
Abstract
Heat networks play a vital role in the energy sector by offering thermal energy to residents in certain countries. Effective management and optimization of heat networks require a deep understanding of users' heat usage patterns. Irregular patterns, such as peak usage periods, can exceed the design capacities of the system. However, previous work has mostly neglected the analysis of heat usage profiles or performed on a small scale. To close the gap, this study proposes a data-driven approach to analyze and predict heat load in a district heating network. The study uses data from over eight heating seasons of a cogeneration DH plant in Cheongju, Korea, to build analysis and forecast models using supervised machine learning (ML) algorithms, including support vector regression (SVR), boosting algorithms, and multilayer perceptron (MLP). The models take weather data, holiday information, and historical hourly heat load as input variables. The performance of these algorithms is compared using different training sample sizes of the dataset. The results show that boosting algorithms, particularly XGBoost, are more suitable ML algorithms with lower prediction errors than SVR and MLP. Finally, different explainable artificial intelligence approaches are applied to provide an in-depth interpretation of the trained model and the importance of input variables.
Similar content being viewed by others

Introduction
District heating (DH) has risen as a crucial energy supply infrastructure in order to effectively provide heat and cooling to consumers over the last few decades1. DH is superior in many aspects compared to other energy supply options, which include having a lower carbon footprint, the integration of multiple heat sources, and high energy throughput. The latest fourth and fifth generations of DH can utilize several heat sources, which include combined heat and power (CHP), gas boilers, water-source heat pumps (HPs), ground-source HPs, and solar energy-based HPs. The recent literature focused more on developing simulation frameworks and effective approaches in regards to designing and optimizing DH systems in terms of the economic and energetic factors, which is due to the fast development of DH technologies2,3. Storage technology is also a hot topic, because it helps decouple heat production and the demand to increase DH efficiency4. The following articles1,5 were reviewed in order to obtain the latest information about DH networks.
The heat usage pattern analysis has become increasingly essential as the number of end-users increases, because it greatly impacts the entire network's efficiency. Variations in the heat usage behavior from the consumers' side lead to variations in the heat usage pattern of a single substation, which is a major matter for accurate and efficient DH management and operation6. For example, the substantial temperature difference between the summer and the winter significantly influences the users' heat demand. In addition, the hourly heat demand also varies between households, which causes heat demand variation at the substation7.
An accurate heat demand prediction framework is imperative in order to effectively manage DH networks8. First, it facilitates the optimization of the overall heat production, minimizes the heat loss, and optimizes the operating costs. Second, the distribution temperature is provided at an appropriate range in order to predict the real-time heat usage using the heat demand forecast model. As a result, the number of studies proposed in regards to predicting the heat demand has been increasing. A heat demand analysis can generally be divided into model-based and data correlation categories9. The data correlation approach mainly depends on building functional correlations of the DH parameters in order to develop a heat usage profile for each substation or building. The model-based technique relies on machine learning (ML) algorithms in order to effectively learn the representative patterns using the historical heat load data10. The data correlation approach offers higher accuracy than the model-based approach, but it is time-consuming and laborious due to each building/substation having a unique heat usage profile that needs to be constructed. The performance of the model-based heat usage prediction algorithm has become significantly better, which is due to the huge advancements in artificial intelligence (AI) and big data over the past few decades9,10.
The heat usage prediction, heat loss estimation, and abnormality analysis based on the energy signature (ES) have been increasingly investigated in recent years, which have shown promising results11,12. However, these studies mainly used outdoor temperature as the main feature in order to discover the heat demand pattern. Other studies focused on peak usage forecasting with the ultimate objective of optimizing the energy usage and DH management13. These studies, which are similar to the ES, failed to consider the meteorological data or the end-user behaviors. Potential influencers of the heat demand patterns can be divided into three main factors, which include meteorology, behaviors, and time14. Some common meteorological data that potentially affects heat demand are humidity, solar irradiation, outdoor temperatures, and the wind flow speed15. Time factor involves all time-related parameters, which include hours, days, months, and years. The social behaviors of the end-users are also a crucial influencer of the heat load variation, which can be affected by both meteorological and time factors16. These three main factors significantly influence the heat demand patterns.
There has been considerable interest in the research area of heat load forecasting for DH, as indicated by numerous recent studies. Idowu et al.17 examined a range of supervised ML algorithms in order to perform heat load prediction up to 48 h in advance. The experimental results revealed that conventional ML algorithms, such as SVM and linear regression, achieved the lowest normalized root mean square error when compared to other algorithms. In another study, Boudreau et al. found that ensemble models provided significantly better prediction accuracy than base ML models when it came to predicting peak power demand and next-day building energy usage18.
