious diseases by using the complete medical records obtained medical institutions. The findings of this study prove that emerging infectious diseases can be monitored using the proposed model framework, which incorporates real medical records sourced from medical institutions.
Data availability
The data that support the findings of this study are available from the corresponding author upon reasonable request.
References
Chala, B. & Hamde, F. Emerging and re-emerging vector-borne infectious diseases and the challenges for control: a review. Front. Public Health https://doi.org/10.3389/fpubh.2021.715759 (2021).
Morens, D. M. & Fauci, A. S. Emerging infectious diseases: threats to human health and global stability. Plos Pathogens https://doi.org/10.1371/journal.ppat.1003467 (2013).
Xu, A. D. et al. The impact of COVID-19 epidemic on the development of the digital economy of china-based on the data of 31 provinces in China. Front. Public Health https://doi.org/10.3389/fpubh.2021.778671 (2022).
Chen, N. et al. Epidemiological and clinical characteristics of 99 cases of 2019 novel coronavirus pneumonia in Wuhan, China: a descriptive study. Lancet 395, 507–513 (2020).
Wu, T. S. J. et al. Establishing a nationwide emergency department-based syndromic surveillance system for better public health responses in Taiwan. BMC Public Health 8, 1–13 (2008).
Zhang, C., Ji, H. & Jin, C. Medical data quality analysis and governance countermeasures. Chinese J Hospital Admin 36, 747–750 (2020).
Reddy, B. K. & Delen, D. Predicting hospital readmission for lupus patients: an RNN-LSTM-based deep-learning methodology. Comput Biol Med 101, 199–209. https://doi.org/10.1016/j.compbiomed.2018.08.029 (2018).
Zeng, X. et al. Explainable machine-learning predictions for complications after pediatric congenital heart surgery. Sci. Rep. https://doi.org/10.1038/s41598-021-96721-w (2021).
Lee, J. H. et al. Deep learning-based automated detection algorithm for active pulmonary tuberculosis on chest radiographs: diagnostic performance in systematic screening of asymptomatic individuals. Eur. Radiol. 31, 1069–1080. https://doi.org/10.1007/s00330-020-07219-4 (2021).
Feng, S. S. & Jin, Z. Infectious diseases spreading on an adaptive metapopulation network. IEEE Access 8, 153425–153435. https://doi.org/10.1109/access.2020.3016016 (2020).
Wang, M. et al. Early warning of infectious diseases in hospitals based on multi-self-regression deep neural network. J. Healthcare Eng. 2022, 8990907–8990907. https://doi.org/10.1155/2022/8990907 (2022).
Christaki, E. New technologies in predicting, preventing and controlling emerging infectious diseases. Virulence 6, 554–561. https://doi.org/10.1080/21505594.2015.1040975 (2015).
Wang, L. et al. Emergence and control of infectious diseases in China. Lancet 372, 1598–1605 (2008).
Li, Q. et al. Early transmission dynamics in wuhan, china, of novel coronavirus-infected pneumonia. New England J Med 382, 1199–1207. https://doi.org/10.1056/NEJMoa2001316 (2020).
Al-Tawfiq, J. A. et al. Emerging respiratory tract infections 1 Surveillance for emerging respiratory viruses. Lancet Infect. Diseases 14, 992–1000. https://doi.org/10.1016/s1473-3099(14)70840-0 (2014).
Begier, E. M. et al. The National Capitol Region’s Emergency Department syndromic surveillance system: do chief complaint and discharge diagnosis yield different results?. Emerging Infect. Diseases 9, 393 (2003).
Hulth, A., Rydevik, G. & Linde, A. Web queries as a source for syndromic surveillance. Plos One https://doi.org/10.1371/journal.pone.0004378 (2009).
Yuan, Q. Y. et al. Monitoring influenza epidemics in china with search query from Baidu. Plos One https://doi.org/10.1371/journal.pone.0064323 (2013).
Carneiro, H. A. & Mylonakis, E. Google trends: a web-based tool for real-time surveillance of disease outbreaks. Clin. Infect. Diseases Offic Publicat Infect. Diseases Soc. Am. 49, 1557–1564 (2009).
Kim, J. & Ahn, I. Infectious disease outbreak prediction using media articles with machine learning models. Sci. Reports https://doi.org/10.1038/s41598-021-83926-2 (2021).
