
Abstract
The paper presents a novel statistical approach for analyzing the daily coronavirus case and fatality statistics. The survival discretization method was used to generate a two-parameter discrete distribution. The resulting distribution is referred to as the "Discrete Marshall–Olkin Length Biased Exponential (DMOLBE) distribution". Because of the varied forms of its probability mass and failure rate functions, the DMOLBE distribution is adaptable. We calculated the mean and variance, skewness, kurtosis, dispersion index, hazard and survival functions, and second failure rate function for the suggested distribution. The DI index demonstrates that the proposed model can represent both over-dispersed and under-dispersed data sets. We estimated the parameters of the DMOLBE distribution. The behavior of ML estimates is checked via a comprehensive simulation study. The behavior of Bayesian estimates is checked by generating 10,000 iterations of Markov chain Monte Carlo techniques, plotting the trace, and checking the proposed distribution. From simulation studies, it was observed that the bias and mean square error decreased with an increase in sample size. To show the importance and flexibility of DMOLBE distribution using two data sets about deaths due to coronavirus in China and Pakistan are analyzed. The DMOLBE distribution provides a better fit than some important discrete models namely the discrete Burr-XII, discrete Bilal, discrete Burr-Hatke, discrete Rayleigh distribution, and Poisson distributions. We conclude that the new proposed distribution works well in analyzing these data sets. The data sets used in the paper was collected from 2020 year.
Similar content being viewed by others
Introduction
A new pandemic appeared at the beginning of 2019 till March 2020 called the COVID-19 (Feroze1). Because of the lockout, COVID-19 has the greatest impact on human life and the economy. Pakistan is the 12th most impacted country in the world as a result of COVID-19 (Khan et al.2).
Mathematical models for the analysis of infectious disease transmission are currently omnipresent. Such models’ play a significant role in assisting with quantifying conceivable irresistible aliment control. Several models are available for infectious disease concerning compartmental models, beginning from the classical SIR model to more complex proposals (Ndaïrou et al.3).
To model the count data sets there are several classical probability distributions such as Binomial, Poisson, Geometric, and Negative Binomial distributions but these models do not provide a better fit for the over-dispersed nature of data sets. Hence one way to deal with such data sets is to discretize the continuous model dealing with the specific behavior to have a better fit. Discretization has attained much attention in the last few decades due to its applicability and better fitting for count data analysis.
In past several discrete distributions have been introduced and studied, such as discrete Weibull distribution discrete beta exponential distribution by Nekoukhou et al.4, two-parameter discrete Lindley distribution by Hussain et al.5, Discrete Marshall–Olkin inverse Toppe–Leone with application to COVID-19 data has been obtained by Almetwally et al.6. discrete weighted exponential distribution by Rasekhi et al.7 exponentiated discrete Lindley distribution by El-Morshedy et al.6, discrete Burr Hutke distribution by El-Morshedy et al.8, discrete Marshall–Olkinin Weibull distribution by Opone et al.9), see Almetwally et al.10, discrete Marshall–Olkinin alpha power inverse Lomax distribution by Almetwally et al.11, discrete inverted Topp–Leone distribution by Eldeeb et al.12, discrete Ramos–Louzada distribution by Eldeeb et al.13, discrete type-II half logistic exponential distribution Ahsan-ul-Haq et al.14, discrete power-Ailamujia distribution by Alghamdi et al.15, Poisson XLindley distribution Ahsan-ul-Haq et al.16, Poisson moment exponential distribution Ahsan-ul-Haq17 and discrete moment exponential distribution by Afify et al.18.
Discrete extended odd Weibull exponential with the application of COVID-19 Mortality Numbers in the Kingdom of Saudi Arabia and Latvia has been introduced by Nagy et al.19. The pmf of the new model for a mixture representation of a geometric model has been obtained by El-Morshedy et al.20.
All these discrete probability models are introduced using the survival discretization approach. Let a random variable X be associated with a continuous probability distribution having survival function \(S\left(x\right)\). The probability mass function (pmf) of a discrete random variable based on discretization is
The primary purpose of this study is to introduce a new flexible probability distribution for modelling across over-dispersed data sets. The mathematical properties of the new distribution, such as its simple closed-form expressions for the pmf, cdf, moments, and other characteristics, are obtained. The maximum likelihood approach is used to estimate the model parameters. To suggest a new alternative approach to model over dispersed data sets, the DMOLBE distribution applied to the number of deaths due to Covid-19 data sets. Consequently, the DMOLBE model's primary goals are:
-
The fact that this distribution provides the several hazard rate forms, such as declining, growing, or increasing-constant, sets it apart from many other one- or two-parameter discrete distributions. Because of these hazard rates, the suggested model can be used to model a variety of data sets.
-
It provides a variety of PMF shapes suitable for modelling symmetric, positively skewed, or negatively skewed data that may not be successfully modelled by other competitor models.
-
The introduction of a number of statistical and reliability traits, such as moments, probability functions, reliability indices, hazard functions, reverse hazard rate, second rate of Failure, etc.
-
In comparison to other discrete distribution models in the literature, analysis results from two practical applications revealed that the DMOLBE distribution matches the supplied data sets satisfactorily;
-
In the presence of gathered data, maximum likelihood and Bayesian estimation methods are taken into consideration to estimate the specified parameters.
-
The effectiveness of the acquired estimators is assessed using lengthy Monte Carlo simulations and a variety of accuracy metrics, including mean squared errors and absolute biases. It would seem plausible to suggest that approaches for parameter estimation are adequate and efficient.
The study is divided into the following sections: “Methodology” is based on the mathematical characteristics and derivation of the discrete Marshall–Olkinin Length Biased Exponential distribution. “Parameter estimation” presents maximum likelihood estimation via an extensive simulation study. “Bayesian estimation” discusses the results for all models. Finally, in “Results and discussion”, we bring the research to a close.
Methodology
In this section, we introduced a new discrete distribution, derived its statistical properties, estimate the model parameters using the maximum likelihood approach.
The DMOLBE distribution and its properties
Let X be a random variable connected with the Ahsan-ul-Haq et al.21 presented Marshall–Olkinin Length Biased Exponential distribution. The MOLBE distribution's probability density function is:
The associated survival function is
The DMOLBE distribution obtained using Eqs. (1) and (3), the pmf of the DMOLBE distribution is given
The cdf of DMOLBED is as follows
where \(\gamma\) is shape and \(\beta\) is scale parameter.
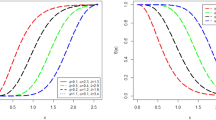
Figure 1 depicts the behavior of the probability mass function of the DMOLBE distribution, which varies with parameter values. The DMOLBE distribution is clearly declining, positively skewed, and symmetric, as seen above. It demonstrates the suggested distribution's versatility in dealing with data of varying behaviour.

