
Abstract
To determine the path of disease in different types of networks, a new method based on compressive sensing is proposed for identifying the disease propagation paths in two-layer networks. If a limited amount of data from network nodes is collected, according to the principle of compressive sensing, it is feasible to accurately identify the path of disease propagation in a multilayer network. Experimental results show that the method can be applied to various networks, such as scale-free networks, small-world networks, and random networks. The impact of network density on identification accuracy is explored. The method could be used to aid in the prevention of disease spread.
Similar content being viewed by others


Introduction
Complex network research has been a trendy area and is on the rise. The area of research is expanding, from protein interaction networks to biological networks, from scientific research networks to social networks, from information transmission networks to disease propagation networks, and from transportation networks to logistical networks. Complex network research topics include synchronization1,2, robustness3, node importance4, structure identification, and stability5, among others6,7,8,9. The simulation of disease models is one of them, and it is an important component of complex network research10,11,12.
Disease propagation and propagation path identification are two aspects of research on the disease model of a complex network. The single-layer network model of disease was first investigated in disease models13. The models involved include SIS (susceptible-infected-susceptible)10,11,12,13, SIR (susceptible-infected-removed)12,14, SIRS (susceptible-infected- removed- susceptible)15, SEIR (susceptible-exposed-infected-recovered)16, SEIRS (susceptible-exposed-infected-recovered-susceptible)17, SIQRS (susceptible-infected-quarantined-recovered-susceptible)18, SIVRS (susceptible-infected-variant-recovered-susceptible)19,20, etc. The propagation characteristics of the SIS model under the condition of infected individual mobility10, the nonlinear infectivity and adaptive weighted SIS model13, the network-based SIS epidemic model with global behavior notes21, the SIS epidemic model with infectious latency22, the epidemic situation of nodes with a square lattice13, and so on are among the most studied models. Path identification in the SIS model of a single-layer disease propagation network was also investigated by Zhesi Shen et al.23. Dongmei Fan et al. investigated the influence of geometric correlation on epidemic propagation with multilayer disease models24. Paulo Cesar Ventura da Silva et al. investigated epidemic propagation with consciousness and varied time scales in multilayer networks25, and Fuzhong Nian et al. simulated the MR-SIS propagation process in multirelational networks26. There is more research on the model of disease propagation in the above research than there is on identifying the propagation path. There is currently just a small amount of literature on disease path identification, and it is focused on single-layer disease networks. In multilayer networks, there is a lack of literature on path identification. This may be because path identification in multilayer disease networks is difficult. Furthermore, identifying the disease propagation path in multilayer networks is critical for disease prevention and control27. We will investigate the identification of propagation paths in a multilayer disease network in this paper.
The Granger causality test28, synchronization-based29, and compressive sensing-based topology identification30,31 are all common methods. The Granger method of topology identification necessitates stochastic network node perturbations, which is not realistic in disease propagation networks. The synchronization-based method requires constructing an auxiliary network with a very general form and designing some adaptive controllers. However, the compressive sensing-based method in this paper does not need these additional conditions. To identify the topology of a disease propagation network, only a small amount of measurement data is needed. Compressed sensing is a new sampling theory that can obtain discrete samples of a signal when the sampling rate is substantially lower than Nyquist, allowing for distortion-free signal reconstruction.The compressive sensing-based method has the advantages of requiring less data to be measured and having a high identification accuracy32,33. The basic concept of compressive sensing is \(Y=AX\), where \(Y\in R^m\), A is a \(m\times n\) dimensional matrix, \(X\in R^n\), and \(m\ll n\). Only a few values of Y and A need to be measured to reliably identify X when there are enough zero elements in it. The aim of this paper is to use compressive sensing to identify the topology of disease spread in multilayer networks.

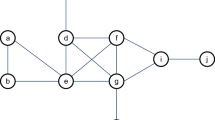
Sketch of a two-layer epidemic network used in this work. The upper layer (virtual contact) represents the spreading of awareness, where nodes have two possible states: unaware (U) or aware (A). The lower layer (physical contact) corresponds to the network where the epidemic spreading takes place. The nodes are the same actors as that in the upper layer, and their states can be: susceptible (S) or infected (I).
