
Abstract
Uncertain information processing is a key problem in classification. Dempster-Shafer evidence theory (D-S evidence theory) is widely used in uncertain information modelling and fusion. For uncertain information fusion, the Dempster’s combination rule in D-S evidence theory has limitation in some cases that it may cause counterintuitive fusion results. In this paper, a new correlation belief function is proposed to address this problem. The proposed method transfers the belief from a certain proposition to other related propositions to avoid the loss of information while doing information fusion, which can effectively solve the problem of conflict management in D-S evidence theory. The experimental results of classification on the UCI dataset show that the proposed method not only assigns a higher belief to the correct propositions than other methods, but also expresses the conflict among the data apparently. The robustness and superiority of the proposed method in classification are verified through experiments on different datasets with varying proportion of training set.
Similar content being viewed by others


Introduction
Classification is a hot topic in artificial intelligence. Many practical approaches have been proposed for improving the classification accuracy such as the logistic regression1, k nearest neighbors2, linear discriminant analysis3, support vector machines4, random forests5, and artificial neural networks6,7. Classification usually faces uncertain information sources, e.g., the data collected by sensors or manually may be subject to a certain amount of errors. In general, the uncertain information in classification problem can be divided into three kinds: (1) The imprecision data. For example, samples from different categories often overlap in the feature space, which may lead to a result that these samples can not truly reflect the accurate distribution of different categories. (2) The incompleteness data. This usually means that the training data cannot describe the real distribution effectively. (3) The noise in the training data in terms of categories or characteristics. This work adopts information fusion and uncertainty management methods to address classification problem.
To address the uncertainty in classification problems, many valuable methods have been proposed. Porebski8 propose a new technique of linguistic rule extraction, which adopts a fuzzy membership function to describe the imprecision of linguistic values and measured the uncertainty by a fuzzy confidence function. Yang et al.9 establish a rule-based system named Cumulative Belief Rule-Based System to overcome the limitation of the classical rule-based system. Based on fuzzy rough set theory, Wang et al.10 propose a new measure to describe the inherent uncertainty in the data and it improves the performance of the classifier. To reduce the impact of redundant data, Salem et al.11 propose a new feature selection framework based on ideal vector which extracts all possible feature relationships with minimal computational cost. Subhashini et al.12 develop a decision-making framework with which fuzzy concepts are used to classify positive, negative and boundary areas. Sun et al.13 construct a multi-label classification method based on neighborhood information and it is used for incomplete data with missing labels in neighborhood decision-making system. Sauglam et al.14 introduce a new clustering Bayesian classification method to detect different concentrations in a class. To reduce the uncertainty introduced by the noise data in classification problem, Yao et al.15 propose a new hybrid integrated credit scoring model based on stacked noise detection and weight assignment to remove or adjust the noise data in the original data set and form the noise detection training data. This work adopts multi-source information fusion technology16,17,18,19 for uncertain information processing in classification.
Information fusion technology has been greatly developed and applied in practical applications such as decision-making20,21,22,23, pattern recognition24,25, fault diagnosis26,27,28, risk analysis29,30, and reliability assessment31,32,33. Many mathematical methods are adopted for information fusion, such as Dempster-Shafer evidence theory (D-S evidence theory)34,35, belief function theory36,37, fuzzy set theory38, probability theory39, D-numbers40, Z-numbers41, generalized evidence theory42,43, and so on44,45. As a widely used theory in information fusion, D-S evidence theory is an effective method for modeling and fusing uncertain information in many fields such as clustering46,47, classification48,49,50, fault diagnosis51,52, decision support system53, reliability analysis54, correlation analysis19,55, multi-attribute decision analysis56, and so on57,58. Nevertheless, there are still some open issues to be addressed including the computational complexity of Dempster’s combination rule59 and the uncertainty measurement in the evidence theory60,61,62,63. Uncertainty measurement in D-S evidence theory is an important step to deal with potential conflict information fusion. To address Uncertainty management in the evidence theory, Gao et al.64 propose a new uncertainty measurement based on Tsallis entropy. Based on the belief intervals of D-number, Deng and Jiang65 propose a total uncertainty measurement that comprises several basic properties including the range, monotonicity, and generalized set consistency. Deng and Wang66 measure the Hellinger distance between the belief interval and the most uncertain interval for each single case as the total uncertainty. Besides, for the existing methods of uncertainty measurement, Moral-García and Abellán67 pointed out that the maximum value of entropy on the belief interval is the most suitable way of measurement for practical applications because of its excellent mathematical properties. This work focuses on information fusion in classification problem with respect to uncertainty management with a new correlation factor in the framework of D-S evidence theory.
There are many works proposing new classification methods based on D-S evidence theory or belief functions. Geng et al.68 combine evidence association rule with classification and propose an evidence association rule-based classification method. Wang et al.69 propose an ensemble classifier that uses the evidence theory to fuse the outputs of multiple classifiers. For classification problem with high-dimensional data, Su et al.70 establish a rough evidential K-NN classification rule in the framework of rough set theory which selects features by minimizing the neighborhood pignistic decision error rate. To address the uncertainty caused by fuzzy data, Li et al.71 propose a new framework to combine the results of multi-supervised classification and clustering based on belief function. With the popularity of deep learning, Tong et al.72 propose the use of convolutional and pooling layers in convolutional neural networks to extract data features and then transform them into belief function. From the perspective of information fusion and uncertainty management in classification, in this paper, a novel correlation belief function is proposed to manage the uncertainty and improve the performance of D-S evidence theory in information fusion in classification.
The rest of this paper is organized as follows. Dempster-Shafer evidence theory is reviewed in section “Preliminaries”. Section “The correlation belief function” introduces the correlation belief function with some numerical examples. Section “Application in classification” is the correlation belief function-based classification method and its application. Section “Discussion” discusses the robustness and superiority of the proposed method. Conclusions are given in section “Conclusions”.
Preliminaries
Dempster-Shafer evidence theory
Definition 1
Define \( \Omega \) as a nonempty set of n exhaustive and mutually exclusive elements. \( \Omega \) is called the frame of discernment (FOD).
The power set of \( \Omega \) is composed of \( 2^{n} \) propositions, which can be denoted as follows:
Definition 2
For \(\Omega \), a basic belief assignment (BBA), which is also called mass function, is a mapping m : \( 2^{\Omega } \rightarrow \left[ 0, 1 \right] \). m satisfies:
A is called a focal element if \( m\left( A \right) > 0 \). \( m\left( A\right) \) indicates the degree to which evidence supports proposition A.
Definition 3
In D-S evidence theory, two independent pieces of evidence can be fused by Dempster’s combination rule:
where K represent the degree of conflict between \(m_1\) and \(m_2\):
\(K=0\) means that there is no conflict between the evidence and \(K=1\) means that the evidence is completely conflicting.
Pignistic probability transformation
The Pignistic probability transformation in transferable belief model was first proposed by Smets73.
Definition 4
Assume m is a BBA on \(\Omega \), both A and B are any set in the power set \(2^{\Omega }\). Its associated pignistic probability function \(BetP_m:\Omega \rightarrow [0, 1]\) is defined as follows:
where \( m\left( \emptyset \right) \ne 1 \), \( \left| A \right| \) is the cardinality of subset A.