The pmf plots of DMOLBE distribution.
Survival and hazard function
The survival function of DMOLBED is as follows
The hazard function (hrf) of DMOLBE is given as follows
Figure 2 shows the behavior of hazard function for different values of parameters which is increasing and decreasing which shows the flexibility of the model.

The discrete hrf plots of DMOLBE distribution.
The second rate of failure
The second rate of failure of DMOLBE is defined as
Reverse hazard rate
The reverse Hazard rate of DMOLBE is defined as:
Recurrence formula
Probability generating function and moments
Let X be a discrete random variable, then the probability generating function of the DMOLBE distribution is given as follows:
Differentiating \({G}_{x}\left(Z\right)\) with respect to \(Z\) and setting \(Z=1\), we can obtain the factorial moments as
The factorial moments can be used to compute moments about the origin.
Now variance is
and the coefficients of skewness (CS) and kurtosis (CK) may be computed as follows
By Table 1 and Figs. 3, 4, and 5 show different measures of moment with different values of parameters.

Plots of mean, variance, skewness and kurtosis of DMOLBED \(\left(\gamma =0.5\right)\)

Plots of mean, variance, skewness and kurtosis of DMOLBED \(\left(\beta =0.5\right)\)

Plots of dispersion index of DMOLBED.
The corresponding Dispersion Index (DI) is defined as
The DI indicates whether a distribution is suitable to model over or under-dispersed data sets. If \(DI>1\), the certain distribution is showing over-dispersed behavior. It is observed that the DMOLBE distribution shows over-dispersion when \(\gamma =0.5\) and different values of parameter \(\beta\). Conversely, the DMOLBE distribution shows under-dispersion when \(\beta =0.5\) and different values of \(\gamma .\)
Parameter estimation
Suppose \(x=({x}_{1}, {x}_{2}, {x}_{3}, \dots , {x}_{n} )\) be a random sample of size n from DMOLBE distribution with probability mass function defined as
Then the log-likelihood function is given by:
Now partially differentiate w.r.t γ and β, respectively.
Since it is difficult to find a closed-form solution for the set of nonlinear Eqs. (13, 14) with unknown gamma and beta values, the above-described nonlinear system may be numerically solved using an iterative method like Newton–Raphson by ‘maxLik’ package in R software.
Bayesian estimation
Since random and parameter uncertainty are expressed by a prior joint distribution that was generated before the data was obtained on the failure, the Bayesian approach deals with parameters. The flexibility of the Bayesian technique to incorporate previous knowledge into research makes it particularly useful in the study of reliability, as the lack of data is one of the major problems with reliability analysis. The \(\gamma\) and \(\beta\) parameters of DMOLBED take prior gamma distributions, where \(\gamma\) and \(\beta\) are non-negative values. The α and b parameters as independent joint prior density functions can be expressed as follows:
The estimates and their variances were equated with the inverse of the Fisher information matrix of alpha and beta to produce the ML estimator for \(\gamma\) and \(\beta\), which was contributed by Dey et al.23. This procedure was used to extract the hyper-parameters of the informative priors. The joint posterior density function of \(\gamma\) and \(\beta\) are derived from likelihood function of DMOLBED and joint prior density:
Most Bayesian inference processes have been created using symmetric loss functions. The squared-error loss function is a popular symmetric loss function. The Bayes estimators of \(\gamma\) and \(\beta\), say \(\widetilde{\gamma }\) and \(\widetilde{\beta }\) based on squared error loss function is given by
See Almetwally et al.22 employed the MCMC technique to solve the above equations.
Two of the most prevalent MCMC methodologies are the Metropolis–Hastings (MH) and Gibbs sampling methods. We employ the MH inside the Gibbs sampling stages:
and
Results and discussion