Method
Figure 1 depicts a typical two-layer disease model. The crowd’s spread of consciousness is shown in the upper layer34, where nodes represent the individuals and edges between nodes indicate information propagation paths. Contacts via Facebook, WeChat, and other social media platforms can be used to spread information. The model used in the upper layer is UAU, where U represents the individual who is unaware of the disease and A represents the one who is aware. After acquiring information from those who are aware, those who are unaware can be changed into aware, with a probability of \(\lambda\). The state of the node is A (aware) if the node is aware of disease; otherwise, the status is U (unaware). The lower layer depicts the spread of disease among humans, with nodes representing people and edges between nodes representing disease propagation paths. We use the conventional SIS model in the lower layer, where S represents the susceptible population and I represents the infected population. In the lower layer, we use S(i) to denote the status of infected and susceptible nodes as follows:
and the state of an arbitrary node i is denoted as M(i) in the upper layer, where
We use \(a_{ij}\) and \(b_{ij}\) in the networks to denote the edges between nodes in the upper and lower networks, respectively (especially if there is an edge between node i and node j, then \(a_{ij} = 1\) or \(b_{ij} = 1\); otherwise, \(a_{ij} = 0\) or \(b_{ij} = 0\)). If node i is unaware of the disease during disease propagation, node i may be converted to aware after being notified by surrounding nodes. The probability is denoted by \(r_i(t)\). The probability that node i will be infected by surrounding nodes at time t is \(q_i^{A01}(t)\) if it is susceptible and aware. The probability is \(q_i^{U01}(t)\) if node i is unaware. The following are the changes in \(r_i(t)\), \(q_i^{A01}(t)\), and \(q_i^{U01}(t)\) over time:
where \(p_i^A\) is the infection probability of node i in the susceptible population if node i is aware, \(p_i^U\) is the infection probability of node i if node i is unaware, and \(\lambda\) is the probability of node i transitioning from unaware to aware when getting a notification. Meanwhile, node i recovers at a probability of \(\sigma\) after infection.
Taking the logarithm of both sides of Eq. (3), we can obtain
When one measures at different time points and obtains the state of multiple copies, then Eq. (4) can be written as a matrix:
where \(\Phi _{m\times (N-1)}\) is defined as the state of other nodes except node i.
at different time t, one obtains the following equation:
We just need to solve vector X in Eq.(5) to find the propagation paths between node i and other nodes in the disease model. Letting \(i= 1, 2,\cdots , N\), we can identify the paths among all nodes. The problem is then transformed into solving the equation \(\Phi X=Y\), where \(\Phi\) is a \(m\times (N-1)\) matrix, Y is a known vector, and the X vector is to be determined. According to the literature23, \(q_i^{A01}(t)\) and \(q_i^{U01}(t)\) can be obtained based on big data. For a specific disease, \(p_i^A\) and \(p_i^U\) are known23, and only the status of each node needs to be measured. When there are few nonzero elements in X, we only need a minimal number of measurements to accurately solve X, according to compressive sensing theory35,36. Minimizing the number of nonzero components in X produces the sparsest solution to \(\Phi X=Y\) with respect to X, i.e.,
Classical Tikhonov regularization is used to solve \(\Phi X=Y\) to obtain accurate reconstruction and increase numerical stability. Then, this problem can be approximated by
The regularization value \(\alpha\) is used to avoid large deviations from the optimal solution. To solve the convex optimization problem, we usually use alternating direction method of multipliers (ADMM) algorithms37.
Numerical simulation
We use different network structures for simulation to verify the universality of our method of identifying propagation paths. It is assumed that a specific disease has spread throughout a community. The notations \(p_i^A\) and \(p_i^U\) denote the infection probability of a node in the aware and unaware states, respectively. In practice, \(p_i^A<p_i^U\). \(\lambda\) represents the probability that a node will become aware of the disease after being notified by any of its neighbours, and \(\sigma\) represents the recovery probability. We set the path value to 1 if there is a disease propagation path between two nodes in the community, which corresponds to \(b_{ij}=1\). We state in the identification procedure that the path is regarded to exist if the identification value is \(b_{ij}\in [1-\varepsilon , 1+\varepsilon ]\) and nonexistent if the value is \(b_{ij}\in [-\varepsilon , \varepsilon ]\). The value of \(\varepsilon\) in this paper is 0.01.
TPR (true positive rate) and TNR (true negative rate) are indicators of identification accuracy, with the TPR being the ratio of all correctly identified paths out of all existing paths and the TNR representing the percentage of all correctly identified nonexistent paths out of all nonexistent paths.