The correlation belief function
In information fusion, it is important to take advantage of all available data. If some information is lost, a counterintuitive combination result may be got. For instance, assume the FOD \(\Omega \) is \( \left\{ \theta _1, \theta _2, \theta _3 \right\} \), the power set of \(\Omega \) is \(2^{\Omega }\) and the mass functions \(m_1\) and \(m_2\) are as follows.
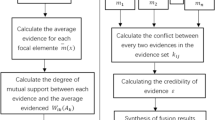
where n is the number of elements in the FOD, \(0 < p \le 1,\ 0\le q_i \le 1,\ \sum _{i=1}^n{q_i}=1,\ B_1\) is any set in \(2^{\Omega }\) except \(\{\theta _1\}\) and \( \emptyset ,\ A_i \) is any set in \(2^{\Omega }\) and its subset does not contain \(\{\theta _1\}\). No matter how the values of p and \(q_i\) change, the combination result \( m_1\oplus m_2\left( \{\theta _1\}\right) \) is always equal to 0. In other words, all information about the proposition \(\{\theta _1\}\) in \(m_1\) is lost. To address this issue, the correlation belief function is proposed. The correlation belief function consists of two steps: belief gathering and correlation belief transfer. The flowchart of the correlation belief function is shown in Fig. 1.

The flowchart of proposed method.
Belief gathering
In a closed world assumption, let \( \Omega \) be a set of n possible values that are mutually exclusive, \( \Omega =\left\{ \theta _1,\ \theta _2,\ \theta _3,\ \ldots \ ,\ \theta _i,\ \ldots \ ,\ \theta _n \right\} \). The power set of \( \Omega \) is \( 2^{\Omega } \), \(2^{\Omega }=\left\{ \emptyset ,\ \left\{ \theta _1 \right\} ,\ \left\{ \theta _2 \right\} ,\ \ldots \ ,\ \left\{ \theta _1\cup \theta _2 \right\} ,\ \ldots \ ,\ \left\{ \theta _1\cup \theta _2\cup \theta _3\cup \theta _i \right\} ,\ \ldots \ ,\ \Omega \right\} \). Single subset propositions in \(2^{\Omega }\) are marked as \(\alpha _i\ (i=1,2,3,\ \ldots \ ,n)\), and multi-subset propositions in \(2^{\Omega }\) are marked as \(\beta _j\ (j=1,2,3,\ \ldots \ ,\ 2^n-n-1)\). Assume m is the original BBA on \(\Omega \) and \(m_*\) is the modified BBA by this step. In this step, single subset propositions (\(\alpha _i\)) are pignistic probability transformed in Eq. (6) and the belief value of multi-subset propositions (\(\beta _j\)) are set as zero. The modified BBA (\(m_*\)) of proposition \(\alpha _i\) and proposition \(\beta _i\) are defined as follows:
where \(\alpha _i\) is any single subset proposition (\(|\alpha _i|=1\)) in the power set \(2^{\Omega }\), A is any proposition in the power set \((2^{\Omega })\).
where \(\beta _j\) is any multi-subset proposition \((|\beta _j|>1)\) in \(2^{\Omega }\).
Correlation belief transfer
This step is the core of correlation belief function, which is called correlation belief transfer. It is defined in section “Definition” and a simple example is presented to clearly illustrate the process of this step in section “Illustrative example”. Figure 2 visualizes this example, which is also an illustration of STEP 2 in Fig. 1.

Correlation belief transfer (only \(m_*(\{\theta _1\})\) and its transferred belief value are marked in the figure, \(m_*(\{\theta _2\})\) and \(m_*(\{\theta _3\})\) are similar to \(m_*(\{\theta _1\})\)).
Definition
Assume the FOD is \(\Omega =\left\{ \theta _1,\ \theta _2,\ \theta _3,\ \ldots \ ,\ \theta _i,\ \ldots \ ,\ \theta _n \right\} \), the power set of \(\Omega \) is \(2^{\Omega }\). m is a BBA on \(\Omega \) and \(m_*\) is the modified BBA by belief gathering in section “Belief gathering”. In this step, the single subset proposition \(\alpha _i\) transferred its belief to the multi-subset propositions \(\beta _j\) where \(\alpha _i \subset \beta _j\), and the result is called the transferred BBA marked as \(m_{**}\). \(m_t({\alpha _i \rightarrow \beta _j})\) is defined as the transferred belief value from single subset proposition \(\alpha _i\) to multi-subset proposition \(\beta _j\). The transferred BBA \(m_{**}\) of single subset propositions \(\alpha _i\) and multi-subset proposition \(\beta _j \) is defined as follows:
where \(\alpha _i, \beta _j \in 2^{\Omega },\ |\alpha _i|=1\), \(|\beta _j|>1\), n is the number of element in the FOD \(\Omega \).
Illustrative example
To better understand the process of correlation belief transfer, a simple illustrative example is presented. Assume FOD \(\Omega =\{\theta _1, \theta _2, \theta _3\}\), the power set of \(\Omega \) is \(2^{\Omega }\), \(2^{\Omega }=\left\{ \emptyset , \left\{ \theta _1 \right\} ,\left\{ \theta _2 \right\} ,\left\{ \theta _3 \right\} ,\left\{ \theta _1,\theta _2 \right\} ,\left\{ \theta _1,\theta _3 \right\} ,\left\{ \theta _2,\theta _3 \right\} ,\left\{ \theta _1,\theta _2,\theta _3 \right\} \right\} \). Since the problem is discussed in a closed world assumption, \(\emptyset \) is not taken into consideration. Suppose that the BBAs after belief gathering are given as follows: \(m_*(\{\theta _1\})=p_1,\ m_*(\{\theta _2\})=p_2,\ m_*(\{\theta _3\})=p_3\), where \(p_1,p_2,p_3\in \left( 0,1 \right) \) and \(\sum _{i=1}^3{p_i}=1\). For proposition \(\{\theta _1\}\), its belief should be transferred to the propositions \(\{\theta _1,\theta _2\},\{\theta _1, \theta _3\},\) and \( \{\theta _1,\theta _2,\theta _3\}\) based on the proposed method. And the transferred belief value is as follows:
The remaining belief of proposition \(\{\theta _1\}\) is \(m_{**}(\{\theta _1\})\), in other words, \(m_{**}(\{\theta _1\})= m_{*}(\{\theta _1\})-m_t({\{\theta _1\}\rightarrow \{\theta _1,\theta _2\}})-m_t({\{\theta _1\}\rightarrow \{\theta _1,\theta _3\}})-m_t({\{\theta _1\}\rightarrow \{\theta _1,\theta _2,\theta _3\}}) = p_1 - \frac{p_1}{\left( 2^3-1 \right) \times 2} - \frac{p_1}{\left( 2^3-1 \right) \times 2} - \frac{p_1}{\left( 2^3-1 \right) \times 3}\). Similarly, the proposition \(\{\theta _2\}\) and proposition \(\{\theta _3\}\) go through the same belief transfer process and \(m_{**}(\{\theta _2\})\), \(m_{**}(\{\theta _3\})\) are as follows:
For the proposition \(\{\theta _1, \theta _2\}\), it receives belief from proposition \(\{\theta _1\}\) and \(\{\theta _2\}\), therefore: \(m_{**}(\{\theta _1, \theta _2\})=m_t({\left\{ \theta _1 \right\} \rightarrow \left\{ \theta _1,\theta _2 \right\} })+m_t({\left\{ \theta _2 \right\} \rightarrow \left\{ \theta _1,\theta _2 \right\} })= \frac{p_1}{(2^3-1)\times 2}+\frac{p_2}{(2^3-1)\times 2}\). Similarly, the result of \(m_{**}(\{\theta _1, \theta _3\})\), \(m_{**}(\{\theta _2, \theta _3\})\), \(m_{**}(\{\theta _1, \theta _2, \theta _3\})\) is as follows:
The whole process of this example can be illustrated in Fig. 2.
