Sight is one of our most vital senses. Biologically inspired machine vision has developed rapidly in the past decade, to the point that artificial systems can ‘see’ in the sense of gaining valuable information from images and videos1,2, although human vision remains much more efficient. Writing in Nature, Mennel et al.3 report a design for a visual system that, rather like the brain, can be trained to classify simple images in nanoseconds.
Read the paper: Ultrafast machine vision with 2D material neural network image sensors
Modern image sensors such as those in digital cameras are based on semiconductor (solid-state) technology and were developed in the early 1970s; they fall into two main types, known as charge-coupled devices and active-pixel sensors4. These sensors can faithfully capture visual information from the environment, but generate a lot of redundant data. This vast amount of optical information is usually converted to a digital electronic format and passed to a computing unit for image processing.
The resulting movement of massive amounts of data between sensor and processing unit results in delays (latency) and high power consumption. As imaging rates and numbers of pixels grow, bandwidth limitations make it difficult to send everything back to a centralized or cloud-based computer rapidly enough for real-time processing and decision-making — which is especially important for delay-sensitive applications such as driverless vehicles, robotics or industrial manufacturing.
A better solution would be to shift some of the computational tasks to the sensory devices at the outer edges of the computer system, reducing unnecessary data movement. And because sensors normally produce analog (continuously varying) outputs, analog processing would be preferable to digital: analog-to-digital conversion is notoriously time- and energy-consuming.
To mimic the brain’s efficient processing of information, biologically inspired neuromorphic engineering adopts a computing architecture that has highly interconnected elements (neurons, connected by synapses), allowing parallel computing (Fig. 1a). These artificial neural networks can learn from their surroundings by iteration — for instance, learning to classify something after being shown known examples (supervised learning), or to recognize a characteristic structure of an object from input data without extra information (unsupervised learning). During learning, an algorithm repeatedly makes predictions and strengthens or weakens each synapse in the network until it reaches an optimum setting.

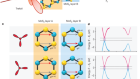
Figure 1 | Computing within a vision sensor for intelligent and efficient preprocessing. a, In conventional artificial-intelligence (AI) vision sensors, signals are collected from light-responsive sensors, converted from analog to digital form (ADC, analog-to-digital converter), amplified and then fed as inputs to an external artificial neural network (ANN) — layers of interconnected computational units (circles) whose connections can be adjusted, allowing the network to be trained to perform tasks such as classifying images. An input layer of the ANN receives signals encoding simple physical elements (represented here by dots and lines); in subsequent layers, these are optimized to mid-level features (simple shapes); and refined images are formed at the output layer (3D shapes). The overall response can be slow and energy-hungry. b, Mennel et al.3 report a system in which interconnected sensors (squares) on a chip not only collect signals, but also work as an ANN to recognize simple features, reducing movement of redundant data between sensors and external circuits.
Mennel and co-workers implement an artificial neural network directly in their image sensor. On a chip, they construct a network of photodiodes — tiny, light-sensitive units, each consisting of a few atomic layers of tungsten diselenide. This semiconductor’s response to light can be increased or decreased by altering an applied voltage, so that the sensitivity of each diode can be individually tuned. In effect, this turns the photosensor network into a neural network (Fig. 1b) and allows it to carry out simple computational tasks. Changing the light responsivity of a photodiode alters the connection strength — the synaptic weight — in the network. Thus, the device combines optical sensing with neuromorphic computing.
The authors arrange the photodiodes into a square array of nine pixels, with three diodes to each pixel. When an image is projected on to the chip, various diode currents are produced, combined and read. The hardware array provides a form of analog computing: each photodiode generates an output current that is proportional to the incident light intensity, and the resulting currents are summed along a row or column, according to Kirchhoff’s law (a fundamental rule of currents in circuits).
The array is then trained to perform a task. The discrepancy between the currents produced by the array and the predicted currents (the currents that would be produced if the array responds correctly to the image, for a given task) is analysed off-chip and used to adjust the synaptic weight for the next training cycle. This learning stage takes up time and computing resources, but, once trained, the chip performs its set task rapidly.
Using different algorithms for the neural network, the authors demonstrate two neuromorphic functions. The first is classification: their 3 × 3 array of pixels can sort an image into one of three classes that correspond to three simplified letters, and thus identify which letter it is in nanoseconds. This relatively simple task is just a proof of concept, and could be extended to recognizing more-complicated images if the array size were scaled up.
Nanoscale connections for brain-like circuits
The second function is autoencoding: the computing-in-sensor array can produce a simplified representation of a processed image by learning its key features, even in the presence of signal noise. The encoded version contains only the most essential information, but can be decoded to reconstruct an image close to the original.
There is more to be done before this promising technology can be used in practical applications. A neuromorphic visual system for autonomous vehicles and robotics will need to capture dynamic images and videos in three dimensions and with a wide field of view. Currently used image-capture technology usually translates the 3D real world into 2D information, thereby losing movement information and depth. The planar shape of existing image-sensor arrays also restricts the development of wide-field cameras5.
Imaging under dim light would be difficult for the device described by the authors. A redesign would be needed to improve light absorption in the thin semiconductor and to increase the range of light intensities that can be detected. Furthermore, the reported design requires high voltages and consumes a lot of power; by comparison, the energy consumption per operation in a biological neural network is at the sub-femtojoule level (10−15 to 10−13 joules)6. It would also be useful to expand the response to ultraviolet and infrared light, to capture information unavailable in the visible spectrum7.
The thin semiconductors used are difficult to produce uniformly over large areas, and are hard to process so that they can be integrated with silicon electronics, such as external circuits used for readout or feedback control. The speed and energy efficiency of devices that use these sensors will be dominated not by the image-capturing process, but by data movement between sensors and external circuits. Moreover, although the computing-in-sensor unit collects and computes data in the analog domain, reducing analog-to-digital conversions, the peripheral circuits still suffer from other intrinsic delays. The sensors and external circuits will need to be co-developed to decrease the latency of the entire system.
Mennel and colleagues’ computing-in-sensor system should inspire further research into artificial-intelligence (AI) hardware. A few companies have developed AI vision chips based on silicon electronics8, but the chips’ intrinsic digital architecture leads to problems of latency and power efficiency.
More broadly, the authors’ strategy is not limited to visual systems. It could be extended to other physical inputs for auditory, tactile, thermal or olfactory sensing9–11. Development of such intelligent systems, together with the arrival of the 5G fast wireless network, should allow real-time edge (low-latency) computing in the future.
 Read the paper: Ultrafast machine vision with 2D material neural network image sensors
Read the paper: Ultrafast machine vision with 2D material neural network image sensors
 Two artificial synapses are better than one
Two artificial synapses are better than one
 Nanoscale connections for brain-like circuits
Nanoscale connections for brain-like circuits