The identification error for nonzero (existing) and zero (nonexistent) edges is represented by \(E_{nz}\) and \(E_{z}\), respectively.
where \(b_{ij}^{'}\) indicates the identification value of the existing edge and \(b_{ij}\) indicates the true value. The true value of \(b_{ij}\) for the existing edge between nodes i and j is 1.
where \(b_{ij}^{'}\) indicates the identification value of nonexistent edges.
Identification paths of disease propagation in ER, WS, and BA networks
We initially discover disease propagation paths in various types of networks using numerical simulation. Random networks (ER), small-world networks (WS), and scale-free networks (BA) are the networks we chose. The three networks are mostly used to mimic real population relationships in disease propagation models6,27,34. The following are the practical implications: Everyone can be considered a node, and there are a great number of paths linking them in a WS network. People who know each other are represented by the connected nodes. A few nodes in BA networks have a great number of connections, while the majority of nodes have minimal connections.Given a specific number of nodes, there is the same probability of a path existing between each pair of nodes in an ER network, u and v. The data ratio in the simulation refers to the proportion of actual observed data to the data necessary for a typical solution. The typical solution takes \(N-1\) measurements to solve the solution vector \((b_{i1}, b_{i2}, \cdots , b_{i-1}, b_{i+1}, \cdots , b_{N})^T\), as given in Eq. 6. However, compressive sensing assumes that only k times (\(k<N-1\)) of data measurement are necessary to solve the vector, and the data ratio is defined as the ratio of k to \(N-1\). The parameters are as follows: all networks’ edge connection probability is \(10\%\), and the total number of nodes in all three networks is 500. The infection probability is \(20\%\), \(p_i^A=0.4, p_i^U=0.7\), and \(\sigma\)=0.2. The identification of paths connecting all nodes is repeated separately 30 times in the simulation, and the average value is taken. The result of the identification is presented in Fig. 2, with the top and lower boundaries of each data point label representing the result’s standard deviations.

Identification results of disease propagation paths in three different networks: ER, WS, and BA. (a) True positive rate (b) True negative rate. (c) Average relative error (d) Average absolute error.
The disease propagation paths for the three networks can be accurately determined, as shown in Fig. 2. The WS network outperforms the others in terms of identification, while the ER network comes in second. This could be because the nodes in the WS network are more uniformly connected than those in other networks. When the data ratio is \(40\%\), the propagation paths of the WS and ER networks may be reliably identified in Panels (a) and (b) of Fig. 2. The paths of the BA network are also accurately identified when the data ratio is \(50\%\). The errors of identification vary with the data ratio, as seen in Panels (c) and (d) of Fig. 2. The relative error of the real existing path is shown in Panel (c) of Fig. 2, whereas the average absolute error of the nonexistent path is shown in Panel (d). When the data ratio is \(40\%\), the average relative error and absolute error of the WS and ER networks in identification are already very small, as shown in Panels (c) and (d) of Fig. 2. The ER network is zero and 0.009, and the WS network is all zero. The BA network is the worst. When the data ratio is \(50\%\), each of the three networks has a zero error.
Impact of network density on identification
To investigate the impact of network density on identification, we simulate networks of the same kind but with varied densities. In this case, we use the BA scale-free model. The network’s density parameters are \(m = 2\), \(m = 4\), and \(m = 8\). When generating the network, m represents the number of connection edges of the new node. The network density is \(3.92\%\), \(7.68\%\) and \(14.72\%\), respectively. The number of network nodes is set to 100, and the rest of the settings are the same as in “Conclusion” Section Fig. 3 depicts the identification result.

Identification performance with varying data ratio \(R_m\) in three 100-node BA networks, where \(\varepsilon =0.01\), and the density parameter is given as \(m=2\), 4, and 8 separately.
As shown in Fig. 3, propagation paths may be accurately identified at three different path densities while maintaining the same data ratio. However, as the path density of the network increases, the accuracy of the identification decreases. The identification accuracy of the TPR in three different path densities is \(90\%\), \(60\%\), and \(7\%\) when the data ratio is \(20\%\), as shown in Panel (a) of Fig. 3. The identification accuracy of the TNR is better than that of the TPR, as shown in Panel (b) of Fig. 3; however, the identification accuracy diminishes as path density increases. The identification accuracy is \(98\%\), \(94\%\), and \(86\%\) when the data ratio is \(20\%\). The relative and absolute errors of identification rapidly decrease as the data ratio increases, as seen in Panels (c) and (d) of Fig. 3. The absolute error is decreased to zero when the data ratio is \(60\%\), and the relative error is reduced to zero when the data ratio is \(70\%\).