Discussion of the correlation belief function
To summarize the above two steps of the correlation belief function, firstly, all the belief is put into the single subset propositions. The first step aims at gathering the belief for an easier decision-making and a convenient in transferring correlation belief. In the next step, the belief of single subset propositions is transferred to correlated multi-subset propositions. Note that in this assignment, the single subset proposition must be a subset of the multi-subset proposition. In other words, the intersection of the single subset proposition which supplies belief and the multi-subset proposition which receives belief is not empty set. The idea is that if the belief of proposition \(\{\theta _1\}\) is greater than 0, the belief of the proposition which contains \(\{\theta _1\}\) must also be greater than 0. For example, assuming that there are three opaque bags \(\{\theta _1\}\), \(\{\theta _2\}\), and \(\{\theta _3\}\), now there is a ball in one of these three bags at random. If this ball is in bag \(\{\theta _1\}\), now pack bag \(\{\theta _1\}\) and bag \(\{\theta _2\}\) in a larger bag \(\{\theta _1, \theta _2\}\). If it is stated that this ball is in bag \(\{\theta _1\}\), it is reasonable to assume that it is also in the larger bag \(\{\theta _1, \theta _2\}\). That is to say, if \( m\left( \{\theta _1\}\right) > 0 \), \( m\left( \{\theta _1,\theta _2\}\right) \) is also supposed to be greater than 0.
The most advantage of the correlation belief function is that it makes use of the source evidence information to eliminate the counterintuitive combination result. When the belief of some propositions is 0, there is often high conflict between the evidence, and the correlation belief function can address this issue well. If one of the data’s attributes has a value of 0 due to the fault, this method can transfer the related attribute value to it. If the value of its related attribute is also equal to 0, it is rational to believe that the sensors do not receive the signal about this attribute, and the collected data is reliable and effective. The proposed method is consistent with people’s intuition and greatly enhances the robustness of Dempster’s combination rule. In brief, even if the data collected are not accurate enough in a complex environment, it will not have a decisive impact on the final combination result, especially while processing a large amount of data.
Numerical examples
Start with conflicting evidence fusion based on Dempster’s combination rule.
Example 1
Define that the FOD is \( \Omega = \left\{ \theta _1, \theta _2, \theta _3 \right\} \) and two \( BBA_S \) are as follows:
If using Dempster’s combination rule to fuse the two \( BBA_S\) directly, the result will be counterintuitive:
Based on the proposed method in Eqs. (7)–(11), the modified \( BBA_S \) are calculated as follows.
Step 1: Belief gathering:
Step 2: Correlation belief transfer:
\(m_2\) is calculated in the same way. The modified \(BBA_S\) are given in Table 1.
The combination result compared with Dempster’s method is shown in Table 2.
From Table 2, it can be seen that the result of the proposed method is more reasonable than using Dempster’s combination rule directly.
As can be seen from the first piece of original evidence, \( m_1\left( \{\theta _1\}\right) \) is 0.99, which means that proposition \(\{\theta _1\}\) has a very high probability of happening. But when the first piece of evidence is combined with the other one, the result shows that \(m\left( \theta _1\right) \) is 0, which means proposition \(\{\theta _1\}\) is never going to happen. In other words, the first piece of evidence about proposition \(\{\theta _1\}\) is completely denied by the other one, thus losing its support on proposition \(\{\theta _1\}\). The main reason for this unreasonable result is that in the other piece of evidece, all propositions involving \(\{\theta _1\}\) have a belief of 0 ( \( m_2\left( \{\theta _1\}\right) = m_2\left( \{\theta _1,\theta _2\}\right) = m_2\left( \{\theta _1,\theta _3\}\right) = m_2\left( \{\theta _1,\theta _2,\theta _3\}\right) =0\) ). If we modify the original evidence like:
the fusion result is quite different:
Therefore, the proposed method, which transfers the belief from single subset propositions to correlated multi-subset propositions and maintains the support of the original belief as much as possible, is effective and reliable.
Example 2
Suppose that the FOD is \(\Omega =\left\{ \theta _1,\theta _2\right\} \), two \(BBA_S\) are given as follows:
Use the proposed method to modify the original \(BBA_S\), and get the result by using Dempster’s combination rule:
In this example, two pieces of evidence are completely conflicting and the classical Dempster’s combination rule cannot address this problem. However, by using the correlation belief function to modify the original \(BBA_S\), the result is satisfactory: proposition \(\{\theta _1\}\) and proposition \(\{\theta _2\}\) have equal belief, and proposition \(\{\theta _1,\theta _2\}\) is also given a tiny amount of belief. This example also embodies another crucial advantage of the correlation belief function that it can deal with completely conflicting evidence.
Example 3
Suppose that the FOD is \(\Omega = \left\{ \theta _1, \theta _2, \theta _3\right\} \), the \(BBA_s\) are given as follows:
From this example, it can be seen that although the first piece of evidence believes that proposition \(\{\theta _3\}\) can never happen, the latter two pieces of evidence have high belief in proposition \(\{\theta _3\}\). Thus, it’s reasonable to believe that the proposition \(\{\theta _3\}\) is still possible. However, the result with classical Dempster’s combination rule shows that \(m(\{\theta _3\})=0\), which is illogical and counterintuitive. After modifying the BBA by the proposed method, the fusion result is:
This result indicates that the belief of proposition \(\{\theta _3\}\) is higher than that of proposition \(\{\theta _1\}\) and proposition \(\{\theta _2\}\), which is in line with real situation. Although the belief value of multi-subset propositions is increased, it is very small and the effect on decision-making is slight.
Example 4
Suppose that the FOD is \(\Omega =\left\{ \theta _1, \theta _2, \theta _3\right\} \), the first piece of evidence and i-th piece of evidence are as follows19:
The combination result of \(m_1\) and \(m_i\) is always consistent with \(m_1\). Since Dempster’s combination rule satisfies association law, no matter how much evidence is added, the result is still consistent with \(m_1\), which means the subsequent evidence is invalid and the result is illogical. The correlation belief function can solve this problem effectively and the result is shown in Figs. 3 and 4.