Several studies have delved into specific aspects of DH systems. For example, Saloux et al. explored the application of ML algorithms for predicting the aggregated heating usage of a community. They concluded that the models' performance could be significantly enhanced by considering other crucial factors, such as time of day, systematic variables, and temperature19. López et al. focused on the impact of specific days, such as holidays or festive periods, on the load curve, and determined that such events could considerably affect the heat usage pattern20. Moreover, a case study of a large DH network over several heating seasons revealed that the primary force of heat demand were the various operation settings during daytime (night shutdown and night temperature setback) and the outdoor temperature21.
Despite the numerous issues addressed and methods discussed in existing literature on heat load prediction in DH networks, further research is needed to explore important external factors such as holiday and weather conditions, which could be utilized as input to improve the models' accuracy6. Additionally, while previous work has showed the high predictive performance of ML algorithms for heat demand, they have not provided a clear explanation of why the model achieved good performance, as well as which features are important and their correlation with the models10.
This research is proposed in order to improve the heat usage prediction via an in-depth analysis of the dataset to figure out the potential factors that impact the heat demand. The main contributions include (a) performing a data analysis prior to the training process to help thoroughly understand the dataset, (b) training and comparing different ML models in order to obtain the best hourly heat load prediction model, and (c) offering detailed explanations about what features were imperative to the model prediction, which were overlooked in the previous studies.
The remainder of the manuscript is outlined as follows. Section “Dataset description” gives a detailed description of the proposed heat demand dataset. After that, the Section “Methodology” outlines all processes involved in heat demand prediction. Several experiments are performed in Section “Experimental results” to comprehensively assess the proposed framework. Next, the Section “Discussion” discusses the findings and provides a detailed analysis of the study. Finally, we conclude the study and offer future work in the Section “Conclusion”.
Dataset description
The dataset that is described in this research was the hourly heat demand from an eco-friendly liquefied natural gas (LNG)-based cogeneration plant in the Cheongju region, Korea. The plant produces around 76.5 Gigacalories (Gcal) of local heating to the distribution grid. Gcal is a common heat load unit, which measures the heat energy in the heating plants. The LNG-powered plant is more efficient and environmentally friendly for the generation of thermal energy, which has been reported to produce over 70% less emission than coal or oil sources.
The dataset introduced in this study includes the hourly heat usage from January 2012 to December 2020 of the residents from a region, which spans eight heating seasons from November to April. The heat usage profile suggests the amount of heat that is transmitted from the plant to the consumers at a specific duration, which mainly involves space heating (SH) and domestic hot water (DHW). The corresponding hourly historical weather data was also collected as an additional feature in order to discover the potential connections with the heat load patterns in addition to the heat load data. A holiday feature that indicates whether the day under consideration is a holiday is also added in order to investigate the end-user behaviors. The three main features that belong to the weather data include wind flow speed, humidity, and outdoor temperature. The collected heat usage dataset is used to study the hourly heat load patterns and provides some explanations for the model's predictions. The minimum, maximum, mean and standard deviation for each variable are described in Table 1.
In summary, 8760 hourly heat load profiles and their corresponding historical temperature data are obtained yearly. Therefore, a total of 87,672 entries, which include date and time, holiday, wind flow speed, humidity, and temperature, are used as the input variables, and the heat load profiles are used as the target variables. The data entries from 2012 to 2020 were used as the training set, whereas the hourly heat usage of 2021 was applied in order to test the model’s performance.
Methodology
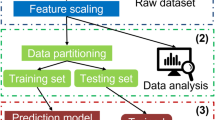
Figure 1 depicts the three components of the hourly heat usage prediction system, which are (a) data preprocessing, (b) pattern analysis and data partitioning, and (c) explainable heat load forecasting.
-
Data preprocessing: There is a high possibility that the structured data may contain some common issues with data preprocessing, such as duplicate data, missing data, and negative data due to human errors, which can affect the system's performance. As a result, it is a prerequisite before the data analysis and training processes to fix all errors and standardize the data.
-
Pattern analysis and data partitioning: Heat usage patterns play an important role in regards to enabling specialists to study consumer behavior. The distinctive patterns of the dataset are discovered in this section by using various data analysis approaches in order to thoroughly analyze the dataset before the training phase. The dataset is then divided into training and testing sets.
-
Explainable heat load prediction: Different ML algorithms were trained in order to forecast the hourly heat usage. Some explainable artificial intelligence (XAI) approaches are finally implemented in order to interpret the model’s predictions.

Description of the primary components of the heat usage patterns analysis framework.
Data preprocessing
Data cleaning
The structured data-related issues, such as missing and duplicated data are unavoidable during the data collection, and they can negatively affect the model's performance if not appropriately corrected. Data cleansing is therefore conducted in order to detect and fix error records in regards to the humidity, wind speed, outdoor temperature, and hourly heat usage data. There are various data cleaning processes, and the two main processes that were performed in this study include removing duplications and fixing the missing values. The dataset is loaded as a data frame using pandas, a famous data manipulation and analysis library. After that, data inconsistencies can be automatically detected using pandas-supported functions.