The compressive sensing method has the advantage of identifying the unknown path with less data. Only a few monitoring data are required to determine the disease’s propagation path. Even with a poor data ratio, we can still roughly identify the path that the disease takes to propagate. Fig. 3 illustrates this. We only need \(20\%\) of the data in the BA network with \(3.92\%\) density, and the recognition accuracy can reach \(90\%\). When the network density is \(14.72\%\), the required monitoring data are approximately \(40\%\), and the identification accuracy is approximately \(80\%\).
Conclusion
To accurately identify disease propagation paths in multilayer networks, this paper uses compressive sensing to identify disease propagation paths using only a few measurement data. The method can accurately identify the path in many types of networks, including ER, WS, and BA, according to experimental data. It has the best identifying performance among them in the WS network. The identification performance of BA networks with various densities has been examined and assessed. The results reveal that as network density increases, the accuracy of identification decreases and the error increases. The path of disease propagation can still be accurately identified assuming appropriate measurement data are added. This method could help in the prevention of disease epidemics in the general population.
Data availability
The datasets used and analysed during the current study available from the corresponding author on reasonable request.
References
Su, H., Han, W. & James, L. Positive edge-consensus for nodal networks via output feedback. IEEE T Automat. Contr. 64, 1244–1249 (2018).
Sun, W. et al. Synchroni, zation of the networked system with continuous and impulsive hybrid communications. IEEE T Neural Networ. 99, 1–12 (2019).
Chen, Z., Wu, J., Xia, Y. & Zhang, X. Robustness of interdependent power grids and communication networks: A complex network perspective. IEEE T Circuits-II 65, 115–119 (2018).
Wu, X., Wei, W., Tang, L., Lu, J. & Lu, J. Coreness and h-index for weighted networks. IEEE T Circuits-I 99, 1–10 (2019).
Mei, G., Wu, X., Ning, D. & Lu, J. Finite-time stabilization of complex dynamical networks via optimal control. Complexity 21, 417–425 (2016).
Wei, X., Wu, X., Chen, S., Lu, J. & Chen, G. Cooperative epidemic spreading on a two-layered interconnected network. Siam. J. Aaal. Dyn. Syst. 17, 1503–1520 (2018).
Mei, G. F. et al. Compressive-sensing-based structure identification for multilayer networks. IEEE Trans. Cybern. 48, 754–764 (2018).
Li, Y., Wu, X., Lu, J. & Lu, J. Synchronizability of duplex networks. IEEE T Circuits-II 63, 206–210 (2016).
Tang, L., Wu, X., Lu, J. H., Lu, J. A. & D’Souza, R. Master stability functions for complete, intralayer, and interlayer synchronization in multiplex networks of coupled Rossler oscillators. Phys. Rev E 99, 012304 (2019).
Silva, D. H. & Ferreira, S. C. Activation thresholds in epidemic spreading with motile infectious agents on scale-free networks. Chaos 28, 123112 (2018).
Sun, M., Zhang, H., Kang, H., Zhu, G. & Fu, X. Epidemic spreading on adaptively weighted scale-free networks. J. Math. Biol. 74, 1263–1298 (2017).
Chu, X., Zhang, Z., Guan, J. & Zhou, S. Epidemic spreading with nonlinear infectivity in weighted scale-free networks. Phys. A 390, 471–481 (2011).
Silva, S., Ferreira, J. & Martins, M. Epidemic spreading in a scale-free network of regular lattices. Phys. A 377, 689–697 (2007).
Pu, C. et al. Traffic-driven SIR epidemic spreading in networks. Phys. A 446, 129–137 (2016).
Li, T. et al. An epidemic spreading model on adaptive scale-free networks with feedback mechanism. Phys. A 450, 649–656 (2016).
Liu, Q. & Li, H. Global dynamics analysis of an SEIR epidemic model with discrete delay on complex network. Phys. A 524, 289–296 (2019).