Example 5
Suppose that the FOD is \( \Omega = \left\{ \theta _1, \theta _2\right\} \), two \(BBA_s\) are given as follows:
According to the proposed method, the modified \(BBA_s\) are as follows:
As can be seen that the proposed method does not increase the belief of proposition \(\{\theta _2\}\) because the belief of proposition \(\{\theta _2\}\) in the original evidence is 0, instead, the belief of proposition \(\{\theta _1,\theta _2\}\) is increased to 0.167, which is more reasonable. The result by using Dempster’s combination rule is as follows:
The result shows that proposition \(\{\theta _1\}\) has a very high degree of belief. The proposition \(\{\theta _1,\theta _2\}\) is given a small degree of belief, and there is no belief in the proposition \(\{\theta _2\}\). Compared with fusion result without evidence modification, the proposed method loses some belief in proposition \(\{\theta _1\}\), but the value of the belief is tiny and it can avoid counterintuitive fusion result in conflict data fusion.
Example 6
Suppose that the FOD is \(\Omega =\left\{ \theta _1,\theta _2,\theta _3\right\} \), two \(BBA_s\) are as follows:
The results of Dempster’s rule and proposed method are shown in Table 3.
The first piece of evidence strongly suggests that proposition \(\{\theta _1\}\) has a high belief of 0.9, and the proposition \(\{\theta _1,\theta _2,\theta _3\}\) also gives \(\{theta_1\}\) a small belief value. The second piece of evidence argues that proposition \(\{\theta _3\}\) has high belief of 0.9, but there is no other proposition supporting proposition \(\{\theta _3\}\) (i.e., \(\{\theta _1,\theta _3\}=\{\theta _2,\theta _3\}=\{\theta _1,\theta _2,\theta _3\}=0\)). Therefore, in the final combination result, the belief of proposition \(\{\theta _1\}\) is slightly higher than that of proposition \(\{\theta _3\}\), which is opposite to the classical Dempster’s method. In addition, the results of Murphy’s method74 and Abellán75 method are similar to the proposed method, which further demonstrating the effectiveness of the new method.
Application in classification
In this section, the classification experiments with real data sets are performed to evaluate the effectiveness of the proposed method. The real data sets are from UCI Machine Learning Repository. The classification process is as follows. Firstly, 80% of the dataset is selected as the training set to generate triangular fuzzy number models. Secondly, the triangular fuzzy number models are used to generate BBA for the remaining 20% data. Then, the proposed correlation belief function, which is composed of belief gathering and correlation belief transfer, is used to modify the evidence, and the Dempster’s combination rule is used to fuse the modified BBAs. Finally, the fused BBA is transformed as belief of single set based on pignistic probability transformation, and the single subset proposition with the highest belief is the classification category. Figure 5 shows the flowchart of the proposed method in classification.

The flowchart of correlation belief function-based classification method.
Iris data set classification
In the data set of Iris, there are three species (Setosa(\(\theta _1\)), Versicolor(\(\theta _2\)), Virginica(\(\theta _3\))) with 50 examples of each species. Each sample contains 4 attributes named sepal length (SL), sepal width (SW), petal length (PL), and petal width (PW) which can be treated as the information source to build BBA. 40 samples in each category are randomly selected as training set to generate triangular fuzzy numbers and the result is shown in Table 4. The remaining 10 samples are considered as the test set to verify the effectiveness of the proposed method. In the following contents, a sample is used to illustrate the process of data fusion and the complete classification result of the Iris data set will be shown in Table 7.
Firstly, one test sample from Setosa(\(\theta _1\)) is randomly selected and its BBA generated from triangular fuzzy number model is shown in Table 5. Next, the BBA is modified by correlation belief function and the result is shown in Table 6. Finally, the complete classification result of the test set is shown in Table 7.
Table 5 exhibits that the BBA entail certain conflict information. Specifically, in the evidence derived from the SL and SW attributes, the belief value is distributed evenly across propositions \(\{\theta _1\}\), \(\{\theta _2\}\), and \(\{\theta _3\}\), rendering it arduous for the decision maker to reach a cogent judgment based on these two pieces of evidence. Conversely, in the evidence generated by the PL and PW attributes, the proposition \(\{\theta _1\}\) has a higher level of belief degree, while the proposition \(\{\theta _3\}\) is deemed entirely untrustworthy, creating a contradiction with the SL and SW evidence. Consequently, an optimal combination outcome ought to facilitate the decision maker’s discernment while preserving the original conflict information, thereby aiding future policy formulation.
As can be seen from Table 6, all results believe that the sample belongs to class \(\theta _1\), which is in line with the actual situation. Although Dempster’s combination rule has the highest belief for proposition \(\{\theta _1\}\), it’s illogical that it has the belief value of 0 for the proposition \(\{\theta _3\}\). Yager’s method has no big belief value and is not conducive to decision-making, because the result indicates that there may be other proposition besides propositions \(\{\theta _1\}\), \(\{\theta _2\}\) and \(\{\theta _3\}\). This method has betrayed its original purpose for indicating the degree of belief in certain propositions. Wang et al’s method has a right result in conflict management. However, the most disadvantage is that the unimportant propositions are also given a big belief value. The proposed method has a more satisfactory result. The proposition \(\{\theta _3\}\) is still considered possible. Although the belief value on \(m(\{\theta _3\})\) is low, the sense is significant that conflict information should not be ignored directly. Compared with the Wang et al.’s method, the proposed method maintains a higher degree of indicating the potential and right target.
The advantage of the proposed method can also be seen from Table 7. Only two samples are not classified correctly, and the total classification accuracy can reach 93.33%. Besides, in most cases of correctly classified, the maximum value of BBA is significantly higher than the other two classes. For example, in classification of Setosa(\(\theta _1\)), the value of \(m_{**}(\{\theta _1\})\) is much larger than \(m_{**}(\{\theta _2\})\) and \(m_{**}(\{\theta _3\})\). Above all, the correlation belief function addresses the issue of conflicting data fusion rightly and properly.
Wine data set classification
In this experiment, Wine data set is used to further verify the effectiveness of the proposed method. The Wine data set contains 3 different varieties of wine and each has 13 attributes. In Wine data set, there are 59 samples in class \(\theta _1\), 71 samples in class \(\theta _2\), and 48 samples in class \(\theta _3\).
As with the Iris experiments, a test sample is chosen to demonstrate the effectiveness of the proposed method. Besides, to further test the performance of the proposed method on classification problem, the cross-validation method in machine learning is introduced to divide the dataset. For the Wine dataset, 10-times-5-fold cross-validation method is adopted and the its process is as follows.
-
1.
Randomly shuffle the dataset. Divide the Wine data set D into five mutually exclusive subsets (\(D_i, i=1,2,\ldots ,5\)) of the same size. In brief, \(D=\bigcup _{i=1}^5{D_i}\), \(\bigcap _{i=1}^5{D_i=\emptyset }\) and \(|D_i|=\frac{D}{5}, i = 1,2,\ldots ,5\).
-
2.