Wilkinson, K. et al. The impact of pertussis vaccine programme changes on pertussis disease burden in Manitoba, 1992–2017-an age-period-cohort analysis. Int J Epidemiol 51, 440–447. https://doi.org/10.1093/ije/dyac001 (2022).
Ji, L., Hui, B. & Song, B. The research on computer-aided diagnosis application basing on bayesian classification schemes. J Comput Theoret Nanosci 11, 2535–2544. https://doi.org/10.1166/jctn.2014.3671 (2014).
Li L, Li S and Wang Y. Early warning methods for unknown infectious diseases, involves obtaining characteristic data of object, and pre-warning unknown infectious disease according to object number of unknown disease type in preset time period. Patent CN112420211-A.
Wang, M. et al. Deep learning model for multi-classification of infectious diseases from unstructured electronic medical records. BMC Med.. Inform. Decision Making https://doi.org/10.1186/s12911-022-01776-y (2022).
Anselin, L. Spatial externalities, spatial multipliers, and spatial econometrics. Int. Region Sci. Rev. 26, 153–166. https://doi.org/10.1177/0160017602250972 (2003).
Li, X. et al. Quality of primary health care in China: challenges and recommendations. Lancet 395, 1802–1812 (2020).
Wu, S. et al. Deep learning in clinical natural language processing: a methodical review. J. Am. Med. Inform. Assoc. 27, 457–470. https://doi.org/10.1093/jamia/ocz200 (2020).
Suárez-Paniagua, V. et al. A two-stage deep learning approach for extracting entities and relationships from medical texts - ScienceDirect. J. Biomed Inform. 99, 103285–103285 (2019).
Tao, L. et al. Accuracy and effects of clinical decision support systems integrated with BMJ best practice-aided diagnosis: interrupted time series study. JMIR Med. Inform. 8, 56–70. https://doi.org/10.2196/16912 (2020).
Mikolov, T., Chen, K., Corrado, G., et al. Efficient estimation of word representations in vector space. Comput. Sci. 2013.
Wu, S. et al. Deep learning in clinical natural language processing: a methodical review. J. Am. Med. Inform. Assoc 3, 457–470 (2019).
Wu, P. et al. Real-time tentative assessment of the epidemiological characteristics of novel coronavirus infections in Wuhan, China, as at 22 January 2020. Eurosurveillance 25, 4–9. https://doi.org/10.2807/1560-7917.Es.2020.25.3.2000044 (2020).
Riou, J. & Althaus, C. L. Pattern of early human-to-human transmission of Wuhan 2019 novel coronavirus (2019-nCoV), December 2019 to January 2020. Eurosurveillance 25, 7–11. https://doi.org/10.2807/1560-7917.Es.2020.25.4.2000058 (2020).
Raymenants, J. et al. Empirical evidence on the efficiency of backward contact tracing in COVID-19. Nat. Commun. https://doi.org/10.1038/s41467-022-32531-6 (2022).
Bergstra, J. & Bengio, Y. Random search for hyper-parameter optimization. J. Mach. Learn. Res. 13, 281–305 (2012).
Hong, J. H. & Cho, S. B. A probabilistic multi-class strategy of one-vs.-rest support vector machines for cancer classification. Neurocomputing 71, 3275–3281. https://doi.org/10.1016/j.neucom.2008.04.033 (2008).
Otani, T. & Takahashi, K. Flexible scan statistics for detecting spatial disease clusters: the rflexscan R package. J. Stat. Softw. 99, 1–29. https://doi.org/10.18637/jss.v099.i13 (2021).
Liu Q-l, Li X, Feng Z, et al. Study on the application of Rogerson Spatial Pattern Surveillance Method in real-time surveillance for infectious diseases. Zhonghua liu xing bing xue za zhi = Zhonghua liuxingbingxue zazhi 2007; 28: 1133–1137
Houben, M. et al. Space–time clustering patterns of gliomas in the Netherlands suggest an infectious aetiology. Eur. J. Cancer 41, 2917–2923 (2005).
Eliane, C. et al. Space-time clustering of childhood cancers: a systematic review and pooled analysis. Eur J Epidemiol 34, 9–21 (2018).
Chen, W. et al. Urban building type mapping using geospatial data: a case study of Beijing China. Remote Sensing https://doi.org/10.3390/rs12172805 (2020).