Standard techniques, such as moving average (MA) and imputation, are usually employed in order to correct the missing data. This study applied the exponential weighted moving average (EWMA) technique22, which is an extension of the MA algorithm. EWMA considers the recent data points to be significantly important with a higher weight, whereas the data points in the further past receive an exponentially lower weight. Moreover, the EWMA method can be effectively applied due to the nature of the dataset, and the differences between the two consecutive data points are considered minor. The EWMA can be described as follows.
where \({E}_{t}\) indicate the computed value at time t based on the EWMA technique. \({x}_{t}\) is the value of the series in the current period. \({E}_{t-1}\) is the EWMA at the previous time period. Finally, \(\alpha \) is the smoothing factor, which ranges between 0 and 1 and controls the influence of the current value \({x}_{t}\) on the \({E}_{t}\). A larger \(\alpha \) places more weight on recent observations and results in a more reactive EWMA, while a smaller \(\alpha \) results in a smoother EWMA.
Feature engineering
Feature engineering is the process of selecting, extracting, and transforming relevant features or variables from raw data to enhance the performance of ML algorithms. The goal of feature engineering is to provide ML algorithms with informative and discriminative features that can help them better understand the underlying patterns and relationships in the data. Two main processes in the feature engineering process are standardization and feature transformation.
The regression model fitting and learned function can be negatively affected by structured data, and it eventually creates a bias when numerical features with different scales are fed into the model23. The normalization/standardization techniques therefore need to be implemented in order to normalize the input features. Min–max normalization and standardization are two common feature scaling approaches24. The heat usage dataset that is applied to fit the model contains peak heat load on some specific periods, which are outliers, and it has an essential role during the training process. The min–max normalization likely lowers the impact of those outliners by transforming all features into a range between 0 and 1. The standardization therefore scales the features in order to have a zero mean, and a standard deviation of 1 is implemented in this study.
Feature transformation is necessary for structured data in order to convert categorical inputs into numerical inputs, because most ML models work with numerical data. The holiday variable is categorical, because it has two distinctive values, which represent whether a particular day is a regular day or a holiday. As a result, one-hot encoding, which creates a binary representation of the categorical feature, is applied in order to transform the holiday feature25. For instance, when a specific day is a holiday, the value for the holiday binary variable is set to 1, and the regular binary variable is 0.
Pattern analysis and data partitioning
Pattern analysis
Heat network during the summer season
The investigation of the heat network in the summer season, which spans from June to August, gives some exciting insights into the town's heat usage. Figure 2 illustrates the hourly heat demand distribution density for the summer months from 2012 to 2021. The average heat demand in the summer mainly involves the DHW consumption and the network heat losses. It can generally be seen that there was less heat demand in the distant past compared to the recent years. For instance, a roughly similar distribution can be observed for the following years, which include from 2012 to 2016, with the average heat demand being around 20 Gcal. However, the average heat demand increased to around 30 Gcal, which included the more recent years from 2019 to 2021, with some higher heat demands being related to particular heat usage patterns. Moreover, there has been a gradually increasing trend in the average heat usage of over 40 Gcal in recent years, and the year 2021 shows the highest density.

Distribution density plot of hourly heat demand during the summer season (Jun.–Aug.).
Heat network during the winter season
The chart in Fig. 3 illustrates the network's energy consumption on an hourly basis during the winter season spanning from November to March. The chart depicts three distinct patterns for three different time periods: daytime (06:00–18:00), nighttime (22:00–05:00), and peak hours (19:00–21:00). The scatter plot reveals that the consumers tend to use more heat during the peak time at the same temperature level compared to the nighttime and daytime. Moreover, the lower the outside temperature, the higher the heat load that is required.

Scatter plot of the outdoor temperature and the heat usage during the winter season (Nov.–Mar.).
Some heat load patterns for each season of the year
A typical hourly heat load pattern for each season can be observed in Fig. 4. The spring, fall, and winter seasons have similar variations in the hourly time scale, which is caused by the social behavior of the end-users. Reduced heat loads can be observed in the daytime, which is due to solar radiation that leads to higher daytime temperatures. The highest heat load during the daytime occurs around 8 am in order to prepare the space heating in offices and commercial buildings. The heat demand usually peaks between 19:00 and 21:00 because of the low temperature at night, which requires more heat for SH and DHW. DHW is a major part of the heat demand in the summer, when a tiny difference in the heat variation can be observed.

Average weekly heat load patterns during the four season periods.