Take one of the subsets (\(D_i, i= 1,\ldots ,5\)) as the test set and the other four subsets as the training set, and then calculate the classification accuracy. Repeat this step five times, each time with a different test set. In other words, \(D_1\) is selected as the test set for the first time, \(D_2-D_5\) are selected as the training set. For the second time, \(D_2\) is selected as the test set, \(D_1\), \(D_3-D_5\) are selected as the training set \(\cdots \) \(D_5\) is selected as the test set for the fifth time, \(D_1-D_4\) are selected as the training set.
-
3.
Repeat the previous step ten times to obtain the average classification accuracy number.
The purpose of K-fold cross-validation is to make full use of the available data, avoid errors caused by randomness, and make the evaluation results as close as possible to the generalization ability of the model.
Firstly, the original BBAs generated by triangular fuzzy number are shown in Table 8 and they are visually displayed in Fig. 6. Next, the result modified by the proposed method is compared with other methods and shown in Table 9. Finally, the classification accuracy resulting from 10-times-5-fold cross-validation is shown in Table 10.

Distribution of BBA in Wine data set.
Similarly, analogous to the BBAs in the Iris experiment, diverse pieces of evidence in the real-world often have disparate classification perspectives, thus, significantly compromising the accuracy of individuals’ sample category judgments. For instance, as illustrated in Table 8, the evidence produced by the Hue and Proline attributes neglects the notion and the sample should be assigned to category \(\theta _1\), while the Malic acid and Alkalinity of ash features hold a different viewpoint, that is, proposition \(\{\theta _1\}\) has a higher belief value. In addition, although all evidence provides belief for proposition \(\{\theta _2\}\), there are also significant differences in its values. To remedy these conflicts, the proposed methodology provides a plausible elucidation for the conflicting evidence while preserving the conflicting information of the original evidence.
As shown in Table 9, the result given by only using Dempster’s combination rule is too absolute and hard. It believes that the proposition \(\{\theta _2\}\) has 100% belief degree, while the belief of other propositions is 0, which is illogical because Fig. 6 indicates that proposition \(\{\theta _1\}\) also has certain belief value. In addition, Dempster’s method is less robust since if one piece of evidence is wrong, the conflict coefficient is likely to be 1, and the process of data fusion cannot be carried out. Yager’s method also has the disadvantage of Dempster’s method that it only reduces the belief value proportionally. And due to the multiple combinations, the belief of some propositions is too tiny to provide useful information, which means that most information is lost in the fusion process. Deng et al.’s method works well in this experiment. However, the main problem is that it assigns a large amount of belief to unimportant propositions, which reduces the belief value of important propositions and is unfavorable in decision-making.
When the data collected from a few sensors are in conflict, it is more likely that some sensors are not accurate. However, if many sensors indicate that there is conflict in data, it’s reasonable to believe that some unusual conditions do exist. The proposed method solves this issue well. Firstly, it does not lose information in representing the main propositions, and the information is expressed through the single subset propositions as much as possible for an easier decision-making process. Secondly, when dealing with conflicting information, this method also takes it into consideration and expresses it in the combination result. The most important thing is that this method uses all the information when fusing data, and it is in line with people’s cognition. The combination result in Table 8 shows the superiority of the proposed method. Compared with the other methods, the proposed method gives certain belief to the proposition \(\{\theta _1\}\) and \(\{\theta _3\}\) respectively to avoid conflict information. Meanwhile, it does not reduce the belief degree of the proposition \(\{\theta _2\}\) significantly, which is of great help in decision-making. Furthermore, it can be seen from Table 10 that the average accuracy of classification can reach 86.25%, and the accuracy fluctuates up and down at 86% in each case, with the lowest of 85.38% and the highest of 87.14%. The result indicates the effectiveness and stability of the proposed method.
Metrics of classification results
To further evaluate the performance of the proposed method in the classification problem, different metrics in machine learning are adopted to measure the classification results.
The metrics are listed as follows.
-
Precision: The ability of a classification model to identify only the relevant data points.
$$\begin{aligned} Precision = \frac{TP}{TP+FP} \end{aligned}$$ -
Recall: The ability of a model to find all the relevant cases within a data set.
$$\begin{aligned} Recall = \frac{TP}{TP + FN} \end{aligned}$$ -
Accuracy: Proportion of data correctly judged by the model in the total data.
$$\begin{aligned} Accuracy = \frac{TP+TN}{TP+TN+FP+FN} \end{aligned}$$ -
F1-score: The harmonic mean of precision and recall.
$$\begin{aligned} F_1 = 2\times \frac{Precision \times Recall}{Precision + Recall} \end{aligned}$$
True positive (TP) means that the prediction is correct and the real value is positive. False positive (FP) means that the prediction is incorrect and the real value is negative. True negative (TN) means that the prediction is correct and the real value is negative. False negative (FN) means that the prediction is incorrect and the real value is positive. Based on the aforementioned metrics, the Macro-averaging (Macro-avg, the arithmetic average) parameters (\(Macro\_P\), \(Macro\_R\), \(Macro\_{F_1}\)) and Weighted-averaging (Weighted-avg, the weighted average) parameters (\(Weighted\_P\), \(Weighted\_R\), \(Weighted\_{F_1}\)) for indicators of each category are denoted as follows.
where \(Precision_i\), \(Recall_i\) and \(F_{1i}\) are the Precision, Recall and \(F_1\) of the i-th category respectively, \(W_i=\frac{\text {number of the i-th category}}{\text {total number of data}}\).
The results for these metrics on the Iris data set and Wine data set are shown in Tables 11 and 12.
Table 11 reports the results of the proposed method for different classification metrics on the Iris data set. It shows that the proposed method is good in all metrics of class \(\theta _1\), and the recall rate is equal to the precision rate and reaches 93.33% for both macro-averaging metrics and weighted-averaging metrics. Therefore, for samples with balanced data and clear classification boundaries like the Iris data set, the proposed method can utilize the information and address the uncertainty well.
The proposed method also has unique advantages for samples with many attributes and imbalance data such as the Wine data set. As shown in Table 12, the accuracy rate increases as the number of samples in a category increases. The precision rate is also slightly higher than the recall rate in terms of the weighted-averaging metric, which means that the proposed method is more adaptable in scenarios where false negative samples should be avoided, such as spam blocking systems.
Discussion
Robustness of the proposed method in classification problem
In this section, the robustness of the proposed method in classification problems is discussed. If an algorithm performs well in the classification accuracy of the test set regardless of the large proportion of the training set or the small proportion of the training set, it indicates that the algorithm has strong robustness.
The Iris data set is selected to obtain the classification accuracy of the test set under different proportions of the training set by performing 10 times randomized leave-out method, and the result is shown in Table 13. Each column of the table represents the result of the n-th leave-out method, and each row of the table represents the result of the training set with different proportions. For a more visual presentation of the result, Fig. 7 visualizes Table 13, where the higher the accuracy, the higher the column and the more the color of the column is skewed towards yellow. The overall trend in Fig. 7 shows that the classification accuracy increases as the proportion of the training set becomes larger, and the accuracy is mostly above 90%, which illustrates the strong robustness of the proposed method.