In this section, the results from the Monte Carlo simulation and real-life application are discussed in detail. All numerical calculations performed using R language software.
Simulation study
-
1.
The following simulation research is carried out to examine the behaviour of Bayesian and maximum likelihood estimates of the DMOLBE distribution. The simulation research is conducted using the below procedures.
-
2.
Generate \(N=\mathrm{10,000}\) samples of size \(n=50, 100, 150, 200,\) and 300 from DMOLBD.
-
3.
Estimate the parameters \(\widehat{\gamma }\) and \(\widehat{\beta }\) from each generated sample.
-
4.
Compute the absolute biases (AB) and mean square errors (MSE) using the following equations.
For MLE:
For Bayesian
The simulation results are reported in Tables 2 and 3. Following conclusions are obtained from the results.
The following points were concluded from the simulation results
-
1.
The estimated bias always decreases and approaches zero when \(n\to \infty\) for all combinations of parameters.
-
2.
The estimated MSE decrease with an increase in sample size.
-
3.
Bayesian estimation is better than MLE.
Applications
This section is based on the advantage of the newly proposed DMOLBE distribution over some commonly used distributions. The performance of the DMOLBED is compared with competitive distributions. The competitive distributions are discrete Burr XII distribution (DBXII), discrete Bilal distribution (DB), discrete Burr–Hatke distribution (DBH), discrete exponentiated Rayleigh distribution (DER), discrete length biased exponential distribution (DLBE), discrete Pareto distribution (DPr), and discrete Poisson distribution (DP). The probability mass functions of these distributions are;
Discrete Burr XII distribution
Discrete exponentiated Rayleigh distribution
Discrete Pareto distribution
Discrete length Biased exponentiated distribution
Discrete bilal distribution
Discrete Burr–Hatke distribution
Discrete Poisson distribution
The model parameters of considered models are estimated using the maximum likelihood method. The performance of all fitted distributions is compared utilizing some criteria, Akaike information criterion (AIC), Bayesian information criterion (BIC), and Kolmogorov–Smirnov (K–S) test with its corresponding p values. All the computations are carried out in R software.
Data Set I (death due to coronavirus in China)
The first data set is the number of deaths due to coronavirus in China from 23 January to 28 March. The data sets used in the paper was collected from 2020 year. The data set is reported in https://www.worldometers.info/coronavirus/country/china/. The data are: 8, 16, 15, 24, 26, 26, 38, 43, 46, 45, 57, 64, 65, 73, 73, 86, 89, 97, 108, 97, 146, 121, 143, 142, 105, 98, 136, 114, 118, 109, 97, 150, 71, 52, 29, 44, 47, 35, 42, 31, 38, 31, 30, 28, 27, 22, 17, 22, 11, 7, 13, 10, 14, 13, 11, 8, 3, 7, 6, 9, 7, 4, 6, 5, 3 and 5. The MLEs with their corresponding standard errors and goodness-of-fit measures are presented in Table 4.
Table 4 presents the results for estimated parameters using different models for the first data set which shows that DMOLBE distribution better fits the data set as compared to other competitive models as AIC and BIC are smaller for the proposed model. Table 5 discussed comparing between MLE and Bayesian estimation by SE for the death due to coronavirus in China. By results in Table 5, we conclude that the Bayesian estimation is best estimation method for the death due to coronavirus in China. Figure 6 shows the cdf of different distributions of the first data set and Fig. 7 presents the P–P plots for all the competitive models, both figure supports the results obtained in Table 4. Figure 8 show that estimates of DMOLBED parameters for the death due to coronavirus in China data is existence and has the maximum log-likelihood value. Figure 9 plot MCMC plot results of parameter estimates of DMOLBED for the death due to coronavirus in China data to confirm the estimates have convergence and the posterior has normal distribution as proposed distribution.