Data partitioning
Data partitioning is a fundamental step required before training and evaluating the model. After preprocessing, the data is split into two sets: the training set and the testing set. The training set is utilized to train and optimize the model, while the testing set is typically employed to assess the algorithms' performance across various scenarios. This study used the heat usage profiles between 2012 and 2020 as the training set, whereas the heat load profiles from 2021 were used for the testing. Each training or testing sample consists of day, hour, outdoor temperature, humidity, windspeed, and holiday as the input variables, while the output is the hourly heat usage corresponding to that particular input.
Explainable heat load prediction
This section presents the main concepts behind boosting, support vector regression (SVR)26, and multilayer perceptron (MLP) algorithms27 that were implemented for the heat demand forecasting.
Boosting algorithms
Boosting algorithm belongs to the ensemble approach, which sequentially adds multiple weak learners. Each weak learner is added by using the learned information from its predecessor, and it tries to correct the errors that are predicted by them. A weak learner can be any learning algorithm that offers a slightly better performance than random guessing. Two standard boosting approaches are gradient boosting and adaptive boosting28.
-
Adaptive boosting: The adaptive boosting (AdaBoost) algorithm was proposed by sequentially adding weak learners, which involved using decision trees, and attempting in order to correct the wrongly predicted samples by applying a bigger weight to them during the training process of the latter weak learners. The AdaBoost model's final output is the weighted median.
-
Gradient boosting: AdaBoost assigns new instance weights whenever a new weak learner is added, but gradient boosting aims to fit the new predictor to the residual errors that are caused by the prior predictor with the primary objective of minimizing a loss function29. Some popular gradient boosting algorithms include LightGBM and XGBoost.
XGBoost leverages the feature distribution across all data points to narrow down the search space of potential feature splits. The objective of the XGBoost algorithm can be expressed as:
where the predictive ability of XGBoost is determined by the loss function \(L\), while the regularization term \(\mu \) is used to manage overfitting. \(\mu \) is determined by the number of observers and their prediction threshold in the ensemble model. Since the problem in question belongs to regression analysis, the root mean squared error (RMSE) is used as the loss function \(L\).
Support vector regression (SVR)
Unlike typical regression algorithms that seek to minimize the sum of squared errors between actual and predicted values, SVR attempts to identify the optimal hyperplane within a user-defined threshold value. The threshold value is the distance between the boundary line and the hyperplane. Heat demand prediction is a complex non-linear topic, because it has multiple input variables. To address non-linearity in the initial feature space and treat it as a linear problem in the high-dimensional feature space, SVR requires the use of a non-linear kernel. The Gaussian Radial Basis kernel (RBF) was used in this study as the default kernel for SVR.
Multilayer perceptron (MLP)
Multilayer perceptron (MLP) belongs to the feedforward artificial neural networks (ANN) category. MLP's fundamental structure consists of an input layer, one or more hidden layers with neurons, and an output layer that are stacked in sequence. The neuron is the primary computing component of MLP, and neurons from the current layers fully connect to neurons from the next layer. The inputs are added to the initial weights, fed into an activation function, and propagated to the next layer.
Experimental results
This section shows all experiments that were conducted to determine the most suitable algorithm for predicting heat usage. In addition, various XAI techniques were also conducted in order to provide an in-depth analysis of the trained models.
The heat load prediction models were constructed and trained on scikit-learn30, a Python-based open-source ML library. Three main explainable AI libraries for analyzing the data include partial dependence plot31 (PDP), which is a global and model-agnostic XAI algorithm, local interpretable model-agnostic explanations32 (LIME), which create a local model approximation of the model around the prediction of interest, and shapley additive explanations33 (SHAP), which employ a game-theoretic approach.
Evaluation metrics
Three standard evaluation metrics were computed, which included the coefficient of determination (\({R}^{2}\)), mean squared error (MSE), and mean absolute error (MAE) in order to evaluate the heat demand forecasting. MSE is computed by averaging the squared difference between the predicted values and actual values for all the training samples34. On the other hand, MAE is the average of the absolute differences between the predicted values and true values. While MSE measures the standard deviation of residuals, MAE calculates the average of the residuals in the dataset. \({R}^{2}\) is computed by determining the proportion of the dependent variable's variance predicted by the algorithm. The lower the MSE and MAE scores, the better the model’s performance. However, a higher value of \({R}^{2}\) is considered better. The three metrics can be formulated as follows.
where \(N\) is the total number of training samples. \({y}_{i}\) indicates the actual value, \({\widehat{y}}_{i}\) means the predicted value of the \(i\) th profile, and \(\overline{y }\) is the mean value of \(y\).
Hyperparameter fine-tuning
Five regression models were implemented in this study in order to perform the heat demand forecasting, which included SVR, AdaBoost, XGBoost, LightGBM, and MLP. Each model has its crucial hyperparameters that must be determined before the training. The hyperparameters control the training behavior of the learning algorithms, and they considerably influence the model's performance.