To further illustrate the effectiveness of the proposed method, the average classification accuracy for each proportion of the training set is calculated. The result compared with Wang’s base belief function77 is shown in Fig. 8. It can be seen that in most cases, the red solid line (the proposed method) is above the blue dotted line (Wang’s method), which means that the proposed method has a better performance in classification problem. In addition, the trend of polyline indicates that the larger the proportion of the training set, the higher the classification accuracy. When the proportion exceeds 40%, the classification accuracy of the proposed method can reach 90.44%. However, when the proportion exceeds 80%, the classification accuracy is difficult to be greatly improved. The results of this experiment accord with the practical application.

The classification accuracy of different proportions of the training set.

The average accuracy of the different proportions of the training set and the comparison of different methods.
Comparative analysis in classification problem
In this section, the proposed method will be compared with Abellán’s method75, Jing and Tang’s method79, Wang’s method77, Murphy’s method74, Yager’s method76 and Dempster’s method34 to further demonstrate the superiority of this method in classification problems. In the experiments, four datasets are adopted, namely the Iris data set, the Wine data set, the Seed data set and the Penguins dataset. The Iris and Wine data sets have been introduced in sections “Iris data set classification” and “Wine data set classification”. For the Seeds data set, it comes from UCI Machine Learning Repository and consists of three classes: \(\theta _1\), \(\theta _2\), \(\theta _3\), and each class contains 70 samples with 7 attributes. The Penguins data set is from Palmer Station Antarctica LTER and it also consists of three classes: \(\theta _1\), \(\theta _2\), \(\theta _3\), while class \(\theta _1\) contains 151 samples, class \(\theta _2\) contains 123 samples and class \(\theta _3\) contains 68 samples. Each sample has 2 attributes.
For each data set, stratified sampling is adopted, 80% of the data is used as the training set, and the remaining 20% of the data is used as the test set. Results of the comparative experiment in each data set are show in Figs. 9, 10, 11 and 12 respectively. Each color of the histogram represents a category, the length of the column represents its classification accuracy, and the value to the right of the dotted line marks the classification accuracy of the most effective method.
As can be seen from Figs. 9, 10, 11 and 12, the proposed method can achieve the highest classification accuracy in all datasets. Although the proposed method does not necessarily achieve the highest accuracy in classifying samples of a certain class of a dataset, it still achieve the highest classification accuracy in a complete data set. For example, both Abellán’s method and Yager’s method outperform the proposed method in classifying class \(\theta _1\) of the Wine dataset, but for the complete Wine dataset classification, the proposed method can achieves the highest accuracy. The comparative analysis further demonstrate the superiority and stability of the proposed method.

Comparison of different methods accuracy on the Iris data set.

Comparison of different methods accuracy on Wine data set.

Comparison of different methods accuracy on seeds data set.

Comparison of different methods accuracy on penguins data set.
The experimental results and comparative study show that different methods have their own advantages and disadvantages in conflict management. Yager’s method76 is unique and it modifies the combination rule and maintains the original excellent mathematical properties. However, it is still unreasonable to simply put the belief of the conflict into the unknown part, and from Tables 6 and 9 and the classification results, the result of this method is not very prominent. Murphy’s method74 averages the belief of all evidence and then fused them. Averaging is an effective method to solve the normalization problem in combination, but different pieces of evidence often have different weights and simply performing arithmetic averaging will lose the specificity of the evidence. Abellán et al.’s method75 proposed a hybrid rule to calculate the maximum conflict between two sets of evidence and then combine it with averaging. Although it appears to perform well, the method must assume that the data source is completely reliable, which is often not guaranteed in real world. Wang et al.’s method77 adds the base belief to all propositions so that the belief of each proposition is not zero when evidence is fused. It solves the conflicting data fusion problem. However, since each proposition has the base belief value, it often introduces more uncertainty. Jing and Tang79 modifies this method to some extent by adding base belief for only the single subset propositions and combining it with Bayesian probability, but still suffers from the same problem of77. The proposed method can effectively solve the conflicting data fusion problem and has a good performance in classification applications. Nevertheless, the method is still not completely confident in delineating clear classification boundaries in the classification of samples with multiple attributes and large data volumes, which is worth of further study. The correlation belief function can integrate propositions with a large probability of occurrence and provide decisions in complex and uncertain environment.
Conclusions
When conflicting evidence is fused by using the classical Dempster’s combination rule, a counterintuitive result may be produced. To solve this problem, a new correlation belief function is proposed for conflict management in this paper. It first gathers all the belief in the single subset propositions, and then transfers the belief of the single subset propositions to the related multi-subset propositions. The proposed method has two main advantages. Firstly, it can fully utilize the acquired information and avoid obtaining counterintuitive results generated by the information loss; secondly, compared with other methods, the proposed method can better address the conflicting information among data in the fusion result. A series of numerical examples validate the effectiveness of the proposed method in conflict management problems. The correlation belief function-based classification method has a good performance in classification applications. In the robustness test, the method can obtain high accuracy even with a small number of sample of training set. For example, the classification accuracy can reach 84.67% even if the proportion of the training set is only 20%. In addition, different data sets are tested and the results showed that the proposed classification method has a higher classification accuracy compared to other methods.
The following work can focus on addressing the following open issues. First, the time complexity of the classical Dempster’s combination rule is not satisfaction, which leads to a similar problem in the proposed method59. Second, this method can only be applied to the closed world assumption and the incomplete frame of discernment can be taken into consideration in the future42. Third, there is a broad research scope to apply the proposed correlation function to model uncertainty in other applications such as expert system53. Finally, the proposed method should be adopted to address more complex classification problems.
Data availability
All data are included in the manuscript.
References
Kayabol, K. Approximate sparse multinomial logistic regression for classification. IEEE Trans. Pattern Anal. Mach. Intell. 42(2), 490–493 (2019).
Kim, K. Normalized class coherence change-based knn for classification of imbalanced data. Pattern Recogn. 120, 108126 (2021).
Xu, L., Raitoharju, J., Iosifidis, A. & Gabbouj, M. Saliency-based multilabel linear discriminant analysis. IEEE Trans. Cybern. 52, 10200–10213 (2021).
Yang, C., Sung-Kwun, O., Yang, B., Pedrycz, W. & Wang, L. Hybrid fuzzy multiple svm classifier through feature fusion based on convolution neural networks and its practical applications. Expert Syst. Appl. 202, 117392 (2022).
Sun, J. et al. Random shapley forests: Cooperative game based random forests with consistency. IEEE Trans. Cybern. 52(1), 205–214 (2022).
Jeyasothy, A., Suresh, S., Ramasamy, S. & Sundararajan, N. Development of a novel transformation of spiking neural classifier to an interpretable classifier. IEEE Trans. Cybern. 2022, 56 (2022).
Cong, X., Li, X. & Yang, M. An orthogonal classifier for improving the adversarial robustness of neural networks. Inf. Sci. 591, 251–262 (2022).
Porebski, S. Evaluation of fuzzy membership functions for linguistic rule-based classifier focused on explainability, interpretability and reliability. Expert Syst. Appl. 199, 117116 (2022).
Yang, L.-H. et al. Highly explainable cumulative belief rule-based system with effective rule-base modeling and inference scheme. Knowl.-Based Syst. 240, 107805 (2022).