The estimated CDFs for the death due to coronavirus in China.

The P–P plots for the death due to coronavirus in China.

Existence for the log-likelihood for the death due to coronavirus in China.

MCMC plots of convergence for parameter estimates of DMOLBED for the death due to coronavirus in China.
Data Set II (daily death due to coronavirus in Pakistan)
The second data set is the daily deaths due to coronavirus in Pakistan from 18 March to 30 June. The data sets used in the paper was collected from 2020 year. The data is reported in https://www.worldometers.info/coronavirus/country/Pakistan. The data are: 1, 6, 6, 4, 4, 4, 1, 20, 5, 2, 3, 15, 17, 7, 8, 25, 8, 25, 11, 25, 16, 16, 12, 11, 20, 31, 42, 32, 23, 17, 19, 38, 50, 21, 14, 37, 23, 47, 31, 24, 9, 64, 39, 30, 36, 46, 32, 50, 34, 32, 34, 30, 28, 35, 57, 78, 88, 60, 78, 67, 82, 68, 97, 67, 65, 105, 83, 101, 107, 88, 178, 110, 136, 118, 136, 153, 119, 89, 105, 60, 148, 59, 73, 83, 49, 137 and 91.
Table 6 presents the results for estimated parameters using different models of the second data set which shows that DMOLBE distribution better fits the data set as compared to other competitive models as AIC and BIC are smaller for the proposed model. Table 7 discussed comparing between MLE and Bayesian estimation by SE. By results in Table 7, we conclude that the Bayesian estimation is best estimation method. Figure 10 shows the cdf of different distributions of the second data set and Fig. 11 presents the P–P plots for all the competitive models, both figure supports the results obtained in Table 6. Figure 12 show that estimates of DMOLBED parameters for Coronavirus in Pakistan data is existence and has the maximum log-likelihood value. Figure 13 plot MCMC plot results of parameter estimates of DMOLBED for Coronavirus in Pakistan data to confirm the estimates have convergence and the posterior has normal distribution as proposed distribution.

The estimated CDFs for the death due to coronavirus in Pakistan.

The P–P plots for the death due to coronavirus in Pakistan.

Existence for the log-likelihood of DMOLBED parameters for Coronavirus in Pakistan data.