Chopin, N., Jacob, P. E. & Papaspiliopoulos, O. SMC2: an efficient algorithm for sequential analysis of state space models. J. R. Stat. Soc. Ser. B-Stat. Methodol. 75, 397–426. https://doi.org/10.1111/j.1467-9868.2012.01046.x (2013).
Zhu Ling, L. J.-h, Hu Q., et al. Study on the similarity of TCM symptom terminology based on word vector computation. China Digital Med. 14: 28–31 (2019).
Kamp, C. Untangling the interplay between epidemic spread and transmission network dynamics. Plos Comput. Biol. https://doi.org/10.1371/journal.pcbi.1000984 (2010).
Jajosky, R. A. & Groseclose, S. L. Evaluation of reporting timeliness of public health surveillance systems for infectious diseases. BMC Public Health https://doi.org/10.1186/1471-2458-4-29 (2004).
Zhuang, W. Q. et al. game analysis on epidemic prevention and resuming production: based on China’s experience with COVID-19. Front Psychol. https://doi.org/10.3389/fpsyg.2021.747465 (2021).
Li, M. Public health crises in comparison: China’s epidemic response policies from SARS To COVID-19. Global Public Health 16, 1223–1236. https://doi.org/10.1080/17441692.2021.1919735 (2021).
Prilutsky, D. et al. Classification of infectious diseases based on chemiluminescent signatures of phagocytes in whole blood. Artific. Intell. Med. 52, 153–163. https://doi.org/10.1016/j.artmed.2011.04.001 (2011).
Chang, C. C. & Lin, C. J. LIBSVM: a library for support vector machines. ACM Trans. Intell. Syst. Technol. https://doi.org/10.1145/1961189.1961199 (2011).
Nguyen, B. P., Tay, W. L. & Chui, C. K. Robust biometric recognition from palm depth images for gloved hands. IEEE Trans. Human-Mach. Syst. 45, 799–804. https://doi.org/10.1109/thms.2015.2453203 (2015).
Radford, A. Language Models are Unsupervised Multitask Learners.
Brown, T.B., Mann, B., Ryder, N., et al. Language models are few-shot learners. 2020.
Devlin, J., Chang, M.W., Lee, K., et al. BERT: pre-training of deep bidirectional transformers for language understanding. 2018.
Chawla, N. V. et al. SMOTE: synthetic minority over-sampling technique. J. Artific. Intell. Res. 16, 321–357. https://doi.org/10.1613/jair.953 (2002).
Vakamullu, V., Mishra, M., Mukherjee, A., et al. Real-time heart murmur classification using attention based deep learning approach. In: IEEE International Instrumentation and Measurement Technology Conference (I2MTC) Ottawa, CANADA, 2022 May 16–19 2022, 2022 IEEE International Instrumentation and Measurement Technology Conference (i2mtc 2022).
Han, H., Wang, W.Y. & Mao, B.H. Borderline-SMOTE: A new over-sampling method in imbalanced data sets learning. In: Advances in Intelligent Computing, Pt 1, Proceedings (ed. Huang, D.S., Zhang, X. P. & Huang, G. B.) 878–887 (2005).
Acknowledgements
We would like to thank the information management and big data center of Peking University Third Hospital for its data support for this project.
Funding
This study was supported by the Capital's Funds for Health Improvement and Research, CFH, 2021-1G-4091.
Author information
Authors and Affiliations
Contributions
All authors have read and approved the manuscript, and each author has participated sufficiently in developing the project and the manuscript. C.Y. and H.J. initiated the research and designed the experiments. M.W. analyzed the data. H.J. and B.Y. contributed to data collection. M.W. wrote the paper with the help of C.Y. and Y.Y., Y.L. contributed to the literature review and analysis of the study and drafting the manuscript. All authors read and approved the final manuscript.
Corresponding authors
Ethics declarations
Competing interests
The authors declare no competing interests.
Additional information
Publisher's note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Wang, M., Yang, B., Liu, Y. et al. Emerging infectious disease surveillance using a hierarchical diagnosis model and the Knox algorithm. Sci Rep 13, 19836 (2023). https://doi.org/10.1038/s41598-023-47010-1
Received:
Accepted:
Published:
DOI: https://doi.org/10.1038/s41598-023-47010-1
Comments
By submitting a comment you agree to abide by our Terms and Community Guidelines. If you find something abusive or that does not comply with our terms or guidelines please flag it as inappropriate.