Wang, Yu., Qinghua, H., Chen, H. & Qian, Y. Uncertainty instructed multi-granularity decision for large-scale hierarchical classification. Inf. Sci. 586, 644–661 (2022).
Salem, O. A. M., Liu, F., Chen, Y.-P.P., Hamed, A. & Chen, X. Fuzzy joint mutual information feature selection based on ideal vector. Expert Syst. Appl. 193, 116453 (2022).
Subhashini, L. D. C. S., Li, Y., Zhang, J. & Atukorale, A. S. Integration of fuzzy logic and a convolutional neural network in three-way decision-making. Expert Syst. Appl. 202, 117103 (2022).
Sun, L., Wang, T., Ding, W., Xu, J. & Tan, A. Two-stage-neighborhood-based multilabel classification for incomplete data with missing labels. Int. J. Intell. Syst. 37, 6773–6810 (2022).
Sağlam, F., Yıldırım, E. & Cengiz, M. A. Clustered bayesian classification for within-class separation. Expert Syst. Appl. 208, 118152 (2022).
Yao, J., Zhongyi, L. W., Wang, M. L., Jiang, H. & Chen, Y. Novel hybrid ensemble credit scoring model with stacking-based noise detection and weight assignment. Expert Syst. Appl. 198, 116913 (2022).
Zhang, P. et al. A data-level fusion model for unsupervised attribute selection in multi-source homogeneous data. Inf. Fusion 80, 87–103 (2022).
Zhang, L. & Xiao, F. A novel belief chi (2) divergence for multisource information fusion and its application in pattern classification. Int. J. Intell. Syst. 37, 7968 (2022).
Wang, P., Ji, H. & Liu, L. Consistent fusion method with uncertainty elimination for distributed multi-sensor systems. Inf. Sci. 595, 378–394 (2022).
Zhang, X., Tang, Y., & Zhou, D. A new correlation belief transfer method in the evidence theory. In 2022 IEEE International Conference on Systems, Man, and Cybernetics (SMC), IEEE 3204–3209 (2022).
Zeshui, X. & Zhao, N. Information fusion for intuitionistic fuzzy decision making: An overview. Inf. Fusion 28, 10–23 (2016).
Gou, X., Liao, H., Zeshui, X. & Herrera, F. Double hierarchy hesitant fuzzy linguistic term set and multimoora method: A case of study to evaluate the implementation status of haze controlling measures. Inf. Fusion 38, 22–34 (2017).
Chao, F., Hou, B., Chang, W., Feng, N. & Yang, S. Comparison of evidential reasoning algorithm with linear combination in decision making. Int. J. Fuzzy Syst. 22(2), 686–711 (2020).
Xiao, F. Efmcdm: Evidential fuzzy multicriteria decision making based on belief entropy. IEEE Trans. Fuzzy Syst. 99, 1–1 (2019).
Liu, Z., Zhang, X., Niu, J. & Dezert, J. Combination of classifiers with different frames of discernment based on belief functions. IEEE Trans. Fuzzy Syst. 29(7), 1764–1774 (2021).
Zhun-Ga, Y. L., Liu, J. D. & Cuzzolin, F. Evidence combination based on credal belief redistribution for pattern classification. IEEE Trans. Fuzzy Syst. 28(4), 618–631 (2020).
Hui, K. H., Lim, M. H., Leong, M. S. & Al-Obaidi, S. M. Dempster-shafer evidence theory for multi-bearing faults diagnosis. Eng. Appl. Artif. Intell. 57, 160–170 (2017).
Lin, Y., Li, Y., Yin, X. & Dou, Z. Multisensor fault diagnosis modeling based on the evidence theory. IEEE Trans. Reliab. 67(2), 513–521 (2018).
Zhang, H. & Deng, Y. Weighted belief function of sensor data fusion in engine fault diagnosis. Soft. Comput. 24(3), 2329–2339 (2020).
Chemweno, P., Pintelon, L., Muchiri, P. N. & Van Horenbeek, A. Risk assessment methodologies in maintenance decision making: A review of dependability modelling approaches.. Reliab. Eng. Syst. Saf. 173, 64–77 (2018).
Tang, Y., Tan, S. & Zhou, D. An improved failure mode and effects analysis method using belief jensen-shannon divergence and entropy measure in the evidence theory. Arab. J. Sci. Eng. 48, 7163–7176 (2023).
Song, Y., Wang, X., Zhu, J. & Lei, L. Sensor dynamic reliability evaluation based on evidence theory and intuitionistic fuzzy sets. Appl. Intell. 48(11), 3950–3962 (2018).
Dutta, P. Modeling of variability and uncertainty in human health risk assessment. MethodsX 4, 76–85 (2017).
Seiti, H. & Hafezalkotob, A. Developing pessimistic-optimistic risk-based methods for multi-sensor fusion: An interval-valued evidence theory approach. Appl. Soft Comput. 72, 609–623 (2018).
Dempster, A. P. Upper and lower probabilities induced by a multivalued mapping. Ann. Math. Stat. 38(2), 325–339 (1967).
Shafer, G. A Mathematical Theory of Evidence (Princeton University Press, 1976).
Frikha, A. & Moalla, H. Analytic hierarchy process for multi-sensor data fusion based on belief function theory. Eur. J. Oper. Res. 241(1), 133–147 (2015).
Fei, L. & Deng, Y. A new divergence measure for basic probability assignment and its applications in extremely uncertain environments. Int. J. Intell. Syst. 34(4), 584–600 (2019).
Ebrahimnejad, A., & Verdegay, J. Fuzzy Sets-Based Methods and Techniques for Modern Analytics, volume 364 (Springer, 2018).
Jiang, J., Yin, E., Wang, C., Minpeng, X. & Ming, D. Incorporation of dynamic stopping strategy into the high-speed ssvep-based bcis. J. Neural Eng. 15(4), 046025 (2018).
Xiao, F. A multiple-criteria decision-making method based on d numbers and belief entropy. Int. J. Fuzzy Syst. 21(4), 1144–1153 (2019).
Kang, B. et al. Environmental assessment under uncertainty using dempster?shafer theory and z-numbers. J. Ambient Intell. Hum. Comput. 11(5), 2041–2060 (2020).
Deng, Y. Generalized evidence theory. Appl. Intell. 43(3), 530–543 (2015).
Jiang, W. & Zhan, J. A modified combination rule in generalized evidence theory. Appl. Intell. 46(3), 630–640 (2017).
Srivastava, A. & Kaur, L. Uncertainty and negation-information theoretic applications. Int. J. Intell. Syst. 34(6), 1248–1260 (2019).
Xiaoyan, S., Li, L., Qian, H., Mahadevan, S. & Deng, Y. A new rule to combine dependent bodies of evidence. Soft. Comput. 23(20), 9793–9799 (2019).
Jiao, L., Wang, F., Liu, Z. & Pan, Q. Tecm: Transfer learning-based evidential c-means clustering. Knowl.-Based Syst. 257, 109937 (2022).
Jiao, L., Yang, H., Liu, Z. & Pan, Q. Interpretable fuzzy clustering using unsupervised fuzzy decision trees. Inf. Sci. 611, 540–563 (2022).