MCMC plots of convergence for parameter estimates of DMOLBED parameters for Coronavirus in Pakistan data.
Conclusion
The DMOLBE distribution, a novel two-parameter discrete probability distribution that may be utilised in place of well-known distributions, is introduced in this study. Its mathematical characteristics are provided in some cases. The maximum likelihood and Bayesian estimation methods are used to estimate the distribution's parameters. The MCMC method is applied by the MH algorithm to produce the Bayesian estimation method. To evaluate the performance of unidentified parameters based on AB and MSE, simulation research is conducted. MLE and Bayesian estimate methods for the performance parameter of the DMOLBE distribution were compared through simulation. We came to the conclusion that the Bayesian estimation approach is superior for estimating DMOLBE distribution parameter. The flexibility of the model is proved by using two real data sets and is compared with different existing models and the proposed model perform better among other models. Further the estimation of the proposed model can be performed using transforms. We will make future work as extension for this study, we will make a regression analysis to predict the future mortality rates in many countries under considerations.
Future work
Future work in statistical analysis for COVID-19 data holds great potential in advancing our understanding of the pandemic and informing evidence-based decision-making. One key area of focus is the integration of more comprehensive and diverse datasets, including demographic, socioeconomic, and healthcare variables, to explore the multifaceted aspects of COVID-19's impact on different populations. Advanced machine learning techniques can be applied to identify complex relationships and risk factors associated with the spread, severity, and outcomes of the virus. Furthermore, predictive modeling can be enhanced by incorporating real-time data streams and dynamic factors to provide more accurate and timely forecasts, aiding in proactive planning and resource allocation. Longitudinal studies analyzing the long-term effects of the pandemic and assessing the efficacy of interventions over time will provide valuable insights into the sustainability of public health measures. Additionally, ethical considerations and privacy-preserving methodologies should be integrated into future analyses to ensure data security and protect individuals' rights. Overall, future work in statistical analysis for COVID-19 data will continue to play a pivotal role in guiding public health policies, bolstering preparedness for future outbreaks, and ultimately safeguarding global health.
Data availability
All data exists in the paper with all its references.
Abbreviations
- MOLBE:
-
Marshall–Olkin Length Biased Exponential
- DMOLBE:
-
Discrete Marshall–Olkin Length Biased Exponential
- pmf:
-
Probability mass function
- cdf:
-
Cumulative distribution function
- hrf:
-
Hazard rate function
- DI:
-
Dispersion Index
- DBXII:
-
Discrete Burr XII distribution
- DB:
-
Discrete Bilal distribution
- DBHD:
-
Discrete Burr–Hatke distribution
- DR:
-
Discrete Rayleigh distribution
- Poisson:
-
Poisson distribution
- MLE:
-
Maximum likelihood estimation
References
Feroze, N. Forecasting the patterns of COVID-19 and causal impacts of lockdown in top five affected countries using Bayesian structural time series models. Chaos Solitons Fractals 140, 20 (2020).
Khan, F., Saeed, A. & Ali, S. Modelling and forecasting of new cases, deaths and recover cases of COVID-19 by using vector autoregressive model in Pakistan. Chaos Solitons Fractals 140, 110189 (2020).
Ndaïrou, F., Area, I., Nieto, J. J. & Torres, D. F. M. Mathematical modeling of COVID-19 transmission dynamics with a case study of Wuhan. Chaos Solitons Fractals 135, 25 (2020).
Nekoukhou, V., Alamatsaz, M. H. & Bidram, H. Discrete generalized exponential distribution of a second type. Statistics 47(4), 876–887. https://doi.org/10.1080/02331888.20111.633707 (2013).
Hussain, T., Aslam, M. & Ahmad, M. A two parameter discrete lindley distribution. Rev. Colomb. Estad. 39(1), 45–61 (2016).
Almetwally, E. M. et al. The new discrete distribution with application to COVID-19 data. Results Phys. 32, 104987 (2022).