Table 2 shows the hyperparameters and the value range for each hyperparameter that is required by the five models. A grid search method was conducted next on the different combinations of the hyperparameters of each algorithm in order to explore the most suitable hyperparameter combination that helps the algorithm obtain the best performance.
Heat usage prediction analysis
Figure 5 depicts the performance and scalability comparison of five different learning algorithms using the learning curves in order to show the effect of adding more samples during the training process. The experiment involved randomly selecting samples from the training dataset. A training sample include date, outdoor temperature, windspeed, humidity, holiday, and hourly heat demand as the features.

Heat demand forecasting performance using five different algorithms.
It can generally be concluded that SVR and MLP were highly sensitive to the dataset size, because they widely fluctuated as more training samples were added. On the other hand, the boosting algorithms, which included AdaBoost, LightGBM, and XGBoost, showed their advantages and effectiveness with a bigger dataset. The three ensemble algorithms exhibited similar trends in variation; the error gradually decreased and eventually stabilized. Low MSE scores of less than 0.02 were obtained for the three boosting algorithms when the training dataset size was over 2000 samples. XGBoost achieved the lowest mean squared error of less than 0.01 among the three algorithms, and it showed its robustness when the number of training samples reached 7000. As a result, XGBoost was utilized as the primary model for the following experiments.
Table 3 shows the heat demand forecasting performance using five ML algorithms on the test dataset. All the models generally obtained good performances on the dataset. The boosting algorithms performed better than SVR and MLP. The XGBoost algorithm achieved the highest \({\mathrm{R}}^{2}\), MSE, and MAE at 0.95, 0.12, and 0.15, respectively. On the other hand, MLP showed the lowest heat usage prediction performance with an MSE value of 0.25 and R2 at 0.89.
Figure 6 compares the actual and the predicted heat demand for 2021 using the XGBoost model. The heat usage values predicted by the model, which are illustrated by the red line, are roughly similar to the actual heat usage values, which are illustrated by the blue line. Moreover, each month's peak and bottom heat usage were accurately predicted. However, the model performance was significantly affected, which is due to some uncommon end-user's heat usage behaviors.

Daily heat load prediction results on the testing dataset.
Explainable heat usage prediction
The previous section discussed what model achieved the highest heat usage forecasting performance. However, it is challenging to reveal what features are influential and how they affect the model predictions. As a result, some interesting XAI approaches are implemented in this section in order to attempt to explain how ML models predict the outcomes.
Firstly, three different feature ranking techniques were implemented in order to evaluate each feature's importance in regards to predicting the output heat usage by the model, as displayed in Fig. 7. Figure 7a calculates a feature's relative importance by examining the mean and standard deviation of impurity reduction across each tree. Figure 7b ranks the feature importance by computing the game's theoretically optimal shapley values33. The resulting shapley values provide a measure of the relative importance of each feature in the model prediction for a particular data point. It requires examining every possible feature combination and assessing the marginal impact of each feature on the prediction. Features with higher Shapley values are regarded as more significant. Ranking both approaches reveal that the temperature and month features are crucial, which is valid due to the end-users heat demand pattern being significantly affected by these two features.

Feature importance analysis for the heat usage prediction model.
Finally, Fig. 7c visualizes the feature importance assessed by LIME. Positive weights indicate that a feature promotes a positive prediction, while negative weights indicate the opposite. The magnitude of the weight represents the importance of the feature. It is noticeable that a temperature of 4 °C or lower (cold season) presses the model to output a higher heat usage.
The previous experiment indicated that the temperature and month features greatly impacted the model's predictions, but it did not explain exactly how the model was affected. As a result, PDP, was implemented in order to demonstrate a feature's marginal effect on the models' prediction.
Figure 8 shows how temperature and month together impact heat usage in the form of contour lines. Contour was proved to work best for analyzing the impact of continuous features in the PDP interaction plot35.

PDP interaction plot for the temperature and month features.
The contour lines, ranging from 0.000 to 150.000, indicate how specific ranges of the two features affect heat usage. A higher value of the contour line implies a greater impact of the two features on heat usage. For example, during the summer season when the average temperature is above 22 °C, the features have a negative influence on the model prediction, resulting in an average heat demand of less than 50 Gcal and a contour line value of under 25.000. On the other hand, contour line values greater than 125.000, corresponding to the winter season with an average temperature of fewer than 2 °C, positively impact the model prediction leading to the average heat usage of over 120 Gcal.
Figure 9 illustrates how the temperature feature affected the heat demand through the distribution of the actual heat demand via fixed values of the temperature variable. It was observable that the hourly heat load achieved the biggest average value, which was approximately 150 Gcal, occurred when the temperature feature was between -16.5 °C to -0.6 °C, indicating the winter season. Moreover, the hourly heat demand gradually dropped when the temperature rose. The lowest hourly heat demand, around 21 Gcal, was recorded when the temperature ranged from 26.9 to 38.1 °C , which corresponds to the summer season.