Liu, J. & Zhang, T. Epidemic spreading of an SEIRS model in scale-free networks. Commun. Nonlinear Sci. 16, 3375–3384 (2011).
Li, T., Wang, Y. & Guan, Z. Spreading dynamics of a SIQRS epidemic model on scale-free networks. Commun. Nonlinear Sci. 19, 686–692 (2014).
Wan, C., Li, T., Zhang, W. & Dong, J. Dynamics of epidemic spreading model with drug-resistant variation on scale-free networks. Phys. A 493, 17–28 (2018).
Xu, D., Xu, X., Xie, Y. & Yang, C. Optimal control of an SIVRS epidemic spreading model with virus variation based on complex networks. Commun. Nonlinear Sci. 48, 200–210 (2017).
d’Onofrio, A. A note on the global behaviour of the network-based SIS epidemic model. Nonlinear Anal.-Real. 9, 1567–1572 (2008).
Yu, Y., Ding, L., Lin, L., Hu, P. & An, X. Stability of the SNIS epidemic spreading model with contagious incubation period over heterogeneous networks. Phys. A 526, 120878 (2019).
Shen, Z., Wang, W., Fan, Y., Di, Z. & Lai, Y. C. Reconstructing propagation networks with natural diversity and identifying hidden sources. Nat. Commun. 5, 4323 (2014).
Fan, D., Jiang, G., Song, Y. & Zhang, X. Influence of geometric correlations on epidemic spreading in multiplex networks. Phys. A. 533, 122028 (2019).
da Silva, P. C. V. et al. Epidemic spreading with awareness and different timescales in multiplex networks. Phys. Rev. E 100, 032313 (2019).
Nian, F. & Yao, S. The epidemic spreading on the multi-relationships network. Appl. Math. Comput. 339, 866–873 (2018).
Esquivel-Gomez, J. & Barajas-Ramirez, J. Efficiency of quarantine and self-protection processes in epidemic spreading control on scale-free networks. Chaos 28, 013119 (2018).
Wu, X., Zhou, C., Chen, G. & Lu, J. Detecting the topologies of complex networks with stochastic perturbations. Chaos 21, 043129 (2011).
Zhang, S., Wu, X., Lu, J., Feng, H. & Lu, J. Recovering structures of complex dynamical networks based on generalized outer synchronization. IEEE T Circuits-I 61, 3216–3224 (2014).
Li, G., Wu, X., Liu, J., Lu, J. & Guo, C. Recovering network topologies via Taylor expansion and compressive sensing. Chaos 25, 043102 (2015).
Li, G., Li, N., Liu, S. & Wu, X. Compressive sensing-based topology identification of multilayer networks. Chaos 29, 053117 (2019).
Su, R., Wang, W. & Lai, Y. Detecting hidden nodes in complex networks from time series. Phys. Rev. E 85, 065201 (2012).
Su, R., Ni, X., Wang, W. & Lai, Y. Forecasting synchronizability of complex networks from data. Phys. Rev. E 85, 056220 (2012).
Li, M., Wang, M., Xue, S. & Ma, J. The influence of awareness on epidemic spreading on random networks. J. Theor. Biol. 486, 110090 (2020).
Donoho, D. L. Compressed sensing. IEEE T Inform Theory 52, 1289–1306 (2006).
Candes, E., Romberg, J. & Tao, T. Stable signal recovery from incomplete and inaccurate measurements. Commun. Pur. Appl. Math. 59, 1207–1223 (2006).
Boyd, S., Parikh, N., Chu, E., Peleato, B. & Eckstein, J. Distributed optimization and statistical learning via the alternating direction method of multipliers. Found. Trends Mach. Learn. 3, 1–122 (2010).
Acknowledgements
This work was funded by the China Scholarship Council No. 201808420377.
Ethics declarations
Competing interests
The authors declare no competing interests.
Additional information
Publisher's note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Li, G., Liu, G., Wu, X. et al. Identification of disease propagation paths in two-layer networks. Sci Rep 13, 6357 (2023). https://doi.org/10.1038/s41598-023-33624-y
Received:
Accepted:
Published:
DOI: https://doi.org/10.1038/s41598-023-33624-y
Comments
By submitting a comment you agree to abide by our Terms and Community Guidelines. If you find something abusive or that does not comply with our terms or guidelines please flag it as inappropriate.