Liu, Z.-G., Huang, L.-Q., Zhou, K. & Denoeux, T. Combination of transferable classification with multisource domain adaptation based on evidential reasoning. IEEE Trans. Neural Netw. Learn. Syst. 32(5), 2015–2029 (2021).
Razi, S., Mollaei, M. K. & Ghasemi, J. A novel method for classification of bci multi-class motor imagery task based on dempster-shafer theory. Inf. Sci. 484, 14–26 (2019).
Xiaobin, X., Zhang, Y. D., Bai, L. C. & Li, J. Evidence reasoning rule-based classifier with uncertainty quantification. Inf. Sci. 516, 192–204 (2020).
Liu, J., Li, Q., Chen, W. & Wang, X. A fast fault diagnosis method of the pemfc system based on extreme learning machine and dempster-shafer evidence theory. IEEE Trans. Transp. Electrif. 5(1), 271–284 (2018).
Kari, T., Gao, W., Zhao, D., Zhang, Z. & Le, L. An integrated method of anfis and dempster-shafer theory for fault diagnosis of power transformer. IEEE Trans. Dielectr. Electr. Insul. 25(1), 360–371 (2018).
Cao, Y., Zhou, Z. J., Chang, H. H., Tang, S. W. & Wang, J. A new approximate belief rule base expert system for complex system modelling. Decis. Support Syst. 150, 113558 (2021).
Luo, J., Shi, L. & Ni, Y. Uncertain power flow analysis based on evidence theory and affine arithmetic. IEEE Trans. Power Syst. 33(1), 1113–1115 (2017).
Xie, C., Bai, J., Zhu, W., Lu, G., & Wang, H. Lightning risk assessment of transmission lines based on ds theory of evidence and entropy-weighted grey correlation analysis. In 2017 IEEE Conference on Energy Internet and Energy System Integration (EI2), IEEE 1–6 (2017).
Chao, F., Dong-Ling, X. & Xue, M. Determining attribute weights for multiple attribute decision analysis with discriminating power in belief distributions. Knowl.-Based Syst. 143, 127–141 (2018).
Fei, L., Jiandong, L. & Feng, Y. An extended best-worst multi-criteria decision-making method by belief functions and its applications in hospital service evaluation. Comput. Ind. Eng. 142, 106355 (2020).
Fei, L., Feng, Y. & Liu, L. On pythagorean fuzzy decision making using soft likelihood functions. Int. J. Intell. Syst. 34(12), 3317–3335 (2019).
Yang, Y., Han, D. & Dezert, J. Basic belief assignment approximations using degree of non-redundancy for focal element. Chin. J. Aeronaut. 32(11), 2503–2515 (2019).
Deng, Y. Uncertainty measure in evidence theory. Sci. China Inf. Sci. 63(11), 1–19 (2020).
Jiang, W. A correlation coefficient for belief functions. Int. J. Approx. Reason. 103, 94–106 (2018).
Jiroušek, R. & Shenoy, P. P. On properties of a new decomposable entropy of dempster-shafer belief functions. Int. J. Approx. Reason. 119, 260–279 (2020).
Tang, Y., Chen, Y. & Zhou, D. Measuring uncertainty in the negation evidence for multi-source information fusion. Entropy 24(11), 1596 (2022).
Gao, X., Liu, F., Pan, L., Deng, Y. & Tsai, S.-B. Uncertainty measure based on tsallis entropy in evidence theory. Int. J. Intell. Syst. 34(11), 3105–3120 (2019).
Deng, X. & Jiang, W. A total uncertainty measure for d numbers based on belief intervals. Int. J. Intell. Syst. 34(12), 3302–3316 (2019).
Deng, Z. & Wang, J. Measuring total uncertainty in evidence theory. Int. J. Intell. Syst. 36(4), 1721–1745 (2021).
Moral-García, S. & Abellán, J. Required mathematical properties and behaviors of uncertainty measures on belief intervals. Int. J. Intell. Syst. 36, 8 (2021).
Geng, X., Liang, Y. & Jiao, L. Earc: Evidential association rule-based classification. Inf. Sci. 547, 202–222 (2021).
Wang, Z., Wang, R., Gao, J., Gao, Z. & Liang, Y. Fault recognition using an ensemble classifier based on dempster-shafer theory. Pattern Recogn. 99, 107079 (2020).
Zhi-gang, S., Qinghua, H. & Denoeux, T. A distributed rough evidential k-nn classifier: Integrating feature reduction and classification. IEEE Trans. Fuzzy Syst. 29(8), 2322–2335 (2020).
Li, N., Martin, A. & Estival, R. Heterogeneous information fusion: Combination of multiple supervised and unsupervised classification methods based on belief functions. Inf. Sci. 544, 238–265 (2021).
Tong, Z., Philippe, X. & Denoeux, T. An evidential classifier based on dempster-shafer theory and deep learning. Neurocomputing 450, 275–293 (2021).
Smets, P. & Kennes, R. The transferable belief model. Artif. Intell. 66(2), 191–234 (1994).
Murphy, C. K. Combining belief functions when evidence conflicts. Decis. Support Syst. 29(1), 1–9 (2000).
Abellán, J., Moral-García, S. & Benítez, M. D. Combination in the theory of evidence via a new measurement of the conflict between evidences.. Expert Syst. Appl. 178, 114987 (2021).
Yager, R. R. On the dempster-shafer framework and new combination rules. Inf. Sci. 41(2), 93–137 (1987).
Wang, Y., Zhang, K. & Deng, Y. Base belief function: An efficient method of conflict management. J. Ambient Intell. Humaniz. Comput. 10(9), 3427–3437 (2019).
Yong, D., Wenkang, S., Zhenfu, Z. & Qi, L. Combining belief functions based on distance of evidence. Decis. Support Syst. 38(3), 489–493 (2004).
Jing, M. & Tang, Y. A new base basic probability assignment approach for conflict data fusion in the evidence theory. Appl. Intell. 51(2), 1056–1068 (2021).
Funding
The work was supported by the Natural Science Basic Research Program of Shaanxi (Program No. 2023-JC-QN-0689) and NWPU Research Fund for Young Scholars (Grant No. G2022WD01010).
Author information
Authors and Affiliations
Contributions
Y.T.: conceptualization, methodology, validation, writing—original draft preparation, writing—reviewing and editing. X.Z.: conceptualization, methodology, visualization, data curation, validation, writing—original draft preparation. Y.Z.: methodology, validation, writing—original draft preparation. Y.H.: methodology, validation, writing—original draft preparation. D.Z.: conceptualization, supervision, validation.
Corresponding author
Ethics declarations
Competing interests
The authors declare no competing interests.
Additional information
Publisher's note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Tang, Y., Zhang, X., Zhou, Y. et al. A new correlation belief function in Dempster-Shafer evidence theory and its application in classification. Sci Rep 13, 7609 (2023). https://doi.org/10.1038/s41598-023-34577-y
Received:
Accepted:
Published:
DOI: https://doi.org/10.1038/s41598-023-34577-y
Comments
By submitting a comment you agree to abide by our Terms and Community Guidelines. If you find something abusive or that does not comply with our terms or guidelines please flag it as inappropriate.