Actual predictions plot for the temperature variable. Distribution of the actual prediction via different variable values.
Based on the data, we can conclude that the hourly heat demand is directly proportional to the temperature. In the summer, DHW accounts for the majority of the heat demand. In contrast, both DHW and SH contribute to the heat demand during the winter. Additionally, the hourly heat demand is higher during the winter, with temperatures below 10 °C, and lower during the summer, with temperatures above 26 °C.
Comparison with similar studies
Numerous studies have been conducted in the past to predict and analyze DH head demand. However, direct comparisons with these studies are difficult due to differences in DH network designs, input data, and architecture implementations or experimental setups. We use operational data from DHS to predict heat usage patterns and compare our results using the XGBoost model, which exhibits the best prediction performance. The recorded MAE value from this study was 15%, which is smaller than the reported MAE of 18.07% by Huang et al36. In addition, the computed evaluation metrics are also superior to the following reseach37,38. Specifically, the proposed XGBoost model outperforms the study suggested by Ivanko et al38 in terms of MSE and correlation coefficient, achieving 12% and 0.95 on the testing set, respectively, compared to MSE of 45.04% and a coefficient of determination of 0.81. In terms of the correlation coefficient, the XGBoost method also shows better hourly prediction performance than the ANN model proposed by Bünning et al37, with a correlation coefficient of 0.95 for one hour compared to 0.88.
Discussion
This section provides a discussion based on our approach and the obtained results. Furthermore, a discussion about the interpretability of the study is also presented.
Model performance
To establish the best heat demand prediction model, five different models were evaluated with varying sizes of training datasets. Then, three evaluation metrics (MSE, MAE, and \({\mathrm{R}}^{2}\)) were calculated. Figure 5 demonstrates the learning trend of these models as the number of training samples increases. When the training dataset size is less than 2000, MLP and SVR exhibit the highest accuracy. However, these models have drawbacks such as the need for sequential data and extended training times, making them more suitable for applications that can handle longer training periods. On the other hand, for larger training datasets (over 2000 samples), the accuracy of the three boosting algorithms is higher. Boosting algorithms, such as AdaBoost and XGBoost, are more appropriate for granular control and frequent updating due to their short training time, stability, and forecasting accuracy. Nonetheless, all models can generate predictions swiftly (within a second) after being trained. Hence, the time required for training and retraining the models is the primary constraint for their overall implementation.
Collinearity, which refers to the correlation between predictor variables, always exists in real-world data29. However, the impact of collinearity on prediction models varies due to differences in principles. Previously, several approaches have been introduced to address collinearity problems, such as pre-selection based on thresholds, clustering predictors, and regularization techniques. Regularization is a method used to reduce the complexity of the SVM model and prevent overfitting14. Similarly, boosting-based models like AdaBoost, XGBoost, and LightGBM can effectively handle multicollinearity problems by adjusting the number of variables sampled at each split28, which acts as a regularization parameter. In contrast, MLP's ability to withstand collinearity is relatively weak, which may explain its relatively low accuracy.
The way in which heat is distributed varies greatly depending on the size of the DH network, and the proposed framework is appropriate for smaller networks where the behavior of customers has an impact on the load pattern. It is possible to apply the framework to other small-scale DH networks, in order to anticipate the hourly heat demand, as long as records of the hourly heat demand and environmental factors such as wind speed, humidity and temperature are available.
Interpretability
Model interpretability for AI models refers to the ability to transform the training and testing processes into logical rules. The model's ability to display the significance and ranking of input variables39 allows it to exhibit interpretability. The interpretability of a predictive model is crucial in evaluating the rationality of heat demands in a DH network. A lack of conformity to accepted principles in variable importance can indicate model instability or system malfunction4. Boosting-based methods are highly interpretable as they do not require the interpretation of tree structures by ML professionals, and each decision corresponds to a logical rule14. These models can output visual results of variable importance, with the weight and rank of variables differing depending on the model's inherent principles, as displayed in Fig. 7. However, temperature and month were consistently the most influential variables, with humidity and holiday having a negligible impact, indicating the limited influence of these variables on heat usage.
On the other hand, SVR and MLP were less interpretable, with MLP being considered a black box method due to its difficulty in identifying the features extracted from each layer of the network. The use of a linear kernel function in SVR leads to a more interpretable model, but models with other kernels can be challenging to interpret39.
Conclusion
Hourly heat demand forecasting is essential for heating providers to optimize heat production and heat supply operations. This research presents an hourly heat usage prediction system that is based on standard regression algorithms, and it systematically investigates the input features' influence on the models' outcomes.