Rasekhi, M., Chatrabgoun, O. & Daneshkhah, A. Discrete weighted exponential distribution: Properties and applications. Filomat 32(8), 3043–3056 (2018).
El-Morshedy, M., Altun, E. & Eliwa, M. S. A new statistical approach to model the counts of novel coronavirus cases. Math. Sci. 20, 20 (2021).
Opone, F. C., Izekor, E. K., Akata, I. U. & Osagiede, F. E. U. A discrete analogue of the continuous Marshall–Olkinin Weibull distribution with application to count data. Earthl. J. Math. Sci. 5, 415–428 (2020).
El-Morshedy, M., Eliwa, M. S. & Altun, E. Discrete Burr–Hatke distribution with properties, estimation methods and regression model. IEEE Access 8, 74359–74370 (2020).
El-Morshedy, M., Eliwa, M. S. & Nagy, H. A new two parameter exponentiated discrete Lindley distribution: Properties, estimation and application. J. Appl. Stat. 20, 20 (2019).
Eldeeb, A. S., Ahsan-ul-Haq, M. & Babar, A. A discrete analog of inverted Topp–Leone distribution: Properties, estimation and applications. Int. J. Anal. Appl. 19(5), 695–708 (2021).
Eldeeb, A. S., Ahsan-ul-Haq, M. & Eliwa, M. S. A discrete Ramos–Louzada distribution for asymmetric and over-dispersed data with leptokurtic-shaped: Properties and various estimation techniques with inference. AIMS Math. 7(2), 1726–1741 (2021).
Ahsan-ul-Haq, M., Babar, A., Hashmi, S., Alghamdi, A. S. & Afify, A. Z. The discrete type-II half-logistic exponential distribution with applications to COVID-19 data. Pak. J. Stat. Oper. Res. 20, 921–932 (2021).
Alghamdi, A. S., Ahsan-ul-Haq, M., Babar, A., Aljohani, H. M. & Afify, A. Z. The discrete power-Ailamujia distribution: Properties, inference, and applications. AIMS Math. 7(5), 8344–8360 (2022).
Ahsan-ul-Haq, M., Al-Bossly, A., El-Morshedy, M. & Eliwa, M. S. Poisson XLindley distribution for count data: Statistical and reliability properties with estimation techniques and inference. Comput. Intell. Neurosci. 20, 22 (2022).
Ahsan-ul-Haq, M. On Poisson moment exponential distribution with applications. Ann. Data Sci. 20, 1–22 (2022).
Afify, A. Z. et al. A new one-parameter discrete exponential distribution: Properties, inference, and applications to COVID-19 data. King Saud Univ. J. Sci. 1, 20 (2022).
Nagy, M. et al. The new Novel discrete distribution with application on COVID-19 mortality numbers in Kingdom of Saudi Arabia and Latvia. Complexity 20, 21 (2021).
Almetwally, E. M., Almongy, H. M. & Saleh, H. Managing risk of spreading “COVID-19” in Egypt: Modelling using a discrete Marshall–Olkinin generalized exponential distribution. Int. J. Probabil. Stat. 9(2), 33–41 (2020).
Ahsan-ul-Haq, M., Usman, R. M., Hashmi, S. & Al-Omeri, A. I. The Marshall–Olkinin length-biased exponential distribution and its applications. J. King Saud Univ. Sci. 31(2), 246–251 (2019).
Almetwally, E. M. & Ibrahim, G. M. Discrete alpha power inverse lomax distribution with application of Covid-19 data. Int. J. Appl. Math. Stat. Sci. 9(6), 11–22 (2020).
Dey, S., Singh, S., Tripathi, Y. M. & Asgharzadeh, A. Estimation and prediction for a progressively censored generalized inverted exponential distribution. Stat. Methodol. 32, 185–202 (2016).
Acknowledgment
The researchers would like to acknowledge the Deanship of Scientific Research, Taif University for funding this work.
Author information
Authors and Affiliations
Contributions
All authors contributed equally to this paper
Corresponding author
Ethics declarations
Competing interests
The authors declare no competing interests.
Additional information
Publisher's note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Aljohani, H.M., Ahsan-ul-Haq, M., Zafar, J. et al. Analysis of Covid-19 data using discrete Marshall–Olkinin Length Biased Exponential: Bayesian and frequentist approach. Sci Rep 13, 12243 (2023). https://doi.org/10.1038/s41598-023-39183-6
Received:
Accepted:
Published:
DOI: https://doi.org/10.1038/s41598-023-39183-6
This article is cited by
-
The discrete new XLindley distribution and the associated autoregressive process
International Journal of Data Science and Analytics (2024)
Comments
By submitting a comment you agree to abide by our Terms and Community Guidelines. If you find something abusive or that does not comply with our terms or guidelines please flag it as inappropriate.