First, additional weather information, which includes the outdoor temperature, wind flow speed, and humidity of the corresponding hourly historical heat demand, were extracted during the data collection process, and they were used as the input features. After that, various data preprocessing procedures were implemented in order to clean the dataset. The preprocessed dataset was utilized in order to thoroughly analyze the common heat demand patterns. Finally, the dataset was inputted into five well-known regression algorithms, namely SVR, MLP, XGBoost, AdaBoost, and LightGBM, in order to determine what model is the most suitable for the heat usage prediction task based on standard evaluation metrics.
The XGBoost model achieved the lowest MSE via various experiments, which was less than 0.01, and it was robust when the number of samples in the training dataset increased. Finally, various XAI methods, such as SHAP and PDP were applied in order to thoroughly analyze how the model gave a particular prediction. The results showed that temperature and time-related variables are the most critical features that contribute to the model's predictions.
More attention will be directed in the future toward novel heat load prediction techniques, such as multi-step ahead prediction. In addition, collecting a larger dataset with additional variables can improve the performance and efficiency of the model.
Data availability
The datasets used and/or analysed during the current study available from the corresponding author on reasonable request.
Code availability
The source code for all the analyses presented in this study can be found on these GitHub repositories: https://github.com/minhdl93/HeatLoadAnalysis.
References
Lund, H. et al. The status of 4th generation district heating: Research and results. Energy 164, 147–159 (2018).
Barone, G., Buonomano, A., Forzano, C. & Palombo, A. A novel dynamic simulation model for the thermo-economic analysis and optimisation of district heating systems. Energy Convers. Manage. 220, 113052 (2020).
Dorotić, H., Pukšec, T. & Duić, N. Multi-objective optimization of district heating and cooling systems for a one-year time horizon. Energy 169, 319–328 (2019).
Guelpa, E. & Verda, V. Thermal energy storage in district heating and cooling systems: A review. Appl. Energy 252, 113474 (2019).
Buffa, S., Cozzini, M., D’antoni, M., Baratieri, M. & Fedrizzi, R. 5th generation district heating and cooling systems: A review of existing cases in Europe. Renew. Sustain. Energy Rev. 104, 504–522 (2019).
Dang, L. M. et al. Daily and seasonal heat usage patterns analysis in heat networks. Sci. Rep. 12, 1–12 (2022).
Xue, P. et al. Multi-step ahead forecasting of heat load in district heating systems using machine learning algorithms. Energy 188, 116085 (2019).
Zhao, Y., Zhang, C., Zhang, Y., Wang, Z. & Li, J. A review of data mining technologies in building energy systems: Load prediction, pattern identification, fault detection and diagnosis. Energy Built Environ. 1, 149–164 (2020).
Guo, Y. et al. Machine learning-based thermal response time ahead energy demand prediction for building heating systems. Appl. Energy 221, 16–27 (2018).
Wang, Z., Hong, T. & Piette, M. A. Building thermal load prediction through shallow machine learning and deep learning. Appl. Energy 263, 114683 (2020).
Nageler, P. et al. Comparison of dynamic urban building energy models (UBEM): Sigmoid energy signature and physical modelling approach. Energy Build. 179, 333–343 (2018).
Westermann, P., Deb, C., Schlueter, A. & Evins, R. Unsupervised learning of energy signatures to identify the heating system and building type using smart meter data. Appl. Energy 264, 114715 (2020).
Luo, X. et al. Feature extraction and genetic algorithm enhanced adaptive deep neural network for energy consumption prediction in buildings. Renew. Sustain. Energy Rev. 131, 109980 (2020).
Ntakolia, C., Anagnostis, A., Moustakidis, S. & Karcanias, N. Machine learning applied on the district heating and cooling sector: A review. Energy Syst. 13, 1–30 (2022).
Guelpa, E., Marincioni, L., Capone, M., Deputato, S. & Verda, V. Thermal load prediction in district heating systems. Energy 176, 693–703 (2019).
Rouleau, J. & Gosselin, L. Impacts of the COVID-19 lockdown on energy consumption in a Canadian social housing building. Appl. Energy 287, 116565 (2021).
Idowu, S., Saguna, S., Åhlund, C. & Schelén, O. Applied machine learning: Forecasting heat load in district heating system. Energy Build. 133, 478–488 (2016).
Bourdeau, M., Qiang Zhai, X., Nefzaoui, E., Guo, X. & Chatellier, P. Modeling and forecasting building energy consumption: A review of data-driven techniques. Sustain. Cities Soc. 48, 101533 (2019).
Saloux, E. & Candanedo, J. A. Forecasting district heating demand using machine learning algorithms. Energy Procedia 149, 59–68 (2018).
López, M., Sans, C., Valero, S. & Senabre, C. Classification of special days in short-term load forecasting: The Spanish case study. Energies 12(7), 1253 (2019).
Noussan, M., Jarre, M. & Poggio, A. Real operation data analysis on district heating load patterns. Energy 129, 70–78 (2017).
Sukparungsee, S., Areepong, Y. & Taboran, R. Exponentially weighted moving average—Moving average charts for monitoring the process mean. PLoS ONE 15, e0228208 (2020).
Harrell, F. E. General Aspects of Fitting Regression Models 13–44 (Springer, 2015).
Munkhdalai, L. et al. Mixture of activation functions with extended min-max normalization for forex market prediction. IEEE Access 7, 183680–183691 (2019).
Okada, S., Ohzeki, M. & Taguchi, S. Efficient partition of integer optimization problems with one-hot encoding. Sci. Rep. 9, 1–12 (2019).
Zhang, F. & O’Donnell, L. J. Support Vector Regression 123–140 (Elsevier, 2020).
Liu, Y., Liu, S., Wang, Y., Lombardi, F. & Han, J. A stochastic computational multi-layer perceptron with backward propagation. IEEE Trans. Comput. 67, 1273–1286 (2018).
Azmi, S.S., Baliga, S. An Overview of Boosting Decision Tree Algorithms utilizing AdaBoost and XGBoost Boosting strategies. Int. Res. J. Eng. Technol. 2020, 7.
Bentéjac, C., Csörgő, A. & Martínez-Muñoz, G. A comparative analysis of gradient boosting algorithms. Artif. Intell. Rev. 54, 1937–1967 (2021).
Pedregosa, F. et al. Scikit-learn: Machine learning in Python. J. Mach. Learn. Res. 12, 2825–2830 (2011).
Moosbauer, J., Herbinger, J., Casalicchio, G., Lindauer, M. & Bischl, B. Explaining hyperparameter optimization via partial dependence plots. Adv. Neural. Inf. Process. Syst. 34, 2280–2291 (2021).
Visani, G., Bagli, E., Chesani, F., Poluzzi, A. & Capuzzo, D. Statistical stability indices for LIME: Obtaining reliable explanations for machine learning models. J. Oper. Res. Soc. 73(1), 91–101 (2022).
Sundararajan, M., Najmi, A. The many Shapley values for model explanation. In Proceedings of the International conference on machine learning, 2020, 9269–9278.
Chicco, D., Warrens, M. J. & Jurman, G. The coefficient of determination R-squared is more informative than SMAPE, MAE, MAPE, MSE and RMSE in regression analysis evaluation. PEERJ. Comput. Sci. 7, e623 (2021).
Greenwell, B. M. pdp: an R Package for constructing partial dependence plots. R J. 9(1), 421 (2017).
Huang, Y. et al. A novel energy demand prediction strategy for residential buildings based on ensemble learning. Energy Procedia 158, 3411–3416 (2019).
Bünning, F., Heer, P., Smith, R. S. & Lygeros, J. Improved day ahead heating demand forecasting by online correction methods. Energy Build. 211, 109821 (2020).
Ivanko, D., Sørensen, Å. L. & Nord, N. Selecting the model and influencing variables for DHW heat use prediction in hotels in Norway. Energy Build. 228, 110441 (2020).
Minh, D., Wang, H.X., Li, Y.F. and Nguyen, T.N. Explainable artificial intelligence: A comprehensive review. Artif. Intell. Rev. 2022, 1–66.
Acknowledgements
This work was supported by the Basic Science Research Program via the National Research Foundation of Korea (NRF) funded by the Ministry of Education (2020R1A6A1A03038540) and by a grant (20212020900150) from "Development and Demonstration of Technology for Customers Bigdata-based Energy Management in the Field of Heat Supply Chain" funded by Ministry of Trade, Industry and Energy of Korean government and by the Institute of Information and Communications Technology Planning and Evaluation (IITP) grant funded by the Korea government (MSIT) (No.2022-0-00106, Development of explainable AI-based diagnosis and analysis frame work using energy demand big data in multiple domains).
Author information
Authors and Affiliations
Contributions
H.M. and H.S. acquired the funding and supervised the study. Y.L., L.T., and T.N. performed the data collection, preprocessing, and experimental validation. L.D. wrote the original draft. J.S. revised the manuscript. All authors have read and agreed to publish the version of the manuscript.
Corresponding author
Ethics declarations
Competing interests
The authors declare no competing interests.
Additional information
Publisher's note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Dang, L.M., Shin, J., Li, Y. et al. Toward explainable heat load patterns prediction for district heating. Sci Rep 13, 7434 (2023). https://doi.org/10.1038/s41598-023-34146-3
Received:
Accepted:
Published:
DOI: https://doi.org/10.1038/s41598-023-34146-3
Comments
By submitting a comment you agree to abide by our Terms and Community Guidelines. If you find something abusive or that does not comply with our terms or guidelines please flag it as inappropriate.
